
Parseint C#(开发者用法)
在 C# 中处理数据时,开发人员经常需要将数字的文本表示转换为整数。 这个任务被称为"解析整数",对于各种应用程序至关重要,从处理用户输入到从 PDF 等文件中提取数据。 尽管 C# 提供了功能强大的解析整数的方法,但在处理非结构化或半结构化数据时,如 PDF 中的内容,过程可能变得更加复杂。
这就是IronPDF的用武之地,这是为 .NET 开发人员设计的强大 PDF 库。 使用 IronPDF,您可以从 PDF 中提取文本,并利用 C# 的解析能力将这些文本转化为可用的数字数据。 无论您是在分析发票、报告还是表单,将 C# 的解析工具与 IronPDF 相结合,简化了 PDF 数据的处理,允许您将字符串格式的数字转换为整数。
在本文中,我们将深入探讨在 C# 中如何使用 ParseInt 将数字的字符串表示转换为整数,以及 IronPDF 如何简化从 PDF 中提取和解析数字数据的过程。
C# 中的 ParseInt 有什么作用?
解析整数的基础知识
在 C# 中,将字符串值(例如"123")转换为整数通常使用 int.Parse() 或 Convert.ToInt32() 来完成。 这些方法帮助开发人员将文本数据转换为可用的数字值,用于计算和验证。
- int.Parse(string s):将字符串转换为整数。 如果字符串不是有效的整数,则抛出异常。
- Convert.ToInt32(string s):将字符串转换为整数,对空输入进行特殊处理。
以下是使用 int.Parse() 转换字符串的示例:
string numberString = "123";
// Convert the string to an integer using int.Parse
int num = int.Parse(numberString);
Console.WriteLine(num); // Output: 123string numberString = "123";
// Convert the string to an integer using int.Parse
int num = int.Parse(numberString);
Console.WriteLine(num); // Output: 123Dim numberString As String = "123"
' Convert the string to an integer using int.Parse
Dim num As Integer = Integer.Parse(numberString)
Console.WriteLine(num) ' Output: 123或者,使用 Convert 类:
string numericString = "123";
// Convert the string to an integer using Convert.ToInt32
int result = Convert.ToInt32(numericString);
Console.WriteLine(result); // Outputs: 123string numericString = "123";
// Convert the string to an integer using Convert.ToInt32
int result = Convert.ToInt32(numericString);
Console.WriteLine(result); // Outputs: 123Dim numericString As String = "123"
' Convert the string to an integer using Convert.ToInt32
Dim result As Integer = Convert.ToInt32(numericString)
Console.WriteLine(result) ' Outputs: 123Convert 类允许您安全地转换字符串和其他数据类型。 当字符串变量可能表示空值或无效值时,它尤其有用,因为 Convert.ToInt32() 返回默认值(本例中为 0),而不是抛出异常。
默认值和错误处理
开发人员在将字符串转换为整数时经常遇到的一个问题是处理无效或非数字输入。 如果数字的字符串表示形式不正确,则类似 int.Parse() 的方法会抛出异常。 但是,Convert.ToInt32() 具有针对无效字符串的内置回退机制。
以下是如何在解析时处理默认值的示例:
string invalidString = "abc";
// Convert will return 0 instead of throwing an exception for invalid input
int result = Convert.ToInt32(invalidString);
Console.WriteLine(result); // Outputs: 0string invalidString = "abc";
// Convert will return 0 instead of throwing an exception for invalid input
int result = Convert.ToInt32(invalidString);
Console.WriteLine(result); // Outputs: 0Dim invalidString As String = "abc"
' Convert will return 0 instead of throwing an exception for invalid input
Dim result As Integer = Convert.ToInt32(invalidString)
Console.WriteLine(result) ' Outputs: 0如果您希望更精确地控制字符串转换,可以使用int.TryParse(),它返回一个布尔值,指示转换是否成功:
string invalidInput = "abc";
// Attempt to parse using TryParse, which avoids exceptions for invalid input
if (int.TryParse(invalidInput, out int result))
{
Console.WriteLine(result);
}
else
{
Console.WriteLine("Parsing failed.");
}string invalidInput = "abc";
// Attempt to parse using TryParse, which avoids exceptions for invalid input
if (int.TryParse(invalidInput, out int result))
{
Console.WriteLine(result);
}
else
{
Console.WriteLine("Parsing failed.");
}Dim invalidInput As String = "abc"
' Attempt to parse using TryParse, which avoids exceptions for invalid input
Dim result As Integer
If Integer.TryParse(invalidInput, result) Then
Console.WriteLine(result)
Else
Console.WriteLine("Parsing failed.")
End If在这种情况下,TryParse() 使用 out 参数来存储转换后的整数,这使得该方法能够在不抛出异常的情况下返回一个值。 如果转换失败,则会运行 else 语句,而不是简单地使程序崩溃。 否则,该程序将显示从输入字符串成功解析的数字结果。 在预期会出现转换失败且您希望避免程序崩溃的情况下,使用 int.TryParse 可能会有所帮助。
使用 IronPDF 解析 PDF 数据
为什么使用 IronPDF 解析数据?
处理 PDF 时,您可能会遇到包含数字数据的字符串值的表格或非结构化文本。 为了提取和处理这些数据,将字符串转换为整数至关重要。 IronPDF 使这一过程变得简单明了,提供了读写 PDF 内容并执行诸如将字符串转换为数字值等操作所需的灵活性和强大功能。
以下是IronPDF提供的一些关键特性:
IronPDF入门
要开始使用 IronPDF,您首先需要安装它。 如果它已经安装,您可以跳到下一部分,否则,以下步骤介绍如何安装IronPDF库。
通过 NuGet 包管理器控制台
要使用 NuGet 包管理器控制台安装 IronPDF,打开 Visual Studio 并导航到包管理器控制台。 然后运行以下命令:
// Command to install IronPDF package via the Package Manager Console
Install-Package IronPdf通过解决方案的 NuGet 包管理器
打开 Visual Studio,转到 "工具 -> NuGet 包管理器 -> 为解决方案管理 NuGet 包",然后搜索 IronPDF。 在这里,您只需选择您的项目并点击"安装",IronPDF 就会被添加到您的项目中。
一旦您安装了 IronPDF,您所需添加的全部内容就是在代码顶部添加正确的 using 语句以开始使用 IronPDF:
using IronPdf;using IronPdf;Imports IronPdf解锁免费试用
IronPDF 提供免费试用,您可以完全访问其功能。 访问IronPDF 网站下载试用版,并开始将高级 PDF 处理集成到您的 .NET 项目中。
示例:从 PDF 提取和解析数字
以下 C# 代码演示了如何使用 IronPDF 从 PDF 中提取文本,然后使用正则表达式查找并解析提取文本中的所有数值。 该代码处理整数和小数,清除非数字字符如货币符号。
using IronPdf;
using System.Text.RegularExpressions;
public class Program
{
public static void Main(string[] args)
{
// Load a PDF file
PdfDocument pdf = PdfDocument.FromFile("example.pdf");
// Extract all text from the PDF
string text = pdf.ExtractAllText();
// Print the extracted text (for reference)
Console.WriteLine("Extracted Text: ");
Console.WriteLine(text);
// Parse and print all numbers found in the extracted text
Console.WriteLine("\nParsed Numbers:");
// Use regular expression to find all number patterns, including integers and decimals
var numberMatches = Regex.Matches(text, @"\d+(\.\d+)?");
// Iterate through all matched numbers and print them
foreach (Match match in numberMatches)
{
// Print each matched number
Console.WriteLine($"{match.Value}");
}
}
}using IronPdf;
using System.Text.RegularExpressions;
public class Program
{
public static void Main(string[] args)
{
// Load a PDF file
PdfDocument pdf = PdfDocument.FromFile("example.pdf");
// Extract all text from the PDF
string text = pdf.ExtractAllText();
// Print the extracted text (for reference)
Console.WriteLine("Extracted Text: ");
Console.WriteLine(text);
// Parse and print all numbers found in the extracted text
Console.WriteLine("\nParsed Numbers:");
// Use regular expression to find all number patterns, including integers and decimals
var numberMatches = Regex.Matches(text, @"\d+(\.\d+)?");
// Iterate through all matched numbers and print them
foreach (Match match in numberMatches)
{
// Print each matched number
Console.WriteLine($"{match.Value}");
}
}
}Imports Microsoft.VisualBasic
Imports IronPdf
Imports System.Text.RegularExpressions
Public Class Program
Public Shared Sub Main(ByVal args() As String)
' Load a PDF file
Dim pdf As PdfDocument = PdfDocument.FromFile("example.pdf")
' Extract all text from the PDF
Dim text As String = pdf.ExtractAllText()
' Print the extracted text (for reference)
Console.WriteLine("Extracted Text: ")
Console.WriteLine(text)
' Parse and print all numbers found in the extracted text
Console.WriteLine(vbLf & "Parsed Numbers:")
' Use regular expression to find all number patterns, including integers and decimals
Dim numberMatches = Regex.Matches(text, "\d+(\.\d+)?")
' Iterate through all matched numbers and print them
For Each match As Match In numberMatches
' Print each matched number
Console.WriteLine($"{match.Value}")
Next match
End Sub
End Class输入PDF
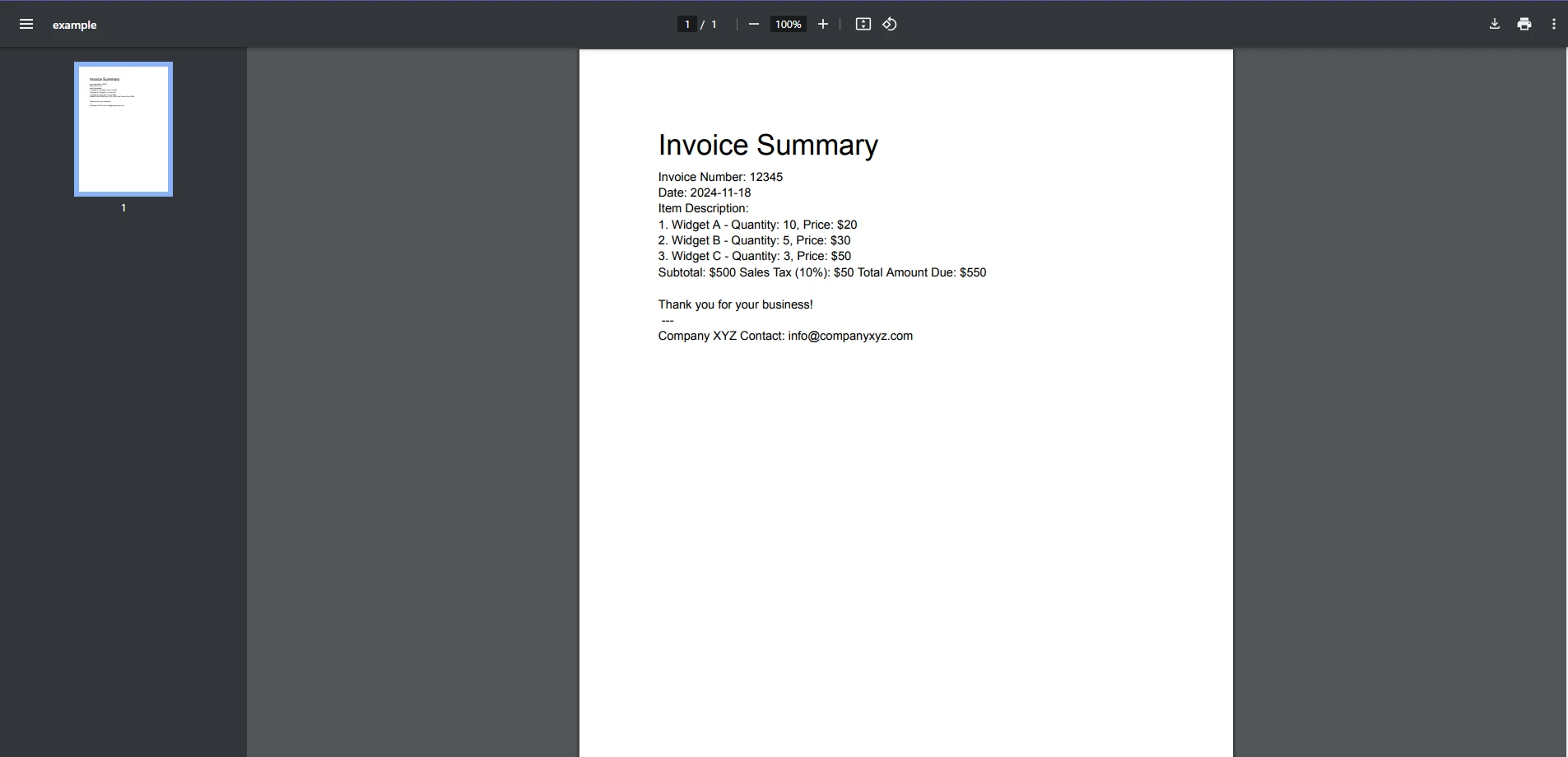
控制台输出
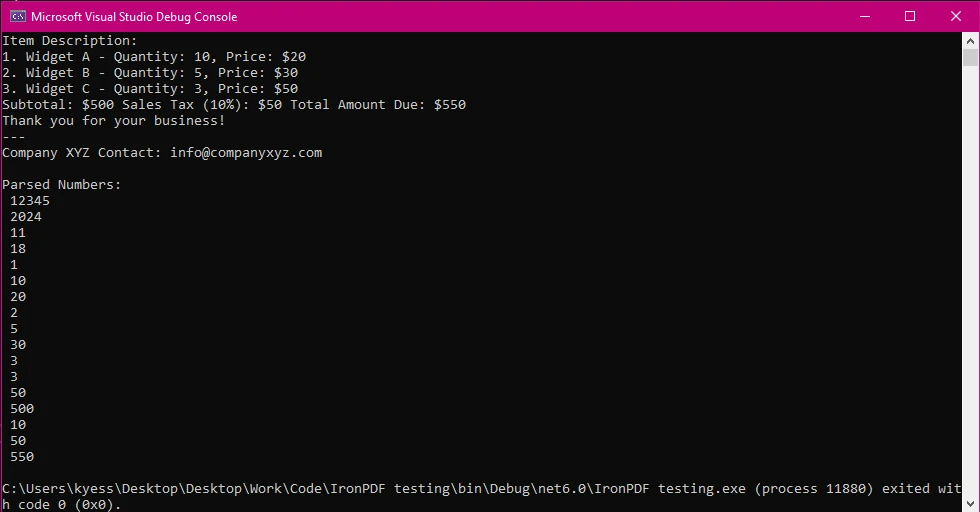
代码解释
1.从PDF中提取文本:
代码首先使用 IronPDF 加载 PDF 文件。 然后从 PDF 中提取所有文本。
2.使用正则表达式查找数字:
该代码使用正则表达式(匹配文本的模式)搜索提取文本中的所有数字。 正则表达式同时查找整数(例如,12345)和小数(例如,50.75)。
3.解析和打印数字:
找到数字后,程序将每个数字打印到控制台。 这包括整数和小数。
4.为什么需要正则表达式:
使用正则表达式是因为它们是用于查找文本中的模式(如数字)的强大工具。 它们可以处理带有符号(如货币符号 $)的数字,从而使过程更加灵活。
常见挑战及 IronPDF 的解决方案
从复杂的 PDF 结构中提取干净的数据通常会产生可能需要进一步处理的字符串值,例如将字符串转换为整数。 以下是一些常见的挑战以及 IronPDF 如何帮助解决这些问题:
PDF 中的不正确格式
PDF 通常包含格式化为文本的数字(例如,"1,234.56"或"12,345 USD")。 为了正确处理这些数字,您需要确保数字的字符串表示格式正确。 IronPDF 允许您干净地提取文本,并且您可以使用字符串操作方法(例如,Replace())在转换之前调整格式。
例:
string formattedNumber = "1,234.56"; // String value with commas
// Remove commas from the string to clean it
string cleanNumber = formattedNumber.Replace(",", "");
// Convert the cleaned string to an integer by first converting to double then to integer
int result = Convert.ToInt32(Convert.ToDouble(cleanNumber));
Console.WriteLine(result); // Outputs: 1234string formattedNumber = "1,234.56"; // String value with commas
// Remove commas from the string to clean it
string cleanNumber = formattedNumber.Replace(",", "");
// Convert the cleaned string to an integer by first converting to double then to integer
int result = Convert.ToInt32(Convert.ToDouble(cleanNumber));
Console.WriteLine(result); // Outputs: 1234Dim formattedNumber As String = "1,234.56" ' String value with commas
' Remove commas from the string to clean it
Dim cleanNumber As String = formattedNumber.Replace(",", "")
' Convert the cleaned string to an integer by first converting to double then to integer
Dim result As Integer = Convert.ToInt32(Convert.ToDouble(cleanNumber))
Console.WriteLine(result) ' Outputs: 1234处理文本中的多个数值
在复杂的 PDF 中,数字值可能以不同格式出现或分散在不同位置。 使用 IronPDF,您可以提取所有文本,然后使用正则表达式高效地查找和转换字符串为整数。
结论
在 C# 中解析整数是一项重要的技能,特别是在处理用户输入或从各种来源提取数据时。 虽然像 int.Parse() 和 Convert.ToInt32() 这样的内置方法很有用,但处理非结构化或半结构化数据(例如 PDF 中的文本)可能会带来额外的挑战。 这就是 IronPDF 发挥作用的地方,提供了一种强大而简单的解决方案,用于从 PDF 中提取文本并在 .NET 应用程序中使用。
通过使用IronPDF,您可以轻松地从复杂的 PDF 中提取文本,包括扫描文档,并将这些数据转换为可用的数字值。 IronPDF 提供的功能如扫描 PDF 的OCR 和强大的文本提取工具允许您简化数据处理,即使在具有挑战性的格式下也是如此。
无论您是在处理发票、财务报告或任何其他包含数据信息的文档,将 C# 的 ParseInt 方法与 IronPDF 结合使用,将帮助您更高效准确地工作。
不要让复杂的 PDF 减慢您的开发流程——开始使用IronPDF 是探索 IronPDF 如何增强工作流程的绝佳机会,为什么不尝试一下,看看它如何简化您的下一个项目?
常见问题解答
如何在 C# 中将字符串转换为整数?
在 C# 中,你可以使用 int.Parse() 方法或 Convert.ToInt32() 将字符串转换为整数。如果字符串不是有效的整数,int.Parse() 方法会抛出异常,而 Convert.ToInt32() 对于空输入返回 0。
int.Parse() 和 Convert.ToInt32() 之间有什么区别?
int.Parse() 用于直接将字符串转换为整数,并且对于无效格式会抛出异常。Convert.ToInt32() 可以通过返回默认值 0 来处理空值,使其对于某些应用程序更安全。
int.TryParse() 如何在解析过程中增强错误处理?
int.TryParse() 通过返回指示转换成功或失败的布尔值来增强错误处理,并使用 out 参数存储结果,不会为无效输入抛出异常。
IronPDF 如何帮助从 PDF 中提取文本以进行解析?
IronPDF 通过提供强大的功能,如文本和图像提取,简化了从 PDF 中提取文本,使开发人员能够轻松访问字符串数据,以便在 C# 中解析为数值。
安装像 IronPDF 这样的 PDF 库涉及哪些步骤?
要安装 IronPDF,请在 Visual Studio 中使用 NuGet 包管理器控制台运行命令 Install-Package IronPDF,或者使用 NuGet 包管理器窗口搜索并安装该库。
解析 PDF 中的数字数据可能会遇到哪些挑战?
由于格式问题如逗号和多样的数字模式,解析 PDF 中的数字数据可能具有挑战性。IronPDF 通过允许干净的文本提取来提供帮助,然后可以使用正则表达式进行处理。
正则表达式如何帮助从 PDF 中提取数字数据?
正则表达式允许开发人员识别文本中的模式,如带符号的数字,协助从使用 IronPDF 提取的 PDF 文本中提取和转换数字数据。
是否可以从扫描的 PDF 文档中提取文本?
是的,IronPDF 包含光学字符识别(OCR)功能,允许从扫描的 PDF 中提取文本,将扫描的图像转换为可编辑和可搜索的文本。
使用 IronPDF 时,正则表达式有哪些好处?
正则表达式通过启用灵活的文本搜索和模式匹配来补充 IronPDF,这对处理复杂文本提取场景至关重要,例如查找和转换数字。














