
Parseint C# (Como funciona para desenvolvedores)
Ao trabalhar com dados em C#, os desenvolvedores frequentemente precisam converter representações textuais de números em números inteiros. Essa tarefa, conhecida como "análise sintática de números inteiros", é fundamental para diversas aplicações, desde o processamento de entradas do usuário até a extração de dados de arquivos como PDFs. Embora o C# forneça métodos poderosos para analisar números inteiros , o processo pode se tornar mais complexo ao trabalhar com dados não estruturados ou semiestruturados, como os encontrados em PDFs.
É aí que entra em cena o IronPDF , uma biblioteca PDF robusta para desenvolvedores .NET . Com o IronPDF, você pode extrair texto de PDFs e aproveitar os recursos de análise sintática do C# para transformar esse texto em dados numéricos utilizáveis. Seja para analisar faturas, relatórios ou formulários, combinar as ferramentas de análise sintática do C# com o IronPDF simplifica o processamento de dados em PDF, permitindo converter números formatados como strings em números inteiros.
Neste artigo, vamos explorar como o ParseInt é usado em C# para converter representações de strings de números em inteiros e como o IronPDF pode simplificar o processo de extração e análise de dados numéricos de PDFs.
O que é ParseInt em C#?
Noções básicas de análise sintática de números inteiros
Em C#, converter um valor de string (como "123") para um inteiro é comumente feito usando int.Parse() ou Convert.ToInt32(). Esses métodos ajudam os desenvolvedores a transformar dados textuais em valores numéricos utilizáveis para cálculos e validações.
- int.Parse(string s): Converte uma string em um número inteiro. Lança uma exceção se a string não for um número inteiro válido.
- Convert.ToInt32(string s): Converte uma string em um inteiro, tratando entradas nulas de maneira diferente.
Aqui está um exemplo de conversão de strings usando int.Parse():
string numberString = "123";
// Convert the string to an integer using int.Parse
int num = int.Parse(numberString);
Console.WriteLine(num); // Output: 123string numberString = "123";
// Convert the string to an integer using int.Parse
int num = int.Parse(numberString);
Console.WriteLine(num); // Output: 123Dim numberString As String = "123"
' Convert the string to an integer using int.Parse
Dim num As Integer = Integer.Parse(numberString)
Console.WriteLine(num) ' Output: 123Alternativamente, usando a classe Convert:
string numericString = "123";
// Convert the string to an integer using Convert.ToInt32
int result = Convert.ToInt32(numericString);
Console.WriteLine(result); // Outputs: 123string numericString = "123";
// Convert the string to an integer using Convert.ToInt32
int result = Convert.ToInt32(numericString);
Console.WriteLine(result); // Outputs: 123Dim numericString As String = "123"
' Convert the string to an integer using Convert.ToInt32
Dim result As Integer = Convert.ToInt32(numericString)
Console.WriteLine(result) ' Outputs: 123A classe Convert permite converter strings e outros tipos de dados de forma segura. É especialmente útil quando a variável string pode representar um valor nulo ou inválido, já que Convert.ToInt32() retorna um valor padrão (0 neste caso) ao invés de lançar uma exceção.
Valor padrão e tratamento de erros
Um problema que os desenvolvedores frequentemente enfrentam ao converter strings em números inteiros é lidar com entradas inválidas ou não numéricas. Se a representação string do número não estiver no formato correto, métodos como int.Parse() lançarão uma exceção. No entanto, Convert.ToInt32() possui um mecanismo de fallback embutido para strings inválidas.
Aqui está um exemplo que demonstra como lidar com valores padrão durante a análise sintática:
string invalidString = "abc";
// Convert will return 0 instead of throwing an exception for invalid input
int result = Convert.ToInt32(invalidString);
Console.WriteLine(result); // Outputs: 0string invalidString = "abc";
// Convert will return 0 instead of throwing an exception for invalid input
int result = Convert.ToInt32(invalidString);
Console.WriteLine(result); // Outputs: 0Dim invalidString As String = "abc"
' Convert will return 0 instead of throwing an exception for invalid input
Dim result As Integer = Convert.ToInt32(invalidString)
Console.WriteLine(result) ' Outputs: 0Se você deseja converter strings com mais controle, pode usar int.TryParse() , que retorna um valor booleano indicando se a conversão foi bem-sucedida ou não:
string invalidInput = "abc";
// Attempt to parse using TryParse, which avoids exceptions for invalid input
if (int.TryParse(invalidInput, out int result))
{
Console.WriteLine(result);
}
else
{
Console.WriteLine("Parsing failed.");
}string invalidInput = "abc";
// Attempt to parse using TryParse, which avoids exceptions for invalid input
if (int.TryParse(invalidInput, out int result))
{
Console.WriteLine(result);
}
else
{
Console.WriteLine("Parsing failed.");
}Dim invalidInput As String = "abc"
' Attempt to parse using TryParse, which avoids exceptions for invalid input
Dim result As Integer
If Integer.TryParse(invalidInput, result) Then
Console.WriteLine(result)
Else
Console.WriteLine("Parsing failed.")
End IfNeste caso, TryParse() usa um parâmetro de saída para armazenar o inteiro convertido, o que permite que o método retorne um valor sem lançar uma exceção. Se a conversão falhar, a instrução else será executada em vez de simplesmente encerrar o programa. Caso contrário, o programa exibirá o resultado do número analisado com sucesso a partir da string de entrada. Usar int.TryParse pode ser útil em casos onde falhas de conversão são esperadas e você deseja evitar que o programa trave.
Analisando dados de PDFs usando o IronPDF
Por que usar o IronPDF para analisar dados?
Ao trabalhar com PDFs, você pode encontrar tabelas ou textos não estruturados que contêm dados numéricos em valores de cadeia de caracteres. Para extrair e processar esses dados, é crucial converter strings em números inteiros. O IronPDF simplifica esse processo, oferecendo flexibilidade e poder para ler conteúdo de PDFs e realizar operações como a conversão de strings em valores numéricos.
Aqui estão alguns dos principais recursos que o IronPDF oferece:
- Conversão de HTML para PDF: O IronPDF pode converter conteúdo HTML (incluindo CSS, imagens e JavaScript) em PDFs totalmente formatados. Isso é especialmente útil para renderizar páginas da web ou relatórios dinâmicos como PDFs.
- Edição de PDF: Com o IronPDF, você pode manipular documentos PDF existentes adicionando texto, imagens e gráficos, além de editar o conteúdo das páginas existentes.
- Extração de Texto e Imagem: A biblioteca permite extrair texto e imagens de PDFs, facilitando a análise e a interpretação do conteúdo do PDF.
- Marca d'água: Também é possível adicionar marcas d'água a documentos PDF para fins de identidade visual ou proteção de direitos autorais.
Primeiros passos com o IronPDF
Para começar a usar o IronPDF , primeiro você precisará instalá-lo. Se já estiver instalado, você pode pular para a próxima seção; caso contrário, as etapas a seguir explicam como instalar a biblioteca IronPDF .
Através do console do Gerenciador de Pacotes NuGet
Para instalar o IronPDF usando o Console do Gerenciador de Pacotes NuGet , abra o Visual Studio e navegue até o Console do Gerenciador de Pacotes. Em seguida, execute o seguinte comando:
// Command to install IronPDF package via the Package Manager Console
Install-Package IronPdfPor meio do Gerenciador de Pacotes NuGet para Soluções
Ao abrir o Visual Studio, acesse "Ferramentas -> Gerenciador de Pacotes NuGet -> Gerenciar Pacotes NuGet para a Solução" e procure por IronPDF. A partir daqui, basta selecionar o seu projeto e clicar em "Instalar", e o IronPDF será adicionado ao seu projeto.
Após instalar o IronPDF, tudo o que você precisa adicionar para começar a usá IronPDF é a instrução using correta no início do seu código:
using IronPdf;using IronPdf;Imports IronPdfDesbloqueando o período de teste gratuito
O IronPDF oferece um período de teste gratuito com acesso completo aos seus recursos. Visite o site do IronPDF para baixar a versão de avaliação e começar a integrar recursos avançados de manipulação de PDFs em seus projetos .NET .
Exemplo: Extrair e analisar números de um PDF
O código C# a seguir demonstra como usar o IronPDF para extrair texto de um PDF e, em seguida, usar expressões regulares para encontrar e analisar todos os valores numéricos no texto extraído. O código processa tanto números inteiros quanto decimais, eliminando caracteres não numéricos, como símbolos de moeda.
using IronPdf;
using System.Text.RegularExpressions;
public class Program
{
public static void Main(string[] args)
{
// Load a PDF file
PdfDocument pdf = PdfDocument.FromFile("example.pdf");
// Extract all text from the PDF
string text = pdf.ExtractAllText();
// Print the extracted text (for reference)
Console.WriteLine("Extracted Text: ");
Console.WriteLine(text);
// Parse and print all numbers found in the extracted text
Console.WriteLine("\nParsed Numbers:");
// Use regular expression to find all number patterns, including integers and decimals
var numberMatches = Regex.Matches(text, @"\d+(\.\d+)?");
// Iterate through all matched numbers and print them
foreach (Match match in numberMatches)
{
// Print each matched number
Console.WriteLine($"{match.Value}");
}
}
}using IronPdf;
using System.Text.RegularExpressions;
public class Program
{
public static void Main(string[] args)
{
// Load a PDF file
PdfDocument pdf = PdfDocument.FromFile("example.pdf");
// Extract all text from the PDF
string text = pdf.ExtractAllText();
// Print the extracted text (for reference)
Console.WriteLine("Extracted Text: ");
Console.WriteLine(text);
// Parse and print all numbers found in the extracted text
Console.WriteLine("\nParsed Numbers:");
// Use regular expression to find all number patterns, including integers and decimals
var numberMatches = Regex.Matches(text, @"\d+(\.\d+)?");
// Iterate through all matched numbers and print them
foreach (Match match in numberMatches)
{
// Print each matched number
Console.WriteLine($"{match.Value}");
}
}
}Imports Microsoft.VisualBasic
Imports IronPdf
Imports System.Text.RegularExpressions
Public Class Program
Public Shared Sub Main(ByVal args() As String)
' Load a PDF file
Dim pdf As PdfDocument = PdfDocument.FromFile("example.pdf")
' Extract all text from the PDF
Dim text As String = pdf.ExtractAllText()
' Print the extracted text (for reference)
Console.WriteLine("Extracted Text: ")
Console.WriteLine(text)
' Parse and print all numbers found in the extracted text
Console.WriteLine(vbLf & "Parsed Numbers:")
' Use regular expression to find all number patterns, including integers and decimals
Dim numberMatches = Regex.Matches(text, "\d+(\.\d+)?")
' Iterate through all matched numbers and print them
For Each match As Match In numberMatches
' Print each matched number
Console.WriteLine($"{match.Value}")
Next match
End Sub
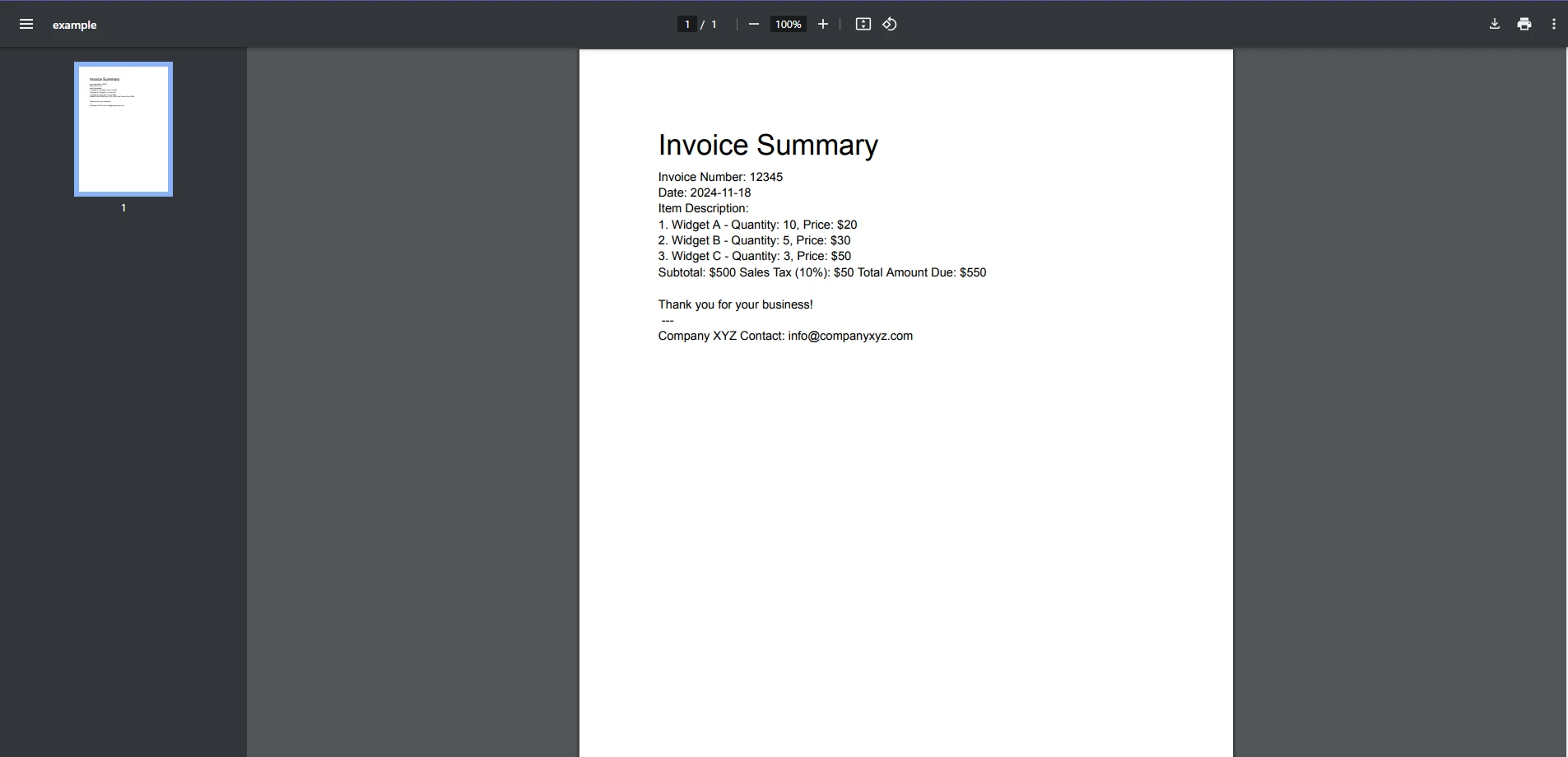
End ClassEntrada PDF
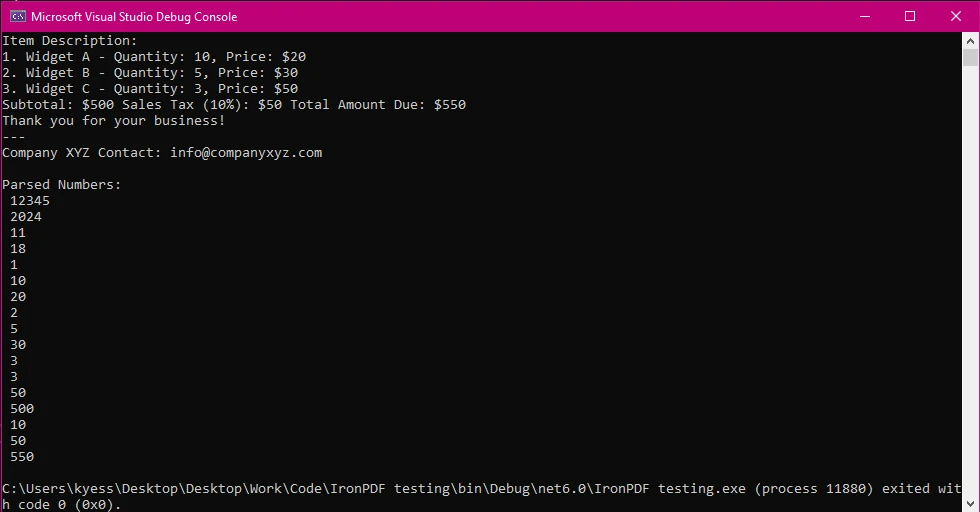
Saída do console
Explicação do código
-
Extract Text from PDF:
O código começa carregando um arquivo PDF usando o IronPDF. Em seguida, extrai todo o texto do PDF.
-
Usar Expressões Regulares para Encontrar Números:
O código utiliza uma expressão regular (um padrão para encontrar correspondências no texto) para pesquisar no texto extraído e localizar quaisquer números. A expressão regular procura tanto números inteiros (ex.: 12345) quanto números decimais (ex.: 50,75).
-
Analisar e Imprimir Números:
Assim que os números forem encontrados, o programa os imprimirá no console. Isso inclui números inteiros e decimais.
-
Por que Expressões Regulares:
Expressões regulares são usadas porque são ferramentas poderosas para encontrar padrões em textos, como números. Eles conseguem lidar com números juntamente com símbolos (como o símbolo monetário $), tornando o processo mais flexível.
Desafios comuns e como o IronPDF os resolve
A extração de dados limpos de estruturas PDF complexas frequentemente resulta em valores de string que podem exigir processamento adicional, como a conversão de strings em números inteiros. Aqui estão alguns desafios comuns e como o IronPDF pode ajudar:
Formatos incorretos em PDFs
Os PDFs geralmente contêm números formatados como texto (por exemplo, "1.234,56" ou "12.345 USD"). Para processar esses números corretamente, você precisa garantir que a representação em formato de string esteja no formato correto para análise. IronPDF permite que você extraia texto de forma limpa, e você pode usar métodos de manipulação de string (por exemplo, Replace()) para ajustar o formato antes da conversão.
Exemplo:
string formattedNumber = "1,234.56"; // String value with commas
// Remove commas from the string to clean it
string cleanNumber = formattedNumber.Replace(",", "");
// Convert the cleaned string to an integer by first converting to double then to integer
int result = Convert.ToInt32(Convert.ToDouble(cleanNumber));
Console.WriteLine(result); // Outputs: 1234string formattedNumber = "1,234.56"; // String value with commas
// Remove commas from the string to clean it
string cleanNumber = formattedNumber.Replace(",", "");
// Convert the cleaned string to an integer by first converting to double then to integer
int result = Convert.ToInt32(Convert.ToDouble(cleanNumber));
Console.WriteLine(result); // Outputs: 1234Dim formattedNumber As String = "1,234.56" ' String value with commas
' Remove commas from the string to clean it
Dim cleanNumber As String = formattedNumber.Replace(",", "")
' Convert the cleaned string to an integer by first converting to double then to integer
Dim result As Integer = Convert.ToInt32(Convert.ToDouble(cleanNumber))
Console.WriteLine(result) ' Outputs: 1234Como lidar com múltiplos valores numéricos em um texto.
Em um PDF complexo, os valores numéricos podem aparecer em formatos diferentes ou dispersos em locais distintos. Com o IronPDF, você pode extrair todo o texto e, em seguida, usar expressões regulares para encontrar e converter strings em números inteiros de forma eficiente.
Conclusão
A análise sintática de números inteiros em C# é uma habilidade essencial para desenvolvedores, especialmente ao lidar com entrada de dados do usuário ou extração de dados de diversas fontes. Embora métodos embutidos como int.Parse() e Convert.ToInt32() sejam úteis, lidar com dados não estruturados ou semi-estruturados—como o texto encontrado em PDFs—pode apresentar desafios adicionais. É aí que o IronPDF entra em cena, oferecendo uma solução poderosa e simples para extrair texto de PDFs e trabalhar com ele em aplicações .NET .
Ao usar o IronPDF , você obtém a capacidade de extrair facilmente texto de PDFs complexos, incluindo documentos digitalizados, e converter esses dados em valores numéricos utilizáveis. Com recursos como OCR para PDFs digitalizados e ferramentas robustas de extração de texto, o IronPDF permite simplificar o processamento de dados, mesmo em formatos complexos.
Seja para lidar com faturas, relatórios financeiros ou qualquer outro documento que contenha dados numéricos, combinar os métodos ParseInt do C# com o IronPDF ajudará você a trabalhar com mais eficiência e precisão.
Não deixe que PDFs complexos atrasem seu processo de desenvolvimento — comece a usar o IronPDF. Esta é a oportunidade perfeita para explorar como IronPDF pode aprimorar seu fluxo de trabalho. Então, por que não experimentar e ver como pode agilizar seu próximo projeto?
Perguntas frequentes
Como posso converter uma string em um número inteiro em C#?
Em C#, você pode converter uma string em um inteiro usando o método int.Parse() ou Convert.ToInt32() . O método int.Parse() lança uma exceção se a string não for um inteiro válido, enquanto Convert.ToInt32() retorna 0 para entradas nulas.
Quais são as diferenças entre int.Parse() e Convert.ToInt32()?
O método int.Parse() ` converte uma string diretamente em um inteiro e lança uma exceção para formatos inválidos. Já Convert.ToInt32() pode lidar com valores nulos, retornando o valor padrão 0, o que o torna mais seguro para certas aplicações.
Como o int.TryParse() aprimora o tratamento de erros durante a análise sintática?
int.TryParse() ` aprimora o tratamento de erros retornando um valor booleano que indica o sucesso ou a falha da conversão, e utiliza um parâmetro `out` para armazenar o resultado sem lançar exceções para entradas inválidas.
Como o IronPDF pode auxiliar na extração de texto de PDFs para análise sintática?
O IronPDF simplifica a extração de texto de PDFs, fornecendo recursos robustos, como extração de texto e imagem, permitindo que os desenvolvedores acessem facilmente dados de string para analisá-los e convertê-los em valores numéricos com C#.
Quais são os passos envolvidos na instalação de uma biblioteca de PDF como o IronPDF?
Para instalar o IronPDF, use o Console do Gerenciador de Pacotes NuGet no Visual Studio e execute o comando Install-Package IronPDF ou use a janela do Gerenciador de Pacotes NuGet para pesquisar e instalar a biblioteca.
Que desafios podem surgir ao analisar dados numéricos de PDFs?
Analisar dados numéricos de PDFs pode ser um desafio devido a problemas de formatação, como vírgulas e padrões numéricos variados. O IronPDF auxilia nesse processo, permitindo a extração de texto limpo, que pode então ser processado com expressões regulares.
Como as expressões regulares podem auxiliar na extração de dados numéricos de PDFs?
Expressões regulares permitem que os desenvolvedores identifiquem padrões em textos, como números com símbolos, facilitando a extração e conversão de dados numéricos de textos em PDF extraídos usando o IronPDF.
É possível extrair texto de documentos PDF digitalizados?
Sim, o IronPDF inclui recursos de OCR (Reconhecimento Óptico de Caracteres) que permitem a extração de texto de PDFs digitalizados, convertendo imagens digitalizadas em texto editável e pesquisável.
Quais são os benefícios das expressões regulares quando usadas com o IronPDF?
As expressões regulares complementam o IronPDF, permitindo buscas de texto flexíveis e correspondência de padrões, que são essenciais para lidar com cenários complexos de extração de texto, como encontrar e converter números.














