


Java PDF vers fichier image
Convertissez des documents PDF en formats d'image tels que JPEG, PNG ou TIFF en Java à l'aide de la méthode toBufferedImages d'IronPDF. Chargez un fichier PDF, appelez toBufferedImages pour obtenir une liste d'objets BufferedImage, puis enregistrez chaque image sur le disque à l'aide de ImageIO. La conversion complète prend moins de dix lignes de code Java fonctionnel.
Démarrage rapide : Convertir un PDF en images en Java
-
Ajoutez la dépendance IronPDF à votre projet Maven : ```xml :title=pom.xml
com.ironsoftware ironpdf 2024.9.1 -
Chargez votre document PDF :
//:path=/static-assets/ironpdf-java/content-code-examples/how-to/java-pdf-to-image-tutorial/load-pdf.java PdfDocument pdf = PdfDocument.fromFile(Paths.get("document.pdf"));//:path=/static-assets/ironpdf-java/content-code-examples/how-to/java-pdf-to-image-tutorial/load-pdf.java PdfDocument pdf = PdfDocument.fromFile(Paths.get("document.pdf"));JAVA - Convertir en images et enregistrer :
//:path=/static-assets/ironpdf-java/content-code-examples/how-to/java-pdf-to-image-tutorial/convert-and-save.java List<BufferedImage> images = pdf.toBufferedImages(); for (int i = 0; i < images.size(); i++) { ImageIO.write(images.get(i), "PNG", new File("page_" + i + ".png")); }//:path=/static-assets/ironpdf-java/content-code-examples/how-to/java-pdf-to-image-tutorial/convert-and-save.java List<BufferedImage> images = pdf.toBufferedImages(); for (int i = 0; i < images.size(); i++) { ImageIO.write(images.get(i), "PNG", new File("page_" + i + ".png")); }JAVA
Comment convertir un PDF en image en Java
- Installez la bibliothèque Java IronPDF
- Chargez un fichier PDF en utilisant
PdfDocument.fromFile() - Appelez
toBufferedImages()pour obtenir uneList - Définissez les dimensions de sortie avec
ToImageOptionssi nécessaire - Écrivez chaque image sur le disque en utilisant
ImageIO.write()
Qu'est-ce que la conversion de PDF en images et pourquoi est-elle nécessaire ?
La conversion de PDF en image transforme chaque page d'un document PDF en un fichier image autonome (JPEG, PNG ou TIFF) qui peut être affiché, intégré ou traité sans visualiseur PDF. Les bibliothèques standard de Java ne fournissent aucun mécanisme intégré pour cela, ce qui en fait un point de douleur persistant pour les développeurs qui ont besoin d'aperçus de documents, de générateurs de vignettes ou de pipelines d'archivage.
Les utilisations courantes incluent la génération d'aperçus de vignettes pour les systèmes de gestion de documents, la production de captures d'écran de niveau page pour les applications web, et l'extraction de contenu visuel pour les rapports ou les présentations. IronPDF gère toute la complexité du rendu en interne, de sorte que le code de l'application reste court et que le rendu est précis au pixel près, indépendamment des polices, des graphiques vectoriels ou des champs de formulaire dans le PDF source. Pour l'opération inverse de placement d'images dans un PDF, consultez le guide de conversion d'image en PDF.
Qu'est-ce qu'IronPDF for Java et en quoi est-il utile?
IronPDF for Java est une bibliothèque pour créer, lire et éditer des fichiers PDF dans les projets basés sur Maven. Les développeurs l'utilisent pour générer des PDFs à partir de HTML, modifier des documents existants et extraire du contenu sans Adobe Acrobat ou aucun visualiseur PDF installé sur le serveur.
La bibliothèque prend en charge les en-têtes et pieds de page personnalisés, les signatures numériques, la création de formulaires, la protection par mot de passe, et le rendu multithread. Sa fonctionnalité de conversion PDF en image expose une API épurée via deux surcharges de toBufferedImages : l'une qui convertit chaque page avec les paramètres par défaut, et l'autre qui accepte un objet ToImageOptions et un PageSelection pour contrôler la résolution et la plage de pages. Pour une vue d'ensemble complète des fonctionnalités, visitez la documentation IronPDF for Java. Pour la référence API complète, consultez la référence API Java.
Au-delà de la conversion de base, IronPDF prend en charge le rendu HTML en PDF, des filigranes personnalisés, des arrière-plans et avant-plans, ainsi que la création de formulaires. Il fournit également des artefacts Maven sur le dépôt Sonatype Maven Central, ainsi la gestion des dépendances suit les flux de travail standard de Maven ou Gradle.
Quels sont les prérequis dont j'ai besoin avant de commencer ?
Avant de commencer, confirmez que les éléments suivants sont en place :
- Java installé avec le chemin défini dans les Variables d'environnement. Voir le guide d'installation Java officiel.
- Un IDE Java installé ; Eclipse ou IntelliJ fonctionnent bien. Téléchargez Eclipse ou IntelliJ IDEA.
- Maven intégré à l'IDE. Voir ce tutoriel d'installation de Maven pour IntelliJ.
- Clés de licence configurées avant le déploiement en production.
Comment installer IronPDF for Java?
Une fois que tous les prérequis sont en place, l'installation est une seule déclaration de dépendance Maven. Pour des étapes d'installation détaillées, consultez la documentation de démarrage.
Ouvrez JetBrains IntelliJ IDEA et créez un nouveau projet Maven.
Créer un nouveau projet Maven
Une nouvelle fenêtre apparaît. Saisissez le nom du projet et cliquez sur Terminer.
Nouveau nom de projet
Après avoir cliqué sur Terminer, le nouveau projet s'ouvre avec pom.xml affiché par défaut. Ajoutez les dépendances suivantes à ce fichier. L'entrée SLF4J optionnelle supprime le bruit de journalisation pendant le développement ; retirez-la si votre projet inclut déjà un framework de journalisation.
Nouveau projet : fichier pom.xml par défaut
//:path=/static-assets/ironpdf-java/content-code-examples/how-to/java-pdf-to-image-tutorial/pom-dependencies.xml
<dependencies>
<dependency>
<groupId>com.ironsoftware</groupId>
<artifactId>ironpdf</artifactId>
<version>2024.9.1</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-simple</artifactId>
<version>1.7.36</version>
</dependency>
</dependencies>//:path=/static-assets/ironpdf-java/content-code-examples/how-to/java-pdf-to-image-tutorial/pom-dependencies.xml
<dependencies>
<dependency>
<groupId>com.ironsoftware</groupId>
<artifactId>ironpdf</artifactId>
<version>2024.9.1</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-simple</artifactId>
<version>1.7.36</version>
</dependency>
</dependencies>Une fois les dépendances ajoutées à pom.xml, une icône de synchronisation Maven apparaît dans le coin supérieur droit de l'éditeur.
Dépendances Maven ajoutées
Cliquez sur l'icône de synchronisation pour télécharger le JAR IronPDF. Le temps de téléchargement dépend de la vitesse de connexion, généralement moins de deux minutes. Après l'installation, consultez la référence API Java pour voir toutes les méthodes et options de configuration disponibles. Pour les cibles de déploiement dans le cloud, IronPDF propose des guides testés pour AWS, Azure, et Google Cloud.
Comment convertir des fichiers PDF en images à l'aide d'IronPDF?
L'appel de toBufferedImages sur un objet PdfDocument produit un List<BufferedImage> où chaque élément correspond à une page PDF dans l'ordre croissant des numéros de page. Le résultat peut ensuite être écrit sur le disque, passé à un pipeline de traitement d'images, ou renvoyé directement à une réponse web.
IronPDF convertit également les URLs et les chaînes HTML en PDF à la volée, ce qui permet de capturer n'importe quelle page web ou tout document HTML rendu en images dans un pipeline unique sans étape de rendu séparée.
Comment convertir un document PDF existant en images?
toBufferedImages accepte un argument facultatif ToImageOptions pour contrôler les dimensions de sortie, et un argument PageSelection pour cibler des pages spécifiques. Lorsque aucun argument n'est passé, toutes les pages sont converties à leur résolution naturelle.
L'exemple ci-dessous convertit toutes les pages d'un PDF en fichiers PNG, en utilisant ToImageOptions pour limiter chaque image de sortie à 800x500 pixels :
//:path=/static-assets/ironpdf-java/content-code-examples/how-to/java-pdf-to-image-tutorial/convert-pdf-to-images.java
import com.ironsoftware.ironpdf.PdfDocument;
import com.ironsoftware.ironpdf.edit.PageSelection;
import com.ironsoftware.ironpdf.image.ToImageOptions;
import javax.imageio.ImageIO;
import java.awt.image.BufferedImage;
import java.io.File;
import java.io.IOException;
import java.nio.file.Paths;
import java.util.List;
public class Main {
public static void main(String[] args) throws IOException {
// Load the PDF document from disk
PdfDocument pdf = PdfDocument.fromFile(Paths.get("business_plan.pdf"));
// Configure output image dimensions
ToImageOptions options = new ToImageOptions();
options.setImageMaxHeight(800);
options.setImageMaxWidth(500);
// Convert all pages to BufferedImage objects with the configured dimensions
List<BufferedImage> pages = pdf.toBufferedImages(options, PageSelection.allPages());
// Write each page image to the assets/images folder (create the folder first)
int pageIndex = 1;
for (BufferedImage page : pages) {
String fileName = "assets/images/" + pageIndex++ + ".png";
ImageIO.write(page, "PNG", new File(fileName));
}
}
}//:path=/static-assets/ironpdf-java/content-code-examples/how-to/java-pdf-to-image-tutorial/convert-pdf-to-images.java
import com.ironsoftware.ironpdf.PdfDocument;
import com.ironsoftware.ironpdf.edit.PageSelection;
import com.ironsoftware.ironpdf.image.ToImageOptions;
import javax.imageio.ImageIO;
import java.awt.image.BufferedImage;
import java.io.File;
import java.io.IOException;
import java.nio.file.Paths;
import java.util.List;
public class Main {
public static void main(String[] args) throws IOException {
// Load the PDF document from disk
PdfDocument pdf = PdfDocument.fromFile(Paths.get("business_plan.pdf"));
// Configure output image dimensions
ToImageOptions options = new ToImageOptions();
options.setImageMaxHeight(800);
options.setImageMaxWidth(500);
// Convert all pages to BufferedImage objects with the configured dimensions
List<BufferedImage> pages = pdf.toBufferedImages(options, PageSelection.allPages());
// Write each page image to the assets/images folder (create the folder first)
int pageIndex = 1;
for (BufferedImage page : pages) {
String fileName = "assets/images/" + pageIndex++ + ".png";
ImageIO.write(page, "PNG", new File(fileName));
}
}
}Les images de sortie sont enregistrées dans assets/images/ avec des noms de fichiers numériques commençant par 1. Créez ce dossier avant d'exécuter le programme, car ImageIO.write ne crée pas les répertoires manquants. Les appels setImageMaxHeight et setImageMaxWidth définissent des limites supérieures pour chaque dimension ; IronPDF préserve le rapport d'aspect original et n'étire pas l'image.
ImageIO.write par "PNG" et mettez à jour l'extension du fichier en conséquence.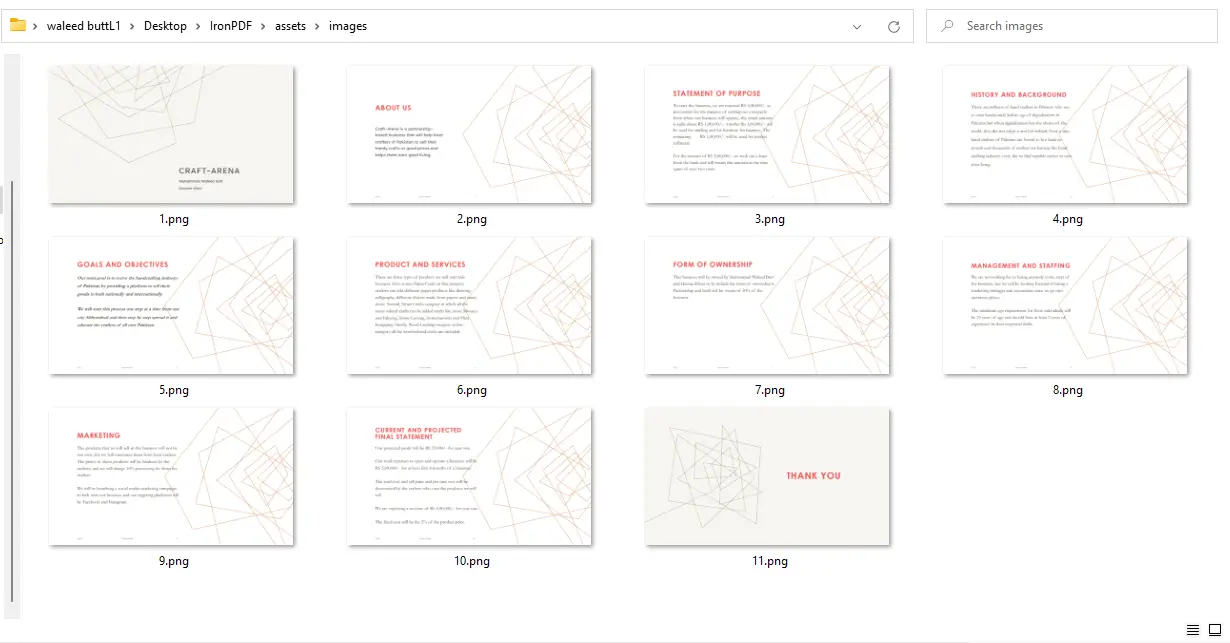
PDF en Images - Sortie de 11 fichiers PNG, un par page
Pour plus d'exemples de conversion, visitez la page d'exemples de rastérisation de PDF.
Comment convertir une URL en images avec IronPDF ?
PdfDocument.renderUrlAsPdf récupère l'URL, l'affiche à l'aide du moteur Chromium intégré et renvoie un PdfDocument qui peut être immédiatement transmis à toBufferedImages. Cela simplifie la capture de toute page web accessible publiquement en une série d'images.
L'exemple ci-dessous rend une page produit Amazon en PDF puis enregistre chaque page résultante en tant que fichier PNG :
//:path=/static-assets/ironpdf-java/content-code-examples/how-to/java-pdf-to-image-tutorial/convert-url-to-images.java
import com.ironsoftware.ironpdf.PdfDocument;
import com.ironsoftware.ironpdf.edit.PageSelection;
import com.ironsoftware.ironpdf.image.ToImageOptions;
import javax.imageio.ImageIO;
import java.awt.image.BufferedImage;
import java.io.File;
import java.io.IOException;
import java.util.List;
public class Main {
public static void main(String[] args) throws IOException {
// Render a URL to a PDF document using the Chromium rendering engine
PdfDocument pdf = PdfDocument.renderUrlAsPdf("https://www.amazon.com");
// Configure output image dimensions
ToImageOptions options = new ToImageOptions();
options.setImageMaxHeight(800);
options.setImageMaxWidth(500);
// Convert all pages and write to disk
List<BufferedImage> pages = pdf.toBufferedImages(options, PageSelection.allPages());
int pageIndex = 1;
for (BufferedImage page : pages) {
String fileName = "assets/images/" + pageIndex++ + ".png";
ImageIO.write(page, "PNG", new File(fileName));
}
}
}//:path=/static-assets/ironpdf-java/content-code-examples/how-to/java-pdf-to-image-tutorial/convert-url-to-images.java
import com.ironsoftware.ironpdf.PdfDocument;
import com.ironsoftware.ironpdf.edit.PageSelection;
import com.ironsoftware.ironpdf.image.ToImageOptions;
import javax.imageio.ImageIO;
import java.awt.image.BufferedImage;
import java.io.File;
import java.io.IOException;
import java.util.List;
public class Main {
public static void main(String[] args) throws IOException {
// Render a URL to a PDF document using the Chromium rendering engine
PdfDocument pdf = PdfDocument.renderUrlAsPdf("https://www.amazon.com");
// Configure output image dimensions
ToImageOptions options = new ToImageOptions();
options.setImageMaxHeight(800);
options.setImageMaxWidth(500);
// Convert all pages and write to disk
List<BufferedImage> pages = pdf.toBufferedImages(options, PageSelection.allPages());
int pageIndex = 1;
for (BufferedImage page : pages) {
String fileName = "assets/images/" + pageIndex++ + ".png";
ImageIO.write(page, "PNG", new File(fileName));
}
}
}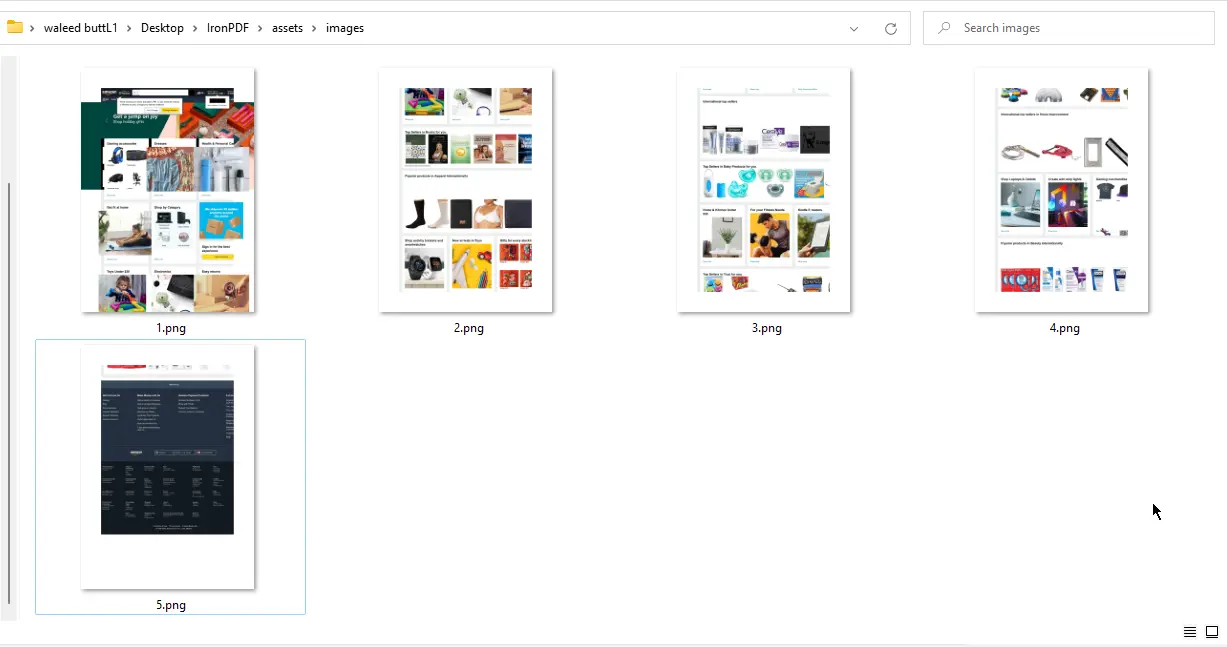
URL vers Images - Sortie de 5 fichiers PNG
Pour les pages nécessitant une authentification ou des cookies de session avant le rendu, consultez le guide sur les connexions aux sites web.
renderUrlAsPdf offre la même prise en charge CSS et JavaScript qu'un navigateur de bureau moderne. Les pages qui s'appuient sur JavaScript côté client pour charger le contenu se rendront correctement, y compris les applications monopage.Comment convertir des pages spécifiques en images?
PageSelection fournit plusieurs méthodes d'usine permettant de cibler un sous-ensemble de pages plutôt que l'intégralité du document. Cela est utile lorsque seule une page de couverture, une section de résumé ou une plage de pages connue doit être extraite.
//:path=/static-assets/ironpdf-java/content-code-examples/how-to/java-pdf-to-image-tutorial/page-selection.java
import com.ironsoftware.ironpdf.PdfDocument;
import com.ironsoftware.ironpdf.edit.PageSelection;
import com.ironsoftware.ironpdf.image.ToImageOptions;
import javax.imageio.ImageIO;
import java.awt.image.BufferedImage;
import java.io.File;
import java.io.IOException;
import java.nio.file.Paths;
import java.util.List;
public class PageSelectionExample {
public static void main(String[] args) throws IOException {
PdfDocument pdf = PdfDocument.fromFile(Paths.get("report.pdf"));
ToImageOptions options = new ToImageOptions();
options.setImageMaxHeight(800);
options.setImageMaxWidth(500);
// Convert only the first page (page index is zero-based)
List<BufferedImage> coverPage = pdf.toBufferedImages(options, PageSelection.singlePage(0));
ImageIO.write(coverPage.get(0), "PNG", new File("cover.png"));
// Convert pages 2 through 5 (zero-based indices 1 through 4)
List<BufferedImage> excerpt = pdf.toBufferedImages(options, PageSelection.pageRange(1, 4));
for (int i = 0; i < excerpt.size(); i++) {
ImageIO.write(excerpt.get(i), "PNG", new File("excerpt_" + (i + 1) + ".png"));
}
}
}//:path=/static-assets/ironpdf-java/content-code-examples/how-to/java-pdf-to-image-tutorial/page-selection.java
import com.ironsoftware.ironpdf.PdfDocument;
import com.ironsoftware.ironpdf.edit.PageSelection;
import com.ironsoftware.ironpdf.image.ToImageOptions;
import javax.imageio.ImageIO;
import java.awt.image.BufferedImage;
import java.io.File;
import java.io.IOException;
import java.nio.file.Paths;
import java.util.List;
public class PageSelectionExample {
public static void main(String[] args) throws IOException {
PdfDocument pdf = PdfDocument.fromFile(Paths.get("report.pdf"));
ToImageOptions options = new ToImageOptions();
options.setImageMaxHeight(800);
options.setImageMaxWidth(500);
// Convert only the first page (page index is zero-based)
List<BufferedImage> coverPage = pdf.toBufferedImages(options, PageSelection.singlePage(0));
ImageIO.write(coverPage.get(0), "PNG", new File("cover.png"));
// Convert pages 2 through 5 (zero-based indices 1 through 4)
List<BufferedImage> excerpt = pdf.toBufferedImages(options, PageSelection.pageRange(1, 4));
for (int i = 0; i < excerpt.size(); i++) {
ImageIO.write(excerpt.get(i), "PNG", new File("excerpt_" + (i + 1) + ".png"));
}
}
}PageSelection.singlePage(0) ne cible que la première page, ce qui est utile pour générer une vignette de couverture. PageSelection.pageRange(1, 4) extrait les pages deux à cinq en utilisant des indices à partir de zéro. Les deux renvoient un List<BufferedImage>, de sorte que le modèle de boucle est identique quel que soit le nombre de pages sélectionnées.
PageSelection sont basés sur zéro : la première page est 0, la deuxième est 1, et ainsi de suite. Le passage d'un index hors limites provoque une exception IndexOutOfBoundsException lors de l'exécution.Quelles sont les prochaines étapes pour la conversion de PDF en image en Java ?
Ce guide couvrait trois schémas courants : convertir toutes les pages d'un PDF existant, capturer une URL en images de page, et extraire une plage de pages cible. IronPDF gère le contrôle de la résolution et la sélection du format via ToImageOptions et ImageIO, ce qui permet de garder le code d'appel court et prévisible.
Pour continuer à construire avec IronPDF for Java, explorez ces ressources connexes :
- Exemples de rastérisation Java - échantillons de code supplémentaires de PDF en image
- Extraire des images et du texte d'un PDF - extraire des images intégrées de fichiers PDF existants
- Compresser des PDFs en Java - réduire la taille du fichier avant le stockage ou la transmission
- Filigranes personnalisés - tamponner des images de sortie ou des PDF avec un filigrane avant sauvegarde
- Documentation IronPDF for Java - référence API complète et guides de configuration
IronPDF for Java est gratuit pour le développement. Une licence est requise pour le déploiement commercial. Commencez votre essai gratuit ou voyez les options de licence pour voir quel plan convient à votre projet.
Prêt à voir ce qu'IronPDF peut faire d'autre ? Consultez la page de tutoriels IronPDF for Java complète.
Questions Fréquemment Posées
Comment convertir un fichier PDF en images PNG en Java ?
Chargez le PDF en utilisant PdfDocument.fromFile(), appelez toBufferedImages() pour obtenir une liste d'objets BufferedImage représentant chaque page, puis utilisez ImageIO.write() pour enregistrer chaque image en tant que fichier PNG.
Quels formats d'image sont disponibles pour la conversion des pages PDF?
La méthode toBufferedImages d'IronPDF renvoie des objets BufferedImage. Vous pouvez les enregistrer dans n'importe quel format pris en charge par la classe ImageIO de Java, notamment PNG, JPEG et TIFF.
Puis-je convertir seulement certaines pages d'un PDF en images?
Oui. Passez un argument PageSelection à toBufferedImages. Utilisez PageSelection.singlePage(0) pour convertir une seule page ou PageSelection.pageRange(1, 4) pour convertir une plage. Les index des pages commencent à zéro.
Quels sont les cas d'utilisation courants pour la conversion de PDF en images en Java?
Les cas d'utilisation courants incluent la génération d'aperçus miniatures pour les systèmes de gestion de documents, la production de captures d'écran au niveau de la page pour les applications web, l'extraction de contenu visuel pour des présentations, et l'archivage de documents sous forme de fichiers image pour les systèmes qui ne prennent pas en charge le rendu PDF.
Comment ajouter IronPDF à mon projet Maven ?
Ajoutez la dépendance suivante à l'intérieur du bloc
Puis-je convertir une URL directement en fichiers image?
Oui. Appelez PdfDocument.renderUrlAsPdf(url) pour rendre la page en utilisant le moteur Chromium intégré, puis passez le PdfDocument résultant à toBufferedImages pour obtenir une liste d'images de page.
Comment contrôler la résolution de l'image de sortie?
Créez une instance ToImageOptions, appelez setImageMaxHeight() et setImageMaxWidth() pour définir des dimensions maximales, puis passez-la en premier argument à toBufferedImages. IronPDF préserve le rapport d'aspect et ne déforme pas l'image.


Vous faites encore défiler ?
Vous voulez une preuve rapidement ?
exécuter un échantillon Regardez votre code HTML se transformer en PDF.













