


Java PDF para arquivo de imagem
Converta documentos PDF para formatos de imagem como JPEG, PNG ou TIFF em Java usando o método toBufferedImages do IronPDF. Carregue um arquivo PDF, chame toBufferedImages para obter uma lista de objetos BufferedImage, em seguida, escreva cada imagem no disco usando ImageIO. A conversão inteira leva menos de dez linhas de código Java funcional.
Início rápido: Converter PDF em imagens em Java
-
Adicione a dependência do IronPDF ao seu projeto Maven: ```xml :title=pom.xml
com.ironsoftware ironpdf 2024.9.1 -
Carregue seu documento PDF:
//:path=/static-assets/ironpdf-java/content-code-examples/how-to/java-pdf-to-image-tutorial/load-pdf.java PdfDocument pdf = PdfDocument.fromFile(Paths.get("document.pdf"));//:path=/static-assets/ironpdf-java/content-code-examples/how-to/java-pdf-to-image-tutorial/load-pdf.java PdfDocument pdf = PdfDocument.fromFile(Paths.get("document.pdf"));JAVA - Converter em imagens e salvar:
//:path=/static-assets/ironpdf-java/content-code-examples/how-to/java-pdf-to-image-tutorial/convert-and-save.java List<BufferedImage> images = pdf.toBufferedImages(); for (int i = 0; i < images.size(); i++) { ImageIO.write(images.get(i), "PNG", new File("page_" + i + ".png")); }//:path=/static-assets/ironpdf-java/content-code-examples/how-to/java-pdf-to-image-tutorial/convert-and-save.java List<BufferedImage> images = pdf.toBufferedImages(); for (int i = 0; i < images.size(); i++) { ImageIO.write(images.get(i), "PNG", new File("page_" + i + ".png")); }JAVA
Como converter PDF em imagem em Java
- Instale a biblioteca IronPDF for Java
- Carregue um arquivo PDF usando
PdfDocument.fromFile() - Chame
toBufferedImages()para obter umaList<BufferedImage> - Defina dimensões de saída com
ToImageOptionsse necessário - Escreva cada imagem no disco usando
ImageIO.write()
O que é a conversão de PDF para imagem e por que ela é necessária?
A conversão de PDF para imagem transforma cada página de um documento PDF em um arquivo de imagem autônomo (JPEG, PNG ou TIFF) que pode ser exibido, incorporado ou processado sem um visualizador de PDF. As bibliotecas padrão do Java não fornecem um mecanismo embutido para isso, o que o torna um ponto problemático persistente para os desenvolvedores que precisam de visualizações de documentos, geradores de miniaturas ou pipelines de arquivamento.
Usos comuns incluem gerar visualizações de miniaturas para sistemas de gerenciamento de documentos, produzir capturas de tela em nível de página para aplicativos web e extrair conteúdo visual para relatórios ou apresentações. IronPDF manuseia toda a complexidade da renderização internamente, mantendo o código da aplicação curto e o resultado com precisão de pixels, independentemente de fontes, gráficos vetoriais ou campos de formulário no PDF de origem. Para a operação inversa de colocar imagens em um PDF, veja o guia de como imagem para PDF.
O que é o IronPDF for Java e como ele pode ajudar?
IronPDF for Java é uma biblioteca para criar, ler e editar arquivos PDF em projetos baseados em Maven. Os desenvolvedores a utilizam para gerar PDFs a partir de HTML, modificar documentos existentes e extrair conteúdo sem Adobe Acrobat ou qualquer visualizador de PDF instalado no servidor.
A biblioteca suporta cabeçalhos e rodapés personalizados, assinaturas digitais, criação de formulários, proteção por senha e renderização multithread. Seu recurso PDF-para-imagem expõe uma API limpa por meio de duas sobrecargas de toBufferedImages: uma que converte cada página com configurações padrão e outra que aceita um objeto ToImageOptions e um PageSelection para controlar a resolução e o intervalo de páginas. Para uma visão geral completa dos recursos, visite a documentação do IronPDF for Java. Para a referência completa da API, veja a referência da API Java.
Além da conversão básica, o IronPDF suporta renderização de HTML para PDF, marcas d'água personalizadas, fundos e primeiros planos, e criação de formulários. Ele também distribui artefatos Maven no repositório Sonatype Maven Central, então o gerenciamento de dependências segue os fluxos de trabalho padrão do Maven ou Gradle.
Quais são os pré-requisitos para começar?
Antes de começar, confirme se os seguintes itens estão em vigor:
- Java instalado com o caminho configurado em Variáveis de Ambiente. Veja o guia oficial de instalação do Java.
- Um IDE Java instalado; Eclipse ou IntelliJ ambos funcionam bem. Baixe o Eclipse ou o IntelliJ IDEA.
- Maven integrado ao IDE. Veja este tutorial de configuração do Maven para IntelliJ.
- Chaves de licença configuradas antes de implantar em um ambiente de produção.
Como instalo o IronPDF for Java?
Uma vez que todos os pré-requisitos estão em vigor, a instalação é uma única declaração de dependência do Maven. Para etapas detalhadas de configuração, consulte a documentação de início rápido.
Abra o JetBrains IntelliJ IDEA e crie um novo projeto Maven.
Criar um novo projeto Maven
Uma nova janela será aberta. Digite o nome do projeto e clique em Concluir.
Novo nome do projeto
Após clicar em Finish, o novo projeto é aberto com pom.xml exibido por padrão. Adicione as seguintes dependências a esse arquivo. A entrada opcional do SLF4J suprime o ruído de log durante o desenvolvimento; remova-a se o seu projeto já incluir um framework de logging.
Novo Projeto: arquivo pom.xml padrão
//:path=/static-assets/ironpdf-java/content-code-examples/how-to/java-pdf-to-image-tutorial/pom-dependencies.xml
<dependencies>
<dependency>
<groupId>com.ironsoftware</groupId>
<artifactId>ironpdf</artifactId>
<version>2024.9.1</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-simple</artifactId>
<version>1.7.36</version>
</dependency>
</dependencies>//:path=/static-assets/ironpdf-java/content-code-examples/how-to/java-pdf-to-image-tutorial/pom-dependencies.xml
<dependencies>
<dependency>
<groupId>com.ironsoftware</groupId>
<artifactId>ironpdf</artifactId>
<version>2024.9.1</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-simple</artifactId>
<version>1.7.36</version>
</dependency>
</dependencies>Uma vez que as dependências são adicionadas ao pom.xml, um ícone de sincronização Maven aparece no canto superior direito do editor.
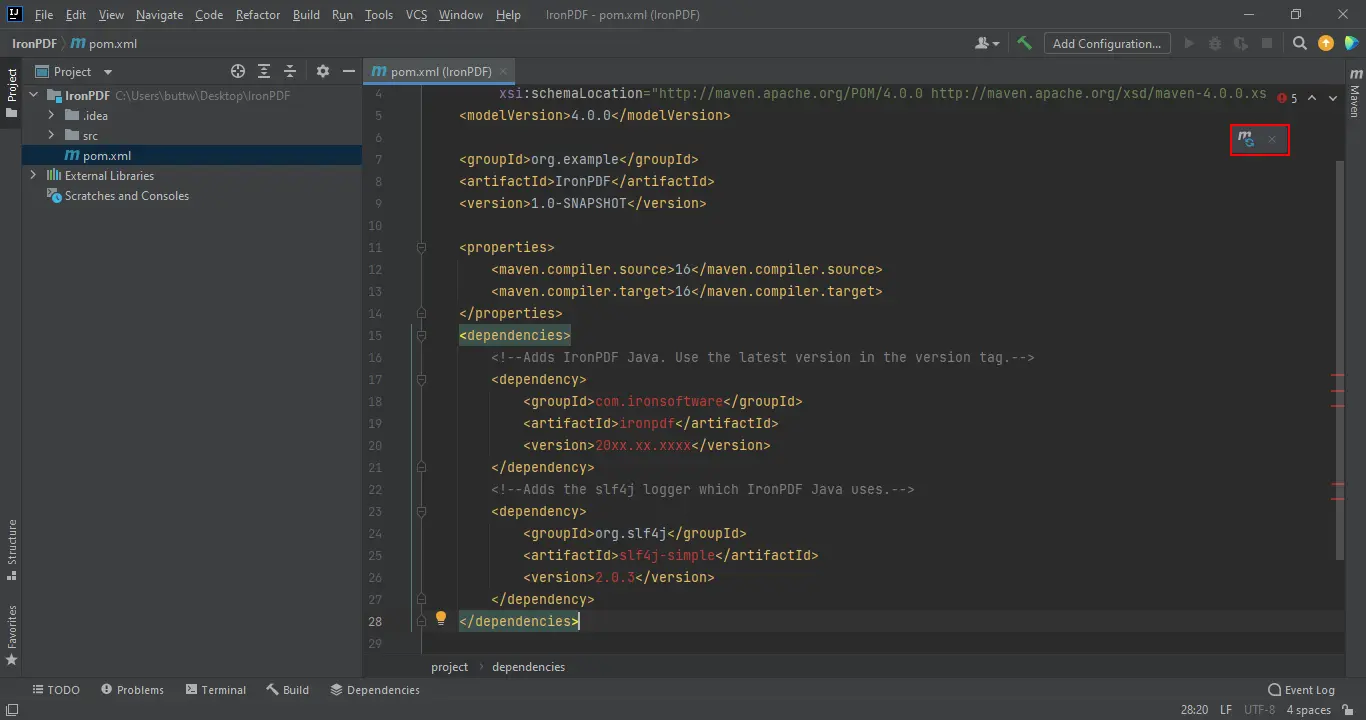
Dependências Maven Adicionadas
Clique no ícone de sincronização para baixar o JAR do IronPDF. O tempo de download depende da velocidade da conexão, normalmente menos de dois minutos. Após a instalação, revise a referência da API Java para ver todos os métodos e opções de configuração disponíveis. Para destinos de implantação na nuvem, o IronPDF possui guias testados para AWS, Azure, e Google Cloud.
Minha biblioteca favorita desse tipo é o IronPDF. Ele permite a manipulação rápida e eficiente de arquivos PDF. Além disso, possui muitos recursos valiosos, como a exportação para o formato PDF/A e a assinatura digital de documentos PDF.
Com o IronOCR, podemos economizar US$ 40.000 por ano em processamento manual, ao mesmo tempo que aumentamos a produtividade e liberamos recursos para tarefas de alto impacto. Eu o recomendo fortemente.
O IronSuite desempenha um papel crucial nas nossas operações. Estas são ferramentas que aumentam a eficiência no negócio, incluindo a criação de plantas baixas e melhoria na gestão de inventário.
Como faço para converter arquivos PDF em imagens usando o IronPDF?
Chamar toBufferedImages em um objeto PdfDocument produz um List<BufferedImage> onde cada elemento corresponde a uma página do PDF em ordem numérica ascendente. O resultado pode então ser gravado no disco, passado para um pipeline de processamento de imagem ou retornado diretamente para uma resposta web.
IronPDF também converte URLs e strings HTML em PDF rapidamente, por isso é possível capturar qualquer página web ou documento HTML renderizado como imagens em um único pipeline, sem um passo de renderização separado.
Como faço para converter um documento PDF existente em imagens?
toBufferedImages aceita um argumento opcional ToImageOptions para controlar as dimensões de saída e um argumento PageSelection para direcionar páginas específicas. Quando nenhum argumento é passado, todas as páginas são convertidas em sua resolução natural.
O exemplo abaixo converte todas as páginas de um PDF para arquivos PNG, usando ToImageOptions para limitar cada imagem de saída a 800x500 pixels:
//:path=/static-assets/ironpdf-java/content-code-examples/how-to/java-pdf-to-image-tutorial/convert-pdf-to-images.java
import com.ironsoftware.ironpdf.PdfDocument;
import com.ironsoftware.ironpdf.edit.PageSelection;
import com.ironsoftware.ironpdf.image.ToImageOptions;
import javax.imageio.ImageIO;
import java.awt.image.BufferedImage;
import java.io.File;
import java.io.IOException;
import java.nio.file.Paths;
import java.util.List;
public class Main {
public static void main(String[] args) throws IOException {
// Load the PDF document from disk
PdfDocument pdf = PdfDocument.fromFile(Paths.get("business_plan.pdf"));
// Configure output image dimensions
ToImageOptions options = new ToImageOptions();
options.setImageMaxHeight(800);
options.setImageMaxWidth(500);
// Convert all pages to BufferedImage objects with the configured dimensions
List<BufferedImage> pages = pdf.toBufferedImages(options, PageSelection.allPages());
// Write each page image to the assets/images folder (create the folder first)
int pageIndex = 1;
for (BufferedImage page : pages) {
String fileName = "assets/images/" + pageIndex++ + ".png";
ImageIO.write(page, "PNG", new File(fileName));
}
}
}//:path=/static-assets/ironpdf-java/content-code-examples/how-to/java-pdf-to-image-tutorial/convert-pdf-to-images.java
import com.ironsoftware.ironpdf.PdfDocument;
import com.ironsoftware.ironpdf.edit.PageSelection;
import com.ironsoftware.ironpdf.image.ToImageOptions;
import javax.imageio.ImageIO;
import java.awt.image.BufferedImage;
import java.io.File;
import java.io.IOException;
import java.nio.file.Paths;
import java.util.List;
public class Main {
public static void main(String[] args) throws IOException {
// Load the PDF document from disk
PdfDocument pdf = PdfDocument.fromFile(Paths.get("business_plan.pdf"));
// Configure output image dimensions
ToImageOptions options = new ToImageOptions();
options.setImageMaxHeight(800);
options.setImageMaxWidth(500);
// Convert all pages to BufferedImage objects with the configured dimensions
List<BufferedImage> pages = pdf.toBufferedImages(options, PageSelection.allPages());
// Write each page image to the assets/images folder (create the folder first)
int pageIndex = 1;
for (BufferedImage page : pages) {
String fileName = "assets/images/" + pageIndex++ + ".png";
ImageIO.write(page, "PNG", new File(fileName));
}
}
}As imagens de saída são salvas em assets/images/ com nomes de arquivo numéricos começando em 1. Crie essa pasta antes de executar o programa, pois ImageIO.write não cria diretórios ausentes. As chamadas setImageMaxHeight e setImageMaxWidth definem limites superiores em cada dimensão; IronPDF preserva a proporção original e não estica a imagem.
ImageIO.write de "PNG" para "JPEG" e atualize a extensão de arquivo de acordo.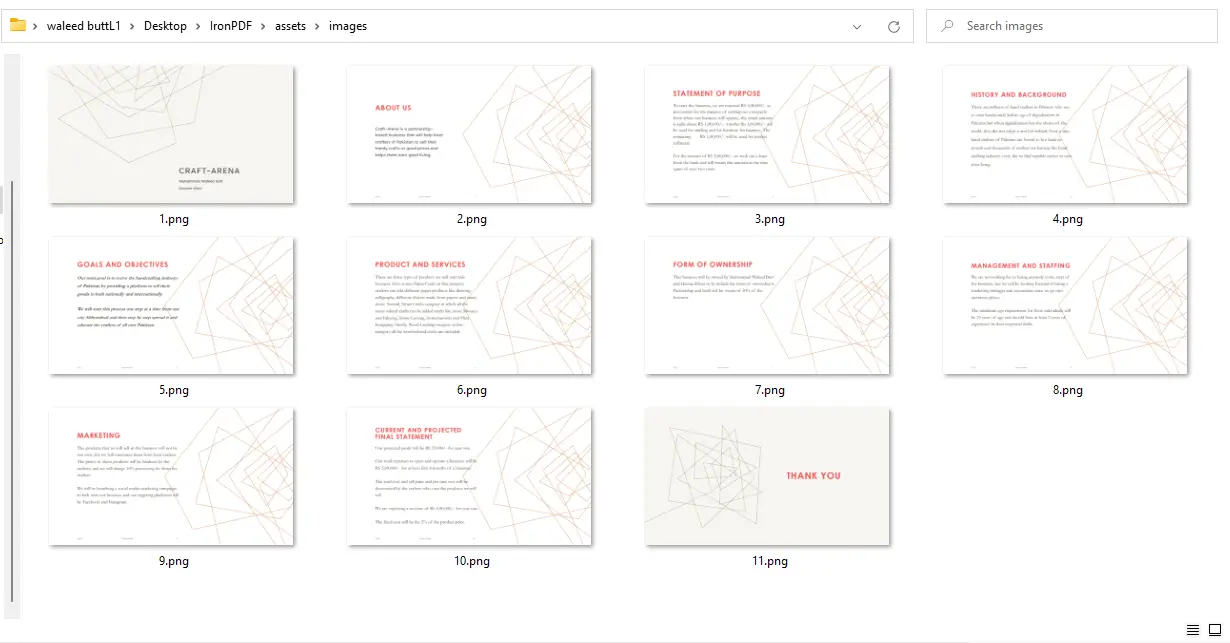
Saída de PDF para Imagens - 11 arquivos PNG, um por página
Para mais exemplos de conversão, visite a página de exemplos de rasterização de PDF.
Como faço para converter uma URL em Imagens usando o IronPDF?
PdfDocument.renderUrlAsPdf busca a URL , renderiza-a com o mecanismo Chromium embutido e retorna um PdfDocument que pode ser imediatamente passado para toBufferedImages. Isso torna simples capturar qualquer página da web acessível publicamente como uma série de imagens.
O exemplo abaixo renderiza uma página de produto da Amazon em um PDF e depois salva cada página resultante como um arquivo PNG:
//:path=/static-assets/ironpdf-java/content-code-examples/how-to/java-pdf-to-image-tutorial/convert-url-to-images.java
import com.ironsoftware.ironpdf.PdfDocument;
import com.ironsoftware.ironpdf.edit.PageSelection;
import com.ironsoftware.ironpdf.image.ToImageOptions;
import javax.imageio.ImageIO;
import java.awt.image.BufferedImage;
import java.io.File;
import java.io.IOException;
import java.util.List;
public class Main {
public static void main(String[] args) throws IOException {
// Render a URL to a PDF document using the Chromium rendering engine
PdfDocument pdf = PdfDocument.renderUrlAsPdf("https://www.amazon.com");
// Configure output image dimensions
ToImageOptions options = new ToImageOptions();
options.setImageMaxHeight(800);
options.setImageMaxWidth(500);
// Convert all pages and write to disk
List<BufferedImage> pages = pdf.toBufferedImages(options, PageSelection.allPages());
int pageIndex = 1;
for (BufferedImage page : pages) {
String fileName = "assets/images/" + pageIndex++ + ".png";
ImageIO.write(page, "PNG", new File(fileName));
}
}
}//:path=/static-assets/ironpdf-java/content-code-examples/how-to/java-pdf-to-image-tutorial/convert-url-to-images.java
import com.ironsoftware.ironpdf.PdfDocument;
import com.ironsoftware.ironpdf.edit.PageSelection;
import com.ironsoftware.ironpdf.image.ToImageOptions;
import javax.imageio.ImageIO;
import java.awt.image.BufferedImage;
import java.io.File;
import java.io.IOException;
import java.util.List;
public class Main {
public static void main(String[] args) throws IOException {
// Render a URL to a PDF document using the Chromium rendering engine
PdfDocument pdf = PdfDocument.renderUrlAsPdf("https://www.amazon.com");
// Configure output image dimensions
ToImageOptions options = new ToImageOptions();
options.setImageMaxHeight(800);
options.setImageMaxWidth(500);
// Convert all pages and write to disk
List<BufferedImage> pages = pdf.toBufferedImages(options, PageSelection.allPages());
int pageIndex = 1;
for (BufferedImage page : pages) {
String fileName = "assets/images/" + pageIndex++ + ".png";
ImageIO.write(page, "PNG", new File(fileName));
}
}
}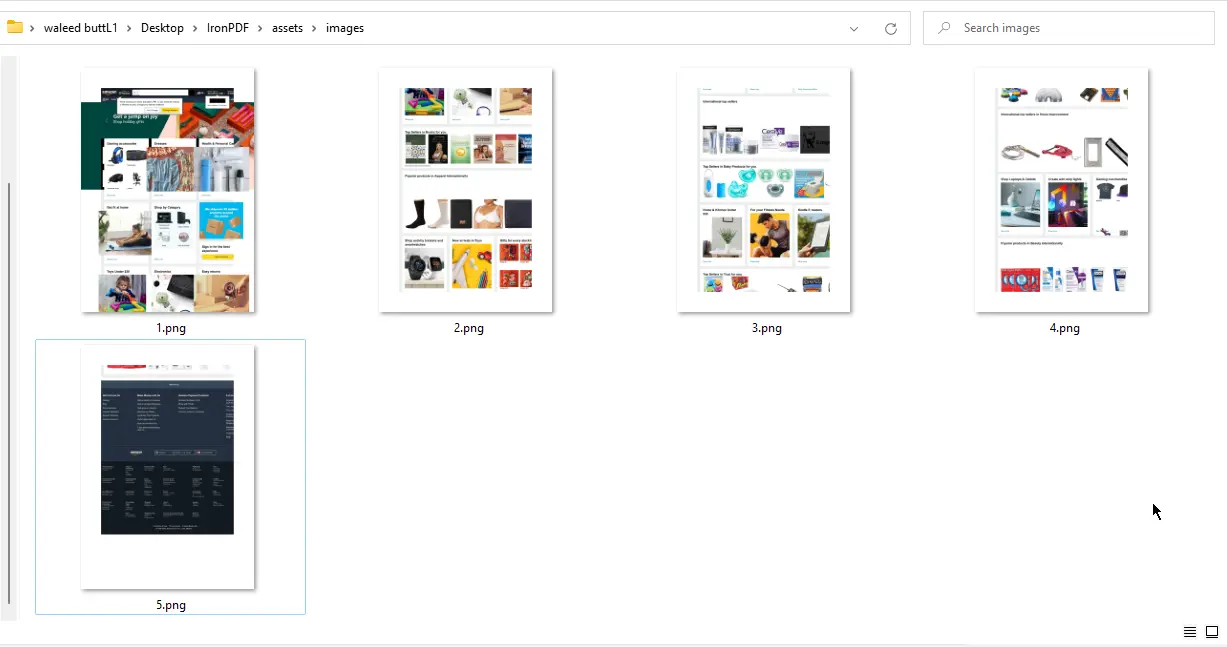
URL para saída de imagens - 5 arquivos PNG
Para páginas que requerem autenticação ou cookies de sessão antes de serem renderizadas, veja o guia de logins no site.
renderUrlAsPdf aplica o mesmo suporte a CSS e JavaScript que um navegador de desktop moderno. Páginas que dependem de JavaScript do lado do cliente para carregar conteúdo serão renderizadas corretamente, incluindo aplicativos de página única.Como faço para converter páginas específicas em imagens?
PageSelection fornece vários métodos de fábrica para direcionar um subconjunto de páginas ao invés do documento inteiro. Isso é útil quando apenas uma página de capa, uma seção de resumo ou um intervalo de páginas conhecido precisa ser extraído.
//:path=/static-assets/ironpdf-java/content-code-examples/how-to/java-pdf-to-image-tutorial/page-selection.java
import com.ironsoftware.ironpdf.PdfDocument;
import com.ironsoftware.ironpdf.edit.PageSelection;
import com.ironsoftware.ironpdf.image.ToImageOptions;
import javax.imageio.ImageIO;
import java.awt.image.BufferedImage;
import java.io.File;
import java.io.IOException;
import java.nio.file.Paths;
import java.util.List;
public class PageSelectionExample {
public static void main(String[] args) throws IOException {
PdfDocument pdf = PdfDocument.fromFile(Paths.get("report.pdf"));
ToImageOptions options = new ToImageOptions();
options.setImageMaxHeight(800);
options.setImageMaxWidth(500);
// Convert only the first page (page index is zero-based)
List<BufferedImage> coverPage = pdf.toBufferedImages(options, PageSelection.singlePage(0));
ImageIO.write(coverPage.get(0), "PNG", new File("cover.png"));
// Convert pages 2 through 5 (zero-based indices 1 through 4)
List<BufferedImage> excerpt = pdf.toBufferedImages(options, PageSelection.pageRange(1, 4));
for (int i = 0; i < excerpt.size(); i++) {
ImageIO.write(excerpt.get(i), "PNG", new File("excerpt_" + (i + 1) + ".png"));
}
}
}//:path=/static-assets/ironpdf-java/content-code-examples/how-to/java-pdf-to-image-tutorial/page-selection.java
import com.ironsoftware.ironpdf.PdfDocument;
import com.ironsoftware.ironpdf.edit.PageSelection;
import com.ironsoftware.ironpdf.image.ToImageOptions;
import javax.imageio.ImageIO;
import java.awt.image.BufferedImage;
import java.io.File;
import java.io.IOException;
import java.nio.file.Paths;
import java.util.List;
public class PageSelectionExample {
public static void main(String[] args) throws IOException {
PdfDocument pdf = PdfDocument.fromFile(Paths.get("report.pdf"));
ToImageOptions options = new ToImageOptions();
options.setImageMaxHeight(800);
options.setImageMaxWidth(500);
// Convert only the first page (page index is zero-based)
List<BufferedImage> coverPage = pdf.toBufferedImages(options, PageSelection.singlePage(0));
ImageIO.write(coverPage.get(0), "PNG", new File("cover.png"));
// Convert pages 2 through 5 (zero-based indices 1 through 4)
List<BufferedImage> excerpt = pdf.toBufferedImages(options, PageSelection.pageRange(1, 4));
for (int i = 0; i < excerpt.size(); i++) {
ImageIO.write(excerpt.get(i), "PNG", new File("excerpt_" + (i + 1) + ".png"));
}
}
}PageSelection.singlePage(0) direciona apenas a primeira página, que é útil para gerar uma miniatura de capa. PageSelection.pageRange(1, 4) extrai páginas duas a cinco usando índices baseados em zero. Ambos retornam um List<BufferedImage>, então o padrão de loop é idêntico, independentemente de quantas páginas são selecionadas.
PageSelection são baseados em zero: a primeira página é 0, a segunda é 1, e assim por diante. Passar um índice fora do intervalo gera um IndexOutOfBoundsException em tempo de execução.Quais são os próximos passos para a conversão de PDF para imagem em Java?
Este guia cobriu três padrões comuns: converter todas as páginas de um PDF existente, capturar uma URL como um conjunto de imagens de página e extrair um intervalo de páginas direcionado. IronPDF lida com controle de resolução e seleção de formato através de ToImageOptions e ImageIO, mantendo o código curto e previsível.
Para continuar construindo com IronPDF for Java, explore estes recursos relacionados:
- Exemplos de rasterização em Java - amostras de código adicional de PDF para imagem
- Extrair imagens e texto de um PDF - extrair imagens incorporadas de arquivos PDF existentes
- Comprimir PDFs em Java - reduzir o tamanho do arquivo antes do armazenamento ou transmissão
- Marcas d'água personalizadas - marcar imagens ou PDFs de saída com uma marca d'água antes de salvar
- Documentação do IronPDF for Java - referência completa de API e guias de configuração
IronPDF for Java é gratuito para desenvolvimento. Uma licença é necessária para implantação comercial. Inicie seu teste gratuito ou veja as opções de licenciamento para ver qual plano se adapta ao seu projeto.
Pronto para ver o que mais o IronPDF pode fazer? Confira a página completa do tutorial do IronPDF for Java.
Perguntas frequentes
Como faço para converter um arquivo PDF em imagens PNG em Java?
Carregue o PDF usando PdfDocument.fromFile(), chame toBufferedImages() para obter uma lista de objetos BufferedImage representando cada página, depois use ImageIO.write() para salvar cada imagem como um arquivo PNG.
Quais formatos de imagem são suportados ao converter páginas de PDF?
O método toBufferedImages do IronPDF retorna objetos BufferedImage. Você pode salvá-los em qualquer formato suportado pela classe ImageIO do Java, incluindo PNG, JPEG e TIFF.
Posso converter apenas páginas específicas de um PDF em imagens?
Sim. Passe um argumento PageSelection para toBufferedImages. Use PageSelection.singlePage(0) para converter uma página ou PageSelection.pageRange(1, 4) para converter um intervalo. Os índices de páginas são baseados em zero.
Quais são os casos de uso comuns para conversão de PDF para imagem em Java?
Os casos de uso comuns incluem geração de pré-visualizações de miniaturas para sistemas de gerenciamento de documentos, produção de capturas de tela em nível de página para aplicativos web, extração de conteúdo visual para apresentações e arquivamento de documentos como arquivos de imagem para sistemas que não suportam renderização de PDF.
Como adiciono o IronPDF ao meu projeto Maven?
Adicione a seguinte dependência dentro do bloco <dependencies> do seu pom.xml: <dependency><groupId>com.ironsoftware</groupId><artifactId>ironpdf</artifactId><version>2024.9.1</version></dependency>
Posso converter uma URL diretamente em arquivos de imagem?
Sim. Chame PdfDocument.renderUrlAsPdf(url) para renderizar a página usando o motor Chromium embutido, depois passe o PdfDocument resultante para toBufferedImages para obter uma lista de imagens de página.
Como controlo a resolução da imagem de saída?
Crie uma instância ToImageOptions, chame setImageMaxHeight() e setImageMaxWidth() para definir as dimensões máximas, então passe como primeiro argumento para toBufferedImages. O IronPDF preserva a proporção e não estica a imagem.


Ainda está rolando a tela?
Quer provas rápidas?
executar um exemplo Veja seu HTML se transformar em um PDF.













