

C# Wyodrębnij tekst z PDF (Samouczek z przykładem kodu)
Pliki PDF (Portable Document Format) odgrywają kluczową rolę w niezliczonych branżach, umożliwiając firmom bezpieczne udostępnianie, przechowywanie i zarządzanie dokumentami. Dla programistów praca z plikami PDF często wiąże się z tworzeniem, odczytywaniem, konwertowaniem i wyodrębnianiem treści w celu zaspokojenia potrzeb klientów. Pobieranie tekstu z plików PDF jest niezbędne do zadań takich jak analiza danych, indeksowanie dokumentów, migracja treści lub wdrażanie funkcji ułatwień dostępu. Nowoczesne biblioteki, takie jak IronPDF, sprawiają, że zadania te są łatwiejsze niż kiedykolwiek, oferując potężne narzędzia do manipulowania plikami PDF przy minimalnym wysiłku.
Niniejszy przewodnik skupia się na jednym z najczęstszych wymagań: wyodrębnianiu tekstu z pliku PDF w języku C#. Przeprowadzimy Cię krok po kroku przez proces konfiguracji projektu w Visual Studio, instalacji IronPDF oraz wykorzystania go do ekstrakcji tekstu, posługując się zwięzłymi przykładami kodu. W trakcie tłumaczenia podkreślimy solidne funkcje IronPDF, w tym możliwość tworzenia, edycji i konwersji plików PDF przy użyciu .NET. Niezależnie od tego, czy tworzysz aplikacje oparte na dużej ilości dokumentów, czy po prostu potrzebujesz wydajnej obsługi plików PDF, ten samouczek pomoże Ci rozpocząć pracę.
Jak wyodrębnić tekst z pliku PDF w języku C#
- Pobierz bibliotekę Extract Text from PDF C#
- Utwórz nowy projekt w Visual Studio
- Zainstaluj bibliotekę w swoim projekcie
- Wykonaj wyodrębnianie tekstu z pliku PDF
- Wyświetl tekst wyjściowy z dokumentu PDF
1. Funkcje IronPDF
IronPDF to solidny konwerter plików PDF, który może wykonywać niemal każdą operację dostępną w przeglądarce. Tworzenie, odczytywanie i edycja dokumentów PDF jest prosta dzięki bibliotece .NET dla programistów. IronPDF konwertuje dokumenty HTML do formatu PDF przy użyciu silnika Chrome. IronPDF obsługuje między innymi HTML, ASPX, Razor HTML i MVC View. Aplikacja Microsoft .NET jest obsługiwana przez IronPDF (zarówno aplikacje internetowe ASP.NET, jak i tradycyjne aplikacje Windows). IronPDF może być również wykorzystywany do tworzenia atrakcyjnych wizualnie dokumentów PDF.
Za pomocą IronPDF możemy utworzyć dokument PDF z plików HTML5, JavaScript, CSS i obrazów. Ponadto pliki mogą zawierać nagłówki i stopki. Dzięki IronPDF możemy z łatwością odczytać dokument PDF. IronPDF posiada również kompleksowy silnik konwersji plików PDF oraz potężny konwerter HTML na PDF, który obsługuje dokumenty PDF.
- Tworzenie plików PDF: Generuj pliki PDF z HTML, JavaScript, CSS, obrazów lub adresów URL. Dodaj nagłówki, stopki, zakładki, znaki wodne i inne niestandardowe elementy, aby uatrakcyjnić wygląd.
- Konwersja HTML do PDF: Konwertuj pliki HTML, widoki Razor/MVC oraz pliki CSS typu media bezpośrednio do formatu PDF.
- Funkcje interaktywnych plików PDF: Twórz, wypełniaj i przesyłaj interaktywne formularze PDF.
- Pobieranie tekstu i obrazów: Pobieraj tekst lub obrazy z istniejących dokumentów PDF w celu przetwarzania danych lub ponownego wykorzystania.
- Manipulacja dokumentami: scalanie, dzielenie i zmiana kolejności stron w nowych lub istniejących plikach PDF.
- Obsługa obrazów i stron: Rasteryzacja stron PDF do obrazów oraz konwersja obrazów do formatu PDF.
- Praca z niestandardowymi danymi logowania: IronPDF umożliwia tworzenie dokumentów na podstawie adresu URL. Obsługuje również niestandardowe dane logowania do sieci, agenty użytkownika, serwery proxy, pliki cookie, nagłówki HTTP oraz zmienne formularzy do logowania za pomocą formularzy logowania HTML.
- Wyszukiwanie i dostępność: Wyszukiwanie tekstu w dokumentach PDF i zapewnienie zgodności z normami dostępności.
- Wszechstronność konwersji: Przekształcaj pliki PDF na inne formaty, takie jak HTML, i korzystaj z plików CSS do generowania plików PDF.
- Funkcjonalność autonomiczna: Działa niezależnie, bez konieczności korzystania z programu Adobe Acrobat lub dodatkowych narzędzi innych firm.
2. Tworzenie nowego projektu w Visual Studio
Otwórz oprogramowanie Visual Studio i przejdź do menu Plik. Wybierz "Nowy projekt", a następnie "Aplikacja konsolowa". W tym artykule wykorzystamy aplikację konsolową do generowania dokumentów PDF.
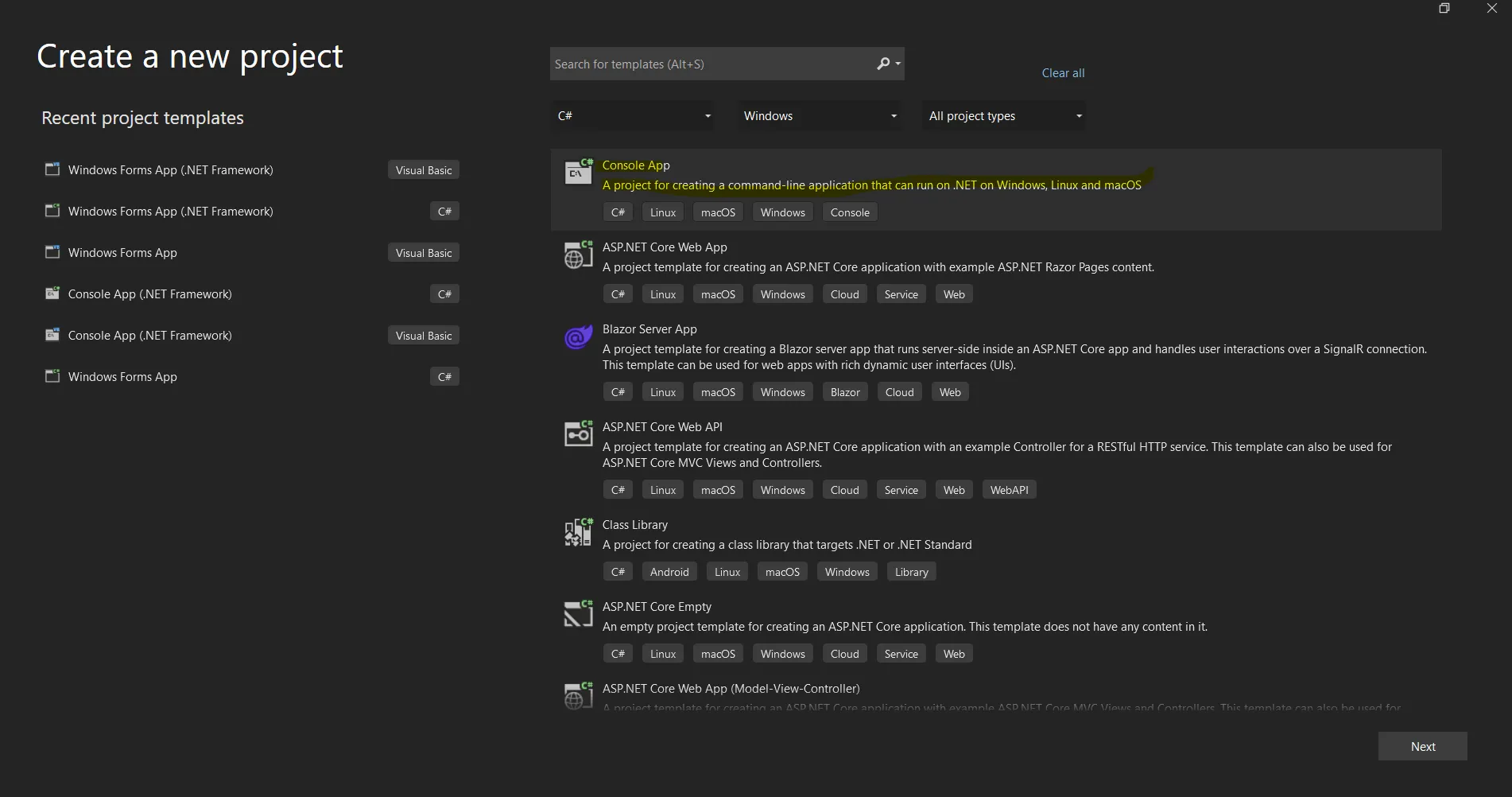 Utwórz nowy projekt w Visual Studio
Utwórz nowy projekt w Visual Studio
Wpisz nazwę projektu i wybierz ścieżkę do pliku w odpowiednim polu tekstowym. Następnie kliknij przycisk Utwórz i wybierz wymagany .NET Framework, tak jak na poniższym zrzucie ekranu.
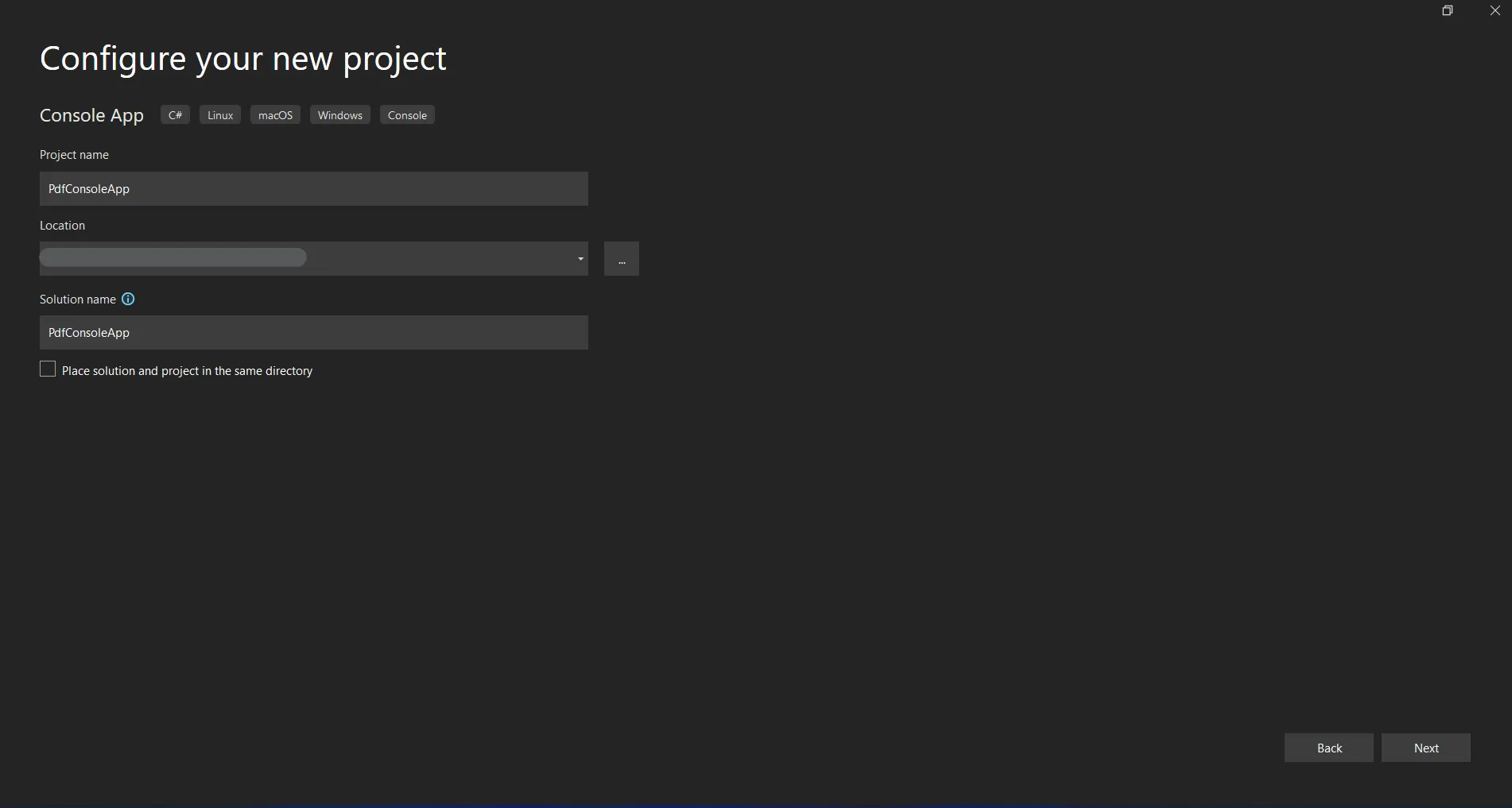 Konfiguracja nowego projektu w Visual Studio
Konfiguracja nowego projektu w Visual Studio
Projekt Visual Studio wygeneruje teraz strukturę dla wybranej aplikacji, a jeśli wybrano aplikację konsolową, aplikację dla systemu Windows lub aplikację internetową, otworzy plik program.cs, w którym można wprowadzić kod oraz skompilować i uruchomić aplikację.
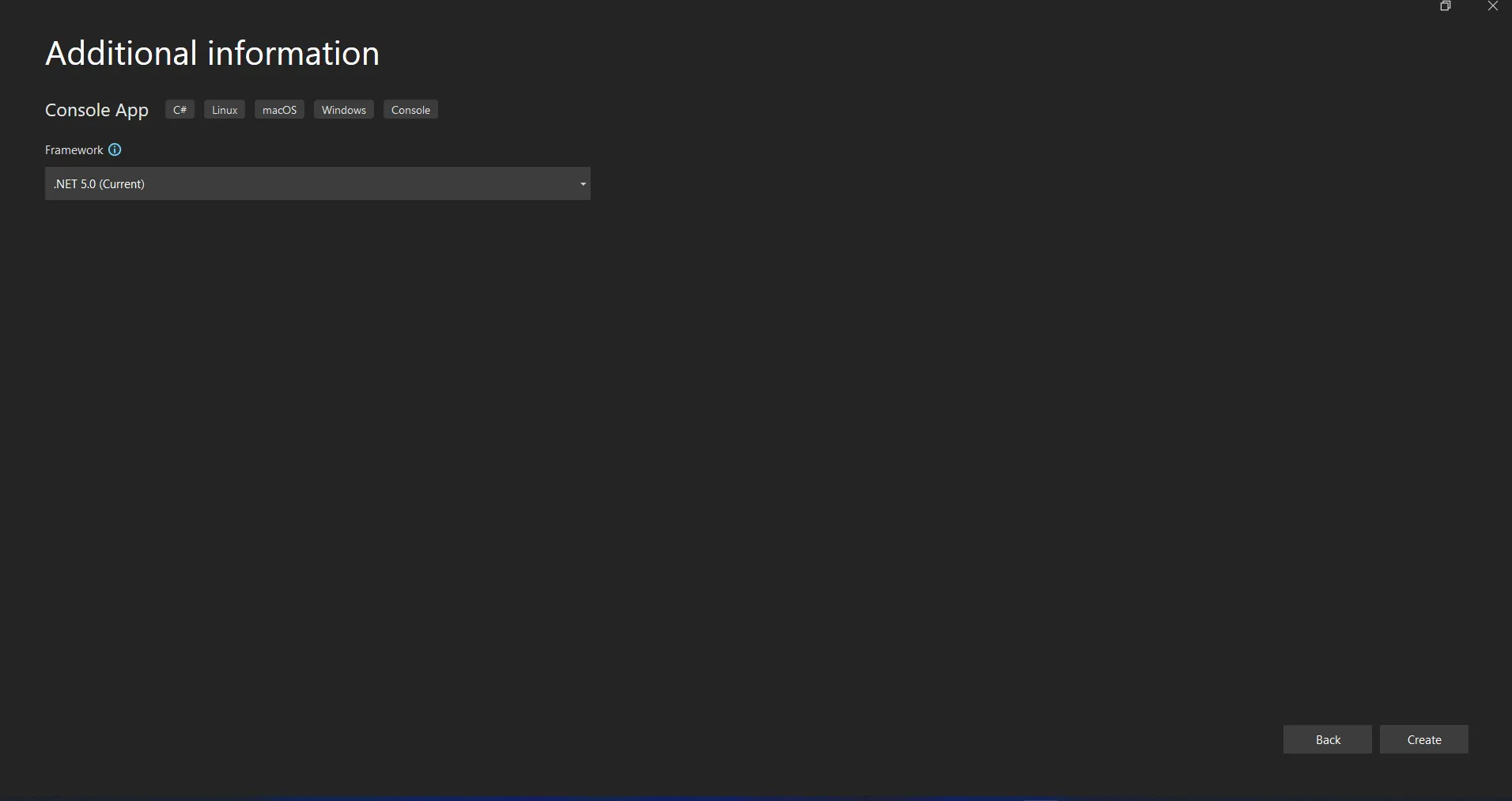 Wybór .NET Core
Wybór .NET Core
Następnie możemy dodać bibliotekę, aby przetestować kod.
3. Zainstaluj bibliotekę IronPDF
Bibliotekę IronPDF można pobrać i zainstalować na cztery sposoby.
Są to:
- Korzystanie z programu Visual Studio.
- Korzystanie z wiersza poleceń programu Visual Studio.
- Bezpośrednie pobranie ze strony NuGet.
- Bezpośrednie pobranie ze strony internetowej IronPDF.
3.1 Korzystanie z programu Visual Studio
Oprogramowanie Visual Studio udostępnia opcję NuGet Package Manager, która pozwala zainstalować pakiet bezpośrednio w rozwiązaniu. Poniższy zrzut ekranu pokazuje, jak otworzyć menedżera pakietów NuGet.
 Plik program.cs w Visual Studio
Plik program.cs w Visual Studio
Udostępnia pole wyszukiwania, w którym wyświetlana jest lista pakietów ze strony NuGet. W menedżerze pakietów należy wyszukać słowo kluczowe "IronPdf", tak jak na poniższym zrzucie ekranu.
 Menedżer pakietów NuGet
Menedżer pakietów NuGet
Na powyższym obrazku widzimy listę powiązanych pozycji wyszukiwania. Musimy wybrać odpowiednią opcję, aby zainstalować pakiet w rozwiązaniu.
3.2 Korzystanie z wiersza poleceń programu Visual Studio
W programie Visual Studio przejdź do menu Narzędzia > Menedżer pakietów NuGet > Konsola menedżera pakietów
Wprowadź następujący wiersz w zakładce konsoli menedżera pakietów:
Install-Package IronPdf
Teraz pakiet zostanie pobrany/zainstalowany w bieżącym projekcie i będzie gotowy do użycia.
 Biblioteka IronPdf w menedżerze pakietów NuGet
Biblioteka IronPdf w menedżerze pakietów NuGet
3.3 Bezpośrednie pobranie ze strony NuGet
Trzecim sposobem jest pobranie pakietu IronPDF NuGet bezpośrednio z ich strony internetowej.
- Przejdź do pakietu IronPDF w serwisie NuGet.
- Wybierz opcję pakietu do pobrania z menu po prawej stronie.
- Kliknij dwukrotnie pobrany pakiet. Zostanie zainstalowany automatycznie.
- Następnie przeładuj rozwiązanie i zacznij z niego korzystać w projekcie.
3.4 Bezpośrednie pobranie ze strony internetowej IronPDF
Odwiedź oficjalną stronę IronPDF, aby pobrać najnowszy pakiet bezpośrednio z ich witryny. Po pobraniu wykonaj poniższe kroki, aby dodać pakiet do projektu.
- Kliknij prawym przyciskiem myszy projekt w oknie rozwiązania.
- Następnie wybierz opcję "Odwołania" i przejdź do lokalizacji pobranego odwołania.
- Następnie kliknij OK, aby dodać odwołanie.
4. Wyodrębnianie tekstu za pomocą IronPDF
Program IronPDF pozwala nam na wyodrębnianie tekstu z pliku PDF oraz konwertowanie stron PDF na obiekty PDF. Poniżej znajduje się przykład wykorzystania IronPDF do odczytania istniejącego pliku PDF.
Pierwszym podejściem jest wyodrębnienie tekstu z pliku PDF, a przykładowy fragment kodu znajduje się poniżej.
using IronPdf;
// Load an existing PDF document from a file
var pdfDocument = PdfDocument.FromFile("result.pdf");
// Extract all text from the entire PDF document
string allText = pdfDocument.ExtractAllText();using IronPdf;
// Load an existing PDF document from a file
var pdfDocument = PdfDocument.FromFile("result.pdf");
// Extract all text from the entire PDF document
string allText = pdfDocument.ExtractAllText();Imports IronPdf
' Load an existing PDF document from a file
Private pdfDocument = PdfDocument.FromFile("result.pdf")
' Extract all text from the entire PDF document
Private allText As String = pdfDocument.ExtractAllText()Metoda statyczna FromFile służy do ładowania dokumentu PDF z istniejącego pliku i przekształcania go w obiekty PDFDocument, jak pokazano w powyższym kodzie. Za pomocą tego obiektu możemy odczytywać tekst i obrazy dostępne na stronach pliku PDF. Obiekt posiada metodę o nazwie ExtractAllText, która wyodrębnia cały tekst z dokumentu PDF, a następnie umieszcza go w ciągu znaków, który możemy wykorzystać do dalszego przetwarzania.
Poniżej znajduje się przykład kodu dla drugiej metody, którą możemy wykorzystać do wyodrębniania tekstu z pliku PDF, strona po stronie.
using IronPdf;
// Load an existing PDF document from a file
using PdfDocument pdf = PdfDocument.FromFile("result.pdf");
// Loop through each page of the PDF document
for (var index = 0; index < pdf.PageCount; index++)
{
// Extract text from the current page
string text = pdf.ExtractTextFromPage(index);
}using IronPdf;
// Load an existing PDF document from a file
using PdfDocument pdf = PdfDocument.FromFile("result.pdf");
// Loop through each page of the PDF document
for (var index = 0; index < pdf.PageCount; index++)
{
// Extract text from the current page
string text = pdf.ExtractTextFromPage(index);
}Imports IronPdf
' Load an existing PDF document from a file
Private PdfDocument As using
' Loop through each page of the PDF document
For index = 0 To pdf.PageCount - 1
' Extract text from the current page
Dim text As String = pdf.ExtractTextFromPage(index)
Next indexW powyższym kodzie widzimy, że najpierw zostanie załadowany cały dokument PDF i przekonwertowany na obiekt PDF. Następnie uzyskujemy liczbę stron całego dokumentu PDF, korzystając z wbudowanej właściwości o nazwie PageCount, która pobiera całkowitą liczbę stron dostępnych w załadowanym dokumencie PDF. Użycie pętli "for" i funkcji ExtractTextFromPage pozwala nam przekazać numer strony jako parametr w celu wyodrębnienia tekstu z załadowanego dokumentu. Następnie zapisze dokładny tekst w zmiennej typu string. Podobnie, będzie wyciągać tekst z pliku PDF strona po stronie za pomocą pętli "for" lub "for each".
5. Podsumowanie
IronPDF to wszechstronna i wydajna biblioteka PDF zaprojektowana w celu płynnej pracy z plikami PDF w aplikacjach .NET. Jego rozbudowane funkcje umożliwiają programistom tworzenie, modyfikowanie i wyodrębnianie treści z plików PDF bez konieczności korzystania z oprogramowania innych firm, takiego jak Adobe Reader. Jedną z wyróżniających się funkcji IronPDF jest możliwość wyodrębniania tekstu z dokumentów PDF. Ta funkcja jest nieoceniona przy automatyzacji zadań, takich jak analiza danych, indeksowanie dokumentów, migracja treści oraz wdrażanie funkcji ułatwień dostępu. Umożliwiając programistom programowe pobieranie i przetwarzanie tekstu, IronPDF upraszcza przepływ pracy i otwiera nowe możliwości obsługi treści PDF.
Dzięki prostej integracji i obsłudze wielu platform IronPDF jest doskonałym wyborem dla programistów, którzy chcą efektywnie obsługiwać dokumenty PDF. Ponadto IronPDF oferuje bezpłatną wersję próbną, która pozwala bez ryzyka zapoznać się z pełnym zakresem funkcji przed podjęciem decyzji o zakupie. Aby uzyskać szczegółowe informacje na temat cen i opcji licencyjnych, odwiedź stronę z cennikiem.
Często Zadawane Pytania
Jak wyodrębnić tekst z dokumentu PDF przy użyciu języka C#?
Możesz wyodrębnić tekst z dokumentu PDF w języku C#, używając biblioteki IronPDF. Najpierw załaduj plik PDF za pomocą metody PdfDocument.FromFile, a następnie zastosuj metodę ExtractAllText, aby pobrać tekst z dokumentu.
Jakie kroki należy wykonać, aby skonfigurować IronPDF w projekcie Visual Studio?
Aby skonfigurować IronPDF w projekcie Visual Studio, można zainstalować go za pomocą menedżera pakietów NuGet. Alternatywnie można użyć wiersza poleceń Visual Studio lub pobrać go bezpośrednio ze stron internetowych NuGet lub IronPDF.
Jakie funkcje sprawiają, że IronPDF jest wszechstronną biblioteką PDF?
IronPDF oferuje szeroki zakres funkcji, w tym tworzenie plików PDF, konwersję HTML na PDF, wyodrębnianie tekstu i obrazów, edycję dokumentów oraz obsługę interaktywnych formularzy PDF.
Czy IronPDF może służyć do konwersji HTML na PDF w języku C#?
Tak, IronPDF może konwertować HTML, w tym widoki Razor/MVC i pliki CSS typu media, bezpośrednio do formatu PDF przy użyciu zintegrowanego silnika Chrome.
Czy IronPDF jest kompatybilny ze wszystkimi typami aplikacji .NET?
Tak, IronPDF jest kompatybilny zarówno z aplikacjami internetowymi ASP.NET, jak i tradycyjnymi aplikacjami Windows, zapewniając wszechstronność programistom .NET.
W jaki sposób IronPDF ułatwia dostępność dokumentów PDF?
IronPDF zwiększa dostępność, umożliwiając użytkownikom wyszukiwanie tekstu w dokumentach PDF i zapewniając zgodność z normami dostępności.
Czy IronPDF wymaga jakichkolwiek zależności od oprogramowania innych firm?
IronPDF działa niezależnie i nie wymaga narzędzi innych firm, takich jak Adobe Acrobat, umożliwiając płynną obsługę plików PDF w aplikacjach .NET.
Jakie są zalety korzystania z IronPDF do wyodrębniania tekstu z plików PDF?
IronPDF usprawnia przepływ pracy, umożliwiając programowe wyodrębnianie tekstu, co jest przydatne do analizy danych, indeksowania dokumentów i migracji treści.
Czy dostępna jest wersja próbna IronPDF?
Tak, IronPDF oferuje bezpłatną wersję próbną, umożliwiającą programistom zapoznanie się z jego funkcjami i możliwościami przed podjęciem decyzji o zakupie.
Jakie znaczenie ma stosowanie IronPDF for .NET do zarządzania plikami PDF w aplikacjach .NET?
IronPDF ma kluczowe znaczenie dla zarządzania plikami PDF w aplikacjach .NET ze względu na swój rozbudowany zestaw funkcji, który obejmuje tworzenie plików PDF, wyodrębnianie tekstu oraz konwersję HTML do PDF, a wszystko to bez konieczności korzystania z zewnętrznego oprogramowania, takiego jak Adobe Acrobat.
Czy kod C# do wyodrębniania tekstu z plików PDF przedstawiony w tym artykule jest kompatybilny z platformą .NET 10?
Tak. Przykłady PdfDocument.FromFile i ExtractText w tym samouczku działają w .NET 10 tak samo, jak w wcześniejszych wersjach .NET. Po utworzeniu projektu .NET 10 zainstaluj najnowszy pakiet IronPDF z NuGet, a następnie uruchom ten sam kod, aby odczytywać pliki PDF i wyodrębniać tekst w nowoczesnych aplikacjach .NET 10.














