
Parseint C# (Jak to działa dla deweloperów)
Podczas pracy z danymi w języku C# programiści często muszą konwertować tekstowe reprezentacje liczb na liczby całkowite. Zadanie to, znane jako "parsowanie liczb całkowitych", ma kluczowe znaczenie dla różnych aplikacji, od przetwarzania danych wprowadzanych przez użytkownika po wyodrębnianie danych z plików takich jak PDF. Chociaż język C# zapewnia potężne metody analizowania liczb całkowitych, proces ten może stać się bardziej złożony podczas pracy z danymi nieustrukturyzowanymi lub częściowo ustrukturyzowanymi, takimi jak te występujące w plikach PDF.
W tym miejscu do gry wkracza IronPDF, solidna biblioteka PDF dla programistów .NET. Dzięki IronPDF możesz wyodrębnić tekst z plików PDF i wykorzystać możliwości parsowania języka C#, aby przekształcić ten tekst w użyteczne dane liczbowe. Niezależnie od tego, czy analizujesz faktury, raporty czy formularze, połączenie narzędzi do parsowania języka C# z IronPDF upraszcza obsługę danych PDF, umożliwiając konwersję liczb sformatowanych jako ciągi znaków na liczby całkowite.
W tym artykule przyjrzymy się, jak funkcja ParseInt jest używana w języku C# do konwersji ciągów znaków reprezentujących liczby na liczby całkowite oraz jak IronPDF może usprawnić proces wyodrębniania i analizowania danych liczbowych z plików PDF.
Czym jest ParseInt w języku C#?
Podstawy analizowania liczb całkowitych
W języku C# konwersja wartości ciągu znaków (np. "123") na liczbę całkowitą odbywa się zazwyczaj za pomocą int.Parse() lub Convert.ToInt32(). Metody te pomagają programistom przekształcić dane tekstowe w wartości liczbowe, które można wykorzystać do obliczeń i walidacji.
- int.Parse(string s): Konwertuje ciąg znaków na liczbę całkowitą. Wywołuje wyjątek, jeśli ciąg znaków nie jest prawidłową liczbą całkowitą.
- Convert.ToInt32(string s): Konwertuje ciąg znaków na liczbę całkowitą, traktując wartości null w różny sposób.
Oto przykład konwersji ciągów znaków przy użyciu int.Parse():
string numberString = "123";
// Convert the string to an integer using int.Parse
int num = int.Parse(numberString);
Console.WriteLine(num); // Output: 123string numberString = "123";
// Convert the string to an integer using int.Parse
int num = int.Parse(numberString);
Console.WriteLine(num); // Output: 123Dim numberString As String = "123"
' Convert the string to an integer using int.Parse
Dim num As Integer = Integer.Parse(numberString)
Console.WriteLine(num) ' Output: 123Alternatywnie, korzystając z klasy Convert:
string numericString = "123";
// Convert the string to an integer using Convert.ToInt32
int result = Convert.ToInt32(numericString);
Console.WriteLine(result); // Outputs: 123string numericString = "123";
// Convert the string to an integer using Convert.ToInt32
int result = Convert.ToInt32(numericString);
Console.WriteLine(result); // Outputs: 123Dim numericString As String = "123"
' Convert the string to an integer using Convert.ToInt32
Dim result As Integer = Convert.ToInt32(numericString)
Console.WriteLine(result) ' Outputs: 123Klasa Convert pozwala na bezpieczną konwersję ciągów znaków i innych typów danych. Jest to szczególnie przydatne, gdy zmienna typu string może reprezentować wartość null lub nieprawidłową, ponieważ Convert.ToInt32() zwraca wartość domyślną (w tym przypadku 0) zamiast zgłaszać wyjątek.
Wartość domyślna i obsługa błędów
Jednym z problemów, z którymi programiści często się spotykają podczas konwersji ciągów znaków na liczby całkowite, jest obsługa nieprawidłowych lub nienumerycznych danych wejściowych. Jeśli reprezentacja liczbowa nie ma prawidłowego formatu, metody takie jak int.Parse() wygenerują wyjątek. Jednak Convert.ToInt32() posiada wbudowany mechanizm awaryjny dla nieprawidłowych ciągów znaków.
Oto przykład pokazujący, jak postępować z wartościami domyślnymi podczas parsowania:
string invalidString = "abc";
// Convert will return 0 instead of throwing an exception for invalid input
int result = Convert.ToInt32(invalidString);
Console.WriteLine(result); // Outputs: 0string invalidString = "abc";
// Convert will return 0 instead of throwing an exception for invalid input
int result = Convert.ToInt32(invalidString);
Console.WriteLine(result); // Outputs: 0Dim invalidString As String = "abc"
' Convert will return 0 instead of throwing an exception for invalid input
Dim result As Integer = Convert.ToInt32(invalidString)
Console.WriteLine(result) ' Outputs: 0Jeśli chcesz konwertować ciągi znaków z większą kontrolą, możesz użyć funkcji int.TryParse(), która zwraca wartość logiczną wskazującą, czy konwersja zakończyła się powodzeniem:
string invalidInput = "abc";
// Attempt to parse using TryParse, which avoids exceptions for invalid input
if (int.TryParse(invalidInput, out int result))
{
Console.WriteLine(result);
}
else
{
Console.WriteLine("Parsing failed.");
}string invalidInput = "abc";
// Attempt to parse using TryParse, which avoids exceptions for invalid input
if (int.TryParse(invalidInput, out int result))
{
Console.WriteLine(result);
}
else
{
Console.WriteLine("Parsing failed.");
}Dim invalidInput As String = "abc"
' Attempt to parse using TryParse, which avoids exceptions for invalid input
Dim result As Integer
If Integer.TryParse(invalidInput, result) Then
Console.WriteLine(result)
Else
Console.WriteLine("Parsing failed.")
End IfW tym przypadku TryParse() wykorzystuje parametr wyjściowy do przechowywania przekonwertowanej liczby całkowitej, co pozwala metodzie zwrócić wartość bez generowania wyjątku. Jeśli konwersja się nie powiedzie, zamiast zwykłego awarii programu zostanie wykonana instrukcja else. W przeciwnym razie program wyświetli wynik pomyślnie przeanalizowanej liczby z ciągu wejściowego. Użycie int.TryParse może być pomocne w przypadkach, gdy spodziewane są błędy konwersji i chcesz uniknąć awarii programu.
Parsowanie danych z plików PDF przy użyciu IronPDF
Dlaczego warto używać IronPDF do analizowania danych?
Podczas pracy z plikami PDF mogą pojawić się tabele lub tekst nieustrukturyzowany zawierający dane liczbowe w postaci ciągów znaków. Aby wyodrębnić i przetworzyć te dane, kluczowe znaczenie ma konwersja ciągów znaków na liczby całkowite. IronPDF sprawia, że proces ten jest prosty, oferując zarówno elastyczność, jak i możliwości odczytu treści plików PDF oraz wykonywania operacji, takich jak konwersja ciągów znaków na wartości liczbowe.
Oto niektóre z kluczowych funkcji oferowanych przez IronPDF:
- Konwersja HTML do PDF: IronPDF może konwertować treści HTML (w tym CSS, obrazy i JavaScript) na w pełni sformatowane pliki PDF. Jest to szczególnie przydatne do renderowania dynamicznych stron internetowych lub raportów w formacie PDF.
- Edycja plików PDF: Dzięki IronPDF możesz modyfikować istniejące dokumenty PDF, dodając tekst, obrazy i grafikę, a także edytując zawartość istniejących stron.
- Wyodrębnianie tekstu i obrazów: Biblioteka umożliwia wyodrębnianie tekstu i obrazów z plików PDF, ułatwiając parsowanie i analizę treści plików PDF.
- Znak wodny: Możliwe jest również dodawanie znaków wodnych do dokumentów PDF w celu budowania marki lub ochrony praw autorskich.
Pierwsze kroki z IronPDF
Aby rozpocząć korzystanie z IronPDF, należy najpierw zainstalować program. Jeśli biblioteka jest już zainstalowana, możesz przejść do następnej sekcji, w przeciwnym razie poniższe kroki opisują sposób instalacji biblioteki IronPDF.
Za pośrednictwem konsoli menedżera pakietów NuGet
Aby zainstalować IronPDF za pomocą konsoli menedżera pakietów NuGet, otwórz program Visual Studio i przejdź do konsoli menedżera pakietów. Następnie uruchom następujące polecenie:
// Command to install IronPDF package via the Package Manager Console
Install-Package IronPdfZa pośrednictwem menedżera pakietów NuGet dla Solution
Po uruchomieniu programu Visual Studio przejdź do "Narzędzia -> Menedżer pakietów NuGet -> Zarządzaj pakietami NuGet dla rozwiązania" i wyszukaj IronPDF. Teraz wystarczy wybrać projekt i kliknąć "Zainstaluj", a IronPDF zostanie dodany do projektu.
Po zainstalowaniu IronPDF wystarczy dodać odpowiednią instrukcję using na początku kodu, aby rozpocząć korzystanie z IronPDF:
using IronPdf;using IronPdf;Imports IronPdfOdblokowanie bezpłatnej wersji próbnej
IronPDF oferuje bezpłatną wersję próbną z pełnym dostępem do wszystkich funkcji. Odwiedź stronę internetową IronPDF, aby pobrać wersję próbną i rozpocząć integrację zaawansowanej obsługi plików PDF z projektami .NET.
Przykład: Wyodrębnianie i analizowanie liczb z pliku PDF
Poniższy kod w języku C# pokazuje, jak użyć IronPDF do wyodrębnienia tekstu z pliku PDF, a następnie użyć wyrażeń regularnych do znalezienia i przeanalizowania wszystkich wartości liczbowych w wyodrębnionym tekście. Kod obsługuje zarówno liczby całkowite, jak i dziesiętne, usuwając znaki nienumeryczne, takie jak symbole walut.
using IronPdf;
using System.Text.RegularExpressions;
public class Program
{
public static void Main(string[] args)
{
// Load a PDF file
PdfDocument pdf = PdfDocument.FromFile("example.pdf");
// Extract all text from the PDF
string text = pdf.ExtractAllText();
// Print the extracted text (for reference)
Console.WriteLine("Extracted Text: ");
Console.WriteLine(text);
// Parse and print all numbers found in the extracted text
Console.WriteLine("\nParsed Numbers:");
// Use regular expression to find all number patterns, including integers and decimals
var numberMatches = Regex.Matches(text, @"\d+(\.\d+)?");
// Iterate through all matched numbers and print them
foreach (Match match in numberMatches)
{
// Print each matched number
Console.WriteLine($"{match.Value}");
}
}
}using IronPdf;
using System.Text.RegularExpressions;
public class Program
{
public static void Main(string[] args)
{
// Load a PDF file
PdfDocument pdf = PdfDocument.FromFile("example.pdf");
// Extract all text from the PDF
string text = pdf.ExtractAllText();
// Print the extracted text (for reference)
Console.WriteLine("Extracted Text: ");
Console.WriteLine(text);
// Parse and print all numbers found in the extracted text
Console.WriteLine("\nParsed Numbers:");
// Use regular expression to find all number patterns, including integers and decimals
var numberMatches = Regex.Matches(text, @"\d+(\.\d+)?");
// Iterate through all matched numbers and print them
foreach (Match match in numberMatches)
{
// Print each matched number
Console.WriteLine($"{match.Value}");
}
}
}Imports Microsoft.VisualBasic
Imports IronPdf
Imports System.Text.RegularExpressions
Public Class Program
Public Shared Sub Main(ByVal args() As String)
' Load a PDF file
Dim pdf As PdfDocument = PdfDocument.FromFile("example.pdf")
' Extract all text from the PDF
Dim text As String = pdf.ExtractAllText()
' Print the extracted text (for reference)
Console.WriteLine("Extracted Text: ")
Console.WriteLine(text)
' Parse and print all numbers found in the extracted text
Console.WriteLine(vbLf & "Parsed Numbers:")
' Use regular expression to find all number patterns, including integers and decimals
Dim numberMatches = Regex.Matches(text, "\d+(\.\d+)?")
' Iterate through all matched numbers and print them
For Each match As Match In numberMatches
' Print each matched number
Console.WriteLine($"{match.Value}")
Next match
End Sub
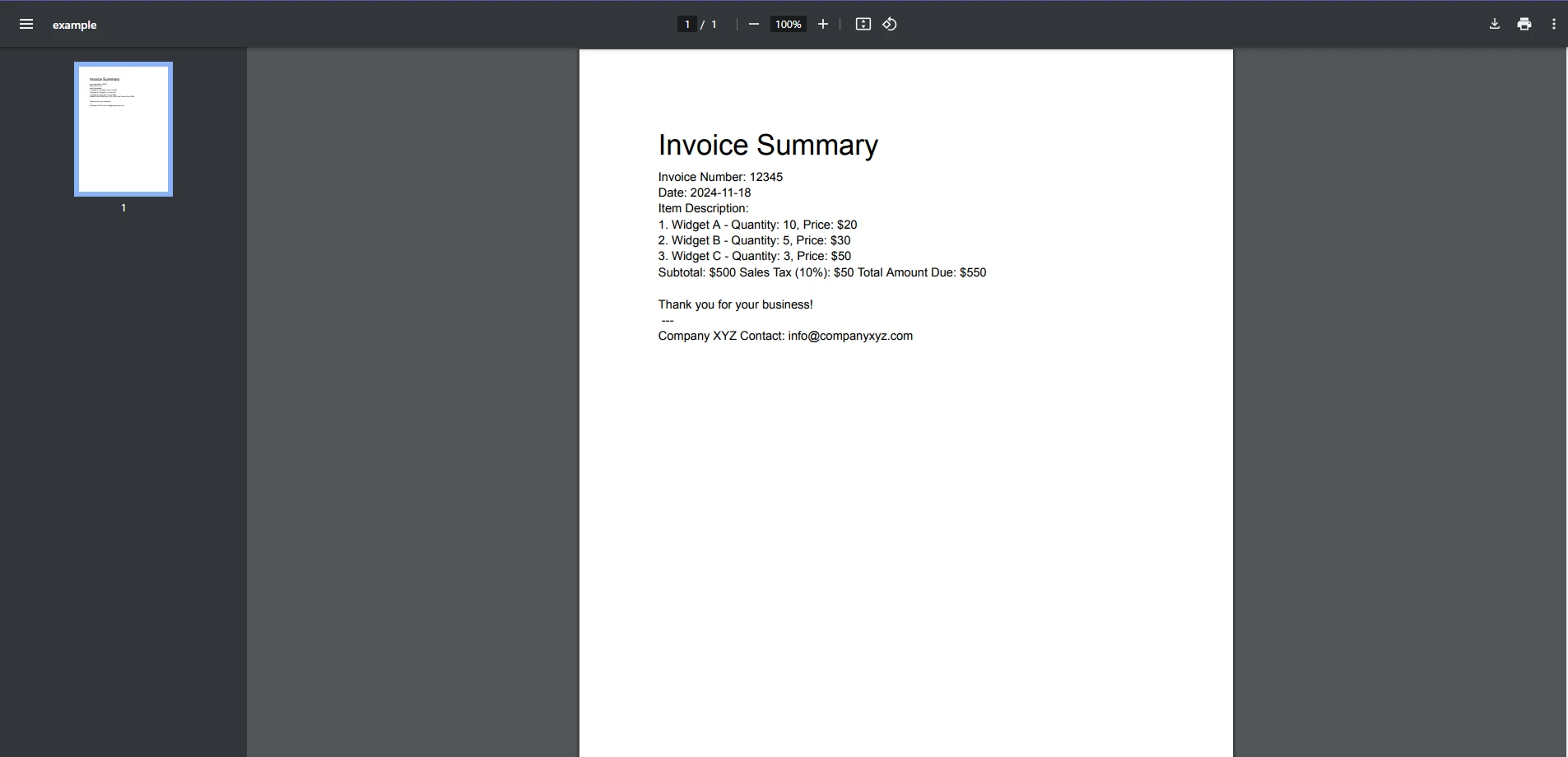
End ClassPlik wejściowy PDF
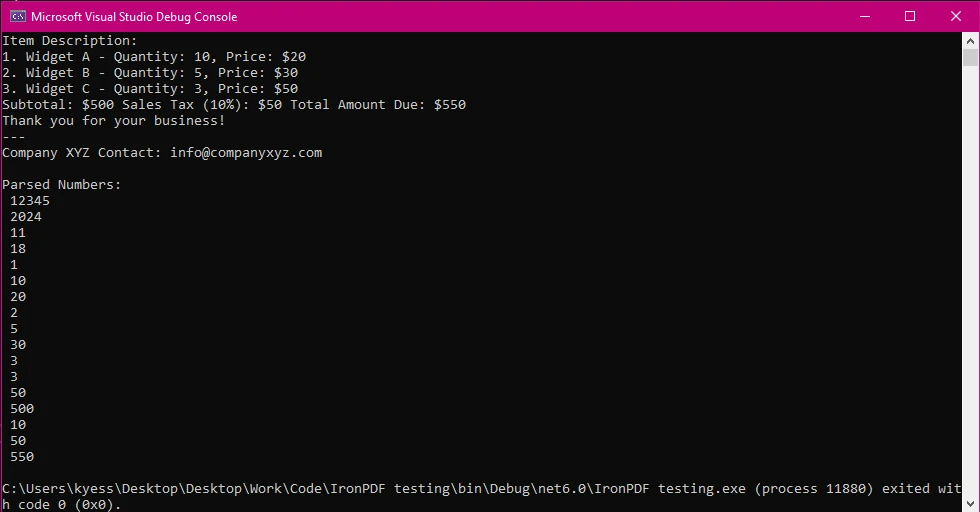
Wynik konsoli
Wyjaśnienie kodu
-
Wyodrębnianie tekstu z plików PDF:
Kod rozpoczyna się od załadowania pliku PDF przy użyciu IronPDF. Następnie wyodrębnia cały tekst z pliku PDF.
-
Wykorzystanie wyrażeń regularnych do wyszukiwania liczb:
Kod wykorzystuje wyrażenie regularne (wzorzec dopasowujący tekst) do przeszukiwania wyodrębnionego tekstu i wyszukiwania wszelkich liczb. Wyrażenie regularne wyszukuje zarówno liczby całkowite (np. 12345), jak i liczby dziesiętne (np. 50,75).
-
Analiza i drukowanie liczb:
Po znalezieniu liczb program PRINTuje każdą z nich w konsoli. Obejmuje to liczby całkowite i ułamkowe.
-
Dlaczego wyrażenia regularne:
Wykorzystuje się wyrażenia regularne, ponieważ są one potężnymi narzędziami do wyszukiwania wzorców w tekście, takich jak liczby. Potrafią obsługiwać liczby z symbolami (takimi jak symbole walut $), co sprawia, że proces jest bardziej elastyczny.
Typowe wyzwania i sposoby ich rozwiązywania przez IronPDF
Pobieranie czystych danych ze złożonych struktur PDF często skutkuje wartościami typu string, które mogą wymagać dalszego przetwarzania, takiego jak konwersja ciągów znaków na liczby całkowite. Oto kilka typowych wyzwań i sposoby, w jakie IronPDF może pomóc:
Nieprawidłowe formaty w plikach PDF
Pliki PDF często zawierają liczby sformatowane jako tekst (np. "1,234.56" lub "12,345 USD"). Aby przetworzyć je poprawnie, należy upewnić się, że reprezentacja ciągu znaków liczby ma format odpowiedni do parsowania. IronPDF pozwala na czyste wyodrębnianie tekstu, a przed konwersją można użyć metod manipulacji ciągami znaków (np. Replace()) w celu dostosowania formatowania.
Przykład:
string formattedNumber = "1,234.56"; // String value with commas
// Remove commas from the string to clean it
string cleanNumber = formattedNumber.Replace(",", "");
// Convert the cleaned string to an integer by first converting to double then to integer
int result = Convert.ToInt32(Convert.ToDouble(cleanNumber));
Console.WriteLine(result); // Outputs: 1234string formattedNumber = "1,234.56"; // String value with commas
// Remove commas from the string to clean it
string cleanNumber = formattedNumber.Replace(",", "");
// Convert the cleaned string to an integer by first converting to double then to integer
int result = Convert.ToInt32(Convert.ToDouble(cleanNumber));
Console.WriteLine(result); // Outputs: 1234Dim formattedNumber As String = "1,234.56" ' String value with commas
' Remove commas from the string to clean it
Dim cleanNumber As String = formattedNumber.Replace(",", "")
' Convert the cleaned string to an integer by first converting to double then to integer
Dim result As Integer = Convert.ToInt32(Convert.ToDouble(cleanNumber))
Console.WriteLine(result) ' Outputs: 1234Obsługa wielu wartości liczbowych w tekście
W złożonym pliku PDF wartości liczbowe mogą występować w różnych formatach lub być rozproszone w różnych miejscach. Dzięki IronPDF można wyodrębnić cały tekst, a następnie użyć wyrażeń regularnych, aby skutecznie wyszukiwać i konwertować ciągi znaków na liczby całkowite.
Wnioski
Analiza liczb całkowitych w języku C# jest niezbędną umiejętnością dla programistów, zwłaszcza podczas pracy z danymi wprowadzanymi przez użytkownika lub podczas pozyskiwania danych z różnych źródeł. Chociaż wbudowane metody, takie jak int.Parse() i Convert.ToInt32(), są przydatne, obsługa danych nieustrukturyzowanych lub częściowo ustrukturyzowanych — takich jak tekst w plikach PDF — może stanowić dodatkowe wyzwanie. W tym miejscu do gry wkracza IronPDF, oferując potężne i proste w obsłudze rozwiązanie do wyodrębniania tekstu z plików PDF i pracy z nim w aplikacjach .NET.
Korzystając z IronPDF, zyskujesz możliwość łatwego wyodrębniania tekstu ze złożonych plików PDF, w tym ze skanowanych dokumentów, oraz konwertowania tych danych na użyteczne wartości liczbowe. Dzięki funkcjom takim jak OCR dla zeskanowanych plików PDF oraz solidnym narzędziom do ekstrakcji tekstu, IronPDF pozwala usprawnić przetwarzanie danych, nawet w trudnych formatach.
Niezależnie od tego, czy masz do czynienia z fakturami, raportami finansowymi czy innymi dokumentami zawierającymi dane liczbowe, połączenie metod ParseInt języka C# z IronPDF pomoże Ci pracować wydajniej i dokładniej.
Nie pozwól, aby skomplikowane pliki PDF spowalniały proces tworzenia oprogramowania — rozpoczęcie korzystania z IronPDF to doskonała okazja, aby sprawdzić, w jaki sposób IronPDF może usprawnić Twój przepływ pracy, więc dlaczego nie wypróbować go i przekonać się, jak może usprawnić Twój następny projekt?
Często Zadawane Pytania
Jak przekonwertować ciąg znaków na liczbę całkowitą w języku C#?
W języku C# można przekonwertować ciąg znaków na liczbę całkowitą za pomocą metody int.Parse() lub Convert.ToInt32(). Metoda int.Parse() zgłasza wyjątek, jeśli ciąg znaków nie jest prawidłową liczbą całkowitą, natomiast Convert.ToInt32() zwraca 0 dla wartości null.
Jakie są różnice między int.Parse() a Convert.ToInt32()?
int.Parse() służy do bezpośredniej konwersji ciągu znaków na liczbę całkowitą i zgłasza wyjątek w przypadku nieprawidłowych formatów. Convert.ToInt32() może obsługiwać wartości null, zwracając domyślną wartość 0, co sprawia, że jest bezpieczniejsza dla niektórych aplikacji.
W jaki sposób int.TryParse() usprawnia obsługę błędów podczas parsowania?
int.TryParse() usprawnia obsługę błędów, zwracając wartość logiczną wskazującą powodzenie lub niepowodzenie konwersji, a także wykorzystuje parametr wyjściowy do zapisania wyniku bez generowania wyjątków w przypadku nieprawidłowych danych wejściowych.
W jaki sposób IronPDF może pomóc w wyodrębnianiu tekstu z plików PDF w celu analizy?
IronPDF upraszcza wyodrębnianie tekstu z plików PDF, oferując solidne funkcje, takie jak wyodrębnianie tekstu i obrazów, co pozwala programistom na łatwy dostęp do danych tekstowych w celu ich przetworzenia na wartości liczbowe za pomocą języka C#.
Jakie kroki trzeba wykonać, żeby zainstalować bibliotekę PDF, taką jak IronPDF?
Aby zainstalować IronPDF, należy użyć konsoli menedżera pakietów NuGet w Visual Studio i uruchomić polecenie Install-Package IronPdf lub skorzystać z okna menedżera pakietów NuGet w celu wyszukania i zainstalowania biblioteki.
Jakie wyzwania mogą pojawić się podczas analizowania danych liczbowych z plików PDF?
Analiza danych liczbowych z plików PDF może stanowić wyzwanie ze względu na problemy z formatowaniem, takie jak przecinki i zróżnicowane wzorce liczbowe. IronPDF pomaga w tym, umożliwiając czyste wyodrębnianie tekstu, który można następnie przetwarzać za pomocą wyrażeń regularnych.
W jaki sposób wyrażenia regularne mogą pomóc w pozyskiwaniu danych liczbowych z plików PDF?
Wyrażenia regularne pozwalają programistom identyfikować wzorce w tekście, takie jak liczby z symbolami, ułatwiając wyodrębnianie i konwersję danych liczbowych z tekstu PDF wyodrębnionego za pomocą IronPDF.
Czy możliwe jest wyodrębnienie tekstu ze skanowanych dokumentów PDF?
Tak, IronPDF zawiera funkcje OCR (optycznego rozpoznawania znaków), które umożliwiają wyodrębnianie tekstu ze skanowanych plików PDF, przekształcając zeskanowane obrazy w edytowalny i przeszukiwalny tekst.
Jakie korzyści zapewniają wyrażenia regularne w połączeniu z IronPDF?
Wyrażenia regularne uzupełniają IronPDF, umożliwiając elastyczne wyszukiwanie tekstu i dopasowywanie wzorców, co jest niezbędne do obsługi złożonych scenariuszy ekstrakcji tekstu, takich jak wyszukiwanie i konwersja liczb.














