

C# Extraire le Texte du PDF (Exemple de Code Tutoriel)
Les fichiers PDF (Portable Document Format) jouent un rôle essentiel dans d'innombrables industries, permettant aux entreprises de partager, stocker et gérer des documents en toute sécurité. Pour les développeurs, travailler avec des PDF implique souvent de créer, lire, convertir et extraire du contenu pour répondre aux besoins des clients. L'extraction de texte des PDF est essentielle pour des tâches telles que l'analyse de données, l'indexation de documents, la migration de contenu ou l'activation de fonctionnalités d'accessibilité. Les bibliothèques modernes comme IronPDF simplifient ces tâches comme jamais auparavant, offrant des outils puissants pour manipuler les fichiers PDF avec un minimum d'effort.
Ce guide se concentre sur l'une des exigences les plus courantes : extraire du texte d'un PDF en C#. Nous vous guiderons dans la configuration d'un projet dans Visual Studio, l'installation d'IronPDF et son utilisation pour effectuer l'extraction de texte avec des exemples de code concis. En chemin, nous mettrons en avant les fonctionnalités robustes d'IronPDF, y compris sa capacité à créer, manipuler et convertir des fichiers PDF à l'aide de .NET. Que vous construisiez des applications riches en documents ou simplement besoin d'une gestion efficace des PDF, ce tutoriel vous permettra de bien démarrer.
Comment extraire du texte d'un PDF en C#
- Télécharger Extraire du texte d'un PDF bibliothèque C#
- Créer un Nouveau Projet dans Visual Studio
- Installer la Bibliothèque dans votre Projet
- Effectuer l'extraction de texte du fichier PDF
- Voir la sortie de texte de votre document PDF
1. Fonctionnalités d'IronPDF
IronPDF est un convertisseur PDF robuste qui peut effectuer presque toutes les opérations qu'un navigateur peut. Créer, lire et manipuler des documents PDF est simple avec la bibliothèque .NET pour les développeurs. IronPDF convertit les documents HTML en PDF en utilisant le moteur Chrome. IronPDF supporte HTML, ASPX, Razor HTML, et MVC View, entre autres composants web. L'application Microsoft .NET est supportée par IronPDF (à la fois les applications Web ASP.NET et les applications Windows traditionnelles). IronPDF peut également être utilisé pour créer un document PDF visuellement attrayant.
Nous pouvons créer un document PDF à partir de HTML5, JavaScript, CSS et d'images avec IronPDF. De plus, les fichiers peuvent avoir des en-têtes et des pieds de page. Grâce à IronPDF, nous pouvons facilement lire un document PDF. IronPDF possède également un moteur de conversion PDF complet et un puissant convertisseur HTML en PDF capable de traiter les documents PDF.
- Création de PDF : Générez des PDF à partir de HTML, JavaScript, CSS, images ou URL. Ajoutez des en-têtes, pieds de page, signets, filigranes et autres éléments personnalisés pour améliorer le design.
- Conversion HTML en PDF : Convertissez les vues HTML, Razor/MVC et les fichiers CSS de type média directement en format PDF.
- Fonctionnalités interactives de PDF : Construisez, remplissez et soumettez des formulaires PDF interactifs.
- Extraction de texte et d'images : Extrayez le texte ou les images des documents PDF existants pour le traitement des données ou la réutilisation.
- Manipulation de documents : Fusionnez, divisez, et réorganisez les pages dans des fichiers PDF nouveaux ou existants.
- Gestion des images et des pages : Rasterisez les pages PDF en images et convertissez les images en format PDF.
- Travailler avec des identifiants de connexion personnalisés : IronPDF est capable de créer un document à partir d'une URL. Il prend également en charge des identifiants de connexion réseau personnalisés, des agents utilisateurs, des proxys, des cookies, des en-têtes HTTP et des variables de formulaire pour la connexion derrière les formulaires de connexion HTML.
- Recherche et accessibilité : Cherchez du texte dans les documents PDF et assurez-vous qu'ils répondent aux normes d'accessibilité.
- Polyvalence de conversion : Transformez les PDF en d'autres formats comme HTML et travaillez avec les fichiers CSS pour générer des PDF.
- Fonctionnalité autonome : Fonctionne de manière indépendante sans nécessiter Adobe Acrobat ou d'autres outils tiers.
2. Créer un nouveau projet dans Visual Studio
Ouvrez le logiciel Visual Studio et allez dans le menu Fichier. Sélectionnez " Nouveau projet ", puis sélectionnez " Application console ". Dans cet article, nous allons utiliser une application console pour générer des documents PDF.
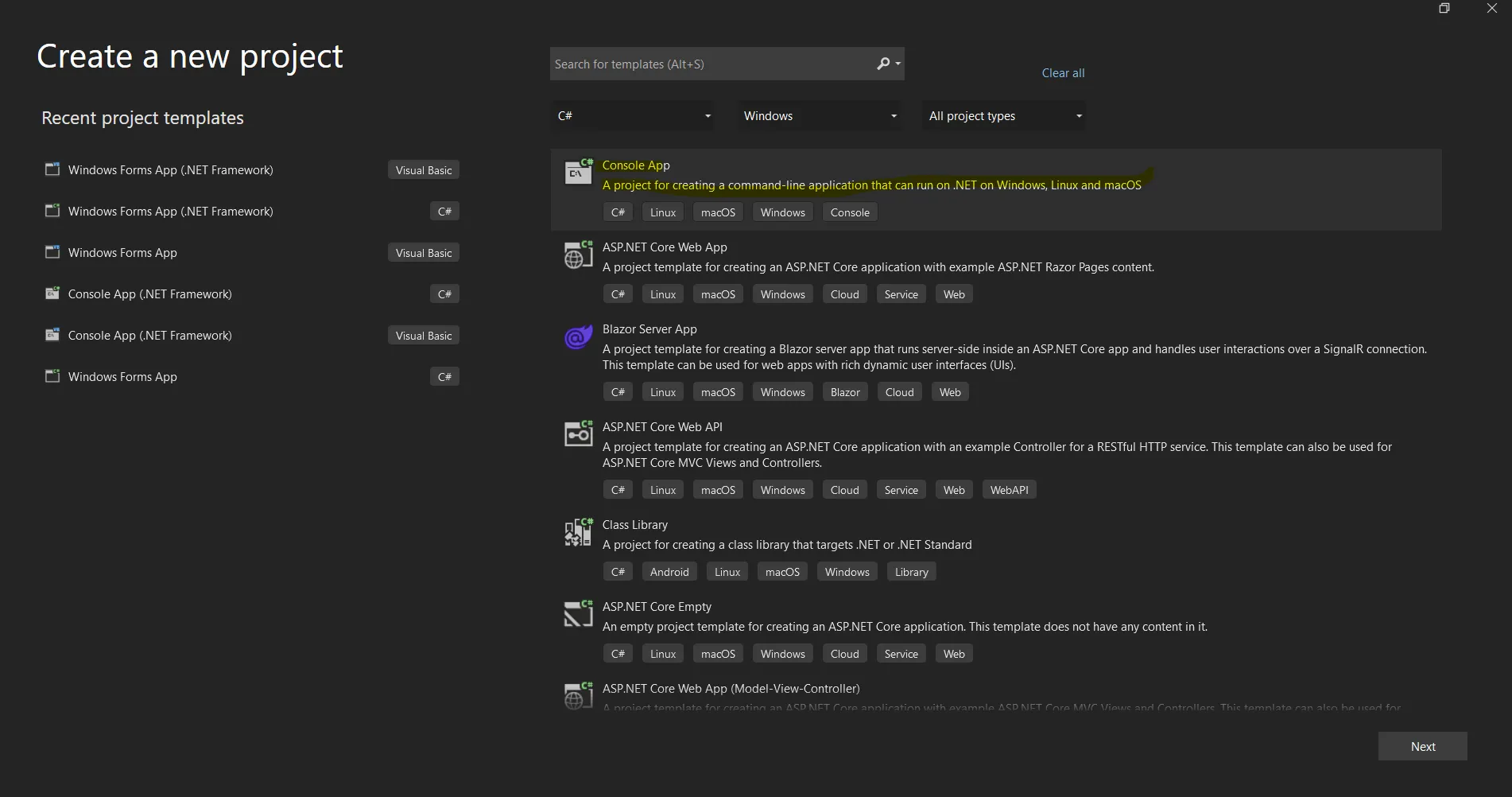 Créer un nouveau projet dans Visual Studio
Créer un nouveau projet dans Visual Studio
Entrez le nom du projet et sélectionnez le chemin du fichier dans la zone de texte appropriée. Ensuite, cliquez sur le bouton Créer et sélectionnez le .NET Framework requis, comme dans la capture d'écran ci-dessous.
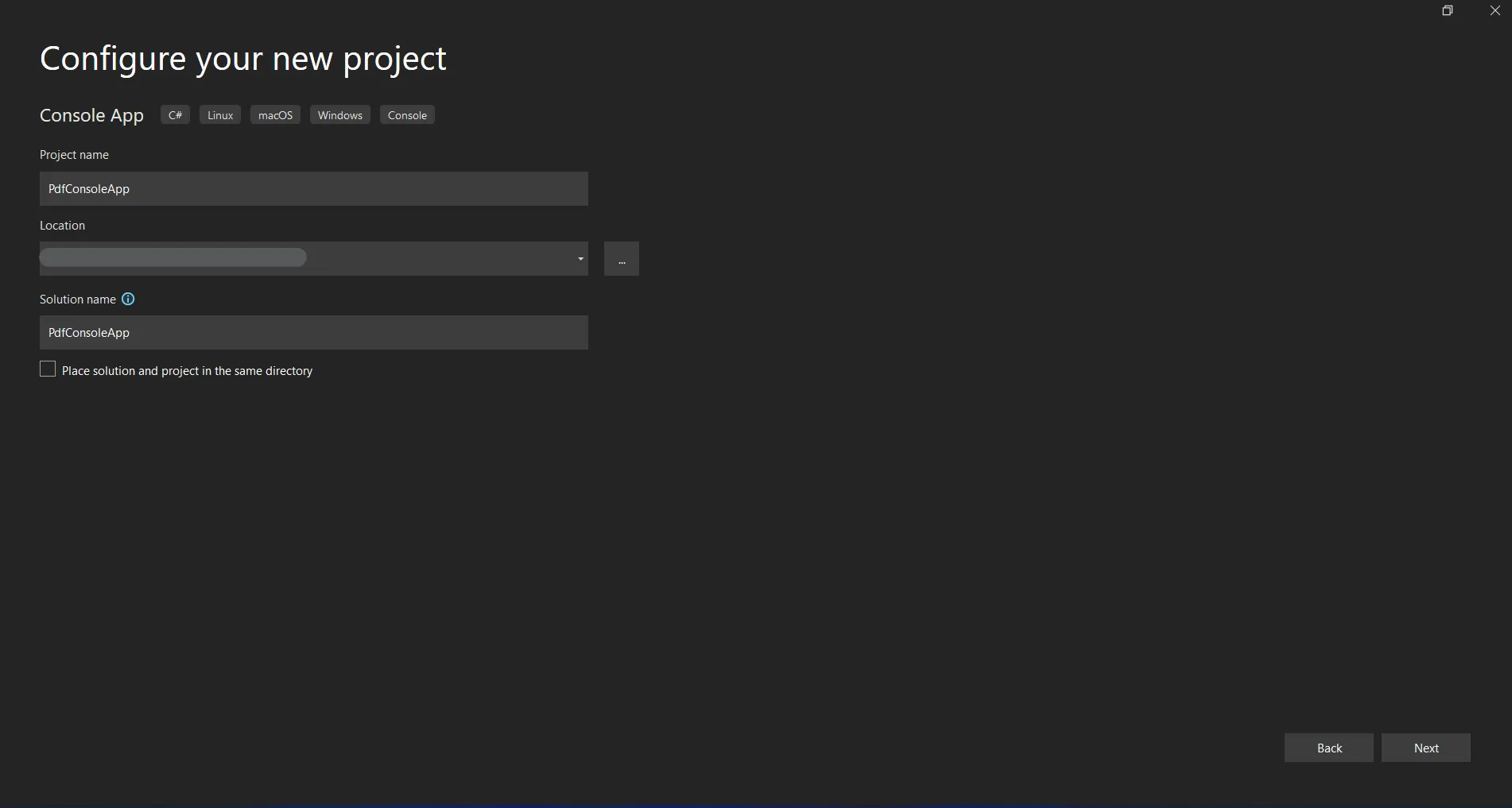 Configuration d'un nouveau projet dans Visual Studio
Configuration d'un nouveau projet dans Visual Studio
Le projet Visual Studio va maintenant générer la structure de l'application sélectionnée, et si vous avez sélectionné l'application console, Windows et Web, il ouvrira le fichier program.cs dans lequel vous pourrez entrer le code et compiler/exécuter l'application.
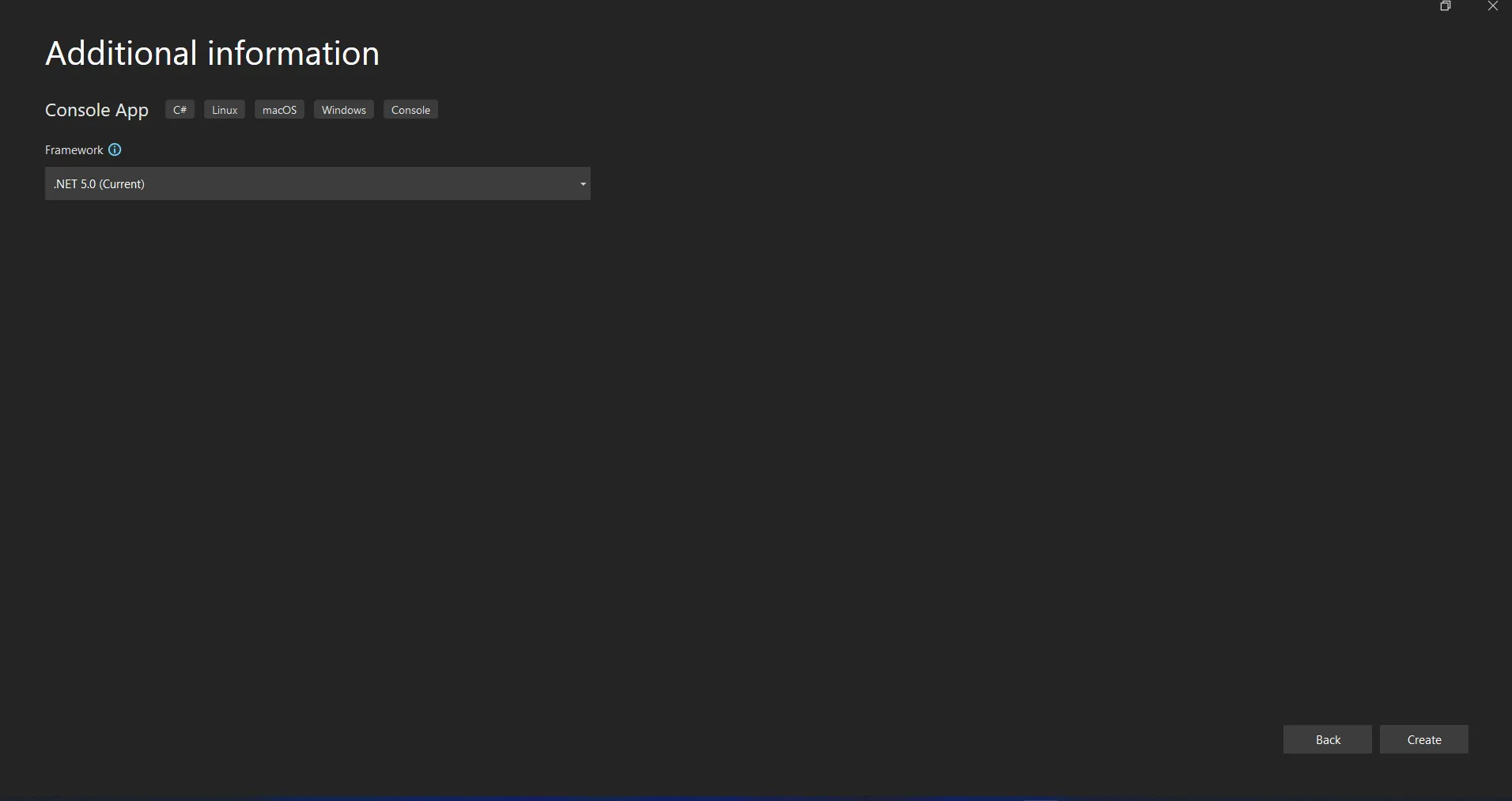 Sélection de .NET Core
Sélection de .NET Core
Ensuite, nous pouvons ajouter la bibliothèque pour tester le code.
3. Installer la bibliothèque IronPDF
La bibliothèque IronPDF peut être téléchargée et installée de quatre manières.
Ceux-ci sont :
- Utilisation de Visual Studio.
- En utilisant la ligne de commande de Visual Studio.
- Téléchargement direct depuis le site Web de NuGet.
- Téléchargement direct depuis le site IronPDF.
3.1 Utilisation de Visual Studio
Le logiciel Visual Studio offre l'option Gestionnaire de packages NuGet pour installer le package directement dans la solution. La capture d'écran ci-dessous montre comment ouvrir le Package Manager NuGet.
 Fichier program.cs de Visual Studio
Fichier program.cs de Visual Studio
Il offre la boîte de recherche pour afficher la liste des paquets du site NuGet. Dans le Package Manager, nous devons rechercher le mot-clé " IronPDF ", comme dans la capture d'écran ci-dessous.
 Gestionnaire de packages NuGet
Gestionnaire de packages NuGet
Dans l'image ci-dessus, nous pouvons voir la liste des éléments de recherche associés. Nous devons sélectionner l'option requise pour installer le paquet dans la solution.
3.2 Utilisation de la ligne de commande de Visual Studio
Dans Visual Studio, allez dans Outils > Package Manager NuGet > Console du Package Manager
Entrez la ligne suivante dans l'onglet de la console du gestionnaire de packages :
Install-Package IronPdf
Maintenant, le package va être téléchargé/installé dans le projet en cours et sera prêt à l'emploi.
 Bibliothèque IronPDF dans le gestionnaire de packages NuGet
Bibliothèque IronPDF dans le gestionnaire de packages NuGet
3.3 Téléchargement direct depuis le site de NuGet
La troisième manière est de télécharger le paquet NuGet IronPDF directement depuis leur site.
- Accédez au paquet IronPDF sur NuGet.
- Sélectionnez l'option de téléchargement de paquet dans le menu à droite.
- Double-cliquez sur le paquet téléchargé. Il s'installera automatiquement.
- Ensuite, rechargez la solution et commencez à l'utiliser dans le projet.
3.4 Téléchargement direct depuis le site IronPDF
Visitez le site officiel d'IronPDF pour télécharger le dernier paquet directement depuis leur site. Une fois téléchargé, suivez les étapes ci-dessous pour ajouter le paquet au projet.
- Clic-droit sur le projet dans la fenêtre de solution.
- Puis, sélectionnez les options de référence et parcourez l'emplacement de la référence téléchargée.
- Ensuite, cliquez sur OK pour ajouter la référence.
4. Extraction de texte avec IronPDF
Le programme IronPDF nous permet de réaliser l'extraction de texte du fichier PDF et de convertir les pages PDF en objets PDF. Ce qui suit est un exemple de comment utiliser IronPDF pour lire un PDF existant.
La première approche est d'extraire du texte d'un PDF et l'extrait de code exemple est ci-dessous.
using IronPdf;
// Load an existing PDF document from a file
var pdfDocument = PdfDocument.FromFile("result.pdf");
// Extract all text from the entire PDF document
string allText = pdfDocument.ExtractAllText();using IronPdf;
// Load an existing PDF document from a file
var pdfDocument = PdfDocument.FromFile("result.pdf");
// Extract all text from the entire PDF document
string allText = pdfDocument.ExtractAllText();Imports IronPdf
' Load an existing PDF document from a file
Private pdfDocument = PdfDocument.FromFile("result.pdf")
' Extract all text from the entire PDF document
Private allText As String = pdfDocument.ExtractAllText()La méthode statique FromFile est utilisée pour charger le document PDF à partir d'un fichier existant et le transformer en objets PDFDocument, comme indiqué dans le code ci-dessus. Nous pouvons lire le texte et les images accessibles sur les pages PDF en utilisant cet objet. L'objet possède une méthode appelée ExtractAllText qui extrait tout le texte de l'ensemble du document PDF, puis stocke le texte extrait dans la chaîne que nous pouvons utiliser pour le traitement.
Ci-dessous est l'exemple de code pour la deuxième méthode que nous pouvons utiliser pour extraire le texte d'un fichier PDF, page par page.
using IronPdf;
// Load an existing PDF document from a file
using PdfDocument pdf = PdfDocument.FromFile("result.pdf");
// Loop through each page of the PDF document
for (var index = 0; index < pdf.PageCount; index++)
{
// Extract text from the current page
string text = pdf.ExtractTextFromPage(index);
}using IronPdf;
// Load an existing PDF document from a file
using PdfDocument pdf = PdfDocument.FromFile("result.pdf");
// Loop through each page of the PDF document
for (var index = 0; index < pdf.PageCount; index++)
{
// Extract text from the current page
string text = pdf.ExtractTextFromPage(index);
}Imports IronPdf
' Load an existing PDF document from a file
Private PdfDocument As using
' Loop through each page of the PDF document
For index = 0 To pdf.PageCount - 1
' Extract text from the current page
Dim text As String = pdf.ExtractTextFromPage(index)
Next indexDans le code ci-dessus, nous voyons qu'il chargera d'abord l'intégralité du document PDF et le convertira en un objet PDF. Ensuite, nous obtenons le nombre de pages de l'ensemble du document PDF en utilisant une propriété intégrée appelée PageCount, qui récupère le nombre total de pages disponibles dans le document PDF chargé. L'utilisation de la boucle " for " et de la fonction ExtractTextFromPage nous permet de passer le numéro de page comme paramètre pour extraire du texte du document chargé. Il conservera ensuite le texte exact dans la variable de chaîne. De même, il extraira le texte de la page PDF, page par page, à l'aide de la boucle "for" ou "for each".
5. Conclusion
IronPDF est une bibliothèque PDF polyvalente et puissante conçue pour rendre le travail avec les PDF dans les applications .NET transparent. Ses fonctionnalités robustes permettent aux développeurs de créer, manipuler et extraire le contenu des PDF sans dépendre des dépendances tierces comme Adobe Reader. L'une des capacités exceptionnelles d'IronPDF est sa capacité à extraire du texte de documents PDF. Cette fonctionnalité est inestimable pour automatiser des tâches telles que l'analyse de données, l'indexation de documents, la migration de contenu et l'activation de fonctionnalités d'accessibilité. En permettant aux développeurs de récupérer et traiter du texte de manière programmatique, IronPDF simplifie les flux de travail et ouvre de nouvelles possibilités pour la gestion du contenu PDF.
Avec une intégration simple et un support multiplateforme, IronPDF est un excellent choix pour les développeurs cherchant à gérer efficacement les documents PDF. De plus, IronPDF offre un essai gratuit, vous permettant d'explorer toute sa gamme de fonctionnalités sans risque avant de vous engager. Pour les détails sur les prix et pour en savoir plus sur les options de licence, visitez la page des prix.
Questions Fréquemment Posées
Comment puis-je extraire du texte d'un document PDF en utilisant C# ?
Vous pouvez extraire du texte d'un document PDF en C# en using IronPDF. Tout d'abord, chargez le PDF avec la méthode PdfDocument.FromFile puis appliquez la méthode ExtractAllText pour récupérer le texte du document.
Quelles étapes sont impliquées dans la configuration d'IronPDF dans un projet Visual Studio ?
Pour configurer IronPDF dans un projet Visual Studio, vous pouvez l'installer via le gestionnaire de packages NuGet. Alternativement, vous pouvez utiliser la ligne de commande de Visual Studio ou le télécharger directement depuis les sites Web de NuGet ou IronPDF.
Quelles caractéristiques font d'IronPDF une bibliothèque PDF complète ?
IronPDF propose un large éventail de fonctionnalités, notamment la création de PDF, la conversion de HTML en PDF, l'extraction de texte et d'images, la manipulation de documents, et la prise en charge des formulaires PDF interactifs.
IronPDF peut-il être utilisé pour convertir du HTML en PDF en C# ?
Oui, IronPDF peut convertir du HTML, y compris les vues Razor/MVC et les fichiers CSS de type média, directement au format PDF grâce à son moteur Chrome intégré.
IronPDF est-il compatible avec tous les types d'applications .NET ?
Oui, IronPDF est compatible à la fois avec les applications Web ASP.NET et les applications Windows traditionnelles, offrant ainsi une polyvalence pour les développeurs .NET.
Comment IronPDF facilite-t-il l'accessibilité dans les documents PDF ?
IronPDF améliore l'accessibilité en permettant aux utilisateurs de rechercher du texte dans les documents PDF et en garantissant qu'ils respectent les normes d'accessibilité.
Y a-t-il des dépendances tierces requises pour IronPDF ?
IronPDF fonctionne de manière autonome et ne nécessite pas d'outils tiers comme Adobe Acrobat, permettant une manipulation transparente des PDF dans vos applications .NET.
Quels sont les avantages de l'utilisation d'IronPDF pour l'extraction de texte depuis des PDF ?
IronPDF rationalise les flux de travail en permettant l'extraction programmatique de texte, ce qui est utile pour l'analyse de données, l'indexation de documents et la migration de contenu.
Une version d'essai est-elle disponible pour IronPDF ?
Oui, IronPDF propose un essai gratuit, permettant aux développeurs d'explorer ses fonctionnalités et capacités avant de prendre une décision d'achat.
Quelle est l'importance d'utiliser IronPDF pour la gestion des PDF dans les applications .NET ?
IronPDF est crucial pour la gestion des PDF dans les applications .NET en raison de son ensemble de fonctionnalités robustes, qui inclut la création de PDF, l'extraction de texte, et la conversion de HTML en PDF, le tout sans avoir besoin de logiciels externes comme Adobe Acrobat.
Le code d'extraction de texte PDF en C# de cet article est-il compatible avec .NET 10 ?
Oui. Les exemples PdfDocument.FromFile et ExtractText de ce tutoriel fonctionnent de la même manière dans .NET 10 que dans les versions précédentes de .NET. Après avoir créé un projet .NET 10, installez le package IronPDF le plus récent depuis NuGet ; vous pourrez alors exécuter le même code pour lire des PDF et extraire du texte dans les applications .NET 10 modernes.













