
Parseint C#(開発者向けの仕組み)
C#でデータを扱う際、開発者は頻繁に数値の文字列表現を整数に変換する必要があります。 "整数のパース"として知られるこのタスクは、ユーザー入力の処理からPDFのようなファイルからのデータ抽出に至るまで、さまざまなアプリケーションにとって重要です。 C# では整数のパース のための強力な方法を提供していますが、PDFのような非構造化または半構造化データを扱う際には、プロセスがさらに複雑になる可能性があります。
ここで、IronPDFという、.NET開発者向けの強力なPDFライブラリが登場します。 IronPDFを使用すると、PDFからテキストを抽出し、そのテキストをC#のパース機能を利用して使用可能な数値データに変換できます。 請求書、レポート、フォームを解析している場合でも、C#のパースツールをIronPDFと組み合わせることで、PDFデータの取り扱いが簡素化され、文字列形式の数値を整数に変換できます。
この記事では、C#のParseIntを使って数値の文字列表現を整数に変換する方法と、IronPDFがPDFからの数値データの抽出とパースをどのように効率化するかを紹介します。
ParseIntとはC#において何か?
整数のパースの基本
C# では、文字列値 ("123"など) を整数に変換するには、通常、int.Parse() または Convert.ToInt32() を使用します。 これらのメソッドは、文字列データを計算やバリデーションのための使用可能な数値に変換するために開発者を支援します。
- int.Parse(string s):文字列を整数に変換します。 文字列が有効な整数でない場合は例外をスローします。
- Convert.ToInt32(string s):文字列を整数に変換し、null 入力を別の方法で処理します。
int.Parse() を使用して文字列を変換する例を次に示します。
string numberString = "123";
// Convert the string to an integer using int.Parse
int num = int.Parse(numberString);
Console.WriteLine(num); // Output: 123string numberString = "123";
// Convert the string to an integer using int.Parse
int num = int.Parse(numberString);
Console.WriteLine(num); // Output: 123Dim numberString As String = "123"
' Convert the string to an integer using int.Parse
Dim num As Integer = Integer.Parse(numberString)
Console.WriteLine(num) ' Output: 123もう一方で、Convertクラスを利用する方法もあります。
string numericString = "123";
// Convert the string to an integer using Convert.ToInt32
int result = Convert.ToInt32(numericString);
Console.WriteLine(result); // Outputs: 123string numericString = "123";
// Convert the string to an integer using Convert.ToInt32
int result = Convert.ToInt32(numericString);
Console.WriteLine(result); // Outputs: 123Dim numericString As String = "123"
' Convert the string to an integer using Convert.ToInt32
Dim result As Integer = Convert.ToInt32(numericString)
Console.WriteLine(result) ' Outputs: 123Convertクラスを用いることで、安全に文字列や他のデータ型を変換できます。 これは、文字列変数が null または無効な値を表す可能性がある場合に、例外をスローする代わりにデフォルト値 (この場合は 0) を返すため、特に便利です。
デフォルト値とエラー処理
文字列を整数に変換する際に開発者がよく直面する問題の一つは、無効または数値でない入力を扱うことです。 数値の文字列表現が正しい形式でない場合、int.Parse() のようなメソッドは例外をスローします。 ただし、Convert.ToInt32() には無効な文字列に対するフォールバック メカニズムが組み込まれています。
パース時にデフォルト値を処理する方法を示す例を以下に示します。
string invalidString = "abc";
// Convert will return 0 instead of throwing an exception for invalid input
int result = Convert.ToInt32(invalidString);
Console.WriteLine(result); // Outputs: 0string invalidString = "abc";
// Convert will return 0 instead of throwing an exception for invalid input
int result = Convert.ToInt32(invalidString);
Console.WriteLine(result); // Outputs: 0Dim invalidString As String = "abc"
' Convert will return 0 instead of throwing an exception for invalid input
Dim result As Integer = Convert.ToInt32(invalidString)
Console.WriteLine(result) ' Outputs: 0int.TryParse()を使用すれば、変換が成功したかどうかを示すブール値を返すため、制御のある文字列変換が可能です:
string invalidInput = "abc";
// Attempt to parse using TryParse, which avoids exceptions for invalid input
if (int.TryParse(invalidInput, out int result))
{
Console.WriteLine(result);
}
else
{
Console.WriteLine("Parsing failed.");
}string invalidInput = "abc";
// Attempt to parse using TryParse, which avoids exceptions for invalid input
if (int.TryParse(invalidInput, out int result))
{
Console.WriteLine(result);
}
else
{
Console.WriteLine("Parsing failed.");
}Dim invalidInput As String = "abc"
' Attempt to parse using TryParse, which avoids exceptions for invalid input
Dim result As Integer
If Integer.TryParse(invalidInput, result) Then
Console.WriteLine(result)
Else
Console.WriteLine("Parsing failed.")
End Ifこの場合、TryParse() は out パラメータを使用して変換された整数を格納し、これによりメソッドは例外をスローせずに値を返すことができます。 変換に失敗すると、プログラムを単にクラッシュさせる代わりにelse文が実行されます。 さもなければ、プログラムは入力文字列から成功裏にパースされた数値の結果を表示します。 変換の失敗が予想され、プログラムのクラッシュを回避したい場合には、int.TryParse を使用すると役立ちます。
IronPDFを使用したPDFデータのパース
なぜIronPDFをデータパースに使用するのか?
PDFを扱う際、文字列値に含まれる数値データを含む表や非構造化テキストに遭遇することがあります。 このデータを抽出して処理するためには、文字列を整数に変換することが重要です。 IronPDFはこのプロセスを簡単にし、PDFコンテンツを読み取って文字列を数値に変換する操作を行うという柔軟性と力を提供します。
以下はIronPDFが提供する主な特徴のいくつかです:
- HTML から PDF への変換: IronPDF は、 HTML コンテンツ(CSS、画像、 JavaScriptを含む) を完全にフォーマットされた PDF に変換できます。 これは、動的なウェブページやレポートをPDFとしてレンダリングするのに特に有用です。
- PDF 編集: IronPDFを使用すると、テキスト、画像、グラフィックを追加したり、既存のページのコンテンツを編集したりして、既存の PDF ドキュメントを操作できます。 *テキストと画像の抽出:*このライブラリを使用すると、PDF からテキストと画像を抽出できるため、PDF コンテンツの解析と分析が容易になります。 透かし:**ブランディングや著作権保護のために PDF ドキュメントに透かしを追加することもできます。
IronPDFを始める
IronPDFを使い始めるには、まずインストールする必要があります。 すでにインストールされている場合は次のセクションに進むことができますが、そうでない場合は以下の手順でIronPDFライブラリのインストール方法をカバーします。
NuGetパッケージマネージャーコンソール経由
NuGetパッケージマネージャーコンソールを使用してIronPDFをインストールするには、Visual Studioを開いてパッケージマネージャーコンソールに移動します。 その後、以下のコマンドを実行します。
// Command to install IronPDF package via the Package Manager Console
Install-Package IronPdfNuGetパッケージマネージャー経由でソリューションの管理
Visual Studioを開いたら、"ツール -> NuGetパッケージマネージャー -> ソリューションのNuGetパッケージを管理"に移動してIronPDFを検索します。 ここからは、プロジェクトを選択して"インストール"をクリックするだけで、IronPDFがプロジェクトに追加されます。
IronPDFをインストールしたら、IronPDFを使い始めるためには、コードの先頭に正しいusing文を追加するだけです。
using IronPdf;using IronPdf;Imports IronPdf無料トライアルの開始
IronPDFは、その機能に完全にアクセスできる無料トライアルを提供しています。 IronPDFのウェブサイトを訪れて、トライアルをダウンロードし、あなた for .NETプロジェクトに高度なPDF操作を統合し始めてください。
例: PDFからの数値抽出と解析
以下のC#コードは、IronPDFを使用してPDFからテキストを抽出し、正規表現を使用して抽出されたテキスト内のすべての数値を見つけて解析する方法を示しています。 このコードは整数と小数の両方を処理し、通貨記号など数値でない文字をクリーンアップします。
using IronPdf;
using System.Text.RegularExpressions;
public class Program
{
public static void Main(string[] args)
{
// Load a PDF file
PdfDocument pdf = PdfDocument.FromFile("example.pdf");
// Extract all text from the PDF
string text = pdf.ExtractAllText();
// Print the extracted text (for reference)
Console.WriteLine("Extracted Text: ");
Console.WriteLine(text);
// Parse and print all numbers found in the extracted text
Console.WriteLine("\nParsed Numbers:");
// Use regular expression to find all number patterns, including integers and decimals
var numberMatches = Regex.Matches(text, @"\d+(\.\d+)?");
// Iterate through all matched numbers and print them
foreach (Match match in numberMatches)
{
// Print each matched number
Console.WriteLine($"{match.Value}");
}
}
}using IronPdf;
using System.Text.RegularExpressions;
public class Program
{
public static void Main(string[] args)
{
// Load a PDF file
PdfDocument pdf = PdfDocument.FromFile("example.pdf");
// Extract all text from the PDF
string text = pdf.ExtractAllText();
// Print the extracted text (for reference)
Console.WriteLine("Extracted Text: ");
Console.WriteLine(text);
// Parse and print all numbers found in the extracted text
Console.WriteLine("\nParsed Numbers:");
// Use regular expression to find all number patterns, including integers and decimals
var numberMatches = Regex.Matches(text, @"\d+(\.\d+)?");
// Iterate through all matched numbers and print them
foreach (Match match in numberMatches)
{
// Print each matched number
Console.WriteLine($"{match.Value}");
}
}
}Imports Microsoft.VisualBasic
Imports IronPdf
Imports System.Text.RegularExpressions
Public Class Program
Public Shared Sub Main(ByVal args() As String)
' Load a PDF file
Dim pdf As PdfDocument = PdfDocument.FromFile("example.pdf")
' Extract all text from the PDF
Dim text As String = pdf.ExtractAllText()
' Print the extracted text (for reference)
Console.WriteLine("Extracted Text: ")
Console.WriteLine(text)
' Parse and print all numbers found in the extracted text
Console.WriteLine(vbLf & "Parsed Numbers:")
' Use regular expression to find all number patterns, including integers and decimals
Dim numberMatches = Regex.Matches(text, "\d+(\.\d+)?")
' Iterate through all matched numbers and print them
For Each match As Match In numberMatches
' Print each matched number
Console.WriteLine($"{match.Value}")
Next match
End Sub
End Class入力PDF
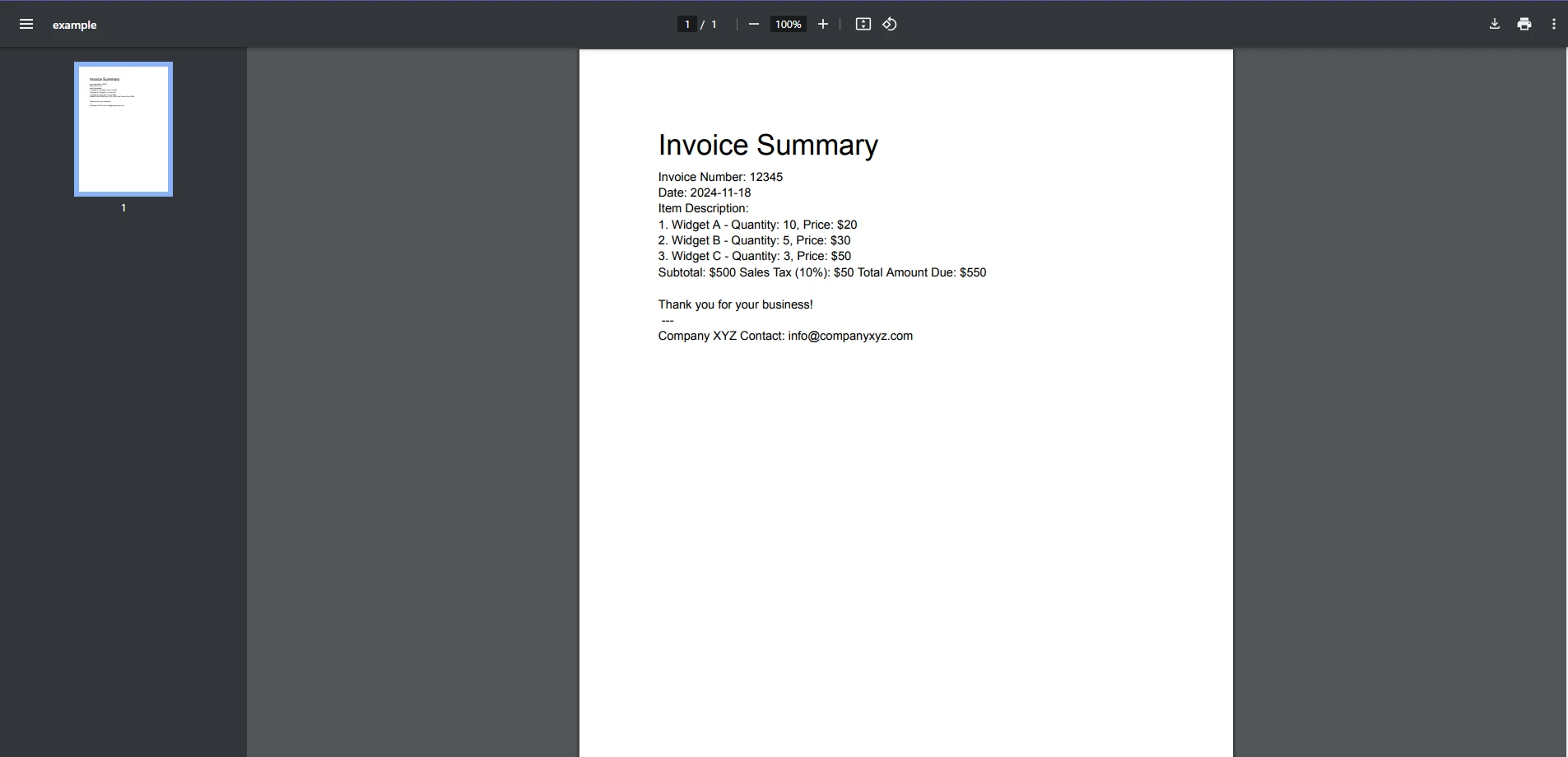
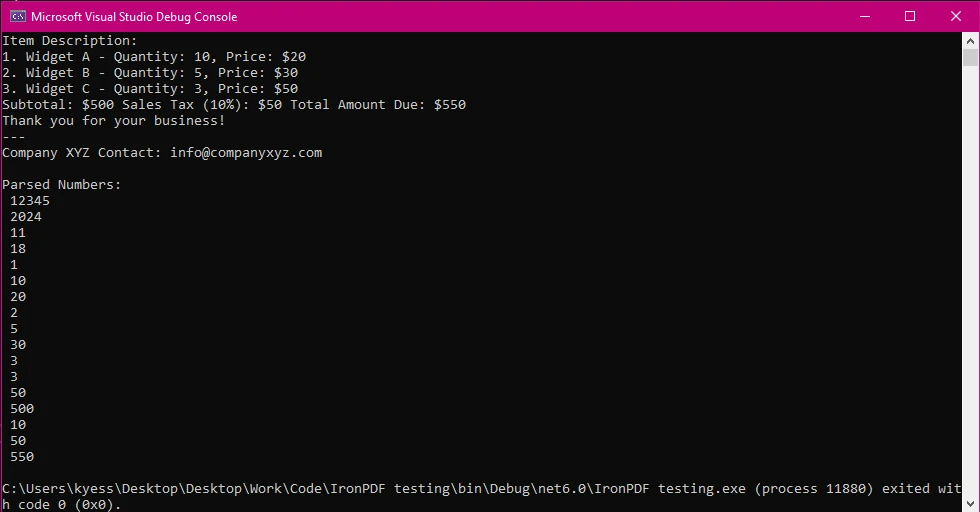
コンソール出力
コードの説明
-
PDFからテキストを抽出する:
コードは、IronPDFを用いてPDFファイルを読み込むことから始まります。 その後、PDFからすべてのテキストを抽出します。
2.正規表現を使って数字を検索する:
コードは正規表現(テキストをマッチするパターン)を使用して、抽出されたテキストの中から任意の数値を検索します。 正規表現は、整数(例えば12345)と小数(例えば50.75)の両方を探します。
3.数値を解析して印刷する:
数値が見つかったら、プログラムはそれぞれをコンソールに表示します。 これには整数と小数が含まれています。
4.正規表現を使う理由:
正規表現はテキスト内のパターン(例: 数字)を見つけるための強力なツールです。 通貨記号のような記号を持つ数値も扱うことができ、プロセスをより柔軟にします。
一般的な課題とIronPDFがそれをどのように解決するか
複雑なPDF構造からきれいなデータを抽出することは、文字列値を変換して整数にする必要があるさらなる処理を必要とすることがあります。 以下は一般的な課題とIronPDFがそれをどう助けるかの一例です:
PDF内の不正なフォーマット
PDFにはしばしば"1,234.56"や"12,345 USD"のように形式化された数値が含まれます。 これらを正しく処理するためには、数値の文字列表現がパース用に正しい形式であることを確認する必要があります。 IronPDF を使用すると、テキストをきれいに抽出することができ、文字列操作メソッド (例: Replace()) を使用して変換前に書式を調整できます。
例:
string formattedNumber = "1,234.56"; // String value with commas
// Remove commas from the string to clean it
string cleanNumber = formattedNumber.Replace(",", "");
// Convert the cleaned string to an integer by first converting to double then to integer
int result = Convert.ToInt32(Convert.ToDouble(cleanNumber));
Console.WriteLine(result); // Outputs: 1234string formattedNumber = "1,234.56"; // String value with commas
// Remove commas from the string to clean it
string cleanNumber = formattedNumber.Replace(",", "");
// Convert the cleaned string to an integer by first converting to double then to integer
int result = Convert.ToInt32(Convert.ToDouble(cleanNumber));
Console.WriteLine(result); // Outputs: 1234Dim formattedNumber As String = "1,234.56" ' String value with commas
' Remove commas from the string to clean it
Dim cleanNumber As String = formattedNumber.Replace(",", "")
' Convert the cleaned string to an integer by first converting to double then to integer
Dim result As Integer = Convert.ToInt32(Convert.ToDouble(cleanNumber))
Console.WriteLine(result) ' Outputs: 1234テキスト中の複数の数値を扱う
複雑なPDFでは、数値が異なる形式で現れたり、異なる場所に散らばっていることがあります。 IronPDFを使用すると、すべてのテキストを抽出し、その後、正規表現を使用して効果的に文字列を整数に変換できます。
結論
C#で整数をパースすることは、特にユーザー入力やさまざまなソースからのデータ抽出を扱う際に、開発者にとって重要なスキルです。 int.Parse() や Convert.ToInt32() などの組み込みメソッドは便利ですが、PDF 内のテキストなどの非構造化データや半構造化データの処理には追加の課題が生じる可能性があります。 そこでIronPDFが登場し、強力で簡単なPDFからテキストを抽出し、それを.NETアプリケーションで扱うためのソリューションを提供します。
IronPDFを使用することで、複雑なPDFからテキストを簡単に抽出し、スキャンされたドキュメントも含むデータを使用可能な数値に変換できます。 スキャンされたPDF用のOCRや強力なテキスト抽出ツールのような機能を備えたIronPDFは、複雑なフォーマットでもデータ処理を効率化します。
請求書、財務報告書、または数値データを含むその他のドキュメントを扱う際は、C#のParseIntメソッドをIronPDFと組み合わせることで、より効率的かつ正確に作業することができます。
複雑なPDFが開発プロセスを遅らせることがないようにするために、IronPDFを使用することは、IronPDFがワークフローをどのように強化できるかを探索するための絶好の機会です。ぜひ試してみて、次のプロジェクトでどのように効率化できるかを確認しましょう。
よくある質問
C#で文字列を整数に変換するにはどうすればよいですか?
C#では、int.Parse()メソッドまたはConvert.ToInt32()を使用して文字列を整数に変換できます。int.Parse()メソッドは無効な整数の場合に例外をスローしますが、Convert.ToInt32()はnull入力に対して0を返します。
int.Parse()とConvert.ToInt32()の違いは何ですか?
int.Parse()は文字列を直接整数に変換し、不正な形式の場合は例外をスローします。Convert.ToInt32()はnull値を0のデフォルトで処理できるため、特定のアプリケーションにとってより安全です。
int.TryParse()は解析中のエラーハンドリングをどのように強化しますか?
int.TryParse()は、変換の成否を示すブール値を返し、結果を保持するためのoutパラメーターを使用し、不正な入力に対して例外をスローしないことでエラーハンドリングを強化します。
IronPDFは、解析のためにPDFからテキストを抽出するのをどのように支援できますか?
IronPDFは、テキストと画像の抽出などの堅牢な機能を提供することにより、開発者がC#で数値値に解析するための文字列データに簡単にアクセスできるようにすることで、PDFからのテキスト抽出を簡素化します。
IronPDFのようなPDFライブラリをインストールする手順は何ですか?
IronPDFをインストールするには、Visual StudioのNuGetパッケージマネージャーコンソールを使用してコマンドInstall-Package IronPDFを実行するか、NuGetパッケージマネージャーウィンドウを使用してライブラリを検索してインストールします。
PDFから数値データを解析する際に生じる可能性のある課題は何ですか?
PDFからの数値データの解析は、コンマや様々な数値パターンなどのフォーマットの問題があるため難しい場合があります。 IronPDFは、正規表現で処理可能なクリーンなテキスト抽出を可能にすることで支援します。
正規表現は、PDFからの数値データ抽出にどのように役立ちますか?
正規表現は、テキスト内のパターンを識別し、IronPDFを使用して抽出されたPDFからテキストを抽出して数値データを変換するのに役立ちます。
スキャンされたPDFドキュメントからテキストを抽出することは可能ですか?
はい、IronPDFにはOCR(光学文字認識)機能が含まれており、スキャンされたPDFからテキストを抽出し、検索可能で編集可能なテキストに変換できます。
IronPDFと一緒に正規表現を使用するとどのような利点がありますか?
正規表現はIronPDFを補完し、複雑なテキスト抽出シナリオ、例えば数字の発見と変換を処理するために不可欠な柔軟なテキスト検索とパターンマッチングを可能にします。














