


Java PDF in Bilddatei
Konvertieren Sie PDF-Dokumente in Java mithilfe der toBufferedImages-Methode von IronPDF in Bildformate wie JPEG, PNG oder TIFF. Laden Sie eine PDF-Datei, rufen Sie toBufferedImages auf, um eine Liste der BufferedImage-Objekte abzurufen, und schreiben Sie dann jedes Bild mit ImageIO auf die Festplatte. Die gesamte Umwandlung erfordert weniger als zehn Zeilen funktionierenden Java-Codes.
Schnellstart: PDF in Java in Bilder konvertieren
-
Fügen Sie die IronPDF-Abhängigkeit zu Ihrem Maven-Projekt hinzu: ```xml :title=pom.xml
com.ironsoftware ironpdf 2024.9.1 -
Laden Sie Ihr PDF-Dokument:
//:path=/static-assets/ironpdf-java/content-code-examples/how-to/java-pdf-to-image-tutorial/load-pdf.java PdfDocument pdf = PdfDocument.fromFile(Paths.get("document.pdf"));//:path=/static-assets/ironpdf-java/content-code-examples/how-to/java-pdf-to-image-tutorial/load-pdf.java PdfDocument pdf = PdfDocument.fromFile(Paths.get("document.pdf"));JAVA - In Bilder umwandeln und speichern:
//:path=/static-assets/ironpdf-java/content-code-examples/how-to/java-pdf-to-image-tutorial/convert-and-save.java List<BufferedImage> images = pdf.toBufferedImages(); for (int i = 0; i < images.size(); i++) { ImageIO.write(images.get(i), "PNG", new File("page_" + i + ".png")); }//:path=/static-assets/ironpdf-java/content-code-examples/how-to/java-pdf-to-image-tutorial/convert-and-save.java List<BufferedImage> images = pdf.toBufferedImages(); for (int i = 0; i < images.size(); i++) { ImageIO.write(images.get(i), "PNG", new File("page_" + i + ".png")); }JAVA
PDF in Java in ein Bild konvertieren
- Installieren Sie die IronPDF-Java-Bibliothek
- Laden Sie eine PDF-Datei mit
PdfDocument.fromFile() - Rufen Sie
toBufferedImages()auf, um eineListzu erhalten - Stellen Sie die Ausgabeabmessungen bei Bedarf mit
ToImageOptionsein - Schreiben Sie jedes Bild mit
ImageIO.write()auf die Festplatte
Was ist die Konvertierung von PDF in Bilder und warum wird sie benötigt?
Bei der Umwandlung von PDF in Bild wird jede Seite eines PDF-Dokuments in eine eigenständige Bilddatei (JPEG, PNG oder TIFF) umgewandelt, die ohne einen PDF-Viewer angezeigt, eingebettet oder verarbeitet werden kann. Javas Standardbibliotheken bieten keinen eingebauten Mechanismus dafür, wodurch es für Entwickler, die Dokumentvorschauen, Thumbnail-Generatoren oder Archivpipelines benötigen, ein anhaltendes Problem bleibt.
Häufige Anwendungen umfassen die Erstellung von Thumbnail-Vorschauen für Dokumentenmanagementsysteme, die Produktion von Seitenscreenshots für Webanwendungen und das Extrahieren von visuellen Inhalten für Berichte oder Präsentationen. IronPDF handhabt die gesamte Rendering-Komplexität intern, sodass der Anwendungs-Code kurz bleibt und die Ausgabe unabhängig von Schriftarten, Vektorgrafiken oder Formularfeldern im Quelldokument pixelgenau ist. Für die inverse Operation des Platzierens von Bildern in ein PDF siehe den Image-to-PDF Anleitungsartikel.
Was ist IronPDF for Java und wie kann es helfen?
IronPDF for Java ist eine Bibliothek zum Erstellen, Lesen und Bearbeiten von PDF-Dateien in Maven-basierten Projekten. Entwickler verwenden es, um PDFs aus HTML zu generieren, bestehende Dokumente zu ändern und Inhalte ohne Adobe Acrobat oder einen installierten PDF-Viewer auf dem Server zu extrahieren.
Die Bibliothek unterstützt benutzerdefinierte Kopf- und Fußzeilen, digitale Signaturen, Formularerstellung, Passwortschutz und mehrstufiges Rendering. Die PDF-zu-Bild-Funktion stellt eine übersichtliche API über zwei Überladungen von toBufferedImages bereit: eine, die jede Seite mit Standardeinstellungen konvertiert, und eine, die ein ToImageOptions-Objekt und ein PageSelection akzeptiert, um Auflösung und Seitenbereich zu steuern. Für eine vollständige Funktionsübersicht besuchen Sie die IronPDF for Java Dokumentation. Für die vollständige API-Referenz siehe die Java API-Referenz.
Neben der grundlegenden Konversion unterstützt IronPDF HTML-zu-PDF-Rendering, benutzerdefinierte Wasserzeichen, Hintergründe und Vordergründe und Formularerstellung. Es liefert auch Maven-Artefakte im Sonatype Maven Central Repository, sodass die Abhängigkeitsverwaltung den Standard-Workflows von Maven oder Gradle folgt.
Welche Voraussetzungen brauche ich, bevor ich anfange?
Vor der Inbetriebnahme bestätigen Sie, dass Folgendes vorhanden ist:
- Java ist installiert und der Pfad ist in den Umgebungsvariablen gesetzt. Siehe den offiziellen Java-Installationsleitfaden.
- Eine Java-IDE ist installiert; Eclipse oder IntelliJ funktionieren beide gut. Laden Sie Eclipse oder IntelliJ IDEA herunter.
- Maven ist in die IDE integriert. Siehe dieses Maven Einrichtungs-Tutorial für IntelliJ.
- Lizenzschlüssel sind konfiguriert vor der Bereitstellung in einer Produktionsumgebung.
Wie installiere ich IronPDF for Java?
Sobald alle Voraussetzungen erfüllt sind, ist die Installation eine einzige Maven-Abhängigkeitsdeklaration. Für detaillierte Einrichtungsanweisungen konsultieren Sie die Erste Schritte Dokumentation.
Öffnen Sie JetBrains IntelliJ IDEA und erstellen Sie ein neues Maven-Projekt.
Erstellen Sie ein neues Maven-Projekt
Ein neues Fenster erscheint. Geben Sie den Projektnamen ein und klicken Sie auf Fertig stellen.
Neuer Projektname
Nach dem Klicken auf "Fertigstellen" wird das neue Projekt geöffnet, wobei standardmäßig pom.xml angezeigt wird. Fügen Sie die folgenden Abhängigkeiten zu dieser Datei hinzu. Der optional SLF4J-Eintrag unterdrückt Lärm bei der Protokollierung während der Entwicklung; entfernen Sie ihn, wenn Ihr Projekt bereits ein Protokollierungsframework enthält.
Neues Projekt: Standard pom.xml
//:path=/static-assets/ironpdf-java/content-code-examples/how-to/java-pdf-to-image-tutorial/pom-dependencies.xml
<dependencies>
<dependency>
<groupId>com.ironsoftware</groupId>
<artifactId>ironpdf</artifactId>
<version>2024.9.1</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-simple</artifactId>
<version>1.7.36</version>
</dependency>
</dependencies>//:path=/static-assets/ironpdf-java/content-code-examples/how-to/java-pdf-to-image-tutorial/pom-dependencies.xml
<dependencies>
<dependency>
<groupId>com.ironsoftware</groupId>
<artifactId>ironpdf</artifactId>
<version>2024.9.1</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-simple</artifactId>
<version>1.7.36</version>
</dependency>
</dependencies>Sobald die Abhängigkeiten zu pom.xml hinzugefügt wurden, erscheint in der oberen rechten Ecke des Editors ein Maven-Synchronisierungssymbol.
Maven-Abhängigkeiten hinzugefügt
Klicken Sie auf das Synchronisierungssymbol, um das IronPDF-JAR herunterzuladen. Die Download-Zeit hängt von der Verbindungsgeschwindigkeit ab, liegt in der Regel jedoch unter zwei Minuten. Nach der Installation sollten Sie die Java API-Referenz durchsehen, um alle verfügbaren Methoden und Konfigurationsoptionen zu sehen. Für Cloud-Bereitstellungsziele gibt es getestete Anleitungen für AWS, Azure, und Google Cloud.
Wie kann ich mit IronPDF PDF-Dateien in Bilder umwandeln?
Der Aufruf von toBufferedImages auf einem PdfDocument-Objekt erzeugt ein List<BufferedImage>, wobei jedes Element einer PDF-Seite in aufsteigender Seitenreihenfolge entspricht. Das Ergebnis kann dann auf die Festplatte geschrieben, einer Bildverarbeitungspipeline zugeführt oder direkt an eine Webantwort zurückgegeben werden.
IronPDF konvertiert auch URLs und HTML-Strings 'on the fly' zu PDF, sodass es möglich ist, jede Webseite oder gerenderte HTML-Dokumente als Bilder in einer einzigen Pipeline zu erfassen, ohne einen separaten Rendering-Schritt.
Wie kann ich ein bestehendes PDF-Dokument in Bilder umwandeln?
toBufferedImages akzeptiert ein optionales ToImageOptions-Argument zur Steuerung der Ausgabedimensionen und ein PageSelection-Argument zur Ausrichtung auf bestimmte Seiten. Werden keine Argumente übergeben, werden alle Seiten mit ihrer natürlichen Auflösung umgewandelt.
Das folgende Beispiel konvertiert alle Seiten einer PDF-Datei in PNG-Dateien und verwendet ToImageOptions, um die Größe jedes Ausgabebildes auf 800 x 500 Pixel zu begrenzen:
//:path=/static-assets/ironpdf-java/content-code-examples/how-to/java-pdf-to-image-tutorial/convert-pdf-to-images.java
import com.ironsoftware.ironpdf.PdfDocument;
import com.ironsoftware.ironpdf.edit.PageSelection;
import com.ironsoftware.ironpdf.image.ToImageOptions;
import javax.imageio.ImageIO;
import java.awt.image.BufferedImage;
import java.io.File;
import java.io.IOException;
import java.nio.file.Paths;
import java.util.List;
public class Main {
public static void main(String[] args) throws IOException {
// Load the PDF document from disk
PdfDocument pdf = PdfDocument.fromFile(Paths.get("business_plan.pdf"));
// Configure output image dimensions
ToImageOptions options = new ToImageOptions();
options.setImageMaxHeight(800);
options.setImageMaxWidth(500);
// Convert all pages to BufferedImage objects with the configured dimensions
List<BufferedImage> pages = pdf.toBufferedImages(options, PageSelection.allPages());
// Write each page image to the assets/images folder (create the folder first)
int pageIndex = 1;
for (BufferedImage page : pages) {
String fileName = "assets/images/" + pageIndex++ + ".png";
ImageIO.write(page, "PNG", new File(fileName));
}
}
}//:path=/static-assets/ironpdf-java/content-code-examples/how-to/java-pdf-to-image-tutorial/convert-pdf-to-images.java
import com.ironsoftware.ironpdf.PdfDocument;
import com.ironsoftware.ironpdf.edit.PageSelection;
import com.ironsoftware.ironpdf.image.ToImageOptions;
import javax.imageio.ImageIO;
import java.awt.image.BufferedImage;
import java.io.File;
import java.io.IOException;
import java.nio.file.Paths;
import java.util.List;
public class Main {
public static void main(String[] args) throws IOException {
// Load the PDF document from disk
PdfDocument pdf = PdfDocument.fromFile(Paths.get("business_plan.pdf"));
// Configure output image dimensions
ToImageOptions options = new ToImageOptions();
options.setImageMaxHeight(800);
options.setImageMaxWidth(500);
// Convert all pages to BufferedImage objects with the configured dimensions
List<BufferedImage> pages = pdf.toBufferedImages(options, PageSelection.allPages());
// Write each page image to the assets/images folder (create the folder first)
int pageIndex = 1;
for (BufferedImage page : pages) {
String fileName = "assets/images/" + pageIndex++ + ".png";
ImageIO.write(page, "PNG", new File(fileName));
}
}
}Die Ausgabebilder werden unter assets/images/ gespeichert, wobei die Dateinamen numerisch bei 1 beginnen. Erstellen Sie diesen Ordner, bevor Sie das Programm ausführen, da ImageIO.write fehlende Verzeichnisse nicht erstellt. Die Aufrufe setImageMaxHeight und setImageMaxWidth legen Obergrenzen für jede Dimension fest; IronPDF bewahrt das ursprüngliche Seitenverhältnis und streckt das Bild nicht.
ImageIO.write von "PNG" zu "JPEG" und passen Sie die Dateiendung entsprechend an.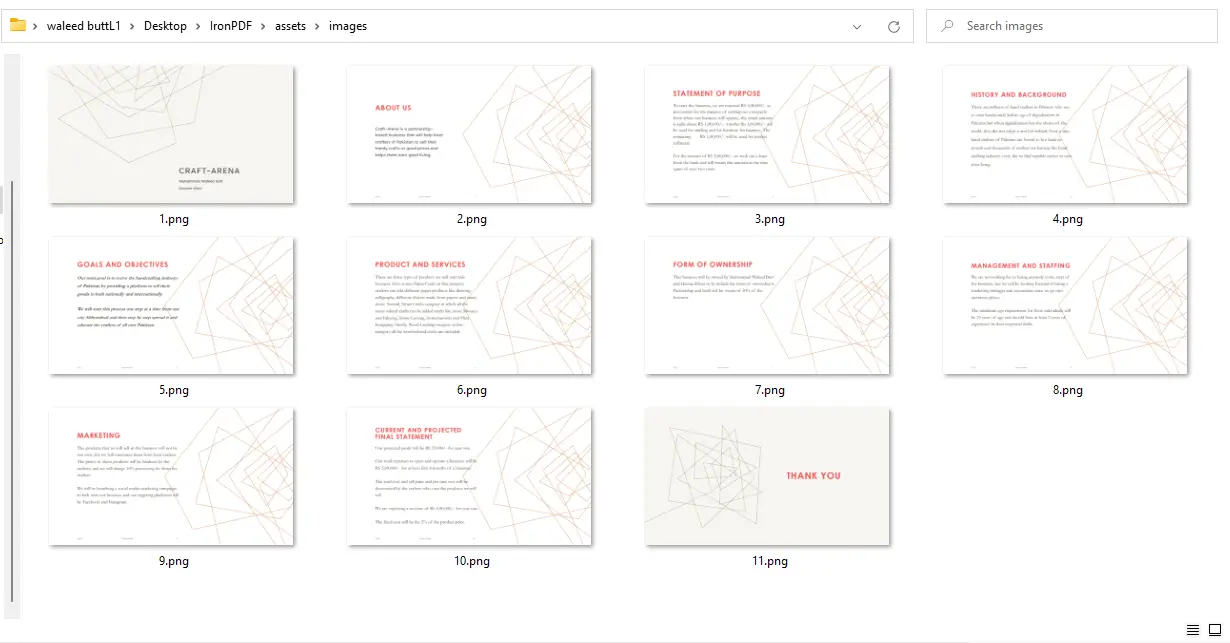
PDF zu Bildern Ausgabe - 11 PNG-Dateien, eine pro Seite
Für weitere Umwandlungsbeispiele besuchen Sie die PDF-Rasterisierungsbeispiele-Seite.
Wie konvertiere ich eine URL zu Bildern mit IronPDF?
PdfDocument.renderUrlAsPdf ruft die URL ab, rendert sie mit der integrierten Chromium-Engine und gibt ein PdfDocument zurück, das sofort an toBufferedImages übergeben werden kann. Dies macht es einfach, jede öffentlich zugängliche Webseite als Reihe von Bildern zu erfassen.
Das folgende Beispiel rendert eine Amazon-Produktseite in ein PDF und speichert dann jede resultierende Seite als PNG-Datei:
//:path=/static-assets/ironpdf-java/content-code-examples/how-to/java-pdf-to-image-tutorial/convert-url-to-images.java
import com.ironsoftware.ironpdf.PdfDocument;
import com.ironsoftware.ironpdf.edit.PageSelection;
import com.ironsoftware.ironpdf.image.ToImageOptions;
import javax.imageio.ImageIO;
import java.awt.image.BufferedImage;
import java.io.File;
import java.io.IOException;
import java.util.List;
public class Main {
public static void main(String[] args) throws IOException {
// Render a URL to a PDF document using the Chromium rendering engine
PdfDocument pdf = PdfDocument.renderUrlAsPdf("https://www.amazon.com");
// Configure output image dimensions
ToImageOptions options = new ToImageOptions();
options.setImageMaxHeight(800);
options.setImageMaxWidth(500);
// Convert all pages and write to disk
List<BufferedImage> pages = pdf.toBufferedImages(options, PageSelection.allPages());
int pageIndex = 1;
for (BufferedImage page : pages) {
String fileName = "assets/images/" + pageIndex++ + ".png";
ImageIO.write(page, "PNG", new File(fileName));
}
}
}//:path=/static-assets/ironpdf-java/content-code-examples/how-to/java-pdf-to-image-tutorial/convert-url-to-images.java
import com.ironsoftware.ironpdf.PdfDocument;
import com.ironsoftware.ironpdf.edit.PageSelection;
import com.ironsoftware.ironpdf.image.ToImageOptions;
import javax.imageio.ImageIO;
import java.awt.image.BufferedImage;
import java.io.File;
import java.io.IOException;
import java.util.List;
public class Main {
public static void main(String[] args) throws IOException {
// Render a URL to a PDF document using the Chromium rendering engine
PdfDocument pdf = PdfDocument.renderUrlAsPdf("https://www.amazon.com");
// Configure output image dimensions
ToImageOptions options = new ToImageOptions();
options.setImageMaxHeight(800);
options.setImageMaxWidth(500);
// Convert all pages and write to disk
List<BufferedImage> pages = pdf.toBufferedImages(options, PageSelection.allPages());
int pageIndex = 1;
for (BufferedImage page : pages) {
String fileName = "assets/images/" + pageIndex++ + ".png";
ImageIO.write(page, "PNG", new File(fileName));
}
}
}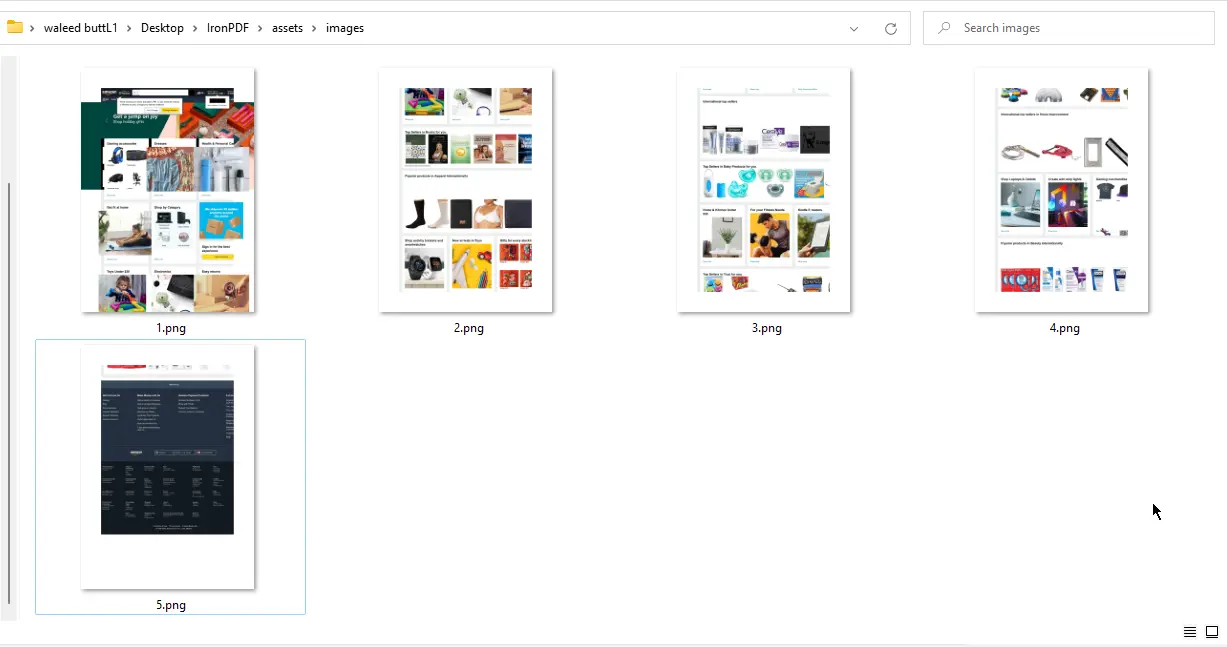
URL zu Bilder Ausgabe - 5 PNG-Dateien
Für Seiten, die Authentifizierung oder Session-Cookies vor dem Rendern erfordern, siehe den Webseiten-Anmeldungsleitfaden.
renderUrlAsPdf basiert, bietet dieselbe CSS- und JavaScript-Unterstützung wie ein moderner Desktop-Browser. Seiten, die sich auf clientseitiges JavaScript zur Inhaltsladung verlassen, werden korrekt gerendert, einschließlich Single-Page-Anwendungen.Wie kann ich bestimmte Seiten in Bilder umwandeln?
PageSelection bietet mehrere Factory-Methoden, um statt des gesamten Dokuments nur eine Teilmenge von Seiten anzusprechen. Dies ist nützlich, wenn nur eine Titelseite, ein Zusammenfassungsabschnitt oder ein bekannter Seitenbereich extrahiert werden muss.
//:path=/static-assets/ironpdf-java/content-code-examples/how-to/java-pdf-to-image-tutorial/page-selection.java
import com.ironsoftware.ironpdf.PdfDocument;
import com.ironsoftware.ironpdf.edit.PageSelection;
import com.ironsoftware.ironpdf.image.ToImageOptions;
import javax.imageio.ImageIO;
import java.awt.image.BufferedImage;
import java.io.File;
import java.io.IOException;
import java.nio.file.Paths;
import java.util.List;
public class PageSelectionExample {
public static void main(String[] args) throws IOException {
PdfDocument pdf = PdfDocument.fromFile(Paths.get("report.pdf"));
ToImageOptions options = new ToImageOptions();
options.setImageMaxHeight(800);
options.setImageMaxWidth(500);
// Convert only the first page (page index is zero-based)
List<BufferedImage> coverPage = pdf.toBufferedImages(options, PageSelection.singlePage(0));
ImageIO.write(coverPage.get(0), "PNG", new File("cover.png"));
// Convert pages 2 through 5 (zero-based indices 1 through 4)
List<BufferedImage> excerpt = pdf.toBufferedImages(options, PageSelection.pageRange(1, 4));
for (int i = 0; i < excerpt.size(); i++) {
ImageIO.write(excerpt.get(i), "PNG", new File("excerpt_" + (i + 1) + ".png"));
}
}
}//:path=/static-assets/ironpdf-java/content-code-examples/how-to/java-pdf-to-image-tutorial/page-selection.java
import com.ironsoftware.ironpdf.PdfDocument;
import com.ironsoftware.ironpdf.edit.PageSelection;
import com.ironsoftware.ironpdf.image.ToImageOptions;
import javax.imageio.ImageIO;
import java.awt.image.BufferedImage;
import java.io.File;
import java.io.IOException;
import java.nio.file.Paths;
import java.util.List;
public class PageSelectionExample {
public static void main(String[] args) throws IOException {
PdfDocument pdf = PdfDocument.fromFile(Paths.get("report.pdf"));
ToImageOptions options = new ToImageOptions();
options.setImageMaxHeight(800);
options.setImageMaxWidth(500);
// Convert only the first page (page index is zero-based)
List<BufferedImage> coverPage = pdf.toBufferedImages(options, PageSelection.singlePage(0));
ImageIO.write(coverPage.get(0), "PNG", new File("cover.png"));
// Convert pages 2 through 5 (zero-based indices 1 through 4)
List<BufferedImage> excerpt = pdf.toBufferedImages(options, PageSelection.pageRange(1, 4));
for (int i = 0; i < excerpt.size(); i++) {
ImageIO.write(excerpt.get(i), "PNG", new File("excerpt_" + (i + 1) + ".png"));
}
}
}PageSelection.singlePage(0) bezieht sich nur auf die erste Seite, was für die Erstellung eines Cover-Miniaturbildes nützlich ist. PageSelection.pageRange(1, 4) extrahiert die Seiten zwei bis fünf unter Verwendung von nullbasierten Indizes. Beide geben ein List<BufferedImage> zurück, sodass das Schleifenmuster unabhängig von der Anzahl der ausgewählten Seiten identisch ist.
PageSelection sind nullbasiert: Die erste Seite ist 0, die zweite ist 1 und so weiter. Das Übergeben eines Index außerhalb des zulässigen Bereichs löst zur Laufzeit einen IndexOutOfBoundsException aus.Was sind die nächsten Schritte bei der Konvertierung von Java-PDF zu Bild?
Diese Anleitung behandelte drei übliche Muster: die Konvertierung aller Seiten eines vorhandenen PDFs, die Erfassung einer URL als Satz von Seitenbildern und die Extraktion eines zielgerichteten Seitenbereichs. IronPDF übernimmt die Steuerung der Auflösung und die Formatauswahl über ToImageOptions und ImageIO, wodurch der aufrufende Code kurz und vorhersehbar bleibt.
Um weiterhin mit IronPDF for Java zu arbeiten, erkunden Sie diese verwandten Ressourcen:
- Java-Rasterisierungsbeispiele - zusätzliche PDF-zu-Bild-Codebeispiele
- Bilder und Text aus einem PDF extrahieren - eingebettete Bilder aus vorhandenen PDF-Dateien herausziehen
- PDFs in Java komprimieren - Dateigröße vor der Speicherung oder Übertragung verringern
- Benutzerdefinierte Wasserzeichen - Ausgabebilder oder PDFs mit einem Wasserzeichen versehen, bevor sie gespeichert werden
- IronPDF for Java Dokumentation - Vollständige API-Referenz und Einrichtungsleitfaden
IronPDF for Java ist kostenlos für die Entwicklung. Eine Lizenz ist für den kommerziellen Einsatz erforderlich. Starten Sie Ihre kostenlose Testversion oder sehen Sie sich die Lizenzierungsoptionen an, um zu sehen, welcher Plan zu Ihrem Projekt passt.
Bereit zu sehen, was IronPDF sonst noch kann? Schauen Sie sich die vollständige IronPDF for Java Tutorialseite an.
Häufig gestellte Fragen
Wie konvertiere ich in Java eine PDF-Datei in PNG-Bilder?
Laden Sie das PDF mit PdfDocument.fromFile(), rufen Sie toBufferedImages() auf, um eine Liste von BufferedImage-Objekten zu erhalten, die jede Seite darstellen, und verwenden Sie ImageIO.write(), um jedes Bild als PNG-Datei zu speichern.
Welche Bildformate werden bei der Konvertierung von PDF-Seiten unterstützt?
Die Methode toBufferedImages von IronPDF gibt BufferedImage-Objekte zurück. Sie können diese in allen Formaten speichern, die von der ImageIO-Klasse von Java unterstützt werden, einschließlich PNG, JPEG und TIFF.
Kann ich nur bestimmte Seiten eines PDFs in Bilder konvertieren?
Ja. Übergeben Sie ein PageSelection-Argument an toBufferedImages. Verwenden Sie PageSelection.singlePage(0), um eine Seite zu konvertieren, oder PageSelection.pageRange(1, 4), um einen Bereich zu konvertieren. Seitenindizes sind null-basiert.
Was sind die häufigsten Anwendungsfälle für die Konvertierung von PDF zu Bild in Java?
Häufige Anwendungsfälle sind das Erstellen von Miniaturbildern für Dokumentmanagement-Systeme, das Erzeugen von seitenbezogenen Screenshots für Webanwendungen, das Extrahieren von visuellen Inhalten für Präsentationen und das Archivieren von Dokumenten als Bilddateien für Systeme, die keine PDF-Darstellung unterstützen.
Wie kann ich IronPDF zu meinem Maven-Projekt hinzufügen?
Fügen Sie die folgende Abhängigkeit innerhalb des
Kann ich eine URL direkt in Bilddateien konvertieren?
Ja. Rufen Sie PdfDocument.renderUrlAsPdf(url) auf, um die Seite mit der integrierten Chromium-Engine zu rendern, und übergeben Sie das resultierende PdfDocument an toBufferedImages, um eine Liste von Seitenbildern zu erhalten.
Wie steuere ich die Auflösung des Ausgabebilds?
Erstellen Sie eine ToImageOptions-Instanz, rufen Sie setImageMaxHeight() und setImageMaxWidth() auf, um maximale Dimensionen festzulegen, und übergeben Sie sie als erstes Argument an toBufferedImages. IronPDF bewahrt das Seitenverhältnis und streckt das Bild nicht.


Scrollst du immer noch?
Sie brauchen schnell einen Beweis?
Führen Sie eine Probe aus Sehen Sie zu, wie Ihr HTML-Code in eine PDF-Datei umgewandelt wird.













