JavaでtoLowerCaseを使用する方法
Javaプログラミングでは、文字列を操作することがさまざまなアプリケーションの基本的な側面です。 文字列を小文字や大文字などの一貫した形式に変換する能力は、多くの場合重要です。 JavaのtoLowerCase()メソッドは、この変換を簡単かつ効果的に実現する方法を提供します。
この記事では、toLowerCase()の構文、実際の用途、例を探求し、Java開発者が文字列クラスのコンバージョンを習得できるようにします。
toLowerCase()の構文の理解
JavaのStringクラスのtoLowerCaseメソッドは、文字のケースの区別を扱うための多用途なツールです。 すべての文字列や指定されたデフォルトのロケールで特定の文字に適用されるかに関わらず、このメソッドは大文字を管理する際の柔軟性と正確性を保証します。
toLowerCase()メソッドはjava.lang.Stringクラスの一部であり、すべて for Java文字列オブジェクトで容易に利用できます。 構文は簡単です:
public String toLowerCase() // Converts all characters to lowercasepublic String toLowerCase() // Converts all characters to lowercaseパラメータを取らず、メソッドはすべての文字を小文字に変換した新しい文字列を返します。 元の文字列を変更しません; 代わりに、小文字に変換した文字で新しい文字列を生成します。
toLowerCase()の実用的な応用
ケースインセンシティブな文字列比較
toLowerCase()の一般的な使い方の1つは、大文字と小文字を区別しない文字列比較です。 両方の文字列を小文字に変換することで、開発者は文字のケースの違いを気にせずに正確な比較を保証できます。
String str = "Hello";
String str2 = "hello";
if (str.toLowerCase().equals(str2.toLowerCase())) {
System.out.println("The strings are equal (case-insensitive).");
} else {
System.out.println("The strings are not equal.");
}String str = "Hello";
String str2 = "hello";
if (str.toLowerCase().equals(str2.toLowerCase())) {
System.out.println("The strings are equal (case-insensitive).");
} else {
System.out.println("The strings are not equal.");
}入力の正規化
ユーザー入力を処理する際に、ケースの正規化は一貫した処理を保証します。 たとえば、メールアドレスやユーザー名をバリデーションする際に、保存や比較の前にそれらを小文字に変換することで意図しない不一致を防ぐことができます。
String userInput = "UsErNaMe@eXample.com";
String normalizedInput = userInput.toLowerCase();
// Store or compare normalizedInputString userInput = "UsErNaMe@eXample.com";
String normalizedInput = userInput.toLowerCase();
// Store or compare normalizedInput検索とフィルタリング
toLowerCase()メソッドは、特に大文字と小文字の区別が重要でない場合、文字列を検索したりフィルタリングする際に価値があります。 たとえば、文字のケースによらずファイル名のリストをフィルタリングする場合:
import java.util.Arrays;
import java.util.List;
List<String> filenames = Arrays.asList("Document.txt", "Image.jpg", "Data.csv");
String searchTerm = "image";
for (String filename : filenames) {
if (filename.toLowerCase().contains(searchTerm.toLowerCase())) {
System.out.println("Found: " + filename);
}
}import java.util.Arrays;
import java.util.List;
List<String> filenames = Arrays.asList("Document.txt", "Image.jpg", "Data.csv");
String searchTerm = "image";
for (String filename : filenames) {
if (filename.toLowerCase().contains(searchTerm.toLowerCase())) {
System.out.println("Found: " + filename);
}
}toLowerCase()使用の例
例1:基本的な文字列変換
String originalString = "Hello World!";
String lowercaseString = originalString.toLowerCase();
System.out.println("Original: " + originalString);
System.out.println("Lowercase: " + lowercaseString);String originalString = "Hello World!";
String lowercaseString = originalString.toLowerCase();
System.out.println("Original: " + originalString);
System.out.println("Lowercase: " + lowercaseString);この例は単純に、文字列内のすべての大文字を小文字に変換します。
出力
Original: Hello World!
Lowercase: hello world!例2:ケースインセンシティブな比較
String input1 = "Java";
String input2 = "java";
if (input1.toLowerCase().equals(input2.toLowerCase())) {
System.out.println("The strings are equal (case-insensitive).");
} else {
System.out.println("The strings are not equal.");
}String input1 = "Java";
String input2 = "java";
if (input1.toLowerCase().equals(input2.toLowerCase())) {
System.out.println("The strings are equal (case-insensitive).");
} else {
System.out.println("The strings are not equal.");
}このメソッドは両方の文字列を小文字に変換してから比較し、元のケースに関係なくそれらが等しいことを示します。
出力
The strings are equal (case-insensitive).例3:ユーザー入力の正規化
String userInput = "UsErInPut";
String normalizedInput = userInput.toLowerCase();
System.out.println("Original Input: " + userInput);
System.out.println("Normalized Input: " + normalizedInput);String userInput = "UsErInPut";
String normalizedInput = userInput.toLowerCase();
System.out.println("Original Input: " + userInput);
System.out.println("Normalized Input: " + normalizedInput);この例は、小文字への変換がユーザー名やパスワードのように不一致なケースの問題にどのように対応できるかを示しています。
出力
Original Input: UsErInPut
Normalized Input: userinputIronPDFを活用したJava PDF処理の強化:文字列操作の利用
IronPDF for Javaの紹介
IronPDF for Javaを探るは、PDFドキュメントの作成、操作、管理を簡素化するために設計された強力なJavaライブラリです。 HTMLのPDFへのレンダリング、既存ファイルの変換、または高度なPDF操作を行う際、IronPDFはプロセスを効率化し、さまざまなドメインの開発者に利用可能にします。
IronPDFでは、テキスト抽出、画像埋め込み、精密なフォーマットなど、PDF関連の作業を強化するための多様な機能を開発者が活用できます。 さまざまな要件に対応する包括的なツールセットを提供し、PDF処理に関与するJavaアプリケーションにとって価値ある資産となっています。
IronPDFをJavaの依存関係として定義
IronPDFをJavaプロジェクトで使用し始めるには、プロジェクトの設定で依存関係として定義する必要があります。 以下のステップは、Mavenを使用してこれを行う方法を示しています。
pom.xml 依存関係
pom.xmlファイルに次の依存関係を追加してください:
<dependencies>
<dependency>
<groupId>com.ironsoftware</groupId>
<artifactId>ironpdf</artifactId>
<version>20xx.xx.xxxx</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-simple</artifactId>
<version>2.0.3</version>
</dependency>
</dependencies><dependencies>
<dependency>
<groupId>com.ironsoftware</groupId>
<artifactId>ironpdf</artifactId>
<version>20xx.xx.xxxx</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-simple</artifactId>
<version>2.0.3</version>
</dependency>
</dependencies>JARファイルのダウンロード
または、SonatypeのIronPDFダウンロードからJARファイルを手動でダウンロードできます。
IronPDFを使用したPDFドキュメントの作成
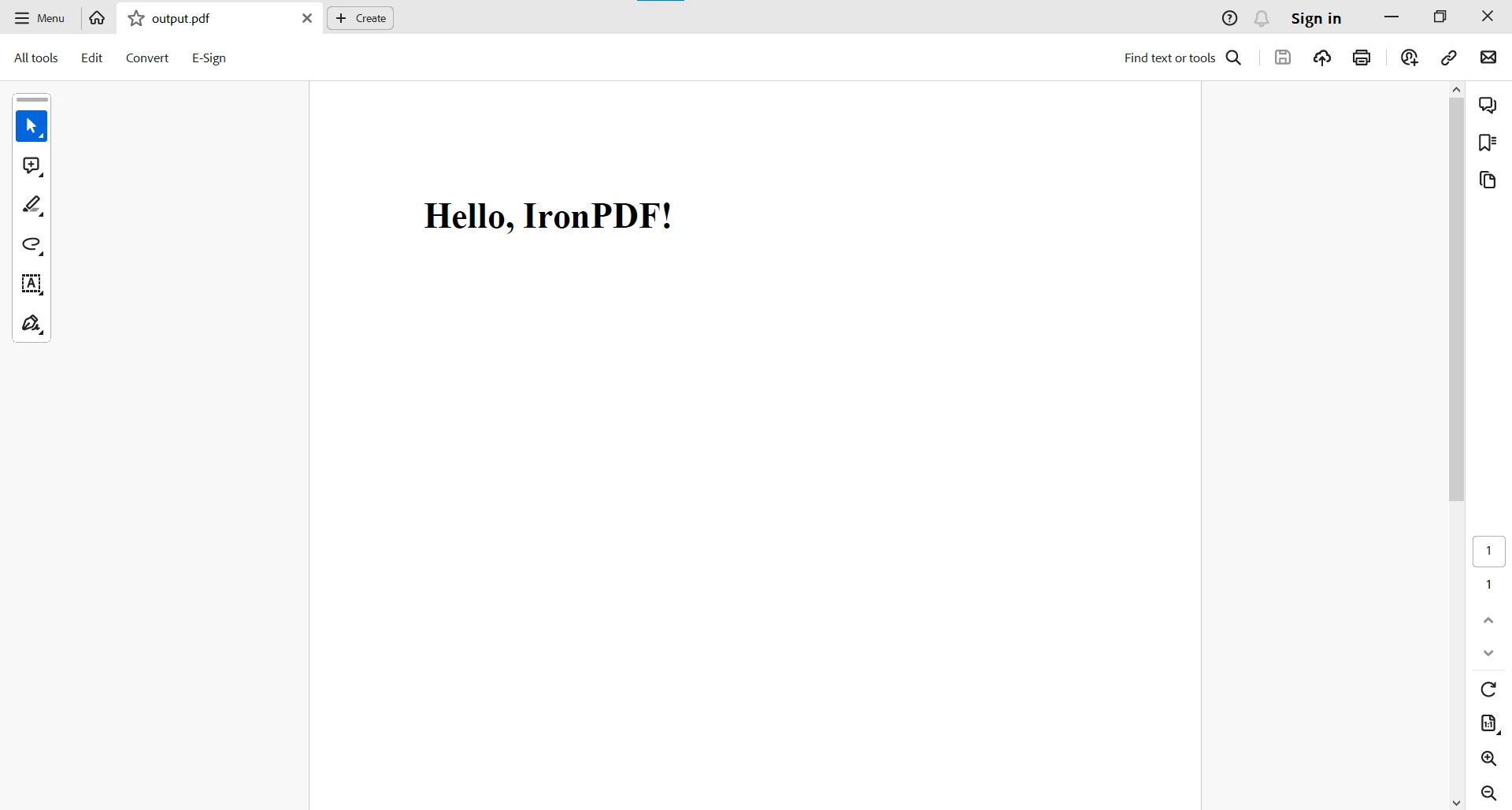
ここでは、JavaでHTML文字列からPDFドキュメントを生成するためにIronPDFを使用する方法を示す簡単な例です:
import com.ironsoftware.ironpdf.*;
import java.io.IOException;
public class IronPDFExample {
public static void main(String[] args) {
// Create a PDF document from an HTML string
PdfDocument myPdf = PdfDocument.renderHtmlAsPdf("<h1>Hello, IronPDF!</h1>");
try {
// Save the PdfDocument to a file
myPdf.saveAs("output.pdf");
System.out.println("PDF created successfully.");
} catch (IOException e) {
System.err.println("Error saving PDF: " + e.getMessage());
}
}
}import com.ironsoftware.ironpdf.*;
import java.io.IOException;
public class IronPDFExample {
public static void main(String[] args) {
// Create a PDF document from an HTML string
PdfDocument myPdf = PdfDocument.renderHtmlAsPdf("<h1>Hello, IronPDF!</h1>");
try {
// Save the PdfDocument to a file
myPdf.saveAs("output.pdf");
System.out.println("PDF created successfully.");
} catch (IOException e) {
System.err.println("Error saving PDF: " + e.getMessage());
}
}
}コードはHTML文字列から生成されたPDFを示しています。 出力はPDFの成功した作成を示しています。
より複雑なPDF作業には、これらのIronPDF for Java例を参照してください。
文字列操作とIronPDFの互換性
toLowerCase()などの文字列操作は多くのプログラミング タスクの基礎となり、開発者がテキストを効果的に操作および正規化できるようにします。 良いニュースは、IronPDFが標準 for Java文字列操作とシームレスに統合されていることです。
以下は、 toLowerCase() をIronPDFと組み合わせて使用する方法の簡単な例です。
import com.ironsoftware.ironpdf.*;
public class IronPDFExample {
public static void main(String[] args) {
try {
// Create a PDF document from HTML
PdfDocument pdfDocument = PdfDocument.renderHtmlAsPdf("<h1>IronPDF Example</h1>");
// Extract text from the PDF and convert to lowercase
String extractedText = pdfDocument.extractAllText().toLowerCase();
// Create a new PDF with the lowercase text
PdfDocument pdf = PdfDocument.renderHtmlAsPdf(extractedText);
// Save the newly created PDF
pdf.saveAs("ironpdf_example.pdf");
System.out.println("PDF processed and saved with lowercase text.");
} catch (Exception e) {
System.err.println("An unexpected exception occurred: " + e.getMessage());
}
}
}import com.ironsoftware.ironpdf.*;
public class IronPDFExample {
public static void main(String[] args) {
try {
// Create a PDF document from HTML
PdfDocument pdfDocument = PdfDocument.renderHtmlAsPdf("<h1>IronPDF Example</h1>");
// Extract text from the PDF and convert to lowercase
String extractedText = pdfDocument.extractAllText().toLowerCase();
// Create a new PDF with the lowercase text
PdfDocument pdf = PdfDocument.renderHtmlAsPdf(extractedText);
// Save the newly created PDF
pdf.saveAs("ironpdf_example.pdf");
System.out.println("PDF processed and saved with lowercase text.");
} catch (Exception e) {
System.err.println("An unexpected exception occurred: " + e.getMessage());
}
}
}この例では、 IronPDFを使用して HTML を PDF としてレンダリングし、PDF からテキストを抽出し、 toLowerCase()を適用してテキストを正規化します。 その後、小文字の文字を使ってファイルをもう一度保存します。 互換性があるのは、 IronPDF がPDF 関連の機能を操作し、 toLowerCase()を含む標準の Java 文字列操作をワークフローにシームレスに統合できるからです。
結論
Java のtoLowerCase()メソッドは、文字列変換のための多目的ソリューションを提供し、開発者が文字列操作のさまざまな側面を効率化できるようにします。 大文字と小文字を区別しない比較、入力の正規化、検索およびフィルタリング操作のいずれの場合でも、 toLowerCase()を習得すると、Java アプリケーションの柔軟性と堅牢性が向上します。 このメソッドをコーディングの兵器庫に取り入れることで、より効率的でユーザーフレンドリーなソフトウェアを作成でき、文字列管理の一貫性を保証し、ユーザーエクスペリエンス全体の向上を図れます。
IronPDF for Javaは、アプリケーションでPDF関連のタスクに取り組む開発者にとって信頼できるパートナーです。 示されているように、 IronPDFはtoLowerCase()などの標準の Java 文字列操作と互換性があるため、開発者は PDF を処理する際に使い慣れた手法を適用できます。 この相互運用性により、Javaの文字列操作能力をIronPDFとタンドゥムでフルに活用でき、Javaアプリケーションでの効率的かつ効果的なPDF処理のための調和のとれた環境が作り出されます。
PDF関連の作業に関する詳細情報は、IronPDF ドキュメントをご覧ください。
IronPDFは開発目的で無料であり、その完全な機能をテストして、十分な判断を下す前に開発者を支援するためにライセンスを取得する必要があります。 ライブラリをGet IronPDF for Javaからダウンロードしてお試しください。