
Parseint C# (Cómo Funciona para Desarrolladores)
Al trabajar con datos en C#, los desarrolladores a menudo necesitan convertir representaciones textuales de números en enteros. Esta tarea, conocida como "análisis de enteros", es crítica para diversas aplicaciones, desde procesar la entrada del usuario hasta extraer datos de archivos como PDFs. Aunque C# proporciona métodos potentes para analizar enteros, el proceso puede volverse más complejo al trabajar con datos no estructurados o semiestructurados, como los que se encuentran en PDFs.
Ahí es donde entra en juego IronPDF, una robusta biblioteca de PDF para desarrolladores .NET. Con IronPDF, puedes extraer texto de PDFs y aprovechar las capacidades de análisis de C# para transformar este texto en datos numéricos utilizables. Ya sea que estés analizando facturas, informes o formularios, combinar las herramientas de análisis de C# con IronPDF simplifica el manejo de datos PDF, permitiéndote convertir números en formato de cadena en enteros.
En este artículo, profundizaremos en cómo se usa ParseInt en C# para convertir representaciones de cadena de números en enteros, y cómo IronPDF puede agilizar el proceso de extracción y análisis de datos numéricos de PDFs.
¿Qué es ParseInt en C#?
Los fundamentos del análisis sintáctico de números enteros
En C#, la conversión de un valor de cadena (como "123") a un entero se realiza comúnmente usando int.Parse() o Convert.ToInt32(). Estos métodos ayudan a los desarrolladores a transformar datos textuales en valores numéricos utilizables para cómputos y validaciones.
- int.Parse(string s): Convierte una cadena en un entero. Lanza una excepción si la cadena no es un entero válido.
- Convert.ToInt32(string s): Convierte una cadena en un entero y maneja las entradas nulas de manera diferente.
A continuación se muestra un ejemplo de conversión de cadenas utilizando int.Parse():
string numberString = "123";
// Convert the string to an integer using int.Parse
int num = int.Parse(numberString);
Console.WriteLine(num); // Output: 123string numberString = "123";
// Convert the string to an integer using int.Parse
int num = int.Parse(numberString);
Console.WriteLine(num); // Output: 123Dim numberString As String = "123"
' Convert the string to an integer using int.Parse
Dim num As Integer = Integer.Parse(numberString)
Console.WriteLine(num) ' Output: 123Alternativamente, usando la clase Convert:
string numericString = "123";
// Convert the string to an integer using Convert.ToInt32
int result = Convert.ToInt32(numericString);
Console.WriteLine(result); // Outputs: 123string numericString = "123";
// Convert the string to an integer using Convert.ToInt32
int result = Convert.ToInt32(numericString);
Console.WriteLine(result); // Outputs: 123Dim numericString As String = "123"
' Convert the string to an integer using Convert.ToInt32
Dim result As Integer = Convert.ToInt32(numericString)
Console.WriteLine(result) ' Outputs: 123La clase Convert le permite convertir cadenas y otros tipos de datos de manera segura. Es especialmente útil cuando la variable de cadena puede representar un valor nulo o no válido, ya que Convert.ToInt32() devuelve un valor predeterminado (0 en este caso) en lugar de generar una excepción.
Valores por defecto y gestión de errores
Un problema que los desarrolladores a menudo enfrentan al convertir cadenas en enteros es tratar con entradas inválidas o no numéricas. Si la representación de la cadena del número no tiene el formato correcto, métodos como int.Parse() generarán una excepción. Sin embargo, Convert.ToInt32() tiene un mecanismo de respaldo incorporado para cadenas no válidas.
Aquí hay un ejemplo que demuestra cómo manejar valores predeterminados al analizar:
string invalidString = "abc";
// Convert will return 0 instead of throwing an exception for invalid input
int result = Convert.ToInt32(invalidString);
Console.WriteLine(result); // Outputs: 0string invalidString = "abc";
// Convert will return 0 instead of throwing an exception for invalid input
int result = Convert.ToInt32(invalidString);
Console.WriteLine(result); // Outputs: 0Dim invalidString As String = "abc"
' Convert will return 0 instead of throwing an exception for invalid input
Dim result As Integer = Convert.ToInt32(invalidString)
Console.WriteLine(result) ' Outputs: 0Si desea convertir cadenas con más control, puede usar int.TryParse(), que devuelve un valor booleano que indica si la conversión fue exitosa o no:
string invalidInput = "abc";
// Attempt to parse using TryParse, which avoids exceptions for invalid input
if (int.TryParse(invalidInput, out int result))
{
Console.WriteLine(result);
}
else
{
Console.WriteLine("Parsing failed.");
}string invalidInput = "abc";
// Attempt to parse using TryParse, which avoids exceptions for invalid input
if (int.TryParse(invalidInput, out int result))
{
Console.WriteLine(result);
}
else
{
Console.WriteLine("Parsing failed.");
}Dim invalidInput As String = "abc"
' Attempt to parse using TryParse, which avoids exceptions for invalid input
Dim result As Integer
If Integer.TryParse(invalidInput, result) Then
Console.WriteLine(result)
Else
Console.WriteLine("Parsing failed.")
End IfEn este caso, TryParse() utiliza un parámetro de salida para almacenar el entero convertido, lo que permite que el método devuelva un valor sin generar una excepción. Si la conversión falla, la declaración else se ejecutará en lugar de simplemente hacer que tu programa se bloquee. De lo contrario, el programa mostrará el resultado del número analizado con éxito de la cadena de entrada. El uso de int.TryParse puede ser útil en casos en los que se esperan fallas de conversión y se desea evitar que el programa se bloquee.
Extracción de datos de archivos PDF con IronPDF
¿Por qué utilizar IronPDF para analizar datos?
Al trabajar con PDFs, puede encontrarse con tablas o texto no estructurado que contiene datos numéricos en valores de cadena. Para extraer y procesar estos datos, convertir cadenas en enteros es crucial. IronPDF hace este proceso sencillo, ofreciendo tanto la flexibilidad como el poder para leer contenido PDF y realizar operaciones como la conversión de cadenas en valores numéricos.
Aquí están algunas de las características clave que ofrece IronPDF:
- Conversión de HTML a PDF: IronPDF puede convertir contenido HTML (incluidos CSS, imágenes y JavaScript) en PDF completamente formateados. Esto es especialmente útil para representar páginas web dinámicas o informes como PDFs.
- Edición de PDF: con IronPDF, puede manipular documentos PDF existentes agregando texto, imágenes y gráficos, así como editar el contenido de páginas existentes.
- Extracción de texto e imágenes: la biblioteca le permite extraer texto e imágenes de archivos PDF, lo que facilita el análisis del contenido PDF.
- Marcas de agua: también es posible agregar marcas de agua a los documentos PDF para proteger la marca o los derechos de autor.
Introducción a IronPDF
Para comenzar a usar IronPDF, primero deberá instalarlo. Si ya está instalado, entonces puede pasar a la siguiente sección, de lo contrario, los siguientes pasos cubren cómo instalar la biblioteca IronPDF.
A través de la consola del gestor de paquetes NuGet
Para instalar IronPDF utilizando la Consola del Administrador de Paquetes NuGet, abra Visual Studio y navegue a la Consola del Administrador de Paquetes. Luego ejecute el siguiente comando:
// Command to install IronPDF package via the Package Manager Console
Install-Package IronPdfMediante el gestor de paquetes NuGet para la solución
Abriendo Visual Studio, vaya a "Herramientas -> Administrador de Paquetes NuGet -> Administrar Paquetes NuGet para Solución" y busque IronPDF. Desde aquí, todo lo que necesita hacer es seleccionar su proyecto y hacer clic en "Instalar", y IronPDF se agregará a su proyecto.
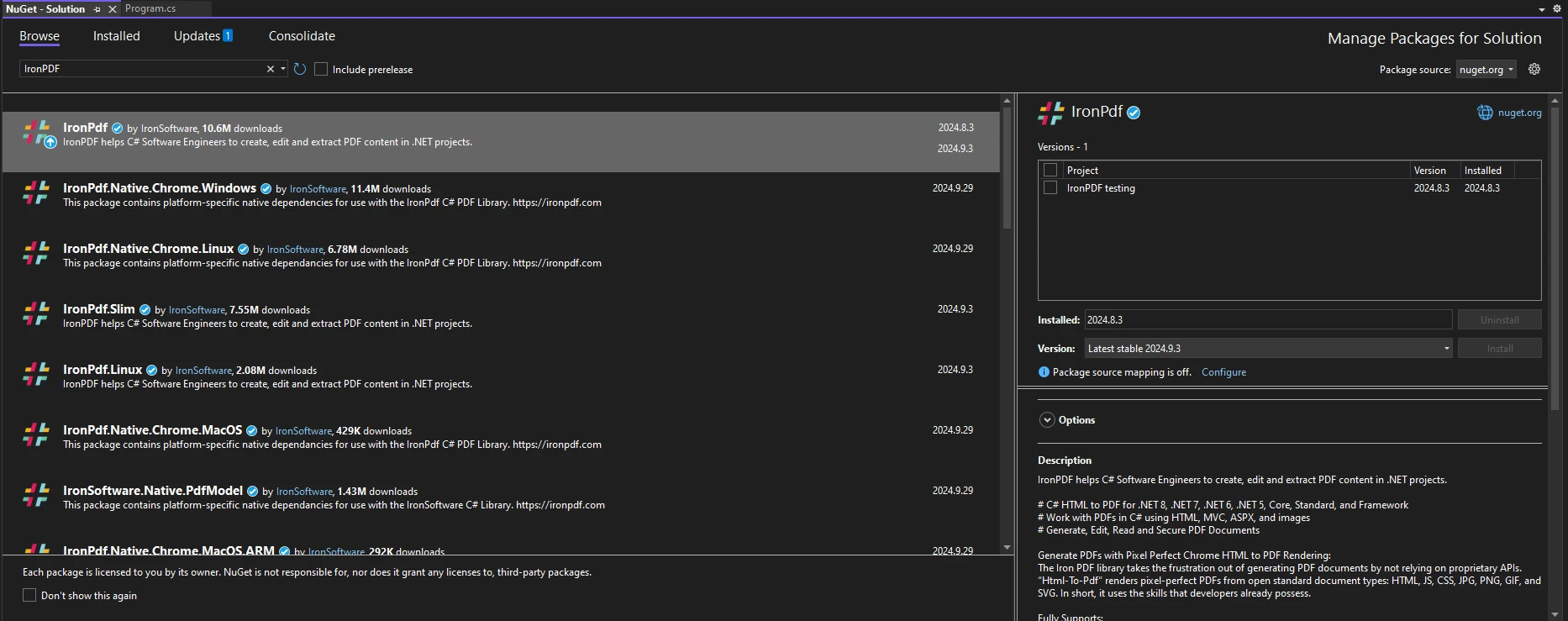
Una vez que haya instalado IronPDF, todo lo que necesita agregar para comenzar a usar IronPDF es la declaración correcta de using en la parte superior de su código:
using IronPdf;using IronPdf;Imports IronPdfDesbloqueo de la prueba gratuita
IronPDF ofrece una prueba gratuita con acceso completo a sus características. Visite el sitio web de IronPDF para descargar la prueba e integrar el manejo avanzado de PDF en sus proyectos .NET.
Ejemplo: Extraer y analizar números de un PDF
El siguiente código C# demuestra cómo usar IronPDF para extraer texto de un PDF, luego usar expresiones regulares para encontrar y analizar todos los valores numéricos en el texto extraído. El código maneja tanto números enteros como decimales, limpiando caracteres no numéricos como símbolos de moneda.
using IronPdf;
using System.Text.RegularExpressions;
public class Program
{
public static void Main(string[] args)
{
// Load a PDF file
PdfDocument pdf = PdfDocument.FromFile("example.pdf");
// Extract all text from the PDF
string text = pdf.ExtractAllText();
// Print the extracted text (for reference)
Console.WriteLine("Extracted Text: ");
Console.WriteLine(text);
// Parse and print all numbers found in the extracted text
Console.WriteLine("\nParsed Numbers:");
// Use regular expression to find all number patterns, including integers and decimals
var numberMatches = Regex.Matches(text, @"\d+(\.\d+)?");
// Iterate through all matched numbers and print them
foreach (Match match in numberMatches)
{
// Print each matched number
Console.WriteLine($"{match.Value}");
}
}
}using IronPdf;
using System.Text.RegularExpressions;
public class Program
{
public static void Main(string[] args)
{
// Load a PDF file
PdfDocument pdf = PdfDocument.FromFile("example.pdf");
// Extract all text from the PDF
string text = pdf.ExtractAllText();
// Print the extracted text (for reference)
Console.WriteLine("Extracted Text: ");
Console.WriteLine(text);
// Parse and print all numbers found in the extracted text
Console.WriteLine("\nParsed Numbers:");
// Use regular expression to find all number patterns, including integers and decimals
var numberMatches = Regex.Matches(text, @"\d+(\.\d+)?");
// Iterate through all matched numbers and print them
foreach (Match match in numberMatches)
{
// Print each matched number
Console.WriteLine($"{match.Value}");
}
}
}Imports Microsoft.VisualBasic
Imports IronPdf
Imports System.Text.RegularExpressions
Public Class Program
Public Shared Sub Main(ByVal args() As String)
' Load a PDF file
Dim pdf As PdfDocument = PdfDocument.FromFile("example.pdf")
' Extract all text from the PDF
Dim text As String = pdf.ExtractAllText()
' Print the extracted text (for reference)
Console.WriteLine("Extracted Text: ")
Console.WriteLine(text)
' Parse and print all numbers found in the extracted text
Console.WriteLine(vbLf & "Parsed Numbers:")
' Use regular expression to find all number patterns, including integers and decimals
Dim numberMatches = Regex.Matches(text, "\d+(\.\d+)?")
' Iterate through all matched numbers and print them
For Each match As Match In numberMatches
' Print each matched number
Console.WriteLine($"{match.Value}")
Next match
End Sub
End ClassPDF de entrada
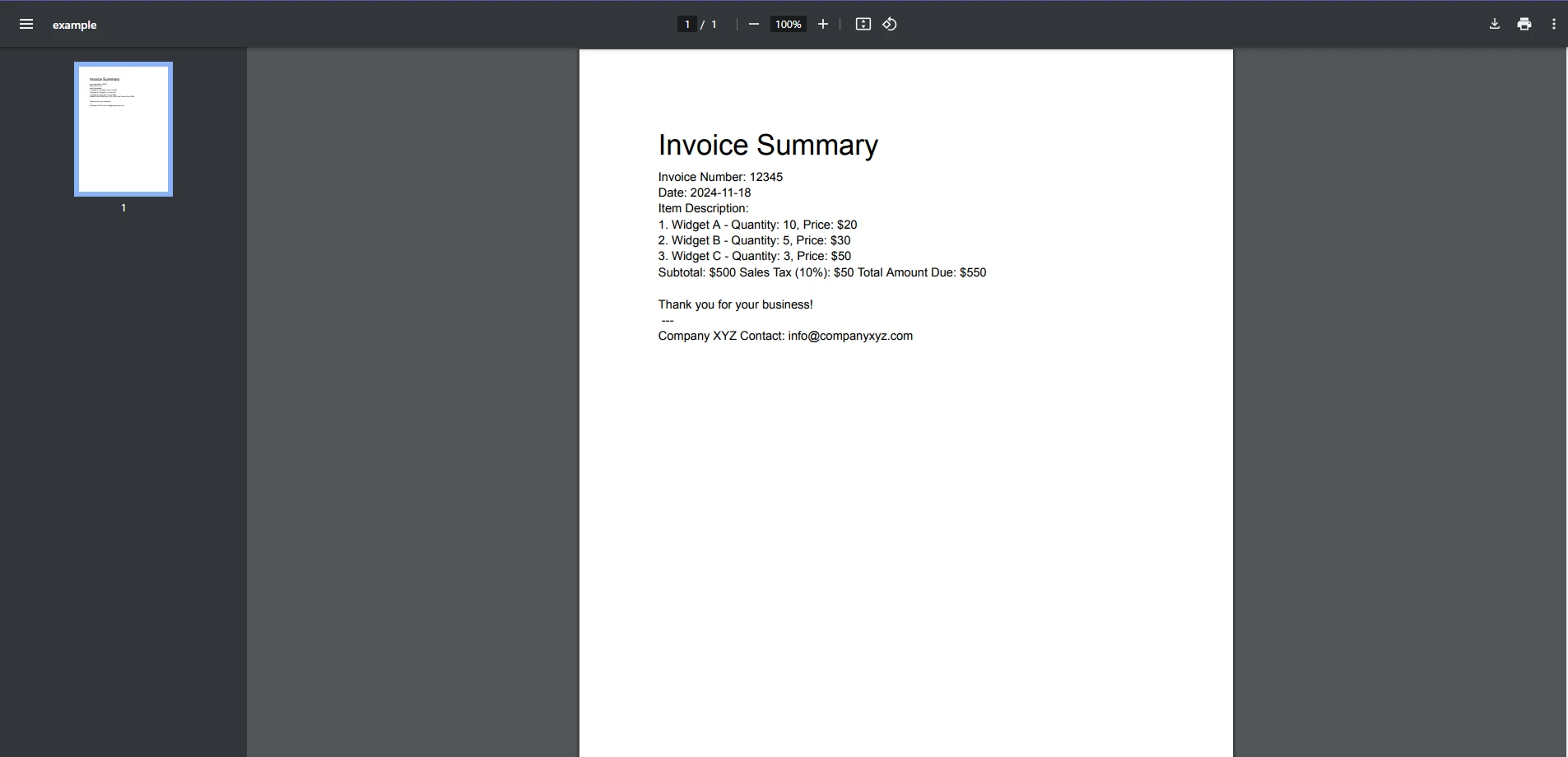
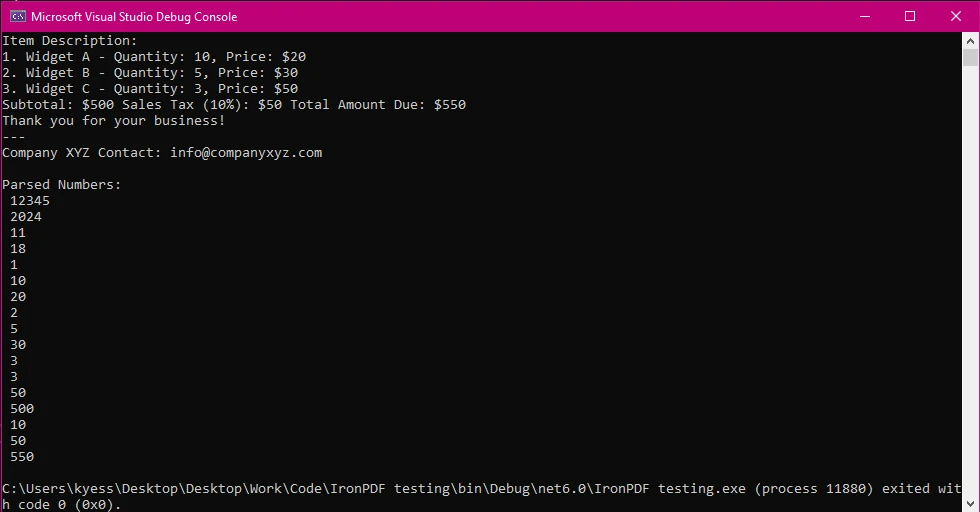
Salida de consola
Explicación del Código
-
Extraer texto del PDF:
El código comienza cargando un archivo PDF usando IronPDF. Luego extrae todo el texto del PDF.
-
Utilice expresiones regulares para encontrar números:
El código utiliza una expresión regular (un patrón para coincidir texto) para buscar en el texto extraído y encontrar cualquier número. La expresión regular busca tanto números enteros (por ejemplo, 12345) como números decimales (por ejemplo, 50.75).
-
Analizar e imprimir números:
Una vez que se encuentran los números, el programa imprime cada uno en la consola. Esto incluye enteros y decimales.
-
¿Por qué expresiones regulares?
Se utilizan expresiones regulares porque son herramientas potentes para encontrar patrones en texto, como números. Pueden manejar números con símbolos (como símbolos de moneda $), haciendo el proceso más flexible.
Desafíos comunes y cómo IronPDF los resuelve
Extraer datos limpios de estructuras PDF complejas a menudo resulta en valores de cadena que pueden requerir procesamiento adicional, como convertir cadenas en enteros. Aquí hay algunos desafíos comunes y cómo IronPDF puede ayudar:
Formatos incorrectos en PDF
Los PDFs a menudo contienen números formateados como texto (por ejemplo, "1,234.56" o "12,345 USD"). Para procesarlos correctamente, necesita asegurarse de que la representación de cadena del número esté en el formato correcto para el análisis. IronPDF le permite extraer texto de forma limpia y puede utilizar métodos de manipulación de cadenas (por ejemplo, Replace()) para ajustar el formato antes de la conversión.
Ejemplo:
string formattedNumber = "1,234.56"; // String value with commas
// Remove commas from the string to clean it
string cleanNumber = formattedNumber.Replace(",", "");
// Convert the cleaned string to an integer by first converting to double then to integer
int result = Convert.ToInt32(Convert.ToDouble(cleanNumber));
Console.WriteLine(result); // Outputs: 1234string formattedNumber = "1,234.56"; // String value with commas
// Remove commas from the string to clean it
string cleanNumber = formattedNumber.Replace(",", "");
// Convert the cleaned string to an integer by first converting to double then to integer
int result = Convert.ToInt32(Convert.ToDouble(cleanNumber));
Console.WriteLine(result); // Outputs: 1234Dim formattedNumber As String = "1,234.56" ' String value with commas
' Remove commas from the string to clean it
Dim cleanNumber As String = formattedNumber.Replace(",", "")
' Convert the cleaned string to an integer by first converting to double then to integer
Dim result As Integer = Convert.ToInt32(Convert.ToDouble(cleanNumber))
Console.WriteLine(result) ' Outputs: 1234Manejo de múltiples valores numéricos en texto
En un PDF complejo, los valores numéricos pueden aparecer en diferentes formatos o dispersos en diferentes ubicaciones. Con IronPDF, puede extraer todo el texto y luego usar expresiones regulares para encontrar y convertir cadenas en enteros de manera eficiente.
Conclusión
Analizar enteros en C# es una habilidad esencial para los desarrolladores, especialmente cuando se trata con entradas de usuario o extracción de datos de diversas fuentes. Si bien los métodos integrados como int.Parse() y Convert.ToInt32() son útiles, el manejo de datos no estructurados o semiestructurados (como el texto que se encuentra en los PDF) puede presentar desafíos adicionales. Ahí es donde IronPDF entra en juego, ofreciendo una solución poderosa y sencilla para extraer texto de PDFs y trabajar con él en aplicaciones .NET.
Al usar IronPDF, obtiene la capacidad de extraer fácilmente texto de PDFs complejos, incluidos documentos escaneados, y convertir esos datos en valores numéricos utilizables. Con características como OCR para PDFs escaneados y robustas herramientas de extracción de texto, IronPDF te permite agilizar el procesamiento de datos, incluso en formatos desafiantes.
Ya sea que se trate de facturas, informes financieros u otros documentos que contengan datos numéricos, combinar los métodos ParseInt de C# con IronPDF le ayudará a trabajar de manera más eficiente y precisa.
No deje que los PDFs complejos ralenticen su proceso de desarrollo; comenzar a usar IronPDF es la oportunidad perfecta para explorar cómo IronPDF puede mejorar su flujo de trabajo, así que ¿por qué no darle una oportunidad y ver cómo puede agilizar su próximo proyecto?
Preguntas Frecuentes
¿Cómo puedo convertir una cadena a un entero en C#?
En C#, puedes convertir una cadena a un entero utilizando el método int.Parse() o Convert.ToInt32(). El método int.Parse() lanza una excepción si la cadena no es un entero válido, mientras que Convert.ToInt32() devuelve 0 para entradas nulas.
¿Cuáles son las diferencias entre int.Parse() y Convert.ToInt32()?
int.Parse() se utiliza para convertir directamente una cadena en un entero y lanza una excepción para formatos no válidos. Convert.ToInt32() puede manejar valores nulos devolviendo por defecto 0, lo que lo hace más seguro para ciertas aplicaciones.
¿Cómo mejora int.TryParse() el manejo de errores durante el análisis?
int.TryParse() mejora el manejo de errores devolviendo un valor booleano que indica el éxito o el fracaso de la conversión, y usa un parámetro de salida para almacenar el resultado sin lanzar excepciones para entradas no válidas.
¿Cómo puede ayudar IronPDF en la extracción de texto de PDFs para análisis?
IronPDF simplifica la extracción de texto de PDFs al proporcionar características robustas como la extracción de texto e imágenes, permitiendo a los desarrolladores acceder fácilmente a datos en cadenas para analizar en valores numéricos con C#.
¿Qué pasos están involucrados en la instalación de una biblioteca PDF como IronPDF?
Para instalar IronPDF, utiliza la Consola del Administrador de Paquetes NuGet en Visual Studio y ejecuta el comando Install-Package IronPDF, o utiliza la ventana del Administrador de Paquetes NuGet para buscar e instalar la biblioteca.
¿Qué desafíos pueden surgir al analizar datos numéricos de PDFs?
Analizar datos numéricos de PDFs puede ser desafiante debido a problemas de formato como comas y patrones numéricos variados. IronPDF ayuda al permitir una extracción limpia de texto, que luego puede ser procesada con expresiones regulares.
¿Cómo pueden las expresiones regulares ayudar en la extracción de datos numéricos de PDFs?
Las expresiones regulares permiten a los desarrolladores identificar patrones en el texto, como números con símbolos, facilitando la extracción y conversión de datos numéricos del texto PDF extraído utilizando IronPDF.
¿Es posible extraer texto de documentos PDF escaneados?
Sí, IronPDF incluye capacidades de OCR (Reconocimiento Óptico de Caracteres) que permiten la extracción de texto de PDFs escaneados, convirtiendo imágenes escaneadas en texto editable y buscable.
¿Qué beneficios proporcionan las expresiones regulares cuando se usan con IronPDF?
Las expresiones regulares complementan a IronPDF al permitir búsquedas de texto flexibles y coincidencias de patrones, lo cual es esencial para manejar escenarios complejos de extracción de texto, como encontrar y convertir números.














