


JavaのPDFから画像ファイルへ
IronPDFのtoBufferedImagesメソッドを使用して、JavaでPDF文書をJPEG、PNG、またはTIFFなどの画像形式に変換します。 PDF ファイルを読み込み、toBufferedImages を呼び出して BufferedImage オブジェクトのリストを取得し、ImageIO を使用して各画像をディスクに書き出します。 すべての変換は、10行未満の動作するJavaコードで済みます。
クイックスタート: Java で PDF を画像に変換する
1.MavenプロジェクトにIronPDF依存関係を追加してください: ```xml :title=pom.xml
2.PDF文書を読み込んでください:
```java
//:path=/static-assets/ironpdf-java/content-code-examples/how-to/java-pdf-to-image-tutorial/load-pdf.java
PdfDocument pdf = PdfDocument.fromFile(Paths.get("document.pdf"));3.画像に変換して保存してください:
//:path=/static-assets/ironpdf-java/content-code-examples/how-to/java-pdf-to-image-tutorial/convert-and-save.java
List<BufferedImage> images = pdf.toBufferedImages();
for (int i = 0; i < images.size(); i++) {
ImageIO.write(images.get(i), "PNG", new File("page_" + i + ".png"));
}//:path=/static-assets/ironpdf-java/content-code-examples/how-to/java-pdf-to-image-tutorial/convert-and-save.java
List<BufferedImage> images = pdf.toBufferedImages();
for (int i = 0; i < images.size(); i++) {
ImageIO.write(images.get(i), "PNG", new File("page_" + i + ".png"));
}JavaでPDFを画像に変換する方法
- IronPDF Java ライブラリをインストールする
- PDFファイルを
PdfDocument.fromFile()を使用して読み込みます toBufferedImages()を呼び出してListを取得します- 必要に応じて
ToImageOptionsで出力サイズを設定します ImageIO.write()を使用して各画像をディスクに書き込みます
PDFから画像への変換とは何ですか、なぜ必要なのですか?
PDFから画像への変換により、PDFドキュメントの各ページがJPEG、PNG、TIFFなどのスタンドアロンの画像ファイルに変換され、表示、埋め込み、またはPDFビューアなしで処理できます。 Javaの標準ライブラリにはこれを行うための組み込みのメカニズムはなく、ドキュメントプレビュー、サムネイル生成、アーカイブパイプラインを必要とする開発者にとって一貫した問題点です。
一般的な使用には、文書管理システムのためのサムネイルプレビューの生成、Webアプリケーションのためのページ単位のスクリーンショットの作成、レポートやプレゼンテーションのための視覚的コンテンツの抽出が含まれます。 IronPDFはすべてのレンダリングの複雑さを内部で処理するため、アプリケーションコードは短く保持され、ソースPDF内のフォント、ベクトルグラフィックス、フォームフィールドに関係なく、出力はピクセル精度で描画されます。 画像をPDFに挿入する逆操作については、画像からPDFへの変換ガイドを参照してください。
JavaのためのIronPDFとは何ですか、そしてそれはどのように役立ちますか?
IronPDF for Javaは、MavenベースのプロジェクトでPDFファイルを作成、読み取り、編集するためのライブラリです。 開発者はこれを使用して、HTMLからPDFを生成し、既存のドキュメントを修正し、サーバー上でAdobe AcrobatやPDFビューアなしでコンテンツを抽出します。
ライブラリはカスタムヘッダーとフッター、デジタル署名、フォーム作成、パスワード保護、マルチスレッドレンダリングをサポートしています。 そのPDFから画像への変換機能は、PageSelectionを受け取り、解像度とページ範囲を制御するものです。 完全な機能の概要については、IronPDF for Java ドキュメントを訪問してください。 完全なAPIリファレンスについては、Java API リファレンスを参照してください。
基本的な変換を超えて、IronPDFはHTMLからPDFレンダリング、カスタムウォーターマーク、背景と前景、およびフォームの作成をサポートしています。 また、Sonatype Maven CentralリポジトリにMavenアーティファクトを提供しているため、依存関係の管理は標準のMavenまたはGradleのワークフローに従います。
始める前に必要な前提条件はありますか?
開始する前に、以下が揃っていることを確認してください:
- 環境変数に設定されたパスを持つJavaがインストールされています。 公式のJavaインストールガイドをご覧ください。
- Java IDEがインストールされています; EclipseまたはIntelliJのどちらでもうまく動作します。 EclipseまたはIntelliJ IDEAをダウンロードします。
- IDEに統合されたMaven。IntelliJ用のこの<Mavenセットアップチュートリアルを参照してください。
- プロダクション環境へのデプロイ前にライセンスキーを構成します。
Java版IronPDFをインストールするには?
すべての前提条件が揃ったら、インストールは単一のMaven依存宣言です。 詳細なセットアップ手順については、入門ドキュメントを参照してください。
JetBrains IntelliJ IDEAを開いて、新しいMavenプロジェクトを作成します。
新しいMavenプロジェクトを作成する
新しいウィンドウが表示されます。 プロジェクト名を入力し、[完了]をクリックします。
新しいプロジェクト名
[完了] をクリックすると、新しいプロジェクトが開き、デフォルトで pom.xml が表示されます。 以下の依存関係をファイルに追加します。オプションのSLF4Jエントリは、開発中のロギングノイズを抑制します; プロジェクトで既にロギングフレームワークを含んでいる場合は削除してください。
新規プロジェクト: デフォルトpom.xml
//:path=/static-assets/ironpdf-java/content-code-examples/how-to/java-pdf-to-image-tutorial/pom-dependencies.xml
<dependencies>
<dependency>
<groupId>com.ironsoftware</groupId>
<artifactId>ironpdf</artifactId>
<version>2024.9.1</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-simple</artifactId>
<version>1.7.36</version>
</dependency>
</dependencies>//:path=/static-assets/ironpdf-java/content-code-examples/how-to/java-pdf-to-image-tutorial/pom-dependencies.xml
<dependencies>
<dependency>
<groupId>com.ironsoftware</groupId>
<artifactId>ironpdf</artifactId>
<version>2024.9.1</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-simple</artifactId>
<version>1.7.36</version>
</dependency>
</dependencies>pom.xmlに依存関係が追加されると、エディタの右上隅にMavenの同期アイコンが表示されます。
Maven依存関係が追加されました
同期アイコンをクリックしてIronPDF JARをダウンロードします。 ダウンロード時間は接続速度に依存し、通常2分未満です。 インストールの後、Java APIリファレンスをレビューして、利用可能なすべてのメソッドと設定オプションを確認します。 クラウドデプロイメントターゲットの場合、IronPDFはAWS、Azure、Google Cloudのテストガイドを提供します。
IronPDFを使ってPDFファイルを画像に変換するには?
toBufferedImages オブジェクトに対して PdfDocument を呼び出すと、List<BufferedImage> が生成されます。ここで、各要素はページ番号の昇順で PDF の 1 ページに対応しています。 結果はディスクに書き出すか、画像処理パイプラインに渡すか、ウェブレスポンスとして直接返すことができます。
IronPDFは、URLやHTMLストリングのPDF化もリアルタイムで行うため、別のレンダリングステップなしで、ウェブページやレンダリングしたHTMLドキュメントを画像としてキャプチャすることが可能です。
既存のPDFドキュメントを画像に変換するにはどうすればよいですか?
toBufferedImages は、出力の寸法を制御するためのオプションの ToImageOptions 引数と、特定のページをターゲットにするための PageSelection 引数を受け付けます。 引数が渡されない場合は、すべてのページがその自然な解像度で変換されます。
以下の例では、PDFの全ページをPNGファイルに変換し、ToImageOptions を使用して各出力画像のサイズを800x500ピクセルに制限しています:
//:path=/static-assets/ironpdf-java/content-code-examples/how-to/java-pdf-to-image-tutorial/convert-pdf-to-images.java
import com.ironsoftware.ironpdf.PdfDocument;
import com.ironsoftware.ironpdf.edit.PageSelection;
import com.ironsoftware.ironpdf.image.ToImageOptions;
import javax.imageio.ImageIO;
import java.awt.image.BufferedImage;
import java.io.File;
import java.io.IOException;
import java.nio.file.Paths;
import java.util.List;
public class Main {
public static void main(String[] args) throws IOException {
// Load the PDF document from disk
PdfDocument pdf = PdfDocument.fromFile(Paths.get("business_plan.pdf"));
// Configure output image dimensions
ToImageOptions options = new ToImageOptions();
options.setImageMaxHeight(800);
options.setImageMaxWidth(500);
// Convert all pages to BufferedImage objects with the configured dimensions
List<BufferedImage> pages = pdf.toBufferedImages(options, PageSelection.allPages());
// Write each page image to the assets/images folder (create the folder first)
int pageIndex = 1;
for (BufferedImage page : pages) {
String fileName = "assets/images/" + pageIndex++ + ".png";
ImageIO.write(page, "PNG", new File(fileName));
}
}
}//:path=/static-assets/ironpdf-java/content-code-examples/how-to/java-pdf-to-image-tutorial/convert-pdf-to-images.java
import com.ironsoftware.ironpdf.PdfDocument;
import com.ironsoftware.ironpdf.edit.PageSelection;
import com.ironsoftware.ironpdf.image.ToImageOptions;
import javax.imageio.ImageIO;
import java.awt.image.BufferedImage;
import java.io.File;
import java.io.IOException;
import java.nio.file.Paths;
import java.util.List;
public class Main {
public static void main(String[] args) throws IOException {
// Load the PDF document from disk
PdfDocument pdf = PdfDocument.fromFile(Paths.get("business_plan.pdf"));
// Configure output image dimensions
ToImageOptions options = new ToImageOptions();
options.setImageMaxHeight(800);
options.setImageMaxWidth(500);
// Convert all pages to BufferedImage objects with the configured dimensions
List<BufferedImage> pages = pdf.toBufferedImages(options, PageSelection.allPages());
// Write each page image to the assets/images folder (create the folder first)
int pageIndex = 1;
for (BufferedImage page : pages) {
String fileName = "assets/images/" + pageIndex++ + ".png";
ImageIO.write(page, "PNG", new File(fileName));
}
}
}出力画像は assets/images/ に保存され、ファイル名は 1 から始まる数字で構成されます。 ImageIO.writeは存在しないディレクトリを作成しないため、プログラムを実行する前にそのフォルダを作成してください。 setImageMaxHeight および setImageMaxWidth の呼び出しは、各次元の上限を設定します; IronPDFは元のアスペクト比を維持し、画像を歪ませません。
"JPEG"に変更し、ファイル拡張子もそれに応じて更新してください。
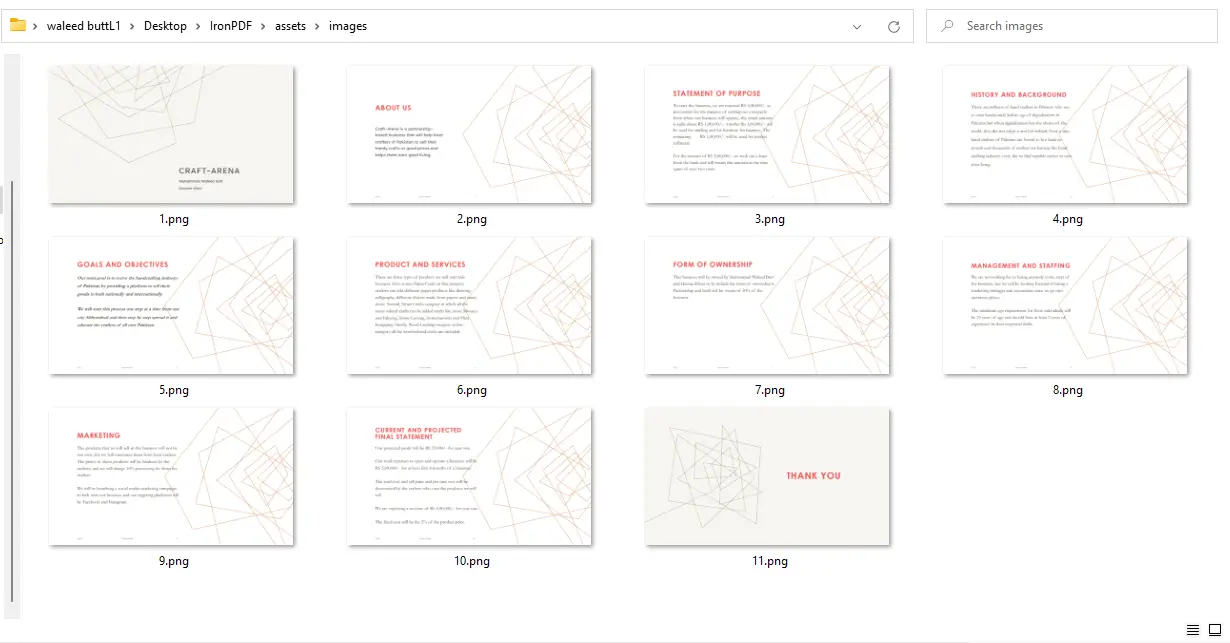
PDFから画像への出力 - 各ページごとに11のPNGファイル
詳細な変換例については、PDFラスター化例ページを訪れてください。
IronPDFを使用してURLを画像に変換するには?
PdfDocument.renderUrlAsPdf は URL を取得し、組み込みの Chromium エンジンでレンダリングして、PdfDocument を返します。この結果は、すぐに toBufferedImages に渡すことができます。 これにより、公開されているどのウェブページも一連の画像としてキャプチャすることが簡単になります。
以下の例では、Amazonの製品ページをレンダリングしてPDFにし、次に得られたページをPNGファイルとして保存します:
//:path=/static-assets/ironpdf-java/content-code-examples/how-to/java-pdf-to-image-tutorial/convert-url-to-images.java
import com.ironsoftware.ironpdf.PdfDocument;
import com.ironsoftware.ironpdf.edit.PageSelection;
import com.ironsoftware.ironpdf.image.ToImageOptions;
import javax.imageio.ImageIO;
import java.awt.image.BufferedImage;
import java.io.File;
import java.io.IOException;
import java.util.List;
public class Main {
public static void main(String[] args) throws IOException {
// Render a URL to a PDF document using the Chromium rendering engine
PdfDocument pdf = PdfDocument.renderUrlAsPdf("https://www.amazon.com");
// Configure output image dimensions
ToImageOptions options = new ToImageOptions();
options.setImageMaxHeight(800);
options.setImageMaxWidth(500);
// Convert all pages and write to disk
List<BufferedImage> pages = pdf.toBufferedImages(options, PageSelection.allPages());
int pageIndex = 1;
for (BufferedImage page : pages) {
String fileName = "assets/images/" + pageIndex++ + ".png";
ImageIO.write(page, "PNG", new File(fileName));
}
}
}//:path=/static-assets/ironpdf-java/content-code-examples/how-to/java-pdf-to-image-tutorial/convert-url-to-images.java
import com.ironsoftware.ironpdf.PdfDocument;
import com.ironsoftware.ironpdf.edit.PageSelection;
import com.ironsoftware.ironpdf.image.ToImageOptions;
import javax.imageio.ImageIO;
import java.awt.image.BufferedImage;
import java.io.File;
import java.io.IOException;
import java.util.List;
public class Main {
public static void main(String[] args) throws IOException {
// Render a URL to a PDF document using the Chromium rendering engine
PdfDocument pdf = PdfDocument.renderUrlAsPdf("https://www.amazon.com");
// Configure output image dimensions
ToImageOptions options = new ToImageOptions();
options.setImageMaxHeight(800);
options.setImageMaxWidth(500);
// Convert all pages and write to disk
List<BufferedImage> pages = pdf.toBufferedImages(options, PageSelection.allPages());
int pageIndex = 1;
for (BufferedImage page : pages) {
String fileName = "assets/images/" + pageIndex++ + ".png";
ImageIO.write(page, "PNG", new File(fileName));
}
}
}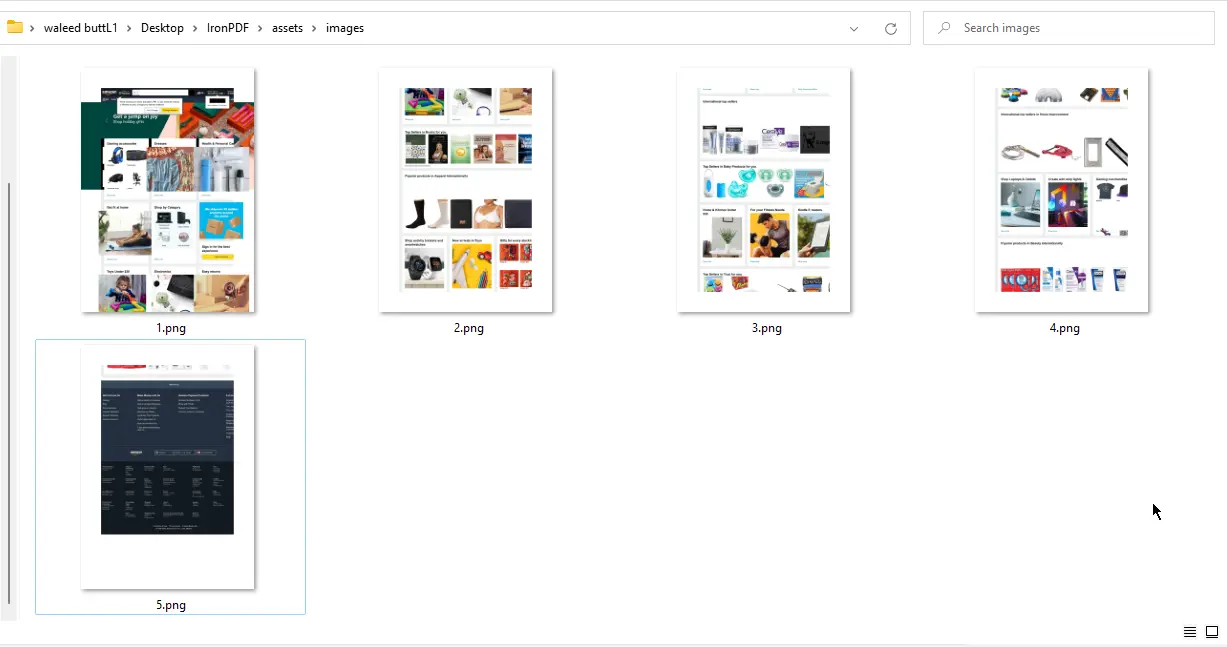
URLから画像への出力 - 5つのPNGファイル
レンダリング前に認証やセッションクッキーが必要なページについては、ウェブサイトログインガイドをご参照ください。
renderUrlAsPdf を駆動する Chromium レンダリングエンジンは、最新のデスクトップブラウザと同様の CSS および JavaScript サポートを提供します。 クライアントサイド for JavaScriptに依存してコンテンツをロードするページも、単一ページアプリケーションを含め、正しくレンダリングされます。)}]特定のページを画像に変換するにはどうすればよいですか?
PageSelection は、ドキュメント全体ではなく、ページのサブセットを対象とするためのいくつかのファクトリメソッドを提供します。 カバーページ、要約セクション、または既知のページ範囲を抽出する際に有用です。
//:path=/static-assets/ironpdf-java/content-code-examples/how-to/java-pdf-to-image-tutorial/page-selection.java
import com.ironsoftware.ironpdf.PdfDocument;
import com.ironsoftware.ironpdf.edit.PageSelection;
import com.ironsoftware.ironpdf.image.ToImageOptions;
import javax.imageio.ImageIO;
import java.awt.image.BufferedImage;
import java.io.File;
import java.io.IOException;
import java.nio.file.Paths;
import java.util.List;
public class PageSelectionExample {
public static void main(String[] args) throws IOException {
PdfDocument pdf = PdfDocument.fromFile(Paths.get("report.pdf"));
ToImageOptions options = new ToImageOptions();
options.setImageMaxHeight(800);
options.setImageMaxWidth(500);
// Convert only the first page (page index is zero-based)
List<BufferedImage> coverPage = pdf.toBufferedImages(options, PageSelection.singlePage(0));
ImageIO.write(coverPage.get(0), "PNG", new File("cover.png"));
// Convert pages 2 through 5 (zero-based indices 1 through 4)
List<BufferedImage> excerpt = pdf.toBufferedImages(options, PageSelection.pageRange(1, 4));
for (int i = 0; i < excerpt.size(); i++) {
ImageIO.write(excerpt.get(i), "PNG", new File("excerpt_" + (i + 1) + ".png"));
}
}
}//:path=/static-assets/ironpdf-java/content-code-examples/how-to/java-pdf-to-image-tutorial/page-selection.java
import com.ironsoftware.ironpdf.PdfDocument;
import com.ironsoftware.ironpdf.edit.PageSelection;
import com.ironsoftware.ironpdf.image.ToImageOptions;
import javax.imageio.ImageIO;
import java.awt.image.BufferedImage;
import java.io.File;
import java.io.IOException;
import java.nio.file.Paths;
import java.util.List;
public class PageSelectionExample {
public static void main(String[] args) throws IOException {
PdfDocument pdf = PdfDocument.fromFile(Paths.get("report.pdf"));
ToImageOptions options = new ToImageOptions();
options.setImageMaxHeight(800);
options.setImageMaxWidth(500);
// Convert only the first page (page index is zero-based)
List<BufferedImage> coverPage = pdf.toBufferedImages(options, PageSelection.singlePage(0));
ImageIO.write(coverPage.get(0), "PNG", new File("cover.png"));
// Convert pages 2 through 5 (zero-based indices 1 through 4)
List<BufferedImage> excerpt = pdf.toBufferedImages(options, PageSelection.pageRange(1, 4));
for (int i = 0; i < excerpt.size(); i++) {
ImageIO.write(excerpt.get(i), "PNG", new File("excerpt_" + (i + 1) + ".png"));
}
}
}PageSelection.singlePage(0) は最初のページのみを対象としており、表紙のサムネイル生成に役立ちます。 PageSelection.pageRange(1, 4) は、0 から始まるインデックスを使用して 2 ページ目から 5 ページ目までを抽出します。 どちらも List<BufferedImage> を返すため、選択したページ数にかかわらずループパターンは同一です。
PageSelection 内のページインデックスは 0 から始まります。最初のページは 0、2 ページ目は 1 となります。 範囲外のインデックスを指定すると、実行時に IndexOutOfBoundsException 例外が発生します。)}]JavaでPDFから画像への変換の次のステップは何ですか?
このガイドでは、既存のPDFのすべてのページを変換する、URLをページ画像のセットとしてキャプチャする、特定のページ範囲を抽出する、の3つの一般的なパターンを紹介しました。 IronPDFは、ImageIOを通じて解像度の制御と形式の選択を処理し、呼び出し側のコードを簡潔かつ予測可能なものに保ちます。
JavaでIronPDFを使って構築を続けるには、これらの関連リソースを探検してください:
- Javaラスター化例 - 追加のPDFから画像へのコードサンプル
- PDFから画像とテキストを抽出 - 既存のPDFファイルから埋め込まれた画像を引き出す
- JavaでのPDF圧縮 - 保存や伝送前にファイルサイズを削減
- カスタムウォーターマーク - 保存前に出力画像やPDFにウォーターマークをスタンプする
- IronPDF for Javaドキュメント - 完全なAPIリファレンスとセットアップガイド
IronPDF for Java は開発用には無料です。 商用デプロイメントにはライセンスが必要です。 無料トライアルを始めるまたはライセンスオプションを表示することで、あなたのプロジェクトに合ったプランを見つけてください。
IronPDFの他の機能をご覧になりたいですか? IronPDF for Javaチュートリアルページをぜひチェックしてください。
よくある質問
JavaでPDFファイルをPNG画像に変換するには?
PdfDocument.fromFile()でPDFをロードし、toBufferedImages()を呼び出して、各ページを表すBufferedImageオブジェクトのリストを取得し、ImageIO.write()を使用して各画像をPNGファイルとして保存します。
PDFページの変換時にサポートされる画像形式は何ですか?
IronPDFのtoBufferedImagesメソッドはBufferedImageオブジェクトを返します。これらは、JavaのImageIOクラスがサポートする任意の形式(PNG、JPEG、TIFFなど)で保存できます。
PDFの特定のページだけを画像に変換できますか?
はい。toBufferedImagesにPageSelection引数を渡します。PageSelection.singlePage(0)を使用して1ページを変換し、PageSelection.pageRange(1, 4)を使用して範囲を変換します。ページインデックスはゼロベースです。
JavaでPDFから画像への変換の一般的な使用例は何ですか?
一般的な使用例には、ドキュメント管理システムのためのサムネイルプレビューの生成、ウェブアプリケーション用のページレベルのスクリーンショットの制作、プレゼンテーション用のビジュアルコンテンツの抽出、PDFレンダリングをサポートしないシステム用にドキュメントを画像ファイルとしてアーカイブすることが含まれます。
MavenプロジェクトにIronPDFを追加するには?
次の依存関係をpom.xmlの
URLを直接画像ファイルに変換できますか?
はい。PdfDocument.renderUrlAsPdf(url)を呼び出して、組み込みのChromiumエンジンを使用してページをレンダリングし、その後toBufferedImagesに結果のPdfDocumentを渡してページの画像リストを取得します。
出力画像の解像度を制御する方法は?
ToImageOptionsインスタンスを作成し、setImageMaxHeight()とsetImageMaxWidth()を呼び出して最大寸法を設定し、toBufferedImagesの最初の引数として渡します。IronPDFはアスペクト比を保持し、画像を引き伸ばしません。


まだスクロールしていますか?
すぐに証拠が欲しいですか?
サンプルを実行するHTML が PDF に変換されるのを確認します。













