


将 Java PDF 转换为图像文件
使用 IronPDF 的 toBufferedImages 方法,在 Java 中将 PDF 文档转换为 JPEG、PNG 或 TIFF 等图像格式。 加载一个 PDF 文件,调用 toBufferedImages 获取 BufferedImage 对象的列表,然后使用 ImageIO 将每张图像写入磁盘。 整个转换过程的Java代码不到十行。
快速入门:在 Java 中将 PDF 转换为图像
1.在您的 Maven 项目中添加 IronPDF 依赖关系: ```xml :title=pom.xml
2.加载您的 PDF 文档:
```java
//:path=/static-assets/ironpdf-java/content-code-examples/how-to/java-pdf-to-image-tutorial/load-pdf.java
PdfDocument pdf = PdfDocument.fromFile(Paths.get("document.pdf"));3.转换为图像并保存:
//:path=/static-assets/ironpdf-java/content-code-examples/how-to/java-pdf-to-image-tutorial/convert-and-save.java
List<BufferedImage> images = pdf.toBufferedImages();
for (int i = 0; i < images.size(); i++) {
ImageIO.write(images.get(i), "PNG", new File("page_" + i + ".png"));
}//:path=/static-assets/ironpdf-java/content-code-examples/how-to/java-pdf-to-image-tutorial/convert-and-save.java
List<BufferedImage> images = pdf.toBufferedImages();
for (int i = 0; i < images.size(); i++) {
ImageIO.write(images.get(i), "PNG", new File("page_" + i + ".png"));
}如何在 Java 中将 PDF 转换为图像
- 安装IronPDF Java库
- 使用
PdfDocument.fromFile()加载PDF文件 - 调用
toBufferedImages()以获取List - 若有需要,使用
ToImageOptions设置输出尺寸 - 使用
ImageIO.write()将每个图像写入磁盘
什么是 PDF 到图像的转换,为什么需要转换?
PDF到图像转换将PDF文档的每一页转换为独立的图像文件(JPEG、PNG或TIFF),可以显示、嵌入或在没有PDF查看器的情况下进行处理。 Java的标准库没有提供内置的机制,这使得需要文档预览、缩略图生成器或存档管道的开发人员感到不断的痛点。
常见用途包括为文档管理系统生成缩略图预览、为Web应用程序产生页面级截图,以及为报告或演示提取视觉内容。 IronPDF内部处理所有渲染的复杂性,因此应用程序代码保持简短,并且输出与源PDF中的字体、矢量图形或表单字段无关,像素准确。 要了解将图像放入PDF的逆操作,请参见图像到PDF指南。
什么是 IronPDF for Java,它能提供哪些帮助?
IronPDF for Java是一个用于在基于Maven的项目中创建、读取和编辑PDF文件的库。 开发人员使用它从HTML生成PDF、修改现有文档和在服务器上未安装Adobe Acrobat或任何PDF查看器的情况下提取内容。
该库支持自定义标题和页脚、数字签名、表单创建、密码保护和多线程渲染。 其 PDF 转图像功能通过 toBufferedImages 的两个重载方法提供了一个简洁的 API:一个使用默认设置转换所有页面,另一个接受 ToImageOptions 对象和 PageSelection 参数来控制分辨率和页面范围。 有关完整的功能概述,请访问IronPDF for Java 文档。 完整的API参考,请参阅Java API参考。
除了基本的转换,IronPDF还支持HTML到PDF的渲染、自定义水印、背景和前景以及表单创建。 它还在Sonatype Maven中央仓库上发布Maven工件,因此依赖管理遵循标准的Maven或Gradle工作流程。
开始之前我需要哪些先决条件?
在开始之前,请确认已准备好以下内容:
- Java已安装,并在环境变量中设置了路径。 请参阅官方Java 安装指南。
- 已安装Java IDE; Eclipse或IntelliJ都很好用。 下载Eclipse或IntelliJ IDEA。
- IDE中集成了Maven。请参阅此Maven设置教程。
- 许可证密钥已配置,在生产环境中部署之前。
如何安装 IronPDF for Java?
一旦所有先决条件就绪,安装就是一个单一的Maven依赖声明。 有关详细的设置步骤,请查阅入门文档。
打开JetBrains IntelliJ IDEA并创建一个新的Maven项目。
创建新的 Maven 项目
出现新窗口。 输入项目名称并单击完成。
新项目名称
点击"完成"后,新项目将打开,默认显示 pom.xml。 将以下依赖项添加到该文件。可选的SLF4J条目在开发过程中抑制日志噪声; 如果您的项目已经包含日志框架,请将其删除。
新项目:默认pom.xml
//:path=/static-assets/ironpdf-java/content-code-examples/how-to/java-pdf-to-image-tutorial/pom-dependencies.xml
<dependencies>
<dependency>
<groupId>com.ironsoftware</groupId>
<artifactId>ironpdf</artifactId>
<version>2024.9.1</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-simple</artifactId>
<version>1.7.36</version>
</dependency>
</dependencies>//:path=/static-assets/ironpdf-java/content-code-examples/how-to/java-pdf-to-image-tutorial/pom-dependencies.xml
<dependencies>
<dependency>
<groupId>com.ironsoftware</groupId>
<artifactId>ironpdf</artifactId>
<version>2024.9.1</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-simple</artifactId>
<version>1.7.36</version>
</dependency>
</dependencies>将依赖项添加到 pom.xml 后,编辑器右上角会出现一个 Maven 同步图标。
已添加Maven依赖项
点击同步图标以下载IronPDF JAR。 下载时间取决于连接速度,通常在两分钟内。 安装后,查看Java API参考以查看所有可用方法和配置选项。 对于云部署目标,IronPDF提供经过测试的指南,适用于AWS、Azure和Google Cloud。
如何使用 IronPDF 将 PDF 文件转换为图像?
在 PdfDocument 对象上调用 toBufferedImages 方法将生成一个 List<BufferedImage> 数组,其中每个元素对应一个 PDF 页面,且按页码升序排列。 然后可以将结果写入磁盘,传递给图像处理管道,或直接返回给Web响应。
IronPDF还能即时将URLs和HTML字符串转换为PDF,因此可以在没有单独渲染步骤的情况下,通过单一管道捕获任何网页或渲染的HTML文档为图像。
如何将现有 PDF 文档转换为图像?
toBufferedImages 接受一个可选的 ToImageOptions 参数用于控制输出尺寸,以及一个 PageSelection 参数用于定位特定页面。 当没有传递参数时,所有页面都会以其自然分辨率转换。
下面的示例将 PDF 的所有页面转换为 PNG 文件,并使用 ToImageOptions 将每张输出图像的尺寸限制为 800x500 像素:
//:path=/static-assets/ironpdf-java/content-code-examples/how-to/java-pdf-to-image-tutorial/convert-pdf-to-images.java
import com.ironsoftware.ironpdf.PdfDocument;
import com.ironsoftware.ironpdf.edit.PageSelection;
import com.ironsoftware.ironpdf.image.ToImageOptions;
import javax.imageio.ImageIO;
import java.awt.image.BufferedImage;
import java.io.File;
import java.io.IOException;
import java.nio.file.Paths;
import java.util.List;
public class Main {
public static void main(String[] args) throws IOException {
// Load the PDF document from disk
PdfDocument pdf = PdfDocument.fromFile(Paths.get("business_plan.pdf"));
// Configure output image dimensions
ToImageOptions options = new ToImageOptions();
options.setImageMaxHeight(800);
options.setImageMaxWidth(500);
// Convert all pages to BufferedImage objects with the configured dimensions
List<BufferedImage> pages = pdf.toBufferedImages(options, PageSelection.allPages());
// Write each page image to the assets/images folder (create the folder first)
int pageIndex = 1;
for (BufferedImage page : pages) {
String fileName = "assets/images/" + pageIndex++ + ".png";
ImageIO.write(page, "PNG", new File(fileName));
}
}
}//:path=/static-assets/ironpdf-java/content-code-examples/how-to/java-pdf-to-image-tutorial/convert-pdf-to-images.java
import com.ironsoftware.ironpdf.PdfDocument;
import com.ironsoftware.ironpdf.edit.PageSelection;
import com.ironsoftware.ironpdf.image.ToImageOptions;
import javax.imageio.ImageIO;
import java.awt.image.BufferedImage;
import java.io.File;
import java.io.IOException;
import java.nio.file.Paths;
import java.util.List;
public class Main {
public static void main(String[] args) throws IOException {
// Load the PDF document from disk
PdfDocument pdf = PdfDocument.fromFile(Paths.get("business_plan.pdf"));
// Configure output image dimensions
ToImageOptions options = new ToImageOptions();
options.setImageMaxHeight(800);
options.setImageMaxWidth(500);
// Convert all pages to BufferedImage objects with the configured dimensions
List<BufferedImage> pages = pdf.toBufferedImages(options, PageSelection.allPages());
// Write each page image to the assets/images folder (create the folder first)
int pageIndex = 1;
for (BufferedImage page : pages) {
String fileName = "assets/images/" + pageIndex++ + ".png";
ImageIO.write(page, "PNG", new File(fileName));
}
}
}输出图像将保存至 assets/images/ 目录,文件名采用数字命名格式,从 1 开始。 请在运行程序前创建该文件夹,因为 ImageIO.write 不会自动创建缺失的目录。 setImageMaxHeight 和 setImageMaxWidth 调用为每个维度设置了上限; IronPDF保留原始的纵横比,并不会拉伸图像。
ImageIO.write 中的格式字符串从 "PNG" 更改为 "JPEG",并相应更新文件扩展名。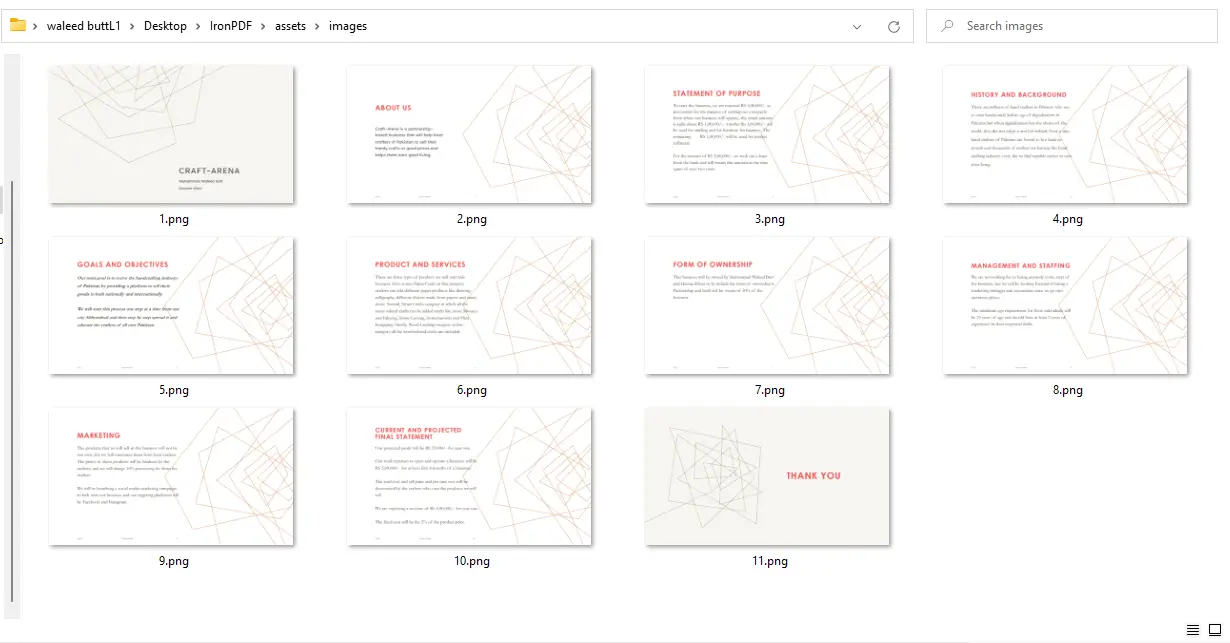
PDF到图像输出 - 11个PNG文件,每页一个
欲获得更多的转换示例,请访问PDF栅格化示例页面。
如何使用IronPDF将URL转换为图像?
PdfDocument.renderUrlAsPdf 获取 URL,通过内置的 Chromium 引擎进行渲染,并返回一个 PdfDocument,该对象可立即传递给 toBufferedImages。 这使得可以直接捕获任何公开可访问的网页为一系列图像。
下面的示例将一个亚马逊产品页面渲染为PDF,然后将每个生成的页面保存为PNG文件:
//:path=/static-assets/ironpdf-java/content-code-examples/how-to/java-pdf-to-image-tutorial/convert-url-to-images.java
import com.ironsoftware.ironpdf.PdfDocument;
import com.ironsoftware.ironpdf.edit.PageSelection;
import com.ironsoftware.ironpdf.image.ToImageOptions;
import javax.imageio.ImageIO;
import java.awt.image.BufferedImage;
import java.io.File;
import java.io.IOException;
import java.util.List;
public class Main {
public static void main(String[] args) throws IOException {
// Render a URL to a PDF document using the Chromium rendering engine
PdfDocument pdf = PdfDocument.renderUrlAsPdf("https://www.amazon.com");
// Configure output image dimensions
ToImageOptions options = new ToImageOptions();
options.setImageMaxHeight(800);
options.setImageMaxWidth(500);
// Convert all pages and write to disk
List<BufferedImage> pages = pdf.toBufferedImages(options, PageSelection.allPages());
int pageIndex = 1;
for (BufferedImage page : pages) {
String fileName = "assets/images/" + pageIndex++ + ".png";
ImageIO.write(page, "PNG", new File(fileName));
}
}
}//:path=/static-assets/ironpdf-java/content-code-examples/how-to/java-pdf-to-image-tutorial/convert-url-to-images.java
import com.ironsoftware.ironpdf.PdfDocument;
import com.ironsoftware.ironpdf.edit.PageSelection;
import com.ironsoftware.ironpdf.image.ToImageOptions;
import javax.imageio.ImageIO;
import java.awt.image.BufferedImage;
import java.io.File;
import java.io.IOException;
import java.util.List;
public class Main {
public static void main(String[] args) throws IOException {
// Render a URL to a PDF document using the Chromium rendering engine
PdfDocument pdf = PdfDocument.renderUrlAsPdf("https://www.amazon.com");
// Configure output image dimensions
ToImageOptions options = new ToImageOptions();
options.setImageMaxHeight(800);
options.setImageMaxWidth(500);
// Convert all pages and write to disk
List<BufferedImage> pages = pdf.toBufferedImages(options, PageSelection.allPages());
int pageIndex = 1;
for (BufferedImage page : pages) {
String fileName = "assets/images/" + pageIndex++ + ".png";
ImageIO.write(page, "PNG", new File(fileName));
}
}
}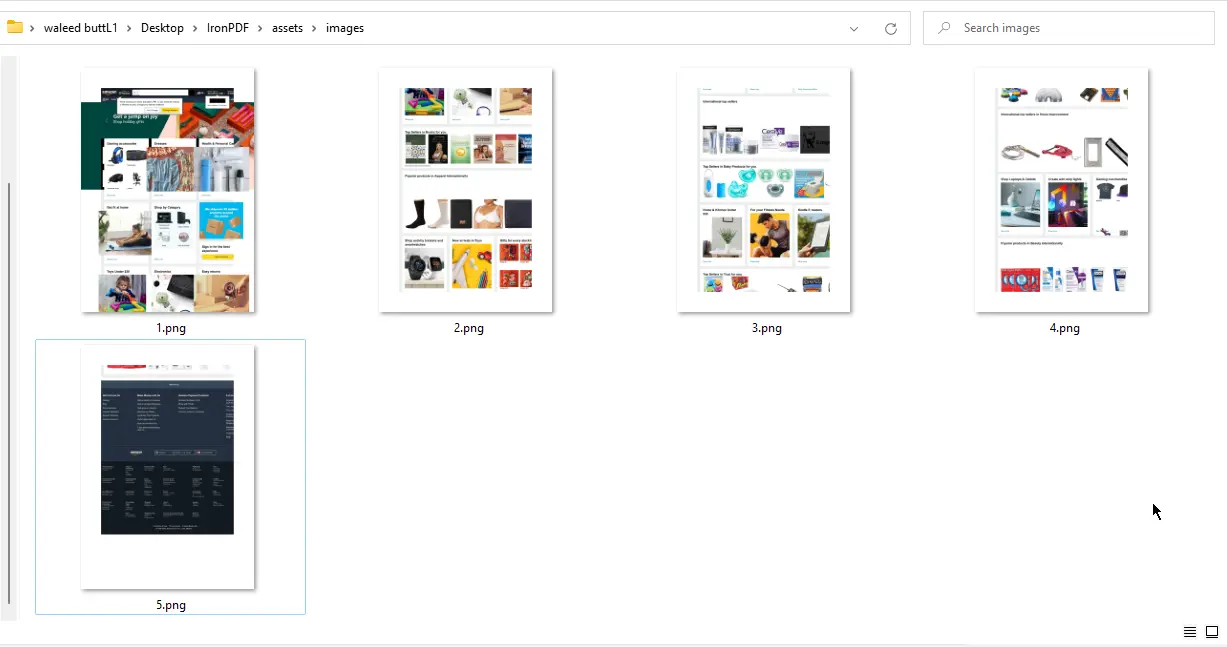
URL到图像输出 - 5个PNG文件
对于渲染前需认证或会话Cookie的页面,请参阅网站登录指南。
renderUrlAsPdf 的 Chromium 渲染引擎提供了与现代桌面浏览器相同的 CSS 和 JavaScript 支持。 依赖于客户端JavaScript加载内容的页面将正确呈现,包括单页应用程序。)}]如何将特定页面转换为图像?
PageSelection 提供了多种工厂方法,用于针对文档的子集而非整个文档进行操作。 这在只需提取封面、总结部分或已知页面范围时非常有用。
//:path=/static-assets/ironpdf-java/content-code-examples/how-to/java-pdf-to-image-tutorial/page-selection.java
import com.ironsoftware.ironpdf.PdfDocument;
import com.ironsoftware.ironpdf.edit.PageSelection;
import com.ironsoftware.ironpdf.image.ToImageOptions;
import javax.imageio.ImageIO;
import java.awt.image.BufferedImage;
import java.io.File;
import java.io.IOException;
import java.nio.file.Paths;
import java.util.List;
public class PageSelectionExample {
public static void main(String[] args) throws IOException {
PdfDocument pdf = PdfDocument.fromFile(Paths.get("report.pdf"));
ToImageOptions options = new ToImageOptions();
options.setImageMaxHeight(800);
options.setImageMaxWidth(500);
// Convert only the first page (page index is zero-based)
List<BufferedImage> coverPage = pdf.toBufferedImages(options, PageSelection.singlePage(0));
ImageIO.write(coverPage.get(0), "PNG", new File("cover.png"));
// Convert pages 2 through 5 (zero-based indices 1 through 4)
List<BufferedImage> excerpt = pdf.toBufferedImages(options, PageSelection.pageRange(1, 4));
for (int i = 0; i < excerpt.size(); i++) {
ImageIO.write(excerpt.get(i), "PNG", new File("excerpt_" + (i + 1) + ".png"));
}
}
}//:path=/static-assets/ironpdf-java/content-code-examples/how-to/java-pdf-to-image-tutorial/page-selection.java
import com.ironsoftware.ironpdf.PdfDocument;
import com.ironsoftware.ironpdf.edit.PageSelection;
import com.ironsoftware.ironpdf.image.ToImageOptions;
import javax.imageio.ImageIO;
import java.awt.image.BufferedImage;
import java.io.File;
import java.io.IOException;
import java.nio.file.Paths;
import java.util.List;
public class PageSelectionExample {
public static void main(String[] args) throws IOException {
PdfDocument pdf = PdfDocument.fromFile(Paths.get("report.pdf"));
ToImageOptions options = new ToImageOptions();
options.setImageMaxHeight(800);
options.setImageMaxWidth(500);
// Convert only the first page (page index is zero-based)
List<BufferedImage> coverPage = pdf.toBufferedImages(options, PageSelection.singlePage(0));
ImageIO.write(coverPage.get(0), "PNG", new File("cover.png"));
// Convert pages 2 through 5 (zero-based indices 1 through 4)
List<BufferedImage> excerpt = pdf.toBufferedImages(options, PageSelection.pageRange(1, 4));
for (int i = 0; i < excerpt.size(); i++) {
ImageIO.write(excerpt.get(i), "PNG", new File("excerpt_" + (i + 1) + ".png"));
}
}
}PageSelection.singlePage(0) 仅针对首页,这对于生成封面缩略图非常有用。 PageSelection.pageRange(1, 4) 使用从零开始的索引提取第 2 至第 5 页。 两者均返回 List<BufferedImage>,因此无论选中多少页,循环模式都是一致的。
PageSelection 中的页码采用从零开始的计数方式:第一页为 0,第二页为 1,依此类推。 传递超出范围的索引会在运行时引发 IndexOutOfBoundsException 异常。)]Java PDF到图像转换的下一步是什么?
本指南涵盖了三种常见模式:转换现有PDF的所有页面,将URL捕获为一组页面图像,以及提取目标页面范围。 IronPDF 通过 ToImageOptions 和 ImageIO 处理分辨率控制和格式选择,从而使调用代码简洁且易于预测。
要继续使用IronPDF for Java进行构建,请探索以下相关资源:
- Java栅格化示例 - 额外的PDF到图像代码示例
- 从PDF中提取图像和文本 - 从现有PDF文件中提取嵌入的图像
- 在Java中压缩PDF - 减小存储或传输前的文件大小
- 自定义水印 - 在保存前为输出图像或PDF添加水印
- IronPDF for Java文档 - 完整的API参考和设置指南
IronPDF for Java免费用于开发。 商业部署需要许可证。 开始您的免费试用或查看许可证选项以查看哪个计划适合您的项目。
准备看看IronPDF还能做些什么吗? 查看完整的IronPDF for Java教程页面。
常见问题解答
如何在 Java 中将 PDF 文件转换为 PNG 图像?
使用PdfDocument.fromFile()加载PDF,调用toBufferedImages()获取BufferedImage对象列表以代表每个页面,然后使用ImageIO.write()将每个图像保存为PNG文件。
在将PDF页面转换时支持哪些图像格式?
IronPDF的toBufferedImages方法返回BufferedImage对象。您可以保存这些对象为Java的ImageIO类支持的任何格式,包括PNG、JPEG和TIFF。
是否可以将PDF中仅特定的页面转换为图像?
可以。将PageSelection参数传递给toBufferedImages。使用PageSelection.singlePage(0)转换一个页面,或使用PageSelection.pageRange(1, 4)转换一个范围。页面索引是从零开始的。
在Java中,PDF转图像转换的常见用例是什么?
常见用例包括为文档管理系统生成缩略图预览,为Web应用程序生成页面级截图,提取用于演示的视觉内容,以及将不支持PDF渲染的系统中的文档归档为图像文件。
如何将 IronPDF 添加到我的 Maven 项目中?
在您的pom.xml的
我可以将URL直接转换为图像文件吗?
可以。调用PdfDocument.renderUrlAsPdf(url)使用内置的Chromium引擎渲染页面,然后将生成的PdfDocument传递给toBufferedImages来获取页面图像列表。
如何控制输出图像分辨率?
创建一个ToImageOptions实例,调用setImageMaxHeight()和setImageMaxWidth()设置最大尺寸,然后将其作为第一个参数传递给toBufferedImages。IronPDF保持纵横比,不会拉伸图像。


还在滚动吗?
想快速获得证据?
运行示例看着你的HTML代码变成PDF文件。













