

Como visualizar arquivos PDF em ASP.NET usando C# e IronPDF
Os arquivos PDF (Portable Document Format) desempenham um papel vital em inúmeros setores, permitindo que as empresas compartilhem, armazenem e gerenciem documentos com segurança. Para os desenvolvedores, trabalhar com PDFs geralmente envolve criar, ler, converter e extrair conteúdo para atender às necessidades do cliente. Extrair texto de PDFs é essencial para tarefas como análise de dados, indexação de documentos, migração de conteúdo ou ativação de recursos de acessibilidade. Bibliotecas modernas como o IronPDF tornam essas tarefas mais fáceis do que nunca, oferecendo ferramentas poderosas para manipular arquivos PDF com o mínimo esforço.
Este guia se concentra em um dos requisitos mais comuns: extrair texto de um PDF em C#. Vamos orientá-lo na configuração de um projeto no Visual Studio, na instalação do IronPDF e em sua utilização para realizar extração de texto com exemplos de código concisos. Ao longo do texto, destacaremos os recursos robustos do IronPDF, incluindo sua capacidade de criar, manipular e converter arquivos PDF usando o .NET. Seja para desenvolver aplicativos que lidam com muitos documentos ou simplesmente para processar PDFs de forma eficiente, este tutorial lhe dará um ponto de partida.
Como extrair texto de um PDF em C#
- Baixe a biblioteca C# para extrair texto de PDFs.
- Criar um novo projeto no Visual Studio
- Instale a biblioteca no seu projeto.
- Realizar extração de texto do arquivo PDF
- Visualize o texto gerado a partir do documento PDF.
1. Recursos do IronPDF
O IronPDF é um conversor de PDF robusto que pode executar praticamente qualquer operação que um navegador possa realizar. Criar, ler e manipular documentos PDF é simples com a biblioteca .NET para desenvolvedores. O IronPDF converte documentos HTML em PDF usando o mecanismo do Chrome. O IronPDF oferece suporte a HTML, ASPX, Razor HTML e MVC View, entre outros componentes da web. O aplicativo Microsoft .NET é compatível com o IronPDF (tanto aplicativos Web ASP.NET quanto aplicativos tradicionais do Windows). O IronPDF também pode ser usado para criar um documento PDF visualmente atraente.
Podemos criar um documento PDF a partir de HTML5, JavaScript, CSS e imagens com o IronPDF. Além disso, os arquivos podem ter cabeçalhos e rodapés. Graças ao IronPDF, podemos ler documentos PDF com facilidade. O IronPDF também possui um mecanismo abrangente de conversão de PDF e um poderoso conversor de HTML para PDF que pode lidar com documentos PDF.
- Criação de PDFs: Gere PDFs a partir de HTML, JavaScript, CSS, imagens ou URLs. Adicione cabeçalhos, rodapés, marcadores, marcas d'água e outros elementos personalizados para aprimorar o design.
- Conversão de HTML para PDF: Converta arquivos HTML, Razor/MVC Views e CSS de outros tipos de mídia diretamente para o formato PDF.
- Funcionalidades de PDF interativo: Crie, preencha e envie formulários PDF interativos.
- Extração de texto e imagem: Extraia texto ou imagens de documentos PDF existentes para processamento ou reutilização de dados.
- Manipulação de documentos: Mesclar, dividir e reorganizar páginas em arquivos PDF novos ou existentes.
- Manipulação de imagens e páginas: Rasterizar páginas PDF em imagens e converter imagens para o formato PDF .
- Trabalhar com credenciais de login personalizadas: o IronPDF é capaz de criar um documento a partir de uma URL. Ele também oferece suporte a credenciais de login de rede personalizadas, agentes de usuário, proxies, cookies, cabeçalhos HTTP e variáveis de formulário para login por meio de formulários de login HTML .
- Pesquisa e Acessibilidade: Pesquise texto em documentos PDF e assegure-se de que eles atendam aos padrões de acessibilidade.
- Versatilidade de conversão: Transforme PDFs em outros formatos, como HTML, e trabalhe com arquivos CSS para gerar PDFs.
- Funcionalidade independente: Opera de forma independente, sem necessidade do Adobe Acrobat ou de ferramentas adicionais de terceiros.
2. Criando um novo projeto no Visual Studio
Abra o software Visual Studio e acesse o menu Arquivo. Selecione "Novo Projeto" e, em seguida, selecione "Aplicativo de Console". Neste artigo, vamos usar um aplicativo de console para gerar documentos PDF.
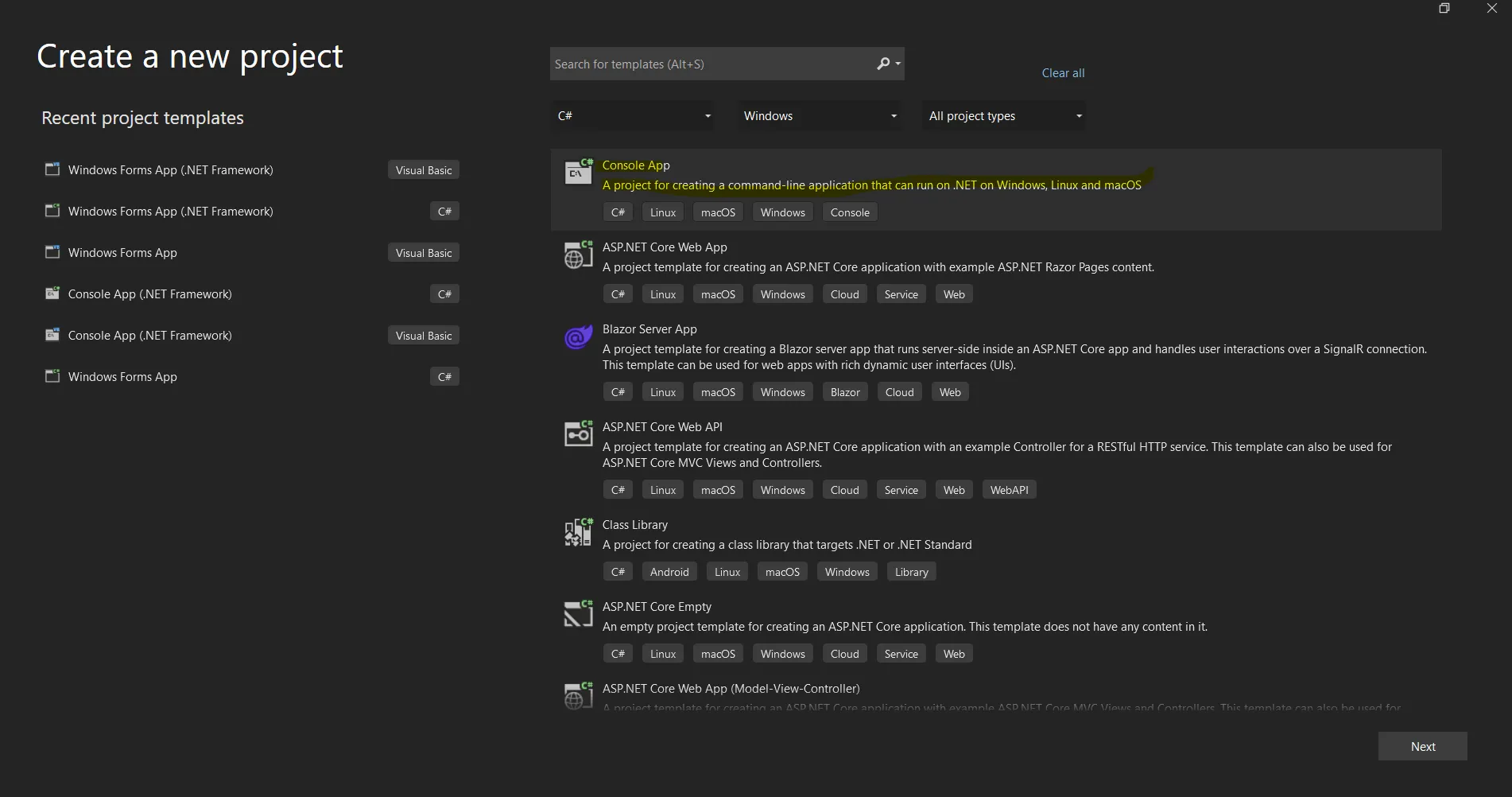 Criar um novo projeto no Visual Studio
Criar um novo projeto no Visual Studio
Insira o nome do projeto e selecione o caminho do arquivo na caixa de texto apropriada. Em seguida, clique no botão Criar e selecione a versão do .NET Framework desejada, conforme mostrado na captura de tela abaixo.
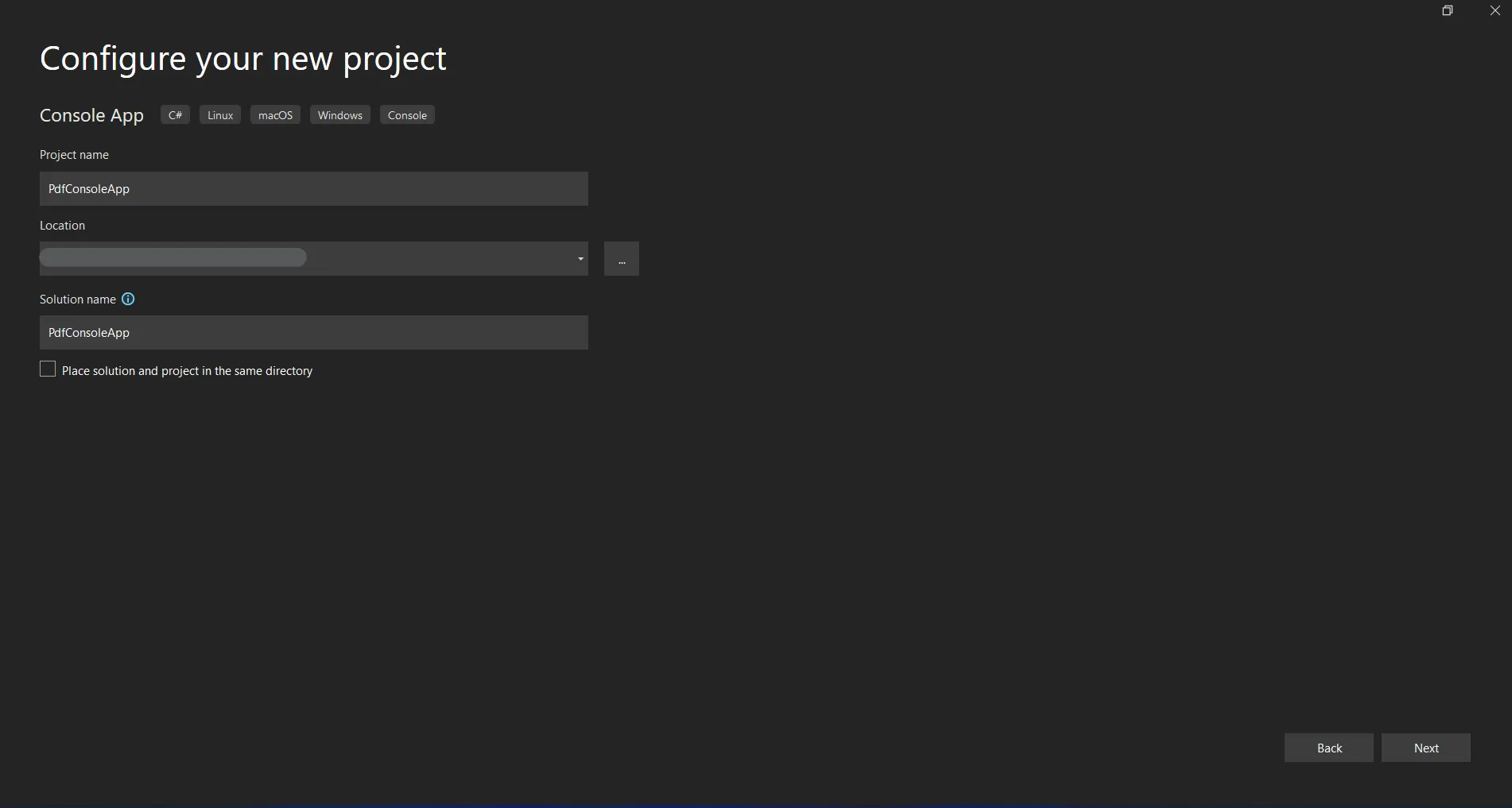 Configurar novo projeto no Visual Studio
Configurar novo projeto no Visual Studio
O projeto do Visual Studio agora gerará a estrutura para a aplicação selecionada e, se você tiver selecionado a Aplicação Console, Windows e Web, ele abrirá o arquivo program.cs onde você pode inserir o código e construir/executar a aplicação.
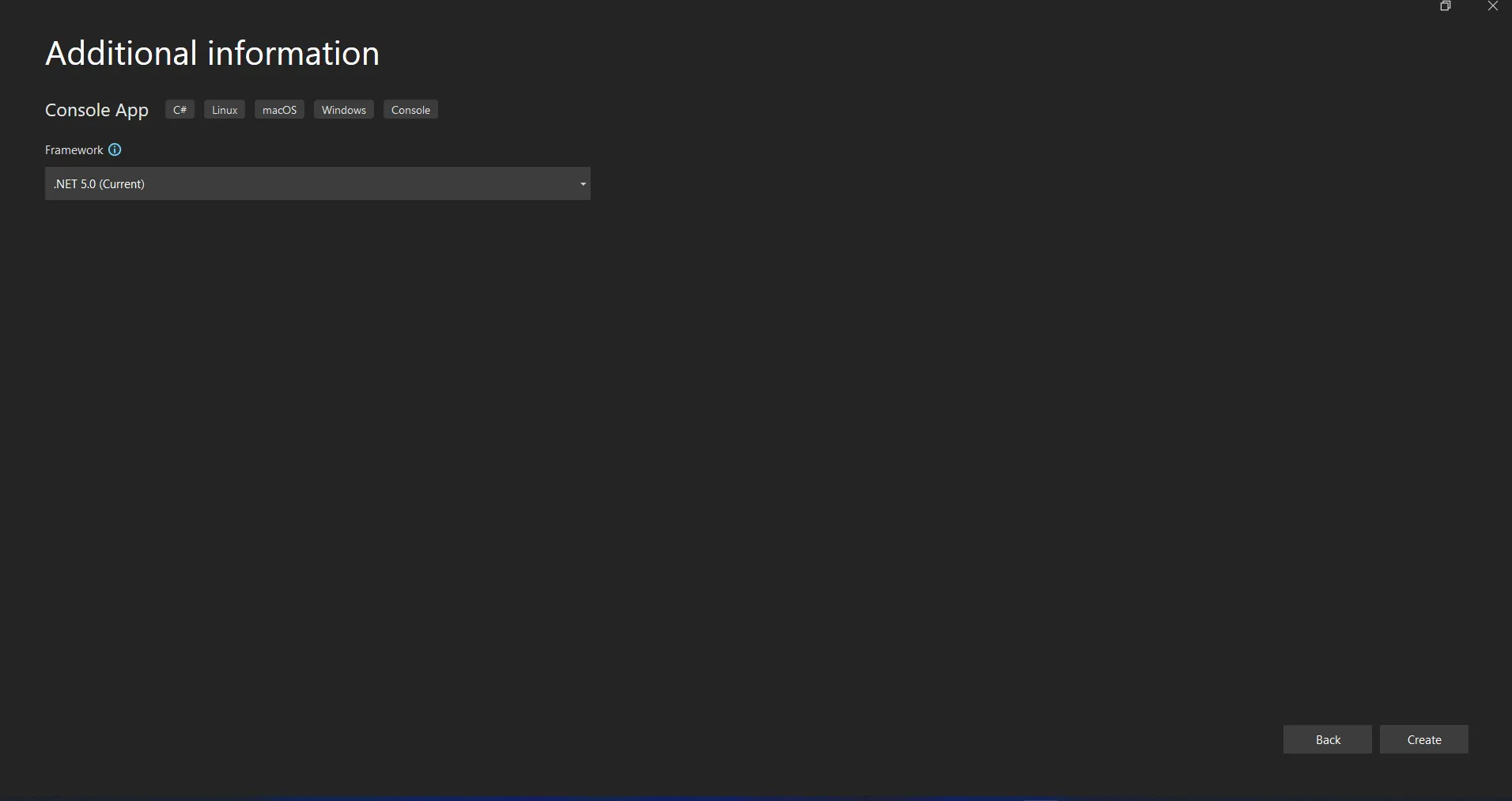 Selecionando .NET Core
Selecionando .NET Core
Em seguida, podemos adicionar a biblioteca para testar o código.
3. Instale a biblioteca IronPDF.
A biblioteca IronPDF pode ser baixada e instalada de quatro maneiras.
Estes são:
- Utilizando o Visual Studio.
- Utilizando a linha de comando do Visual Studio.
- Download direto do site NuGet .
- Download direto do site IronPDF .
3.1 Usando o Visual Studio
O software Visual Studio oferece a opção NuGet Package Manager para instalar o pacote diretamente na solução. A captura de tela abaixo mostra como abrir o Gerenciador de Pacotes NuGet .
 Arquivo program.cs do Visual Studio
Arquivo program.cs do Visual Studio
Ele fornece a caixa de pesquisa para exibir a lista de pacotes do site NuGet . No gerenciador de pacotes, precisamos pesquisar pela palavra-chave "IronPDF", como na captura de tela abaixo.
 Gerenciador de Pacotes NuGet
Gerenciador de Pacotes NuGet
Na imagem acima, podemos ver a lista de itens de pesquisa relacionados. Precisamos selecionar a opção necessária para instalar o pacote na solução.
3.2 Usando a linha de comando do Visual Studio
No Visual Studio, acesse Ferramentas > Gerenciador de Pacotes NuGet > Console do Gerenciador de Pacotes.
Insira a seguinte linha na guia do console do gerenciador de pacotes:
Install-Package IronPdf
Agora o pacote será baixado/instalado no projeto atual e estará pronto para uso.
 Biblioteca IronPDF no Gerenciador de Pacotes NuGet
Biblioteca IronPDF no Gerenciador de Pacotes NuGet
3.3 Download direto do site NuGet
A terceira maneira é baixar o pacote NuGet do IronPDF diretamente do site deles.
- Navegue até o pacote IronPDF no NuGet.
- Selecione a opção de pacote de download no menu à direita.
- Clique duas vezes no pacote baixado. Será instalado automaticamente. Em seguida, recarregue a solução e comece a usá-la no projeto.
3.4 Download direto do site do IronPDF
Visite o site oficial do IronPDF para baixar o pacote mais recente diretamente do site. Após o download, siga os passos abaixo para adicionar o pacote ao projeto.
- Clique com o botão direito do mouse no projeto na janela de soluções. Em seguida, selecione as opções de referência e navegue até o local onde o arquivo de referência foi baixado. Em seguida, clique em OK para adicionar a referência.
4. Extrair texto usando o IronPDF
O programa IronPDF permite extrair texto de um arquivo PDF e converter páginas PDF em objetos PDF. Segue abaixo um exemplo de como usar o IronPDF para ler um PDF existente.
A primeira abordagem consiste em extrair o texto de um PDF, e o trecho de código de exemplo encontra-se abaixo.
using IronPdf;
// Load an existing PDF document from a file
var pdfDocument = PdfDocument.FromFile("result.pdf");
// Extract all text from the entire PDF document
string allText = pdfDocument.ExtractAllText();using IronPdf;
// Load an existing PDF document from a file
var pdfDocument = PdfDocument.FromFile("result.pdf");
// Extract all text from the entire PDF document
string allText = pdfDocument.ExtractAllText();Imports IronPdf
' Load an existing PDF document from a file
Private pdfDocument = PdfDocument.FromFile("result.pdf")
' Extract all text from the entire PDF document
Private allText As String = pdfDocument.ExtractAllText()O método estático FromFile é usado para carregar o documento PDF de um arquivo existente e transformá-lo em objetos PDFDocument, conforme mostrado no código acima. Podemos ler o texto e as imagens acessíveis nas páginas do PDF usando este objeto. O objeto possui um método chamado ExtractAllText que extrai todo o texto do documento PDF inteiro, ele então armazena o texto extraído na string que podemos usar para processamento.
Abaixo está o exemplo de código para o segundo método que podemos usar para extrair texto de um arquivo PDF, página por página.
using IronPdf;
// Load an existing PDF document from a file
using PdfDocument pdf = PdfDocument.FromFile("result.pdf");
// Loop through each page of the PDF document
for (var index = 0; index < pdf.PageCount; index++)
{
// Extract text from the current page
string text = pdf.ExtractTextFromPage(index);
}using IronPdf;
// Load an existing PDF document from a file
using PdfDocument pdf = PdfDocument.FromFile("result.pdf");
// Loop through each page of the PDF document
for (var index = 0; index < pdf.PageCount; index++)
{
// Extract text from the current page
string text = pdf.ExtractTextFromPage(index);
}Imports IronPdf
' Load an existing PDF document from a file
Private PdfDocument As using
' Loop through each page of the PDF document
For index = 0 To pdf.PageCount - 1
' Extract text from the current page
Dim text As String = pdf.ExtractTextFromPage(index)
Next indexNo código acima, vemos que ele primeiro carrega o documento PDF inteiro e o converte em um objeto PDF. Depois, obtemos a contagem de páginas de todo o documento PDF usando uma propriedade embutida chamada PageCount, que recupera o número total de páginas disponíveis no documento PDF carregado. Usar o "for loop" e a função ExtractTextFromPage nos permite passar o número da página como um parâmetro para extrair texto do documento carregado. Em seguida, armazenará o texto exato na variável de string. Da mesma forma, ele extrairá o texto do PDF página por página com a ajuda do laço "for" ou do laço "for each".
5. Conclusão
IronPDF é uma biblioteca PDF versátil e poderosa, projetada para tornar o trabalho com PDFs em aplicações .NET perfeito. Suas funcionalidades robustas permitem que os desenvolvedores criem, manipulem e extraiam conteúdo de PDFs sem depender de softwares de terceiros, como o Adobe Reader. Uma das funcionalidades mais notáveis do IronPDF é a sua capacidade de extrair texto de documentos PDF. Essa funcionalidade é essencial para automatizar tarefas como análise de dados, indexação de documentos, migração de conteúdo e ativação de recursos de acessibilidade. Ao permitir que os desenvolvedores recuperem e processem texto programaticamente, o IronPDF simplifica os fluxos de trabalho e abre novas possibilidades para o gerenciamento de conteúdo em PDF.
Com integração descomplicada e suporte multiplataforma, o IronPDF é uma excelente escolha para desenvolvedores que buscam lidar com documentos PDF de forma eficiente. Além disso, o IronPDF oferece um período de teste gratuito , permitindo que você explore todos os seus recursos sem riscos antes de se comprometer. Para obter detalhes sobre preços e saber mais sobre as opções de licenciamento, visite a página de preços .
Perguntas frequentes
Como posso extrair texto de um documento PDF usando C#?
É possível extrair texto de um documento PDF em C# usando o IronPDF. Primeiro, carregue o PDF usando o método PdfDocument.FromFile e, em seguida, aplique o método ExtractAllText para recuperar o texto do documento.
Quais são os passos envolvidos na configuração do IronPDF em um projeto do Visual Studio?
Para configurar o IronPDF em um projeto do Visual Studio, você pode instalá-lo através do Gerenciador de Pacotes NuGet. Alternativamente, você pode usar a linha de comando do Visual Studio ou baixá-lo diretamente dos sites do NuGet ou do IronPDF.
Quais são as funcionalidades que fazem do IronPDF uma biblioteca de PDFs completa?
O IronPDF oferece uma ampla gama de recursos, incluindo criação de PDFs, conversão de HTML para PDF, extração de texto e imagem, manipulação de documentos e suporte para formulários PDF interativos.
É possível usar o IronPDF para converter HTML em PDF em C#?
Sim, o IronPDF pode converter HTML, incluindo Views Razor/MVC e arquivos CSS de tipos de mídia, diretamente para o formato PDF usando seu mecanismo Chrome integrado.
O IronPDF é compatível com todos os tipos de aplicações .NET?
Sim, o IronPDF é compatível tanto com aplicações Web ASP.NET quanto com aplicações Windows tradicionais, oferecendo versatilidade para desenvolvedores .NET.
Como o IronPDF facilita a acessibilidade em documentos PDF?
O IronPDF aprimora a acessibilidade, permitindo que os usuários pesquisem texto em documentos PDF e garantindo que eles estejam em conformidade com os padrões de acessibilidade.
O IronPDF requer alguma dependência de terceiros?
O IronPDF funciona de forma independente e não requer ferramentas de terceiros como o Adobe Acrobat, permitindo a manipulação perfeita de PDFs em seus aplicativos .NET.
Quais são as vantagens de usar o IronPDF para extrair texto de PDFs?
O IronPDF simplifica os fluxos de trabalho ao permitir a extração programática de texto, o que é útil para análise de dados, indexação de documentos e migração de conteúdo.
Existe uma versão de avaliação disponível para o IronPDF?
Sim, o IronPDF oferece um período de teste gratuito, permitindo que os desenvolvedores explorem seus recursos e funcionalidades antes de tomar uma decisão de compra.
Qual a importância de usar o IronPDF para o gerenciamento de PDFs em aplicações .NET?
O IronPDF é crucial para o gerenciamento de PDFs em aplicações .NET devido ao seu robusto conjunto de recursos, que inclui criação de PDFs, extração de texto e conversão de HTML para PDF, tudo sem a necessidade de softwares externos como o Adobe Acrobat.
O código C# para extração de texto em PDF apresentado neste artigo é compatível com o .NET 10?
Sim. Os exemplos PdfDocument.FromFile e ExtractText neste tutorial funcionam da mesma forma no .NET 10 que nas versões anteriores do .NET. Depois de criar um projeto .NET 10, instale o pacote IronPDF mais recente do NuGet e você poderá executar o mesmo código para ler PDFs e extrair texto em aplicativos .NET 10 modernos.











