


Java를 사용하여 PDF를 이미지 파일로 변환
Java에서 IronPDF의 toBufferedImages 메소드를 사용하여 PDF 문서를 JPEG, PNG 또는 TIFF와 같은 이미지 형식으로 변환하십시오. PDF 파일을 로드하고 toBufferedImages 를 호출하여 리스트의 BufferedImage 객체를 가져온 다음 ImageIO 를 사용하여 각 이미지를 디스크에 작성하십시오. 전체 변환은 10줄 이하의 작업 Java 코드로 가능합니다.
빠른 시작: Java에서 PDF를 이미지로 변환
-
Maven 프로젝트에 IronPDF 종속성을 추가하세요. ```xml :title=pom.xml
com.ironsoftware ironpdf 2024.9.1 -
PDF 문서를 불러오세요:
//:path=/static-assets/ironpdf-java/content-code-examples/how-to/java-pdf-to-image-tutorial/load-pdf.java PdfDocument pdf = PdfDocument.fromFile(Paths.get("document.pdf"));//:path=/static-assets/ironpdf-java/content-code-examples/how-to/java-pdf-to-image-tutorial/load-pdf.java PdfDocument pdf = PdfDocument.fromFile(Paths.get("document.pdf"));JAVA - 이미지로 변환하여 저장하세요:
//:path=/static-assets/ironpdf-java/content-code-examples/how-to/java-pdf-to-image-tutorial/convert-and-save.java List<BufferedImage> images = pdf.toBufferedImages(); for (int i = 0; i < images.size(); i++) { ImageIO.write(images.get(i), "PNG", new File("page_" + i + ".png")); }//:path=/static-assets/ironpdf-java/content-code-examples/how-to/java-pdf-to-image-tutorial/convert-and-save.java List<BufferedImage> images = pdf.toBufferedImages(); for (int i = 0; i < images.size(); i++) { ImageIO.write(images.get(i), "PNG", new File("page_" + i + ".png")); }JAVA
자바를 이용하여 PDF 파일을 이미지 파일로 변환하는 방법
- IronPDF Java 라이브러리 설치
- PDF 파일을
PdfDocument.fromFile()을 사용하여 로드 toBufferedImages()를 호출하여List<BufferedImage>를 얻습니다.- 필요 시
ToImageOptions로 출력 크기 설정 ImageIO.write()를 사용하여 각 이미지를 디스크에 씁니다.
PDF를 이미지로 변환하는 것은 무엇이며 왜 필요한가요?
PDF를 이미지로 변환하면 PDF 문서의 각 페이지가 독립적인 이미지 파일(JPEG, PNG, TIFF)로 변환되어 PDF 뷰어 없이 표시, 포함 또는 처리할 수 있습니다. Java의 표준 라이브러리에는 이를 위한 내장 메커니즘이 없으므로, 문서 미리 보기, 축소판 생성기 또는 아카이브 파이프라인이 필요한 개발자에게 지속적인 골칫거리가 됩니다.
일반적인 사용 사례로는 문서 관리 시스템의 축소판 미리 보기 생성, 웹 응용 프로그램을 위한 페이지 수준 스크린샷 생성, 보고서 또는 프레젠테이션을 위한 시각적 콘텐츠 추출 등이 있습니다. IronPDF는 모든 렌더링 복잡성을 내부적으로 처리하므로, 응용 프로그램 코드가 짧고 출력이 글꼴, 벡터 그래픽 또는 소스 PDF의 양식 필드에 관계없이 픽셀 정확도를 유지합니다. PDF에 이미지를 삽입하는 반대 작업의 경우, 이미지를 PDF로 변환하는 방법 가이드를 참조하십시오.
IronPDF for Java란 무엇이며 어떻게 도움이 될까요?
IronPDF for Java는 Maven 기반 프로젝트에서 PDF 파일을 생성, 읽기 및 편집하기 위한 라이브러리입니다. 개발자들은 이를 사용하여 HTML에서 PDF를 생성하고, 기존 문서를 수정하며 서버에 Adobe Acrobat 또는 PDF 뷰어를 설치하지 않고 콘텐츠를 추출할 수 있습니다.
라이브러리는 사용자 정의 헤더 및 풋터, 디지털 서명, 양식 작성, 비밀번호 보호 및 멀티스레드 렌더링을 지원합니다. PDF-이미지로의 기능은 기본 설정으로 모든 페이지를 변환하는 것과 해상도 및 페이지 범위를 제어하기 위해 ToImageOptions 객체와 PageSelection 를 받는 두 가지 toBufferedImages의 오버로드를 통해 깨끗한 API를 제공합니다. 모든 기능 개요는 IronPDF for Java 문서를 방문하십시오. 전체 API 참조는 Java API 참조를 참조하십시오.
기본 변환 이상의 기능으로, IronPDF는 HTML을 PDF로 렌더링, 사용자 정의 워터마크, 배경 및 전경, 그리고 양식 생성을 지원합니다. 또한 Sonatype Maven Central 저장소에 Maven 아티팩트를 제공하므로, 종속성 관리는 표준 Maven 또는 Gradle 워크플로우를 따릅니다.
시작하기 전에 필요한 사전 준비 사항은 무엇인가요?
시작하기 전에 다음 조건이 충족되었는지 확인하십시오:
- Java가 설치되고 '환경 변수'에 경로가 설정됨. 공식 Java 설치 가이드를 참조하십시오.
- Java IDE가 설치됨; Eclipse 또는 IntelliJ 모두 잘 작동합니다. Eclipse 또는 IntelliJ IDEA를 다운로드하십시오.
- IDE와 통합된 Maven. IntelliJ를 위한 이 Maven 설정 튜토리얼을 참조하십시오.
- 운영 환경에 배포하기 전에 라이선스 키 구성.
Java용 IronPDF 어떻게 설치하나요?
모든 사전 요구사항이 충족되면, 설치는 단일 Maven 종속성 선언입니다. 자세한 설정 단계는 시작 가이드 문서를 참조하십시오.
JetBrains IntelliJ IDEA를 열고 새 Maven 프로젝트를 생성하세요.
새로운 Maven 프로젝트를 생성하세요
새 창이 나타납니다. 프로젝트 이름을 입력하고 마침을 클릭하세요.
새 프로젝트 이름
마침을 클릭하면 기본적으로 pom.xml 가 표시된 새 프로젝트가 열립니다. 해당 파일에 다음 종속성을 추가하십시오. 선택적으로 SLF4J 항목은 개발 중 로깅 소음을 억제합니다; 프로젝트에 이미 로깅 프레임워크가 포함된 경우 이를 제거하십시오.
새 프로젝트: 기본 pom.xml
//:path=/static-assets/ironpdf-java/content-code-examples/how-to/java-pdf-to-image-tutorial/pom-dependencies.xml
<dependencies>
<dependency>
<groupId>com.ironsoftware</groupId>
<artifactId>ironpdf</artifactId>
<version>2024.9.1</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-simple</artifactId>
<version>1.7.36</version>
</dependency>
</dependencies>//:path=/static-assets/ironpdf-java/content-code-examples/how-to/java-pdf-to-image-tutorial/pom-dependencies.xml
<dependencies>
<dependency>
<groupId>com.ironsoftware</groupId>
<artifactId>ironpdf</artifactId>
<version>2024.9.1</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-simple</artifactId>
<version>1.7.36</version>
</dependency>
</dependencies>의존성이 pom.xml 에 추가되면 편집기의 오른쪽 상단에 Maven 동기화 아이콘이 나타납니다.
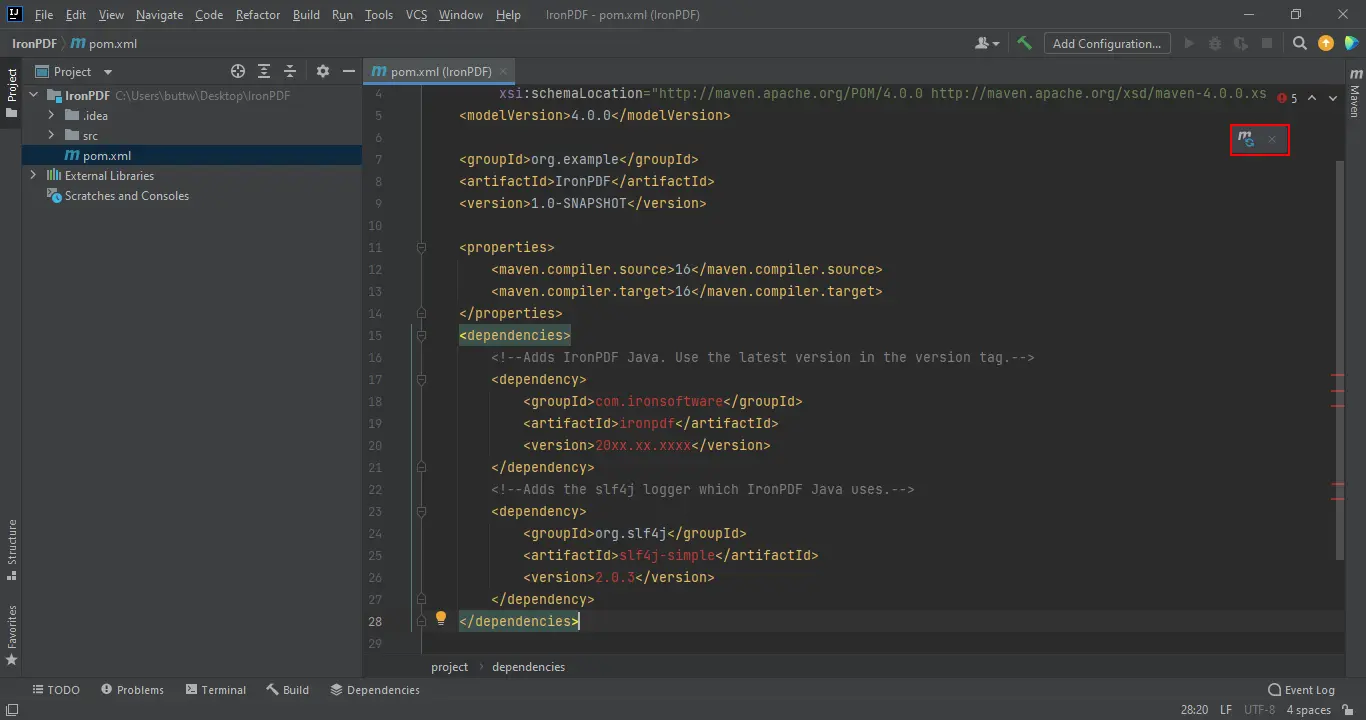
Maven 종속성 추가됨
동기화 아이콘을 클릭하여 IronPDF JAR을 다운로드하십시오. 다운로드 시간은 연결 속도에 따라 다르며, 일반적으로 2분 이내입니다. 설치 후, 사용 가능한 모든 메서드 및 구성 옵션을 보려면 Java API 참조를 검토하십시오. 클라우드 배포 대상의 경우, IronPDF는 AWS, Azure, 및 Google Cloud에 대한 테스트 된 가이드를 제공합니다.
이 종류의 라이브러리 중 가장 좋아하는 것은 IronPDF입니다. PDF 파일을 빠르고 효율적으로 조작할 수 있습니다. 또한 PDF/A 형식으로 내보내기 및 PDF 문서의 디지털 서명과 같은 많은 유용한 기능을 가지고 있습니다.
IronPDF 사용하여 PDF 파일을 이미지로 변환하는 방법은 무엇인가요?
PdfDocument 객체에 대해 toBufferedImages 를 호출하면 각 요소가 오름차순 페이지 번호 순서로 하나의 PDF 페이지에 해당하는 List<BufferedImage> 가 생성됩니다. 그 후 결과를 디스크에 쓸 수 있고, 이미지 처리 파이프라인으로 전달하거나 웹 응답으로 직접 반환할 수 있습니다.
IronPDF는 URL 및 HTML 문자열을 PDF로 실시간 변환하므로 별도의 렌더링 단계 없이 단일 파이프라인으로 모든 웹 페이지나 렌더링 된 HTML 문서를 이미지로 캡처할 수 있습니다.
기존 PDF 문서를 이미지로 변환하는 방법은 무엇인가요?
toBufferedImages 는 출력 차원을 제어하기 위한 선택적 ToImageOptions 인수와 특정 페이지를 대상으로 하는 PageSelection 인수를 받습니다. 인수를 제공하지 않으면 모든 페이지가 자연 해상도로 변환됩니다.
아래 예제는 모든 PDF 페이지를 PNG 파일로 변환하며, ToImageOptions 를 사용하여 각 출력 이미지를 800x500 픽셀로 제한합니다:
//:path=/static-assets/ironpdf-java/content-code-examples/how-to/java-pdf-to-image-tutorial/convert-pdf-to-images.java
import com.ironsoftware.ironpdf.PdfDocument;
import com.ironsoftware.ironpdf.edit.PageSelection;
import com.ironsoftware.ironpdf.image.ToImageOptions;
import javax.imageio.ImageIO;
import java.awt.image.BufferedImage;
import java.io.File;
import java.io.IOException;
import java.nio.file.Paths;
import java.util.List;
public class Main {
public static void main(String[] args) throws IOException {
// Load the PDF document from disk
PdfDocument pdf = PdfDocument.fromFile(Paths.get("business_plan.pdf"));
// Configure output image dimensions
ToImageOptions options = new ToImageOptions();
options.setImageMaxHeight(800);
options.setImageMaxWidth(500);
// Convert all pages to BufferedImage objects with the configured dimensions
List<BufferedImage> pages = pdf.toBufferedImages(options, PageSelection.allPages());
// Write each page image to the assets/images folder (create the folder first)
int pageIndex = 1;
for (BufferedImage page : pages) {
String fileName = "assets/images/" + pageIndex++ + ".png";
ImageIO.write(page, "PNG", new File(fileName));
}
}
}//:path=/static-assets/ironpdf-java/content-code-examples/how-to/java-pdf-to-image-tutorial/convert-pdf-to-images.java
import com.ironsoftware.ironpdf.PdfDocument;
import com.ironsoftware.ironpdf.edit.PageSelection;
import com.ironsoftware.ironpdf.image.ToImageOptions;
import javax.imageio.ImageIO;
import java.awt.image.BufferedImage;
import java.io.File;
import java.io.IOException;
import java.nio.file.Paths;
import java.util.List;
public class Main {
public static void main(String[] args) throws IOException {
// Load the PDF document from disk
PdfDocument pdf = PdfDocument.fromFile(Paths.get("business_plan.pdf"));
// Configure output image dimensions
ToImageOptions options = new ToImageOptions();
options.setImageMaxHeight(800);
options.setImageMaxWidth(500);
// Convert all pages to BufferedImage objects with the configured dimensions
List<BufferedImage> pages = pdf.toBufferedImages(options, PageSelection.allPages());
// Write each page image to the assets/images folder (create the folder first)
int pageIndex = 1;
for (BufferedImage page : pages) {
String fileName = "assets/images/" + pageIndex++ + ".png";
ImageIO.write(page, "PNG", new File(fileName));
}
}
}출력 이미지는 assets/images/ 에 숫자 파일명으로 저장되며 1 부터 시작합니다. 프로그램 실행 전에 해당 폴더를 생성하세요. ImageIO.write 는 누락된 디렉터리를 생성하지 않습니다. setImageMaxHeight 와 setImageMaxWidth 호출은 각각의 차원에 대한 상한선을 설정합니다; IronPDF는 원래의 종횡비를 유지하고 이미지를 늘리지 않습니다.
ImageIO.write 의 형식 문자열을 "PNG" 에서 "JPEG" 로 변경하고 파일 확장자를 적절하게 업데이트하십시오.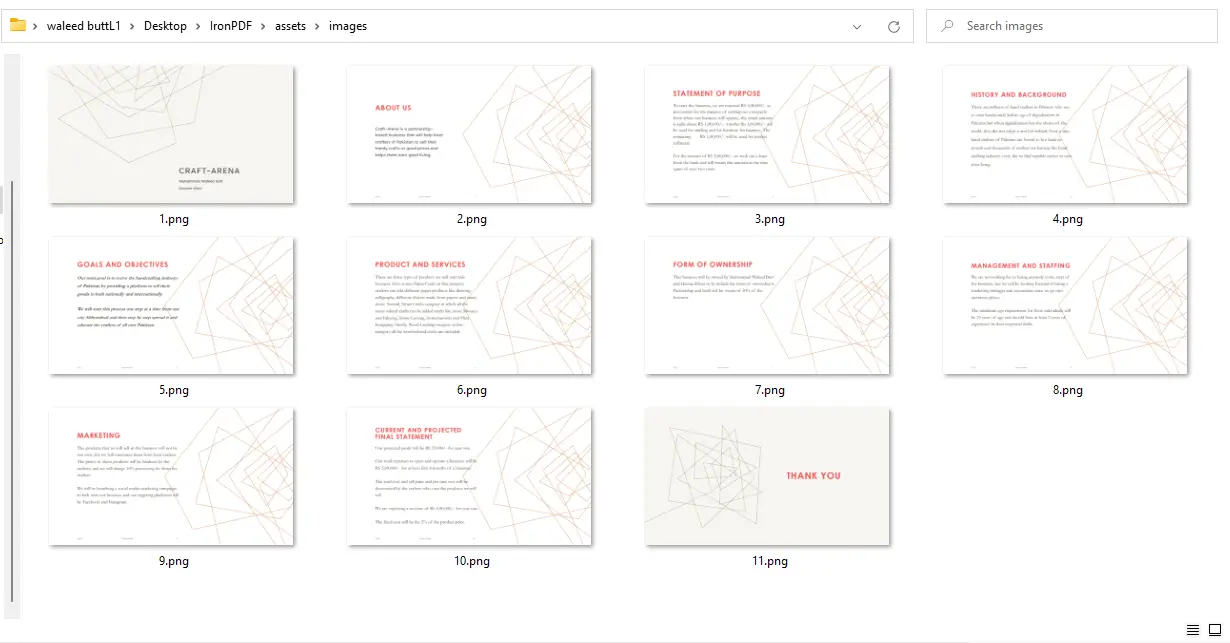
PDF에서 이미지로 변환 출력 - 페이지 당 하나의 PNG 파일 11개
추가 변환 예제는 PDF 래스터화 예제 페이지를 방문하십시오.
IronPDF로 URL을 이미지로 변환하는 방법은?
PdfDocument.renderUrlAsPdf 는 URL을 가져와 내장된 Chromium 엔진으로 렌더링하고 PdfDocument 를 반환하여 즉시 toBufferedImages 에 전달할 수 있습니다. 이를 통해 공개적으로 접근 가능한 웹 페이지를 이미지 시리즈로 캡처하기가 간편해집니다.
아래 예제는 Amazon 제품 페이지를 PDF로 렌더링 한 다음, 각 결과 페이지를 PNG 파일로 저장합니다:
//:path=/static-assets/ironpdf-java/content-code-examples/how-to/java-pdf-to-image-tutorial/convert-url-to-images.java
import com.ironsoftware.ironpdf.PdfDocument;
import com.ironsoftware.ironpdf.edit.PageSelection;
import com.ironsoftware.ironpdf.image.ToImageOptions;
import javax.imageio.ImageIO;
import java.awt.image.BufferedImage;
import java.io.File;
import java.io.IOException;
import java.util.List;
public class Main {
public static void main(String[] args) throws IOException {
// Render a URL to a PDF document using the Chromium rendering engine
PdfDocument pdf = PdfDocument.renderUrlAsPdf("https://www.amazon.com");
// Configure output image dimensions
ToImageOptions options = new ToImageOptions();
options.setImageMaxHeight(800);
options.setImageMaxWidth(500);
// Convert all pages and write to disk
List<BufferedImage> pages = pdf.toBufferedImages(options, PageSelection.allPages());
int pageIndex = 1;
for (BufferedImage page : pages) {
String fileName = "assets/images/" + pageIndex++ + ".png";
ImageIO.write(page, "PNG", new File(fileName));
}
}
}//:path=/static-assets/ironpdf-java/content-code-examples/how-to/java-pdf-to-image-tutorial/convert-url-to-images.java
import com.ironsoftware.ironpdf.PdfDocument;
import com.ironsoftware.ironpdf.edit.PageSelection;
import com.ironsoftware.ironpdf.image.ToImageOptions;
import javax.imageio.ImageIO;
import java.awt.image.BufferedImage;
import java.io.File;
import java.io.IOException;
import java.util.List;
public class Main {
public static void main(String[] args) throws IOException {
// Render a URL to a PDF document using the Chromium rendering engine
PdfDocument pdf = PdfDocument.renderUrlAsPdf("https://www.amazon.com");
// Configure output image dimensions
ToImageOptions options = new ToImageOptions();
options.setImageMaxHeight(800);
options.setImageMaxWidth(500);
// Convert all pages and write to disk
List<BufferedImage> pages = pdf.toBufferedImages(options, PageSelection.allPages());
int pageIndex = 1;
for (BufferedImage page : pages) {
String fileName = "assets/images/" + pageIndex++ + ".png";
ImageIO.write(page, "PNG", new File(fileName));
}
}
}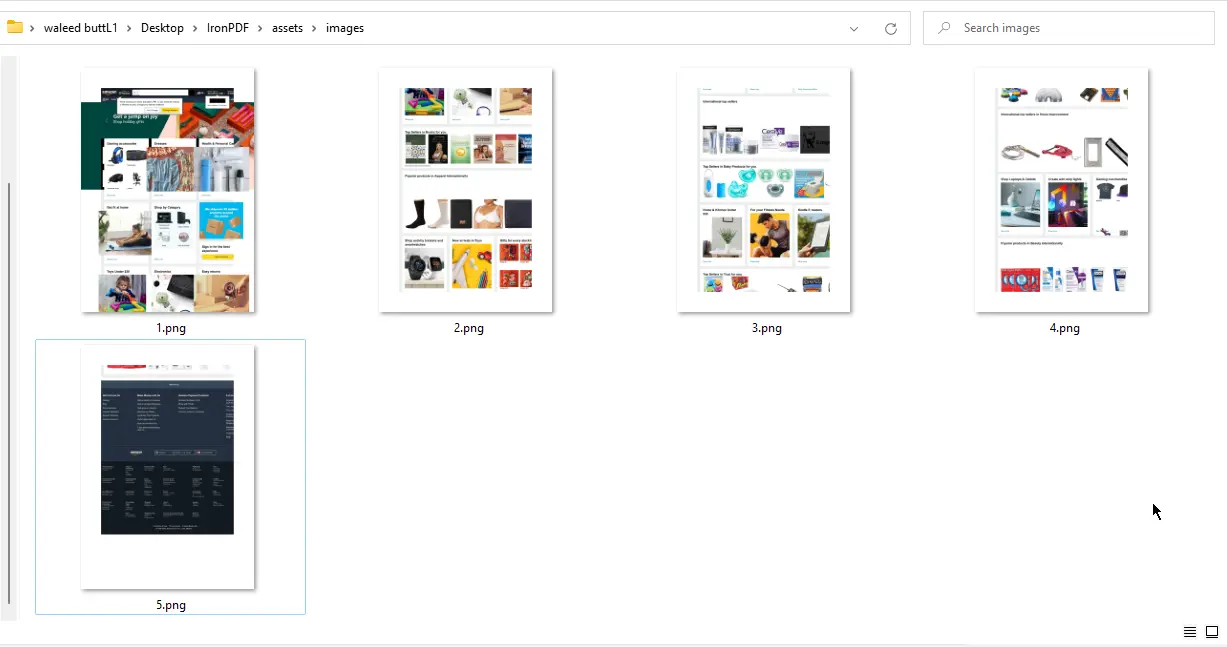
URL에서 이미지로 변환 출력 - PNG 파일 5개
렌더링 전에 인증이나 세션 쿠키가 필요한 페이지에 대해서는 웹사이트 로그인 가이드를 참조하십시오.
renderUrlAsPdf 의 Chromium 렌더링 엔진은 최신 데스크톱 브라우저와 동일한 CSS 및 JavaScript 지원을 적용합니다. 클라이언트 측 JavaScript를 사용하여 콘텐츠를 로드하는 페이지는 단일 페이지 응용 프로그램을 포함하여 올바르게 렌더링됩니다.특정 페이지를 이미지로 변환하는 방법은 무엇인가요?
PageSelection 는 전체 문서가 아닌 특정 페이지 하위 집합을 대상으로 하는 여러 팩토리 메소드를 제공합니다. 표지 페이지, 요약 섹션 또는 알려진 페이지 범위만 추출해야 할 때 유용합니다.
//:path=/static-assets/ironpdf-java/content-code-examples/how-to/java-pdf-to-image-tutorial/page-selection.java
import com.ironsoftware.ironpdf.PdfDocument;
import com.ironsoftware.ironpdf.edit.PageSelection;
import com.ironsoftware.ironpdf.image.ToImageOptions;
import javax.imageio.ImageIO;
import java.awt.image.BufferedImage;
import java.io.File;
import java.io.IOException;
import java.nio.file.Paths;
import java.util.List;
public class PageSelectionExample {
public static void main(String[] args) throws IOException {
PdfDocument pdf = PdfDocument.fromFile(Paths.get("report.pdf"));
ToImageOptions options = new ToImageOptions();
options.setImageMaxHeight(800);
options.setImageMaxWidth(500);
// Convert only the first page (page index is zero-based)
List<BufferedImage> coverPage = pdf.toBufferedImages(options, PageSelection.singlePage(0));
ImageIO.write(coverPage.get(0), "PNG", new File("cover.png"));
// Convert pages 2 through 5 (zero-based indices 1 through 4)
List<BufferedImage> excerpt = pdf.toBufferedImages(options, PageSelection.pageRange(1, 4));
for (int i = 0; i < excerpt.size(); i++) {
ImageIO.write(excerpt.get(i), "PNG", new File("excerpt_" + (i + 1) + ".png"));
}
}
}//:path=/static-assets/ironpdf-java/content-code-examples/how-to/java-pdf-to-image-tutorial/page-selection.java
import com.ironsoftware.ironpdf.PdfDocument;
import com.ironsoftware.ironpdf.edit.PageSelection;
import com.ironsoftware.ironpdf.image.ToImageOptions;
import javax.imageio.ImageIO;
import java.awt.image.BufferedImage;
import java.io.File;
import java.io.IOException;
import java.nio.file.Paths;
import java.util.List;
public class PageSelectionExample {
public static void main(String[] args) throws IOException {
PdfDocument pdf = PdfDocument.fromFile(Paths.get("report.pdf"));
ToImageOptions options = new ToImageOptions();
options.setImageMaxHeight(800);
options.setImageMaxWidth(500);
// Convert only the first page (page index is zero-based)
List<BufferedImage> coverPage = pdf.toBufferedImages(options, PageSelection.singlePage(0));
ImageIO.write(coverPage.get(0), "PNG", new File("cover.png"));
// Convert pages 2 through 5 (zero-based indices 1 through 4)
List<BufferedImage> excerpt = pdf.toBufferedImages(options, PageSelection.pageRange(1, 4));
for (int i = 0; i < excerpt.size(); i++) {
ImageIO.write(excerpt.get(i), "PNG", new File("excerpt_" + (i + 1) + ".png"));
}
}
}PageSelection.singlePage(0) 는 첫 번째 페이지만을 대상으로 하며, 표지 섬네일 생성을 위해 유용합니다. PageSelection.pageRange(1, 4) 는 0부터 시작하는 인덱스를 사용하여 2페이지에서 5페이지까지를 추출합니다. 둘 다 List<BufferedImage> 를 반환하므로 선택한 페이지 수와 관계없이 루프 패턴은 동일합니다.
PageSelection 의 페이지 인덱스는 0부터 시작합니다: 첫 번째 페이지는 0이고, 두 번째는 1입니다. 범위를 벗어난 인덱스를 전달하면 런타임에 IndexOutOfBoundsException 을 발생시킵니다.Java PDF에서 이미지 변환을 위한 다음 단계는 무엇입니까?
이 가이드는 세 가지 일반적인 패턴을 다루었습니다: 기존 PDF의 모든 페이지 변환, URL을 페이지 이미지 세트로 캡처, 지정된 페이지 범위 추출. IronPDF는 해상도 제어와 형식 선택을 ToImageOptions 및 ImageIO을 통해 처리하여 호출 코드가 짧고 예측 가능하게 유지됩니다.
IronPDF for Java로 계속 개발하려면 관련 리소스를 탐색하십시오:
- Java 래스터화 예제 - 추가 PDF-이미지 코드 샘플
- PDF에서 이미지 및 텍스트 추출 - 기존 PDF 파일에서 포함된 이미지 추출
- Java에서 PDF 압축 - 저장 또는 전송 전에 파일 크기 감소
- 사용자 정의 워터마크 - 저장 전 이미지 또는 PDF에 워터마크 추가
- IronPDF for Java 문서 - 전체 API 참조 및 설정 가이드
IronPDF for Java는 개발을 위해 무료입니다. 상업적 배포에는 라이선스가 필요합니다. 무료 체험 시작 또는 라이선스 옵션 보기를 통해 프로젝트에 알맞은 플랜을 확인하십시오.
IronPDF로 무엇을 할 수 있는지 준비되셨습니까? 전체 IronPDF for Java 튜토리얼 페이지를 확인하십시오.
자주 묻는 질문
Java에서 PDF 파일을 PNG 이미지로 변환하는 방법은 무엇인가요?
PdfDocument.fromFile()을 사용하여 PDF를 로드하고, 각 페이지를 나타내는 BufferedImage 객체 목록을 얻기 위해 toBufferedImages()를 호출한 다음, ImageIO.write()를 사용하여 각 이미지를 PNG 파일로 저장합니다.
PDF 페이지를 변환할 때 지원되는 이미지 형식은 무엇입니까?
IronPDF의 toBufferedImages 메서드는 BufferedImage 객체를 반환합니다. Java의 ImageIO 클래스가 지원하는 모든 형식으로 이를 저장할 수 있으며, 여기에는 PNG, JPEG, TIFF가 포함됩니다.
PDF의 특정 페이지만 이미지로 변환할 수 있습니까?
예. PageSelection 인자를 toBufferedImages에 전달하세요. PageSelection.singlePage(0)을 사용해 한 페이지를 변환하거나 PageSelection.pageRange(1, 4)를 사용해 범위를 변환하세요. 페이지 인덱스는 0 기반입니다.
Java에서 PDF를 이미지로 변환하는 일반적인 사용 사례는 무엇입니까?
일반적인 사용 사례로는 문서 관리 시스템을 위한 썸네일 미리보기 생성, 웹 애플리케이션을 위한 페이지 수준 스크린샷 생성, 프레젠테이션을 위한 시각적 콘텐츠 추출, PDF 렌더링을 지원하지 않는 시스템을 위한 이미지 파일로 문서 아카이빙이 포함됩니다.
IronPDF를 Maven 프로젝트에 추가하려면 어떻게 해야 하나요?
다음 종속성을 pom.xml의 <dependencies> 블록 내에 추가하십시오: <dependency><groupId>com.ironsoftware</groupId><artifactId>ironpdf</artifactId><version>2024.9.1</version></dependency>
URL을 직접 이미지 파일로 변환할 수 있습니까?
예. PdfDocument.renderUrlAsPdf(url)을 호출하여 내장 Chromium 엔진을 사용해 페이지를 렌더링한 후 결과 PdfDocument를 toBufferedImages에 전달하여 페이지 이미지 목록을 얻습니다.
출력 이미지 해상도를 어떻게 제어합니까?
ToImageOptions 인스턴스를 생성하고, setImageMaxHeight() 및 setImageMaxWidth()를 호출하여 최대 크기를 설정한 다음, 첫번째 인자로 이를 toBufferedImages에 전달합니다. IronPDF는 비율을 유지하며 이미지를 늘리지 않습니다.


아직도 스크롤하고 계신가요?
빠른 증거를 원하시나요?
샘플을 실행하세요 HTML이 PDF로 변환되는 것을 지켜보세요.













