
PythonでスキャンされたPDFからテキストを抽出する方法
PDF ファイル、特にスキャンされたファイルからテキストを抽出するのは難しい場合があります。 ただし、適切なツールとテクニックを使用すれば、このプロセスを簡素化できます。 このチュートリアルでは、PythonライブラリであるIronPDFを使用して、スキャンしたPDFファイルからテキストを抽出する方法を説明します。環境の設定方法、光学式文字認識(OCR)の適用方法、そして効果的なテキスト抽出方法について解説します。
1. IronPDFの紹介
 Python PDFライブラリ
Python PDFライブラリ
IronPDF は、Python 環境内での PDF の操作と処理用に設計された、多用途で強力なライブラリです。 Python アプリケーションとシームレスに統合できることで知られる IronPDF は、基本的な PDF の読み取りと書き込みを超えたさまざまな機能を提供します。 HTML を PDF に変換したり、Web ページや生の HTML コードから PDF ドキュメントをレンダリングしたり、既存の PDF ファイルを編集したりする機能が際立っています。
さらに、光学文字認識 (OCR) 機能は、スキャンした PDF ドキュメントからテキストを抽出するのに便利です。 これは、さまざまな PDF 関連のタスクを扱う開発者にとって頼りになるツールです。 PDF ファイルの作成、変更、または PDF ファイルからのデータ抽出のいずれの場合でも、IronPDF は、さまざまなアプリケーションにおける Python 開発者の多様なニーズに応える、堅牢で信頼性の高いソリューションです。
2. 事前準備
PDF からのテキスト抽出プロセスに進む前に、いくつかの前提条件と必要なライブラリを用意することが重要です。 これにより、作業を進める際にスムーズかつ効果的なワークフローが確保されます。
- Python 環境: コンピュータ システムに Python がインストールされていることを確認します。 Python は汎用性の高いプログラミング言語であり、広範なライブラリ サポートにより、テキスト抽出などのタスクに最適です。 Python をインストールしていない場合は、公式 Python Web サイトからダウンロードできます。 必ず、ご使用のオペレーティング システムと互換性のある Python バージョンをダウンロードしてください。
- .NET 6.0 SDK のインストール: IronPDF for Python は、.NET 6.0 上に構築された IronPDF for .NET ライブラリを活用するため、システムに .NET 6.0 SDK がインストールされていることが重要です。 この SDK は、IronPDF ライブラリが正しく機能するために必要なランタイムとライブラリを提供します。 .NET 6.0 SDK は、Microsoft .NET の公式 Web サイトからダウンロードしてインストールできます。
- Python 用 IronPDF ライブラリ: IronPDF は、Python で PDF ドキュメントを操作するための強力なライブラリです。 テキスト抽出を容易にするだけでなく、PDF の作成、編集、変換などの機能も提供します。
- スキャンした PDF ドキュメント: テキスト抽出用にスキャンした PDF ドキュメントを用意します。 スキャンした PDF の品質は OCR と抽出されたテキストの精度に大きな影響を与える可能性があるため、このドキュメントは明瞭で読みやすいことが理想的です。
- 基本的な Python の理解: Python プログラミングの基本的な理解があると役立ちます。 変数、ループ、基本的なファイル操作などの概念を理解しておくと、コード内を移動し、テキスト抽出プロセスをより効果的に理解するのに役立ちます。
- 適切な開発環境: 厳密には必須ではありませんが、 Visual Studio Code 、 PyCharm 、 Jupyter Notebookなどの開発環境があれば、コーディング作業をより管理しやすくなります。 これらの環境は、構文の強調表示、コード補完、デバッグ ツールなどの機能を提供しており、Python スクリプトを操作するときに非常に役立ちます。
これらの前提条件を満たしていれば、IronPDF for Python ライブラリを使用してスキャンした PDF ドキュメントからテキストを抽出する準備が整います。 以降の手順では、IronPDF のインストール、PDF ドキュメントの読み込み、OCR の適用、テキストの抽出、および抽出されたデータを特定のニーズに合わせて利用する手順を説明します。
3. スキャンしたPDFからテキストを抽出するためのステップバイステップガイド
ステップ1: IronPDFのインストール
まず、Python 環境にIronPDF for Python ライブラリをインストールする必要があります。 これは通常、Pythonのパッケージマネージャーであるpipを使用して行われます。コマンドラインインターフェースを開き、次のコマンドを実行します。
pip install ironpdf
 IronPDFパッケージをインストールする
IronPDFパッケージをインストールする
ステップ2: IronPDFをインポートする
インストール後、IronPDF ライブラリを Python スクリプトにインポートします。 この手順は、IronPDF が提供する機能にアクセスするために重要です。
import ironpdfimport ironpdfIronPDF をインポートすると、スクリプトでそのクラスとメソッドを使用できるようになります。
ステップ3: ライセンスキーを適用する
IronPDF の全機能を使用するにはライセンス キーが必要です。 ライセンスを購入した場合は、次のようにライセンス キーを適用します。
ironpdf.License.LicenseKey = "YOUR-LICENSE-KEY-HERE"ironpdf.License.LicenseKey = "YOUR-LICENSE-KEY-HERE"実際のIronPDFライセンスキーと"YOUR-LICENSE-KEY-HERE"を置き換えてください。 この手順は、IronPDF のすべての機能を制限なくロック解除するために不可欠です。
ステップ4: スキャンしたPDFファイルを読み込む
テキストを抽出するには、まず PDF ドキュメントをスクリプトに読み込みます。
pdf = ironpdf.PdfDocument.FromFile("scannedpdf.pdf")pdf = ironpdf.PdfDocument.FromFile("scannedpdf.pdf")ここでは、処理する予定のPDFドキュメントの実際のファイルパスで"scannedpdf.pdf"を置き換える必要があります。 このコマンドは PDF ファイルを読み取り、テキスト抽出の準備をします。
ステップ5:PDFファイルからテキストを抽出する
PDFがロードされた状態で、次のコードに示されているようにIronPDFのExtractAllText()メソッドを使用してテキストを抽出できます。
text = pdf.ExtractAllText()text = pdf.ExtractAllText()このコード行は、PDFドキュメント全体を処理し、そのテキストコンテンツをtext変数に格納します。
ステップ6:抽出したテキストを処理して活用する
抽出後、テキストデータはtext変数に利用可能です。 このテキストをコンソールに出力したり、必要に応じてさらに処理したりすることができます。
print(text)
# Additional code here to process or utilize the extracted textprint(text)
# Additional code here to process or utilize the extracted textこのステップには、抽出されたテキストをファイルに保存したり、テキスト データ分析を実行したり、データベースや Web アプリケーションに統合したりするなど、さまざまな操作が含まれます。 ここで、上記のコードの出力を確認できます。
出力テキスト
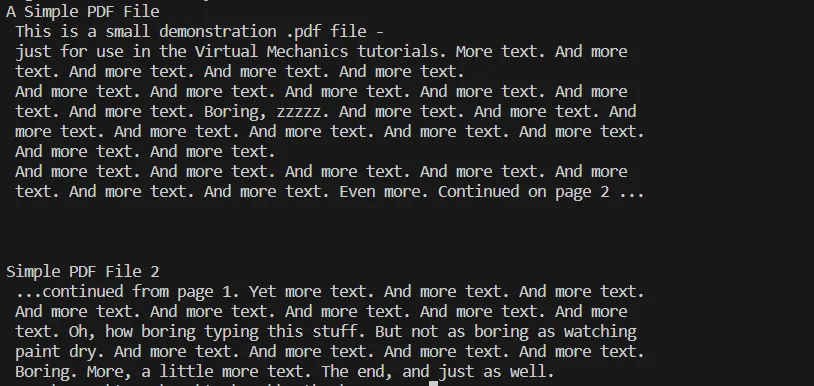 PDFファイルからテキストを抽出する上記のプロセスのコンソール出力
PDFファイルからテキストを抽出する上記のプロセスのコンソール出力
ステップ7: 追加操作(オプション)
IronPDF の機能はテキスト抽出だけにとどまりません。 プロジェクトの要件に応じて、PDF の編集、PDF から別の形式への変換、HTML からの PDF の生成などの追加機能を検討できます。
4. 高度なテクニック
4.1 非テキスト要素の処理
スキャンしたPDFには、画像やグラフなど、テキスト以外の要素が含まれていることがよくあります。OCRはテキストに重点を置きますが、これらの要素を別の方法で処理したい場合があります。 テキスト以外のコンテンツを処理または無視するには、追加の Python ライブラリが必要になる場合があります。
4.2 OCR精度の向上
テキスト抽出の精度は、スキャンされたドキュメントの品質によって異なります。 OCR の結果を改善するには、スキャンした PDF が高品質であり、テキストが可能な限り鮮明であることを確認してください。
4.3 他の形式への変換
PDF からテキストを抽出した後、さらに処理するために CSV、JSON、XML などの他の形式に変換する必要がある場合があります。 IronPDF ではこのような変換が可能で、柔軟なデータ処理オプションが提供されます。
5. よくある問題のトラブルシューティング
OCR とテキスト抽出を使用する場合、次のような問題が発生する可能性があります。
- スキャン品質が低いため、OCR の精度が低くなります。
- OCR が一部の文字を認識できない場合、テキストが欠落します。
- 大きな PDF ファイルの読み込み中にエラーが発生しました。
これらの問題を解決するには、スキャンした PDF ファイルが鮮明で高品質であることを確認し、大きなファイルを小さなファイルに分割することを検討し、 IronPDFライブラリが最新であることを確認します。
結論
スキャンされた PDF ファイルからテキストを抽出することは、 IronPDF Python ライブラリを使用してシームレスに実行できます。 このチュートリアルで説明されている手順に従うと、検索不可能なスキャンされたドキュメントを、すぐに処理および分析できるテキストが豊富な形式に変換できます。 PDFの各ページを丁寧に扱い、OCRを適用してスキャンしたPDFを検索可能なPDFファイルに変換してください。抽出されたテキストがあれば、データの操作と活用の可能性は無限に広がり、革新的なソリューションと合理化されたワークフローへの道が開かれます。
要約すると、この記事では、IronPDF のインストールとセットアップ、PDF ファイルの読み込み、スキャンした PDF を検索可能にするための OCR テクノロジの適用、実際のテキスト抽出プロセス、複数の PDF ページの処理について説明しました。 また、高度なテクニックや一般的な問題のトラブルシューティングについても触れました。 この知識があれば、Python を使用して PDF ドキュメントからテキスト データを抽出できます。
IronPDF は、フル機能にアクセスできる無料トライアルを提供しており、ユーザーは PDF 操作やテキスト抽出機能を評価できます。 トライアル後、$799より有料ライセンスが始まり、プロフェッショナルおよび商業用途に対応した包括的な機能セットを提供します。 IronPDFは開発に無料で使用できるため、開発者はアプリケーション開発段階でコストをかけずにその機能を統合およびテストできます。
よくある質問
Python を使用してスキャンされた PDF からテキストを抽出するために環境をどのように設定するのですか?
.NET 6.0 SDK と IronPDF ライブラリを Python のパッケージマネージャーで pip install ironpdf を使用してインストールし、Python 環境と Visual Studio Code や PyCharm などの適切な開発環境を用意します。
光学式文字認識(OCR)とは何であり、Pythonでどのように適用されますか?
光学文字認識 (OCR) は、スキャンされた紙のドキュメントや PDF などのさまざまな種類のドキュメントを編集可能で検索可能なデータに変換する技術です。Python では、IronPDF を使用してスキャンされた PDF をロードし、ライブラリの OCR 機能を使用してテキストを抽出することができます。
スキャンされた PDF からの正確なテキスト抽出をどのように保証できますか?
正確なテキスト抽出を確実にするには、高品質のスキャン PDF を使用してください。スキャンのクリアでより良い品質により OCR の精度が向上します。IronPDF を使用して OCR を適用し、必要に応じてテキストを抽出および処理します。
IronPDF を使用してスキャンされた PDF からテキストを抽出する際に含まれるステップは何ですか?
ステップには、IronPDF のインストール、ライブラリのインポート、ライセンスキーの適用、スキャンされた PDF の読み込み、OCR の適用、および ExtractAllText() メソッドを使用してテキストを抽出することが含まれます。
抽出されたテキストを CSV、JSON、XML などの形式に変換できますか?
はい、IronPDF を使用してスキャンされた PDF からテキストを抽出した後で、CSV、JSON、XML などのさまざまな形式に変換してさらなる分析やデータ操作を行うことができます。
テキスト抽出に失敗した場合の一般的なトラブルシューティング手順にはどのようなものがありますか?
テキスト抽出に失敗した場合は、スキャンされた PDF の品質を確認してください。IronPDF が正しくインストールされているか、開発環境が適切に設定されているか確認してください。また、正しいメソッドと OCR 機能が使用されていることを確認してください。
IronPDF の試用版はありますか?
はい、IronPDF はその機能をテストするためにユーザーに無料試用版を提供しています。試用期間後の完全な機能には有料ライセンスが必要です。
















