
如何在 Java 中讀取 PDF 文件
本文將示範如何使用 Java 中的 PDF 庫讀取 PDF 文件,並以名為IronPDF Java Library Overview的示範 Java 專案為例,讀取 PDF 文件中的文字和元資料類型對象,以及建立加密文件。
如何在Java中讀取PDF文件
- 安裝 PDF 函式庫,以便使用 Java 讀取 PDF 檔案。
- 匯入在專案中使用 PDF 文件所需的依賴項。
- 使用[
PdfDocument.fromFile方法文件](/java/object-reference/api/com/ironsoftware/ironpdf/PdfDocument.html#fromFile(java.nio.file.Path)載入現有 PDF 文件)。 - 使用 PDF 文字擷取方法([詳見 PDF 文字擷取方法說明](/java/object-reference/api/com/ironsoftware/ironpdf/PdfDocument.html#extractAllText())擷取 PDF 檔案中的文字。
- 使用[PDF 元資料檢索教學](/java/object-reference/api/com/ironsoftware/ironpdf/PdfDocument.html#getMetadata())方法建立元資料物件。
- 使用從元資料中取得作者的方法(請參閱["從元資料中取得作者"指南)從元](/java/object-reference/api/com/ironsoftware/ironpdf/metadata/MetadataManager.html#getAuthor()資料中讀取作者資訊。
介紹適用於 Java 的IronPDF ,它是一款 PDF 閱讀庫
為了簡化 Java 中讀取 PDF 檔案的過程,開發人員經常求助於提供全面且高效解決方案的第三方程式庫。 IronPDF for Java 就是這樣一個出色的函式庫。
IronPDF 的設計對開發者非常友好,它提供了一個簡單易用的 API,抽象化了 PDF 頁面操作的複雜性。 透過IronPDF,Java 開發人員可以無縫地將 PDF 閱讀功能整合到他們的專案中,從而減少開發時間和精力。 該庫支援多種 PDF 功能,使其成為各種使用場景的多功能選擇。
主要功能包括能夠從不同格式(包括 HTML、 JavaScript、CSS、XML 文件和各種圖像格式)建立 PDF 文件。 此外, IronPDF也提供了在 PDF 中新增頁首和頁尾、在 PDF 文件中建立表格等功能。
安裝IronPDF 適用於 Java
要安裝IronPDF,請確保您擁有可靠的 Java 編譯器。 本文推薦使用 IntelliJ IDEA。
- 啟動 IntelliJ IDEA 並建立新的Maven專案。
-
專案建立完成後,存取
pom.xml檔案。插入以下Maven依賴項以整合IronPDF:<dependency> <groupId>com.ironsoftware</groupId> <artifactId>ironpdf</artifactId> <version>YOUR_VERSION_HERE</version> </dependency><dependency> <groupId>com.ironsoftware</groupId> <artifactId>ironpdf</artifactId> <version>YOUR_VERSION_HERE</version> </dependency>XML - 新增這些依賴項後,點擊螢幕右側出現的小按鈕進行安裝。
Java 程式碼範例中讀取 PDF 文件
讓我們來看看一個簡單的Java程式碼範例,它示範如何使用IronPDF讀取PDF檔案的內容。在這個例子中,我們將重點放在從PDF文件中提取文字的方法。
// Importing necessary classes from IronPDF and Java libraries
import com.ironsoftware.ironpdf.*;
import java.io.IOException;
import java.nio.file.Paths;
// Class definition
class Test {
public static void main(String[] args) throws IOException {
// Setting the license key for IronPDF (replace "License-Key" with a valid key)
License.setLicenseKey("License-Key");
// Loading a PDF document from the file "html_file_saved.pdf"
PdfDocument pdf = PdfDocument.fromFile(Paths.get("html_file_saved.pdf"));
// Extracting all text content from the PDF document
String text = pdf.extractAllText();
// Printing the extracted text to the console
System.out.println(text);
}
}// Importing necessary classes from IronPDF and Java libraries
import com.ironsoftware.ironpdf.*;
import java.io.IOException;
import java.nio.file.Paths;
// Class definition
class Test {
public static void main(String[] args) throws IOException {
// Setting the license key for IronPDF (replace "License-Key" with a valid key)
License.setLicenseKey("License-Key");
// Loading a PDF document from the file "html_file_saved.pdf"
PdfDocument pdf = PdfDocument.fromFile(Paths.get("html_file_saved.pdf"));
// Extracting all text content from the PDF document
String text = pdf.extractAllText();
// Printing the extracted text to the console
System.out.println(text);
}
}這段 Java 程式碼利用IronPDF庫從指定的 PDF 檔案中提取文字。它會匯入該 Java 庫並設定許可證金鑰,這是使用該庫的先決條件。 然後,程式碼從文件"html_file_saved.pdf"載入PDF文檔,並將文件中的所有文字內容提取為內部字串緩衝區。 提取的文字儲存在一個變數中,隨後列印到控制台。
控制台輸出影像
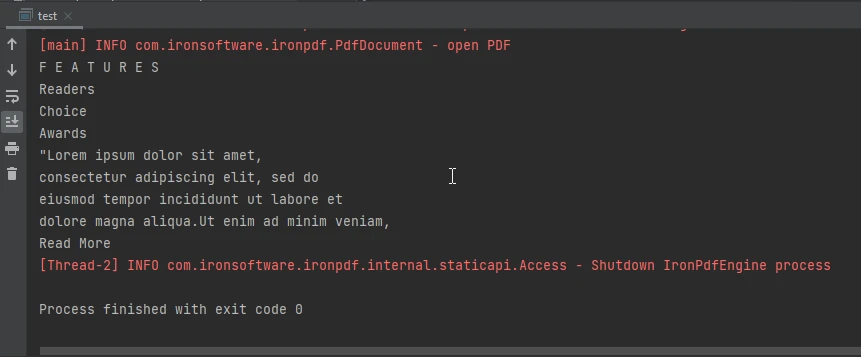 控制台輸出
控制台輸出
Java 程式碼範例中讀取 PDF 檔案的元數據
IronPDF除了能夠提取文字外,還擴展了其功能,支援從 PDF 文件中提取元資料。 為了說明此功能,讓我們深入研究一個 Java 程式碼範例,該範例展示了從 PDF 文件中檢索元資料的過程。
// Importing necessary classes from IronPDF and Java libraries
import com.ironsoftware.ironpdf.*;
import com.ironsoftware.ironpdf.metadata.MetadataManager;
import java.io.IOException;
import java.nio.file.Paths;
// Class definition
class Test {
public static void main(String[] args) throws IOException {
// Setting the license key for IronPDF (replace "License-Key" with a valid key)
License.setLicenseKey("License-Key");
// Loading a PDF document from the file "html_file_saved.pdf"
PdfDocument document = PdfDocument.fromFile(Paths.get("html_file_saved.pdf"));
// Creating a MetadataManager object to access document metadata
MetadataManager metadata = document.getMetadata();
// Extracting the author information from the document metadata
String author = metadata.getAuthor();
// Printing the extracted author information to the console
System.out.println(author);
}
}// Importing necessary classes from IronPDF and Java libraries
import com.ironsoftware.ironpdf.*;
import com.ironsoftware.ironpdf.metadata.MetadataManager;
import java.io.IOException;
import java.nio.file.Paths;
// Class definition
class Test {
public static void main(String[] args) throws IOException {
// Setting the license key for IronPDF (replace "License-Key" with a valid key)
License.setLicenseKey("License-Key");
// Loading a PDF document from the file "html_file_saved.pdf"
PdfDocument document = PdfDocument.fromFile(Paths.get("html_file_saved.pdf"));
// Creating a MetadataManager object to access document metadata
MetadataManager metadata = document.getMetadata();
// Extracting the author information from the document metadata
String author = metadata.getAuthor();
// Printing the extracted author information to the console
System.out.println(author);
}
}這段 Java 程式碼利用IronPDF庫從 PDF 文件中提取元數據,特別是作者資訊。 它首先從文件"html_file_saved.pdf"載入PDF文件。程式碼使用MetadataManager類別文件檢索文件的元數據,特別是取得作者資訊。 提取的作者詳細資訊儲存在一個變數中,並列印到控制台。
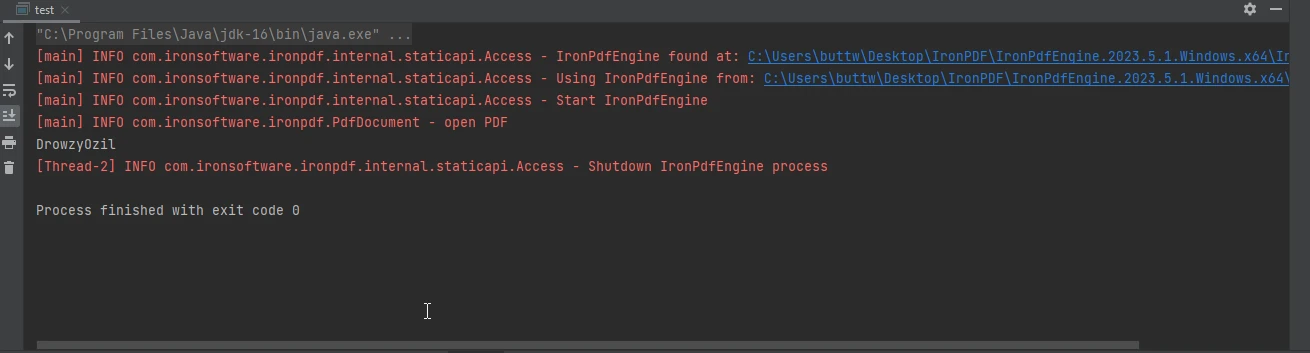 控制台輸出
控制台輸出
結論
總之,在 Java 程式中讀取現有的 PDF 文件是一項寶貴的技能,它為開發人員開啟了無限的可能性。 無論是提取文字、圖像還是其他數據,以程式設計方式操作 PDF 的能力都是許多應用程式的關鍵方面。 IronPDF for Java 為希望將 PDF 閱讀功能整合到 Java 專案中的開發人員提供了一個強大且有效率的解決方案。
透過依照安裝步驟和探索提供的程式碼範例,開發人員可以快速利用IronPDF的強大功能輕鬆建立新文件並處理與 PDF 相關的任務。 除此之外,還可以進一步探索其在建立加密文件方面的功能。
IronPDF產品入口網站為其開發人員提供全面的支援。 若要了解有關IronPDF 適用於 Java 的更多工作原理,請造訪這些全面的文件頁面。 此外, IronPDF還提供免費試用許可頁面,這是一個探索IronPDF及其功能的絕佳機會。
常見問題
如何在Java中讀取PDF文件中的文字?
您可以使用IronPDF在 Java 中讀取 PDF 文件中的文本,方法是使用PdfDocument.fromFile方法載入 PDF,然後使用extractAllText方法提取文字。
如何在Java中從PDF中提取元資料?
要在 Java 中使用IronPDF從 PDF 中提取元數據,請載入 PDF 文件並使用getMetadata方法。這樣就可以檢索諸如作者姓名和其他元資料屬性之類的資訊。
在Java專案中安裝PDF庫的步驟是什麼?
若要在 Java 專案中安裝IronPDF ,請在 IntelliJ IDEA 中建立 Maven 項目,並將IronPDF新增為pom.xml檔案中的依賴項。然後,使用 IntelliJ 提供的選項安裝相依性。
我可以用Java建立加密的PDF文件嗎?
本文主要介紹如何讀取 PDF 文件,但IronPDF也支援建立加密 PDF 文件。有關詳細說明,請參閱 IronPDF 的文件。
為 Java PDF 庫設定許可證金鑰的目的是什麼?
在IronPDF中設定許可證密鑰是存取庫全部功能的必要條件。您可以使用 Java 程式碼中的License.setLicenseKey方法來設定授權金鑰,從而解除試用限制。
Java PDF 函式庫提供哪些功能?
IronPDF提供從 HTML、圖像創建 PDF、添加頁眉和頁腳、建立表格以及從 PDF 文件中提取文字和元資料等功能。
如何排查Java讀取PDF時遇到的常見問題?
請確保pom.xml檔案中已正確配置 Maven 依賴項,且IronPDF庫已正確安裝。有關詳細的故障排除步驟,請參閱 IronPDF 的文件。
哪裡可以學習更多關於在Java中使用PDF庫的知識?
如需了解更多關於IronPDF 適用於 Java 的信息,請訪問IronPDF產品入口網站並查閱其文件。他們還提供免費試用許可證,供您測試其功能。

















