
Como ler um arquivo PDF em Java
Este artigo demonstrará como ler arquivos PDF em Java usando a biblioteca PDF para o projeto de demonstração em Java, chamado IronPDF Java Library Overview , para ler objetos de texto e metadados em arquivos PDF, além de criar documentos criptografados.
Passos para ler um arquivo PDF em Java
- Instale a biblioteca PDF para ler arquivos PDF usando Java.
- Importe as dependências para usar o documento PDF no projeto.
- Carregue um arquivo PDF existente usando
PdfDocument.fromFile[documentação do método](/java/object-reference/api/com/ironsoftware/ironpdf/PdfDocument.html#fromFile(java.nio.file.Path). - Extraia o texto no arquivo PDF usando o [explicação do método de extração de texto do PDF](/java/object-reference/api/com/ironsoftware/ironpdf/PdfDocument.html#extractAllText() método.
- Crie o objeto Metadata usando o [tutorial de recuperação de metadados do PDF](/java/object-reference/api/com/ironsoftware/ironpdf/PdfDocument.html#getMetadata() método.
- Leia o autor dos metadados usando o [guia para obter o autor dos metadados](/java/object-reference/api/com/ironsoftware/ironpdf/metadata/MetadataManager.html#getAuthor() método.
Apresentando o IronPDF for Java como uma biblioteca de leitura de PDFs.
Para agilizar o processo de leitura de arquivos PDF em Java, os desenvolvedores frequentemente recorrem a bibliotecas de terceiros que oferecem soluções abrangentes e eficientes. Uma dessas bibliotecas de destaque é o IronPDF for Java.
O IronPDF foi projetado para ser amigável ao desenvolvedor, fornecendo uma API simples que abstrai as complexidades da manipulação de páginas PDF. Com o IronPDF, os desenvolvedores Java podem integrar facilmente recursos de leitura de PDF em seus projetos, reduzindo o tempo e o esforço de desenvolvimento. Esta biblioteca suporta uma ampla gama de funcionalidades de PDF, tornando-a uma escolha versátil para diversos casos de uso.
As principais funcionalidades incluem a capacidade de criar um arquivo PDF a partir de diferentes formatos, incluindo HTML, JavaScript, CSS, documentos XML e vários formatos de imagem. Além disso, o IronPDF oferece a possibilidade de adicionar cabeçalhos e rodapés a PDFs , criar tabelas dentro de documentos PDF e muito mais.
Instalando o IronPDF for Java
Para configurar o IronPDF, certifique-se de ter um compilador Java confiável. Este artigo recomenda a utilização do IntelliJ IDEA.
- Inicie o IntelliJ IDEA e crie um novo projeto Maven.
-
Uma vez que o projeto esteja estabelecido, acesse o arquivo
pom.xml. Insira as seguintes dependências Maven para integrar o IronPDF:<dependency> <groupId>com.ironsoftware</groupId> <artifactId>ironpdf</artifactId> <version>YOUR_VERSION_HERE</version> </dependency><dependency> <groupId>com.ironsoftware</groupId> <artifactId>ironpdf</artifactId> <version>YOUR_VERSION_HERE</version> </dependency>XML - Depois de adicionar essas dependências, clique no pequeno botão que aparece no lado direito da tela para instalá-las.
Exemplo de código Java para ler arquivos PDF
Vamos explorar um exemplo simples de código Java que demonstra como usar o IronPDF para ler o conteúdo de um arquivo PDF. Neste exemplo, vamos nos concentrar no método de extração de texto de um documento PDF.
// Importing necessary classes from IronPDF and Java libraries
import com.ironsoftware.ironpdf.*;
import java.io.IOException;
import java.nio.file.Paths;
// Class definition
class Test {
public static void main(String[] args) throws IOException {
// Setting the license key for IronPDF (replace "License-Key" with a valid key)
License.setLicenseKey("License-Key");
// Loading a PDF document from the file "html_file_saved.pdf"
PdfDocument pdf = PdfDocument.fromFile(Paths.get("html_file_saved.pdf"));
// Extracting all text content from the PDF document
String text = pdf.extractAllText();
// Printing the extracted text to the console
System.out.println(text);
}
}// Importing necessary classes from IronPDF and Java libraries
import com.ironsoftware.ironpdf.*;
import java.io.IOException;
import java.nio.file.Paths;
// Class definition
class Test {
public static void main(String[] args) throws IOException {
// Setting the license key for IronPDF (replace "License-Key" with a valid key)
License.setLicenseKey("License-Key");
// Loading a PDF document from the file "html_file_saved.pdf"
PdfDocument pdf = PdfDocument.fromFile(Paths.get("html_file_saved.pdf"));
// Extracting all text content from the PDF document
String text = pdf.extractAllText();
// Printing the extracted text to the console
System.out.println(text);
}
}Este código Java utiliza a biblioteca IronPDF para extrair texto de um arquivo PDF especificado. Ele importará a biblioteca Java e definirá a chave de licença, um pré-requisito para usar a biblioteca. Em seguida, o código carrega um documento PDF do arquivo "html_file_saved.pdf" e extrai todo o seu conteúdo de texto como um buffer de string interno. O texto extraído é armazenado em uma variável e posteriormente impresso no console.
Imagem de saída do console
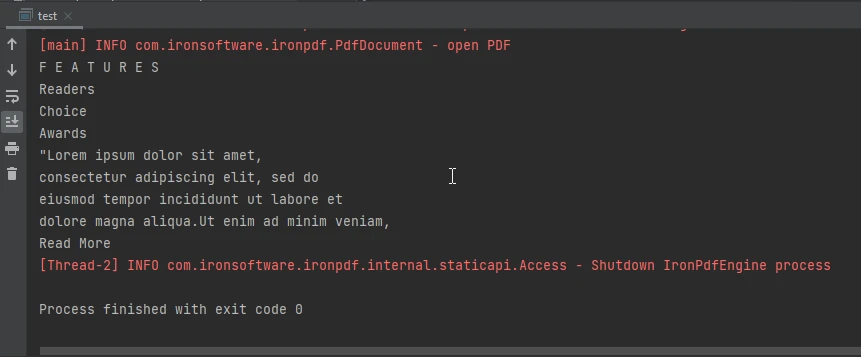 A saída do console
A saída do console
Exemplo de código Java para ler metadados de um arquivo PDF
Expandindo suas capacidades além da extração de texto, o IronPDF agora oferece suporte à extração de metadados de arquivos PDF. Para ilustrar essa funcionalidade, vamos analisar um exemplo de código Java que demonstra o processo de recuperação de metadados de um documento PDF.
// Importing necessary classes from IronPDF and Java libraries
import com.ironsoftware.ironpdf.*;
import com.ironsoftware.ironpdf.metadata.MetadataManager;
import java.io.IOException;
import java.nio.file.Paths;
// Class definition
class Test {
public static void main(String[] args) throws IOException {
// Setting the license key for IronPDF (replace "License-Key" with a valid key)
License.setLicenseKey("License-Key");
// Loading a PDF document from the file "html_file_saved.pdf"
PdfDocument document = PdfDocument.fromFile(Paths.get("html_file_saved.pdf"));
// Creating a MetadataManager object to access document metadata
MetadataManager metadata = document.getMetadata();
// Extracting the author information from the document metadata
String author = metadata.getAuthor();
// Printing the extracted author information to the console
System.out.println(author);
}
}// Importing necessary classes from IronPDF and Java libraries
import com.ironsoftware.ironpdf.*;
import com.ironsoftware.ironpdf.metadata.MetadataManager;
import java.io.IOException;
import java.nio.file.Paths;
// Class definition
class Test {
public static void main(String[] args) throws IOException {
// Setting the license key for IronPDF (replace "License-Key" with a valid key)
License.setLicenseKey("License-Key");
// Loading a PDF document from the file "html_file_saved.pdf"
PdfDocument document = PdfDocument.fromFile(Paths.get("html_file_saved.pdf"));
// Creating a MetadataManager object to access document metadata
MetadataManager metadata = document.getMetadata();
// Extracting the author information from the document metadata
String author = metadata.getAuthor();
// Printing the extracted author information to the console
System.out.println(author);
}
}Este código Java utiliza a biblioteca IronPDF para extrair metadados, especificamente as informações do autor, de um documento PDF. O processo começa carregando um documento PDF do arquivo "html_file_saved.pdf". O código recupera os metadados do documento usando a documentação da classe MetadataManager , especificamente buscando as informações do autor. Os detalhes do autor extraídos são armazenados em uma variável e impressos no console.
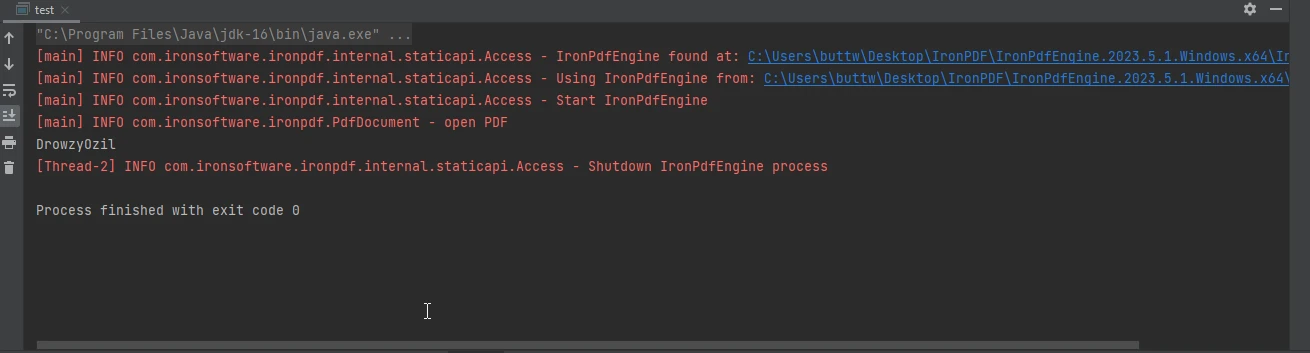 A saída do console
A saída do console
Conclusão
Em conclusão, ler um documento PDF existente em um programa Java é uma habilidade valiosa que abre um mundo de possibilidades para os desenvolvedores. Seja para extrair texto, imagens ou outros dados, a capacidade de manipular PDFs programaticamente é um aspecto crucial de muitas aplicações. IronPDF for Java serve como uma solução robusta e eficiente para desenvolvedores que buscam integrar recursos de leitura de PDF em seus projetos Java.
Seguindo os passos de instalação e explorando os exemplos de código fornecidos, os desenvolvedores podem aproveitar rapidamente o poder do IronPDF para criar novos arquivos e lidar com tarefas relacionadas a PDFs com facilidade. Além disso, também é possível explorar ainda mais suas capacidades na criação de documentos criptografados.
O portal de produtos IronPDF oferece amplo suporte aos seus desenvolvedores. Para saber mais sobre como o IronPDF for Java funciona, visite estas páginas de documentação abrangentes . Além disso, o IronPDF oferece uma página com uma licença de avaliação gratuita , que é uma ótima oportunidade para explorar o IronPDF e seus recursos.
Perguntas frequentes
Como posso ler texto de um arquivo PDF em Java?
É possível ler texto de um arquivo PDF em Java usando o IronPDF, carregando o PDF com o método PdfDocument.fromFile e, em seguida, extraindo o texto com o método extractAllText .
Como extrair metadados de um PDF em Java?
Para extrair metadados de um PDF em Java usando o IronPDF, carregue o documento PDF e utilize o método getMetadata . Isso permite recuperar informações como o nome do autor e outras propriedades de metadados.
Quais são os passos para instalar uma biblioteca PDF em um projeto Java?
Para instalar o IronPDF em um projeto Java, crie um projeto Maven no IntelliJ IDEA e adicione o IronPDF como uma dependência no arquivo pom.xml . Em seguida, instale as dependências usando as opções fornecidas no IntelliJ.
Posso criar documentos PDF criptografados em Java?
Embora este artigo se concentre na leitura de PDFs, o IronPDF também permite a criação de documentos PDF criptografados. Para obter instruções detalhadas, consulte a documentação do IronPDF.
Qual a finalidade de configurar uma chave de licença para uma biblioteca Java PDF?
Para acessar todos os recursos da biblioteca, é necessário definir uma chave de licença no IronPDF. Você a define no seu código Java usando License.setLicenseKey para remover as limitações da versão de avaliação.
Que funcionalidades oferece uma biblioteca Java para PDF?
O IronPDF oferece funcionalidades como a criação de PDFs a partir de HTML e imagens, a adição de cabeçalhos e rodapés, a criação de tabelas e a extração de texto e metadados de arquivos PDF.
Como posso solucionar problemas comuns na leitura de PDFs em Java?
Certifique-se de que suas dependências do Maven estejam configuradas corretamente no arquivo pom.xml e que a biblioteca IronPDF esteja instalada corretamente. Consulte a documentação do IronPDF para obter instruções detalhadas de solução de problemas.
Onde posso aprender mais sobre como usar uma biblioteca PDF em Java?
Para obter mais informações sobre o IronPDF for Java, visite o portal do produto IronPDF e explore a documentação. Eles também oferecem uma licença de avaliação gratuita para testar suas funcionalidades.

















