
How to Read A PDF File in Java
This article will demonstrate how PDF files are read in Java using the PDF Library for the demo Java project, named IronPDF Java Library Overview, to read text and metadata-type objects in PDF files along with creating encrypted documents.
Steps to Read PDF File in Java
- Install the PDF Library to read PDF files using Java.
- Import the dependencies to use the PDF document in the project.
- Load an existing PDF file using
PdfDocument.fromFile[method documentation](/java/object-reference/api/com/ironsoftware/ironpdf/PdfDocument.html#fromFile(java.nio.file.Path). - Extract the text in the PDF file using the [PDF text extraction method explanation](/java/object-reference/api/com/ironsoftware/ironpdf/PdfDocument.html#extractAllText() method.
- Create the Metadata object using the [PDF metadata retrieval tutorial](/java/object-reference/api/com/ironsoftware/ironpdf/PdfDocument.html#getMetadata() method.
- Read the author from metadata using the [getting author from metadata guide](/java/object-reference/api/com/ironsoftware/ironpdf/metadata/MetadataManager.html#getAuthor() method.
Introducing IronPDF for Java as a Reading PDF Library
To streamline the process of reading PDF files in Java, developers often turn to third-party libraries that provide comprehensive and efficient solutions. One such standout library is IronPDF for Java.
IronPDF is designed to be developer-friendly, providing a straightforward API that abstracts the complexities of PDF page manipulation. With IronPDF, Java developers can seamlessly integrate PDF reading capabilities into their projects, reducing development time and effort. This library supports a wide range of PDF functionalities, making it a versatile choice for various use cases.
The main features include the ability to create a PDF file from different formats including HTML, JavaScript, CSS, XML documents, and various image formats. In addition, IronPDF offers the ability to add headers and footers to PDFs, create tables within PDF documents, and much more.
Installing IronPDF for Java
To set up IronPDF, ensure you have a reliable Java compiler. This article recommends utilizing IntelliJ IDEA.
- Launch IntelliJ IDEA and initiate a new Maven project.
-
Once the project is established, access the
pom.xmlfile. Insert the following Maven dependencies to integrate IronPDF:<dependency> <groupId>com.ironsoftware</groupId> <artifactId>ironpdf</artifactId> <version>YOUR_VERSION_HERE</version> </dependency><dependency> <groupId>com.ironsoftware</groupId> <artifactId>ironpdf</artifactId> <version>YOUR_VERSION_HERE</version> </dependency>XML - After adding these dependencies, click on the small button that appears on the right side of the screen to install them.
Read PDF Files in Java Code Example
Let's explore a simple Java code example that demonstrates how to use IronPDF to read the content of a PDF file. In this example, let's focus on the method of extracting text from a PDF document.
// Importing necessary classes from IronPDF and Java libraries
import com.ironsoftware.ironpdf.*;
import java.io.IOException;
import java.nio.file.Paths;
// Class definition
class Test {
public static void main(String[] args) throws IOException {
// Setting the license key for IronPDF (replace "License-Key" with a valid key)
License.setLicenseKey("License-Key");
// Loading a PDF document from the file "html_file_saved.pdf"
PdfDocument pdf = PdfDocument.fromFile(Paths.get("html_file_saved.pdf"));
// Extracting all text content from the PDF document
String text = pdf.extractAllText();
// Printing the extracted text to the console
System.out.println(text);
}
}// Importing necessary classes from IronPDF and Java libraries
import com.ironsoftware.ironpdf.*;
import java.io.IOException;
import java.nio.file.Paths;
// Class definition
class Test {
public static void main(String[] args) throws IOException {
// Setting the license key for IronPDF (replace "License-Key" with a valid key)
License.setLicenseKey("License-Key");
// Loading a PDF document from the file "html_file_saved.pdf"
PdfDocument pdf = PdfDocument.fromFile(Paths.get("html_file_saved.pdf"));
// Extracting all text content from the PDF document
String text = pdf.extractAllText();
// Printing the extracted text to the console
System.out.println(text);
}
}This Java code utilizes the IronPDF library to extract text from a specified PDF file. It will import the Java library as well as set the license key, a prerequisite for using the library. The code then loads a PDF document from the file "html_file_saved.pdf" and extracts all of its text content from the file as an internal string buffer. The extracted text is stored in a variable and subsequently printed to the console.
Console Output Image
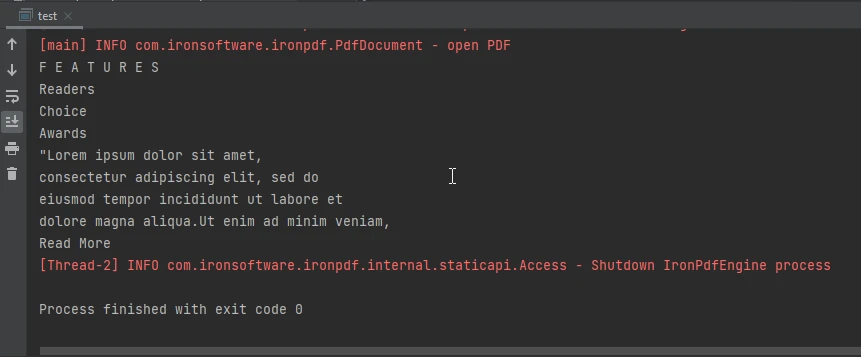 The console output
The console output
Read Metadata of PDF File in Java Code Example
Expanding on its capabilities beyond text extraction, IronPDF extends support to the extraction of metadata from PDF files. To illustrate this functionality, let's delve into a Java code example that showcases the process of retrieving metadata from a PDF document.
// Importing necessary classes from IronPDF and Java libraries
import com.ironsoftware.ironpdf.*;
import com.ironsoftware.ironpdf.metadata.MetadataManager;
import java.io.IOException;
import java.nio.file.Paths;
// Class definition
class Test {
public static void main(String[] args) throws IOException {
// Setting the license key for IronPDF (replace "License-Key" with a valid key)
License.setLicenseKey("License-Key");
// Loading a PDF document from the file "html_file_saved.pdf"
PdfDocument document = PdfDocument.fromFile(Paths.get("html_file_saved.pdf"));
// Creating a MetadataManager object to access document metadata
MetadataManager metadata = document.getMetadata();
// Extracting the author information from the document metadata
String author = metadata.getAuthor();
// Printing the extracted author information to the console
System.out.println(author);
}
}// Importing necessary classes from IronPDF and Java libraries
import com.ironsoftware.ironpdf.*;
import com.ironsoftware.ironpdf.metadata.MetadataManager;
import java.io.IOException;
import java.nio.file.Paths;
// Class definition
class Test {
public static void main(String[] args) throws IOException {
// Setting the license key for IronPDF (replace "License-Key" with a valid key)
License.setLicenseKey("License-Key");
// Loading a PDF document from the file "html_file_saved.pdf"
PdfDocument document = PdfDocument.fromFile(Paths.get("html_file_saved.pdf"));
// Creating a MetadataManager object to access document metadata
MetadataManager metadata = document.getMetadata();
// Extracting the author information from the document metadata
String author = metadata.getAuthor();
// Printing the extracted author information to the console
System.out.println(author);
}
}This Java code utilizes the IronPDF library to extract metadata, specifically the author information, from a PDF document. It begins by loading a PDF document from the file "html_file_saved.pdf." The code retrieves the document's metadata using the MetadataManager class documentation, specifically fetching the author information. The extracted author details are stored in a variable and printed to the console.
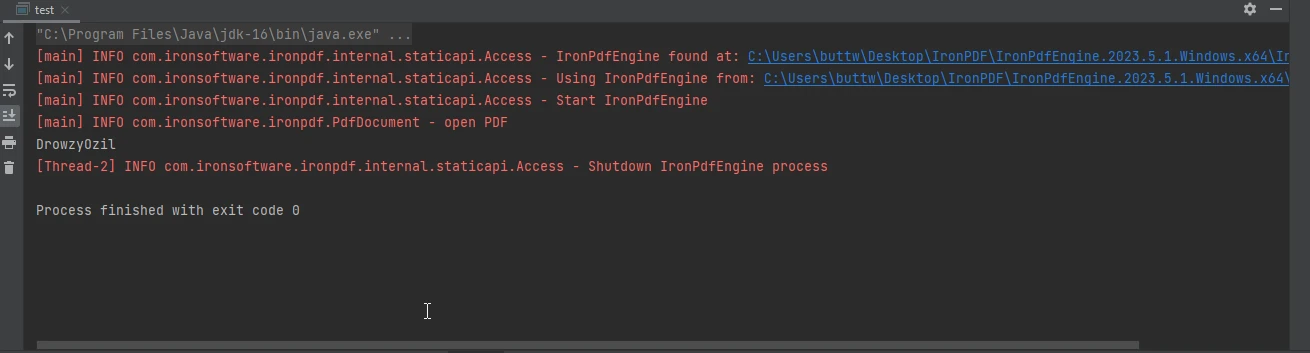 The console output
The console output
Conclusion
In conclusion, reading an existing PDF document in a Java program is a valuable skill that opens up a world of possibilities for developers. Whether it's extracting text, images, or other data, the ability to manipulate PDFs programmatically is a crucial aspect of many applications. IronPDF for Java serves as a robust and efficient solution for developers seeking to integrate PDF reading capabilities into their Java projects.
By following the installation steps and exploring the provided code examples, developers can quickly leverage the power of IronPDF to create new files and handle PDF-related tasks with ease. In addition to this, one can also further explore its capabilities in creating encrypted documents.
IronPDF product portal offers extensive support for its developers. To know more about how IronPDF for Java works, visit these comprehensive documentation pages. Also, IronPDF offers a free trial license offer page that is a great opportunity to explore IronPDF and its features.
Frequently Asked Questions
How can I read text from a PDF file in Java?
You can read text from a PDF file in Java using IronPDF by loading the PDF with the PdfDocument.fromFile method and then extracting the text using the extractAllText method.
How do I extract metadata from a PDF in Java?
To extract metadata from a PDF in Java using IronPDF, load the PDF document and use the getMetadata method. This allows you to retrieve information such as the author's name and other metadata properties.
What are the steps to install a PDF library in a Java project?
To install IronPDF in a Java project, create a Maven project in IntelliJ IDEA and add IronPDF as a dependency in the pom.xml file. Then, install the dependencies using the options provided in IntelliJ.
Can I create encrypted PDF documents in Java?
While this article focuses on reading PDFs, IronPDF does support the creation of encrypted PDF documents. For detailed instructions, refer to IronPDF's documentation.
What is the purpose of setting a license key for a Java PDF library?
Setting a license key in IronPDF is necessary to access the full features of the library. You set it in your Java code using License.setLicenseKey to remove trial limitations.
What features does a Java PDF library offer?
IronPDF provides features such as creating PDFs from HTML, images, adding headers and footers, creating tables, and extracting text and metadata from PDF files.
How can I troubleshoot common issues with reading PDFs in Java?
Ensure that your Maven dependencies are correctly set up in the pom.xml file and that the IronPDF library is properly installed. Refer to IronPDF's documentation for detailed troubleshooting steps.
Where can I learn more about using a PDF library in Java?
For more information about IronPDF for Java, visit the IronPDF product portal and explore their documentation. They also provide a free trial license for testing its capabilities.

















