Jak użyć toLowerCase w Java
W programowaniu w języku Java manipulowanie ciągami znaków jest podstawowym aspektem wielu aplikacji. Często niezbędna jest możliwość przekształcania ciągów znaków na jednolitą wielkość liter, np. małe lub wielkie. Metoda toLowerCase() w Javie zapewnia prosty i skuteczny sposób na osiągnięcie tej transformacji.
Ten artykuł pomoże Ci zgłębić złożoność funkcji toLowerCase() — jej składnię, praktyczne zastosowania i przykłady — aby umożliwić programistom Java opanowanie konwersji klas ciągów znaków.
Zrozumienie składni funkcji toLowerCase()
Metoda toLowerCase w klasie String języka Java jest wszechstronnym narzędziem do obsługi różnic między wielkimi i małymi literami. Niezależnie od tego, czy metoda ta jest stosowana do całego ciągu znaków, czy do określonych znaków z określoną domyślną lokalizacją, zapewnia ona elastyczność i precyzję w zarządzaniu wielkimi literami.
Metoda toLowerCase() jest częścią klasy java.lang.String, dzięki czemu jest łatwo dostępna dla wszystkich obiektów typu string w Javie. Składnia jest prosta:
public String toLowerCase() // Converts all characters to lowercasepublic String toLowerCase() // Converts all characters to lowercaseMetoda nie przyjmuje żadnych parametrów i zwraca nowy ciąg znaków, w którym wszystkie znaki zostały zamienione na małe litery. Nie modyfikuje oryginalnego ciągu znaków; zamiast tego tworzy nowy ciąg znaków, w którym znaki są zamienione na małe litery.
Praktyczne zastosowania funkcji toLowerCase()
Porównanie ciągów znaków bez uwzględniania wielkości liter
Jednym z typowych zastosowań funkcji toLowerCase() jest porównywanie ciągów znaków bez uwzględniania wielkości liter. Dzięki zamianie obu ciągów znaków na małe litery programiści mogą zapewnić dokładne porównania bez martwienia się o różnice w wielkości liter.
String str = "Hello";
String str2 = "hello";
if (str.toLowerCase().equals(str2.toLowerCase())) {
System.out.println("The strings are equal (case-insensitive).");
} else {
System.out.println("The strings are not equal.");
}String str = "Hello";
String str2 = "hello";
if (str.toLowerCase().equals(str2.toLowerCase())) {
System.out.println("The strings are equal (case-insensitive).");
} else {
System.out.println("The strings are not equal.");
}Normalizacja danych wejściowych
W przypadku danych wprowadzanych przez użytkownika normalizacja wielkości liter zapewnia spójność przetwarzania. Na przykład podczas sprawdzania poprawności adresów e-mail lub nazw użytkowników, zamiana ich na małe litery przed zapisaniem lub porównaniem może zapobiec niezamierzonym rozbieżnościom.
String userInput = "UsErNaMe@eXample.com";
String normalizedInput = userInput.toLowerCase();
// Store or compare normalizedInputString userInput = "UsErNaMe@eXample.com";
String normalizedInput = userInput.toLowerCase();
// Store or compare normalizedInputWyszukiwanie i filtrowanie
Metoda toLowerCase() jest przydatna podczas wyszukiwania lub filtrowania ciągów znaków, zwłaszcza gdy wielkość liter nie ma kluczowego znaczenia. Na przykład filtrowanie listy nazw plików bez względu na wielkość liter:
import java.util.Arrays;
import java.util.List;
List<String> filenames = Arrays.asList("Document.txt", "Image.jpg", "Data.csv");
String searchTerm = "image";
for (String filename : filenames) {
if (filename.toLowerCase().contains(searchTerm.toLowerCase())) {
System.out.println("Found: " + filename);
}
}import java.util.Arrays;
import java.util.List;
List<String> filenames = Arrays.asList("Document.txt", "Image.jpg", "Data.csv");
String searchTerm = "image";
for (String filename : filenames) {
if (filename.toLowerCase().contains(searchTerm.toLowerCase())) {
System.out.println("Found: " + filename);
}
}Przykłady ilustrujące użycie funkcji toLowerCase()
Przykład 1: Podstawowa konwersja ciągów znaków
String originalString = "Hello World!";
String lowercaseString = originalString.toLowerCase();
System.out.println("Original: " + originalString);
System.out.println("Lowercase: " + lowercaseString);String originalString = "Hello World!";
String lowercaseString = originalString.toLowerCase();
System.out.println("Original: " + originalString);
System.out.println("Lowercase: " + lowercaseString);Ten przykład po prostu zamienia wszystkie wielkie litery w ciągu znaków na małe.
Wynik
Original: Hello World!
Lowercase: hello world!Przykład 2: Porównanie bez uwzględniania wielkości liter
String input1 = "Java";
String input2 = "java";
if (input1.toLowerCase().equals(input2.toLowerCase())) {
System.out.println("The strings are equal (case-insensitive).");
} else {
System.out.println("The strings are not equal.");
}String input1 = "Java";
String input2 = "java";
if (input1.toLowerCase().equals(input2.toLowerCase())) {
System.out.println("The strings are equal (case-insensitive).");
} else {
System.out.println("The strings are not equal.");
}Metoda ta konwertuje oba ciągi znaków na małe litery przed ich porównaniem, pokazując, że są one równe niezależnie od ich pierwotnej wielkości liter.
Wynik
The strings are equal (case-insensitive).Przykład 3: Normalizacja danych wprowadzanych przez użytkownika
String userInput = "UsErInPut";
String normalizedInput = userInput.toLowerCase();
System.out.println("Original Input: " + userInput);
System.out.println("Normalized Input: " + normalizedInput);String userInput = "UsErInPut";
String normalizedInput = userInput.toLowerCase();
System.out.println("Original Input: " + userInput);
System.out.println("Normalized Input: " + normalizedInput);Ten przykład pokazuje, w jaki sposób zamiana liter wielkich na małe może rozwiązać problemy związane z niespójną wielkością liter, na przykład podczas porównywania nazw użytkowników lub haseł.
Wynik
Original Input: UsErInPut
Normalized Input: userinputUsprawnianie obsługi plików PDF w Javie dzięki IronPDF: Wykorzystanie operacji na ciągach znaków
Przedstawiamy IronPDF for Java
Poznaj IronPDF for Java – solidną bibliotekę Java zaprojektowaną w celu uproszczenia tworzenia, edycji i zarządzania dokumentami PDF. Niezależnie od tego, czy renderujesz HTML do PDF, konwertujesz istniejące pliki, czy wykonujesz zaawansowane operacje na plikach PDF, IronPDF usprawnia ten proces, udostępniając go programistom z różnych dziedin.
Dzięki IronPDF programiści mogą korzystać z wielu funkcji usprawniających zadania związane z plikami PDF, takich jak wyodrębnianie tekstu, osadzanie obrazów i precyzyjne formatowanie. Zapewnia kompleksowy zestaw narzędzi dostosowanych do różnorodnych wymagań, co czyni go cennym zasobem dla aplikacji Java zajmujących się obsługą plików PDF.
Zdefiniuj IronPDF jako zależność Java
Aby rozpocząć korzystanie z IronPDF w projekcie Java, należy zdefiniować go jako zależność w konfiguracji projektu. Poniższe kroki pokazują, jak to zrobić przy użyciu Mavena.
Zależność pom.xml
Dodaj następujące zależności do pliku pom.xml:
<dependencies>
<dependency>
<groupId>com.ironsoftware</groupId>
<artifactId>ironpdf</artifactId>
<version>20xx.xx.xxxx</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-simple</artifactId>
<version>2.0.3</version>
</dependency>
</dependencies><dependencies>
<dependency>
<groupId>com.ironsoftware</groupId>
<artifactId>ironpdf</artifactId>
<version>20xx.xx.xxxx</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-simple</artifactId>
<version>2.0.3</version>
</dependency>
</dependencies>Pobierz plik JAR
Alternatywnie można ręcznie pobrać plik JAR ze strony IronPDF Downloads na Sonatype.
Utwórz dokument PDF za pomocą IronPDF
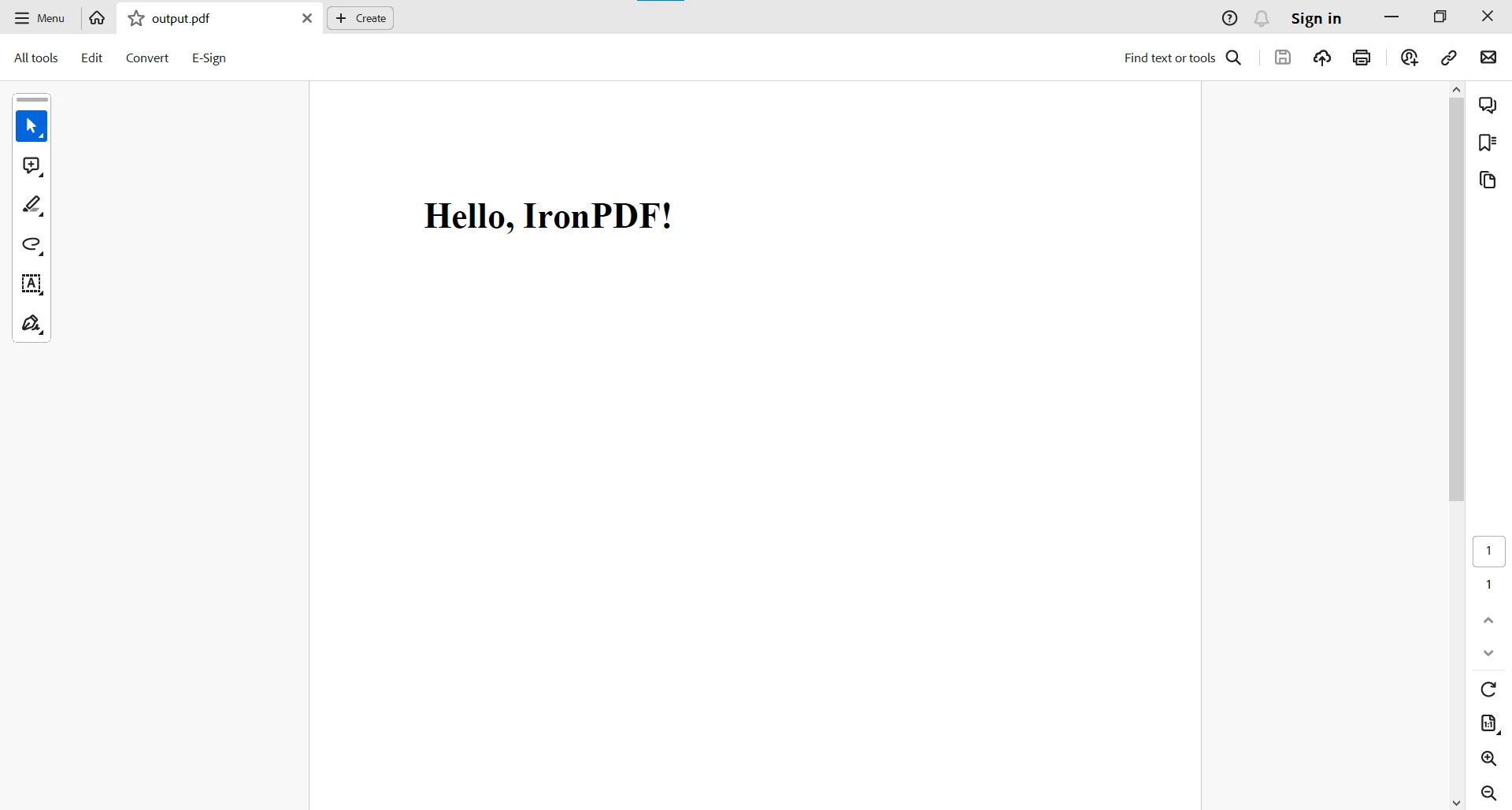
Oto prosty przykład pokazujący, jak używać IronPDF do generowania dokumentu PDF z ciągu znaków HTML w Javie:
import com.ironsoftware.ironpdf.*;
import java.io.IOException;
public class IronPDFExample {
public static void main(String[] args) {
// Create a PDF document from an HTML string
PdfDocument myPdf = PdfDocument.renderHtmlAsPdf("<h1>Hello, IronPDF!</h1>");
try {
// Save the PdfDocument to a file
myPdf.saveAs("output.pdf");
System.out.println("PDF created successfully.");
} catch (IOException e) {
System.err.println("Error saving PDF: " + e.getMessage());
}
}
}import com.ironsoftware.ironpdf.*;
import java.io.IOException;
public class IronPDFExample {
public static void main(String[] args) {
// Create a PDF document from an HTML string
PdfDocument myPdf = PdfDocument.renderHtmlAsPdf("<h1>Hello, IronPDF!</h1>");
try {
// Save the PdfDocument to a file
myPdf.saveAs("output.pdf");
System.out.println("PDF created successfully.");
} catch (IOException e) {
System.err.println("Error saving PDF: " + e.getMessage());
}
}
}Kod generuje plik PDF utworzony na podstawie ciągu znaków HTML. Wynik wskazuje na pomyślne utworzenie pliku PDF.
W przypadku bardziej złożonych zadań związanych z plikami PDF można zapoznać się z przykładami Java dla IronPDF.
Operacje na ciągach znaków i kompatybilność z IronPDF
Operacje na ciągach znaków, takie jak toLowerCase(), mają fundamentalne znaczenie dla wielu zadań programistycznych, umożliwiając programistom skuteczne manipulowanie tekstem i jego normalizację. Dobrą wiadomością jest to, że IronPDF płynnie integruje się ze standardowymi operacjami na ciągach znaków w Javie.
Oto krótki przykład wykorzystania funkcji toLowerCase() w połączeniu z IronPDF:
import com.ironsoftware.ironpdf.*;
public class IronPDFExample {
public static void main(String[] args) {
try {
// Create a PDF document from HTML
PdfDocument pdfDocument = PdfDocument.renderHtmlAsPdf("<h1>IronPDF Example</h1>");
// Extract text from the PDF and convert to lowercase
String extractedText = pdfDocument.extractAllText().toLowerCase();
// Create a new PDF with the lowercase text
PdfDocument pdf = PdfDocument.renderHtmlAsPdf(extractedText);
// Save the newly created PDF
pdf.saveAs("ironpdf_example.pdf");
System.out.println("PDF processed and saved with lowercase text.");
} catch (Exception e) {
System.err.println("An unexpected exception occurred: " + e.getMessage());
}
}
}import com.ironsoftware.ironpdf.*;
public class IronPDFExample {
public static void main(String[] args) {
try {
// Create a PDF document from HTML
PdfDocument pdfDocument = PdfDocument.renderHtmlAsPdf("<h1>IronPDF Example</h1>");
// Extract text from the PDF and convert to lowercase
String extractedText = pdfDocument.extractAllText().toLowerCase();
// Create a new PDF with the lowercase text
PdfDocument pdf = PdfDocument.renderHtmlAsPdf(extractedText);
// Save the newly created PDF
pdf.saveAs("ironpdf_example.pdf");
System.out.println("PDF processed and saved with lowercase text.");
} catch (Exception e) {
System.err.println("An unexpected exception occurred: " + e.getMessage());
}
}
}W tym przykładzie renderujemy HTML jako PDF przy użyciu IronPDF, wyodrębniamy tekst z pliku PDF, a następnie stosujemy funkcję toLowerCase(), aby znormalizować tekst. Następnie zapisujemy plik ponownie, używając małych liter. Kompatybilność wynika z faktu, że IronPDF obsługuje funkcje związane z plikami PDF, a standardowe operacje na ciągach znaków w Javie, w tym toLowerCase(), można płynnie zintegrować z przepływem pracy.
Wnioski
Metoda toLowerCase() w Javie zapewnia wszechstronne rozwiązanie do konwersji ciągów znaków, umożliwiając programistom usprawnienie różnych aspektów manipulacji ciągami znaków. Niezależnie od tego, czy chodzi o porównania bez uwzględniania wielkości liter, normalizację danych wejściowych, czy operacje wyszukiwania i filtrowania, opanowanie funkcji toLowerCase() zwiększa elastyczność i niezawodność aplikacji Java. Włączenie tej metody do swojego arsenału programistycznego pozwala tworzyć bardziej wydajne i przyjazne dla użytkownika oprogramowanie, zapewniając spójność w obsłudze ciągów znaków i poprawiając ogólne wrażenia użytkownika.
IronPDF for Java stanowi niezawodnego pomocnika dla programistów zmagających się z zadaniami związanymi z plikami PDF w swoich aplikacjach. Jak pokazano, kompatybilność IronPDF ze standardowymi operacjami na ciągach znaków w Javie, takimi jak toLowerCase(), umożliwia programistom stosowanie znanych technik podczas pracy z plikami PDF. Ta interoperacyjność gwarantuje, że programiści mogą w pełni wykorzystać możliwości manipulacji ciągami znaków w Javie w połączeniu z IronPDF, tworząc harmonijne środowisko do wydajnej i skutecznej obsługi plików PDF w aplikacjach Java.
Więcej informacji na temat pracy z plikami PDF można znaleźć w dokumentacji IronPDF.
IronPDF jest bezpłatny do celów programistycznych i wymaga licencji, aby umożliwić programistom przetestowanie pełnej funkcjonalności przed podjęciem świadomej decyzji. Pobierz bibliotekę z Get IronPDF for Java i wypróbuj ją.