
Jak odczytać plik PDF w Javie
W tym artykule pokażemy, jak odczytywać pliki PDF w Javie przy użyciu biblioteki PDF w przykładowym projekcie Java o nazwie "IronPDF Java Library Overview", aby odczytywać tekst i obiekty typu metadanych w plikach PDF oraz tworzyć zaszyfrowane dokumenty.
Kroki, aby odczytać plik PDF w Javie
- Zainstaluj bibliotekę PDF, aby odczytywać pliki PDF przy użyciu języka Java.
- Zaimportuj zależności, aby użyć dokumentu PDF w projekcie.
- Załaduj istniejący plik PDF, korzystając z [metody
PdfDocument.fromFile](/java/object-reference/api/com/ironsoftware/ironpdf/PdfDocument.html#fromFile(java.nio.file.Path) (dokumentacja metody. - Wyodrębnij tekst z pliku PDF, korzystając z [metody wyodrębniania tekstu z plików PDF](/java/object-reference/api/com/ironsoftware/ironpdf/PdfDocument.html#extractAllText() ([wyjaśnienie](/java/object-reference/api/com/ironsoftware/ironpdf/PdfDocument.html#extractAllText()).
- Utwórz obiekt metadanych, korzystając z metody opisanej [w samouczku](/java/object-reference/api/com/ironsoftware/ironpdf/PdfDocument.html#getMetadata() dotyczącym [pobierania metadanych z plików PDF](/java/object-reference/api/com/ironsoftware/ironpdf/PdfDocument.html#getMetadata().
- Odczytaj autora z metadanych, korzystając z metody opisanej [w przewodniku "Pobieranie autora z metadanych](/java/object-reference/api/com/ironsoftware/ironpdf/metadata/MetadataManager.html#getAuthor()".
Przedstawiamy IronPDF for Java jako bibliotekę do odczytu plików PDF
Aby usprawnić proces odczytu plików PDF w Javie, programiści często korzystają z bibliotek innych firm, które zapewniają kompleksowe i wydajne rozwiązania. Jedną z takich wyróżniających się bibliotek jest IronPDF for Java.
IronPDF został zaprojektowany z myślą o programistach, oferując proste API, które eliminuje złożoność związaną z manipulowaniem stronami PDF. Dzięki IronPDF programiści Java mogą płynnie zintegrować funkcje odczytu plików PDF ze swoimi projektami, skracając czas i wysiłek związany z programowaniem. Biblioteka ta obsługuje szeroki zakres funkcji związanych z plikami PDF, co czyni ją wszechstronnym wyborem do różnych zastosowań.
Główne funkcje obejmują możliwość tworzenia plików PDF z różnych formatów, w tym dokumentów HTML, JavaScript, CSS, XML oraz różnych formatów obrazów. Ponadto IronPDF oferuje możliwość dodawania nagłówków i stopek do plików PDF, tworzenia tabel w dokumentach PDF i wiele więcej.
Instalacja IronPDF for Java
Aby skonfigurować IronPDF, upewnij się, że masz niezawodny kompilator Java. W tym artykule zaleca się korzystanie z IntelliJ IDEA.
- Uruchom IntelliJ IDEA i załóż nowy projekt Maven.
-
Po utworzeniu projektu otwórz plik
pom.xml. Dodaj następujące zależności Maven, aby zintegrować IronPDF:<dependency> <groupId>com.ironsoftware</groupId> <artifactId>ironpdf</artifactId> <version>YOUR_VERSION_HERE</version> </dependency><dependency> <groupId>com.ironsoftware</groupId> <artifactId>ironpdf</artifactId> <version>YOUR_VERSION_HERE</version> </dependency>XML - Po dodaniu tych zależności kliknij mały przycisk, który pojawi się po prawej stronie ekranu, aby je zainstalować.
Odczytywanie plików PDF w Javie – przykład kodu
Przyjrzyjmy się prostemu przykładowi kodu Java, który pokazuje, jak używać IronPDF do odczytu zawartości pliku PDF. W tym przykładzie skupimy się na metodzie wyodrębniania tekstu z dokumentu PDF.
// Importing necessary classes from IronPDF and Java libraries
import com.ironsoftware.ironpdf.*;
import java.io.IOException;
import java.nio.file.Paths;
// Class definition
class Test {
public static void main(String[] args) throws IOException {
// Setting the license key for IronPDF (replace "License-Key" with a valid key)
License.setLicenseKey("License-Key");
// Loading a PDF document from the file "html_file_saved.pdf"
PdfDocument pdf = PdfDocument.fromFile(Paths.get("html_file_saved.pdf"));
// Extracting all text content from the PDF document
String text = pdf.extractAllText();
// Printing the extracted text to the console
System.out.println(text);
}
}// Importing necessary classes from IronPDF and Java libraries
import com.ironsoftware.ironpdf.*;
import java.io.IOException;
import java.nio.file.Paths;
// Class definition
class Test {
public static void main(String[] args) throws IOException {
// Setting the license key for IronPDF (replace "License-Key" with a valid key)
License.setLicenseKey("License-Key");
// Loading a PDF document from the file "html_file_saved.pdf"
PdfDocument pdf = PdfDocument.fromFile(Paths.get("html_file_saved.pdf"));
// Extracting all text content from the PDF document
String text = pdf.extractAllText();
// Printing the extracted text to the console
System.out.println(text);
}
}Ten kod Java wykorzystuje bibliotekę IronPDF do wyodrębniania tekstu z określonego pliku PDF. Zaimportuje bibliotekę Java, a także ustawi klucz licencyjny, który jest warunkiem koniecznym do korzystania z biblioteki. Następnie kod ładuje dokument PDF z pliku "html_file_saved.pdf" i wyodrębnia całą jego zawartość tekstową z pliku jako wewnętrzny bufor ciągów znaków. Wyodrębniony tekst jest przechowywany w zmiennej, a następnie wyświetlany w konsoli.
Obraz wyjścia konsoli
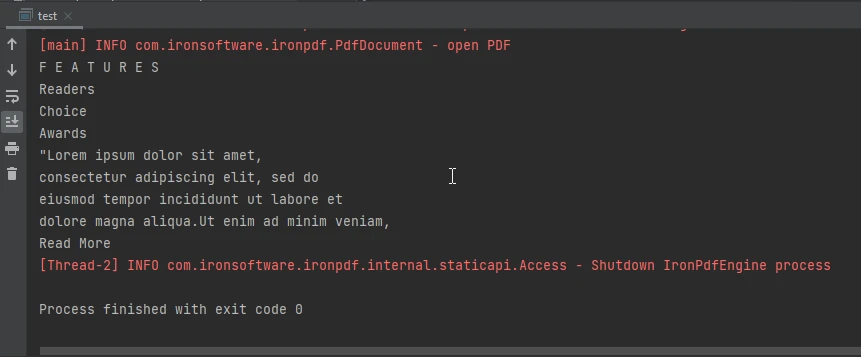 Wynik wyświetlany w konsoli
Wynik wyświetlany w konsoli
Przykład kodu Java do odczytu metadanych pliku PDF
Rozszerzając swoje możliwości poza wyodrębnianie tekstu, IronPDF rozszerza obsługę o wyodrębnianie metadanych z plików PDF. Aby zilustrować tę funkcjonalność, przyjrzyjmy się przykładowi kodu w języku Java, który pokazuje proces pobierania metadanych z dokumentu PDF.
// Importing necessary classes from IronPDF and Java libraries
import com.ironsoftware.ironpdf.*;
import com.ironsoftware.ironpdf.metadata.MetadataManager;
import java.io.IOException;
import java.nio.file.Paths;
// Class definition
class Test {
public static void main(String[] args) throws IOException {
// Setting the license key for IronPDF (replace "License-Key" with a valid key)
License.setLicenseKey("License-Key");
// Loading a PDF document from the file "html_file_saved.pdf"
PdfDocument document = PdfDocument.fromFile(Paths.get("html_file_saved.pdf"));
// Creating a MetadataManager object to access document metadata
MetadataManager metadata = document.getMetadata();
// Extracting the author information from the document metadata
String author = metadata.getAuthor();
// Printing the extracted author information to the console
System.out.println(author);
}
}// Importing necessary classes from IronPDF and Java libraries
import com.ironsoftware.ironpdf.*;
import com.ironsoftware.ironpdf.metadata.MetadataManager;
import java.io.IOException;
import java.nio.file.Paths;
// Class definition
class Test {
public static void main(String[] args) throws IOException {
// Setting the license key for IronPDF (replace "License-Key" with a valid key)
License.setLicenseKey("License-Key");
// Loading a PDF document from the file "html_file_saved.pdf"
PdfDocument document = PdfDocument.fromFile(Paths.get("html_file_saved.pdf"));
// Creating a MetadataManager object to access document metadata
MetadataManager metadata = document.getMetadata();
// Extracting the author information from the document metadata
String author = metadata.getAuthor();
// Printing the extracted author information to the console
System.out.println(author);
}
}Ten kod Java wykorzystuje bibliotekę IronPDF do wyodrębniania metadanych, a konkretnie informacji o autorze, z dokumentu PDF. Zaczyna się od załadowania dokumentu PDF z pliku "html_file_saved.pdf". Kod pobiera metadane dokumentu, korzystając z dokumentacji klasy MetadataManager, a konkretnie pobiera informacje o autorze. Wyodrębnione dane autora są zapisywane w zmiennej i wyświetlane w konsoli za pomocą komendy PRINT.
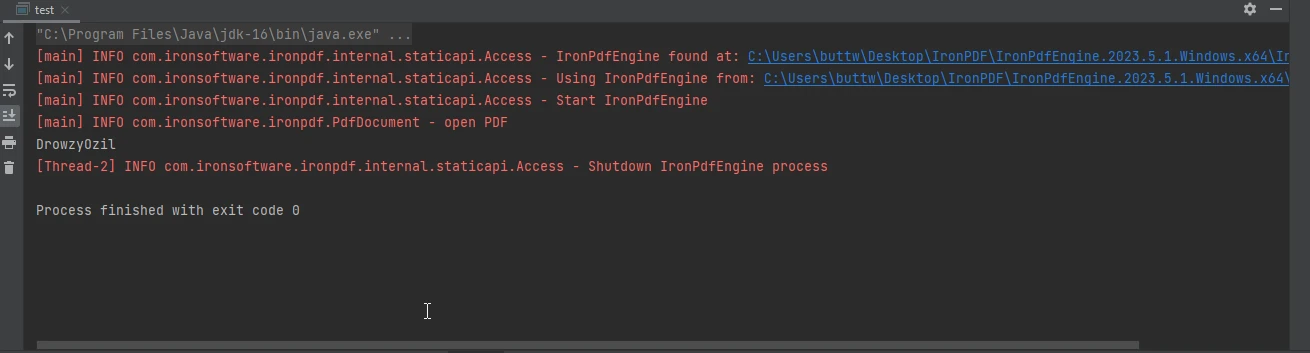 Wynik wyświetlany w konsoli
Wynik wyświetlany w konsoli
Wnioski
Podsumowując, odczytywanie istniejących dokumentów PDF w programie Java to cenna umiejętność, która otwiera przed programistami szerokie możliwości. Niezależnie od tego, czy chodzi o wyodrębnianie tekstu, obrazów czy innych danych, możliwość programowego przetwarzania plików PDF jest kluczowym aspektem wielu aplikacji. IronPDF for Java stanowi solidne i wydajne rozwiązanie dla programistów pragnących zintegrować funkcje odczytu plików PDF ze swoimi projektami Java.
Postępując zgodnie z instrukcjami instalacji i zapoznając się z dostarczonymi przykładami kodu, programiści mogą szybko wykorzystać możliwości IronPDF do tworzenia nowych plików i łatwego wykonywania zadań związanych z plikami PDF. Oprócz tego można również zgłębiać jego możliwości w zakresie tworzenia zaszyfrowanych dokumentów.
Portal produktów IronPDF oferuje szerokie wsparcie dla programistów. Aby dowiedzieć się więcej o tym, jak działa IronPDF for Java, odwiedź te obszerne strony dokumentacji. Ponadto firma IronPDF udostępnia stronę z ofertą bezpłatnej licencji probnej, która stanowi doskonałą okazję do zapoznania się z IronPDF i jego funkcjami.
Często Zadawane Pytania
Jak odczytać tekst z pliku PDF w Javie?
Można odczytać tekst z pliku PDF w Javie przy użyciu IronPDF, ładując plik PDF za pomocą metody PdfDocument.fromFile, a następnie wyodrębniając tekst za pomocą metody extractAllText.
Jak wyodrębnić metadane z pliku PDF w Javie?
Aby wyodrębnić metadane z pliku PDF w Javie przy użyciu IronPDF, należy załadować dokument PDF i użyć metody getMetadata. Pozwala to na pobranie informacji, takich jak nazwisko autora i inne właściwości metadanych.
Jakie kroki należy wykonać, aby zainstalować bibliotekę PDF w projekcie Java?
Aby zainstalować IronPDF w projekcie Java, utwórz projekt Maven w IntelliJ IDEA i dodaj IronPDF jako zależność w pliku pom.xml. Następnie zainstaluj zależności, korzystając z opcji dostępnych w IntelliJ.
Czy w Javie można tworzyć zaszyfrowane dokumenty PDF?
Chociaż niniejszy artykuł skupia się na odczytywaniu plików PDF, IronPDF obsługuje również tworzenie zaszyfrowanych dokumentów PDF. Szczegółowe instrukcje można znaleźć w dokumentacji IronPDF.
Jaki jest cel ustawienia klucza licencyjnego dla biblioteki Java PDF?
Aby uzyskać dostęp do wszystkich funkcji biblioteki, konieczne jest ustawienie klucza licencyjnego w IronPDF. Ustawia się go w kodzie Java za pomocą metody License.setLicenseKey, aby usunąć ograniczenia wersji próbnej.
Jakie funkcje oferuje biblioteka Java do obsługi plików PDF?
IronPDF oferuje takie funkcje, jak tworzenie plików PDF z HTML i obrazów, dodawanie nagłówków i stopek, tworzenie tabel oraz wyodrębnianie tekstu i metadanych z plików PDF.
Jak mogę rozwiązać typowe problemy z odczytywaniem plików PDF w Javie?
Upewnij się, że zależności Maven są poprawnie skonfigurowane w pliku pom.xml oraz że biblioteka IronPDF jest prawidłowo zainstalowana. Szczegółowe instrukcje dotyczące rozwiązywania problemów znajdziesz w dokumentacji IronPDF.
Gdzie mogę dowiedzieć się więcej o korzystaniu z biblioteki PDF w Javie?
Aby uzyskać więcej informacji na temat IronPDF for Java, odwiedź portal produktu IronPDF i zapoznaj się z dokumentacją. Firma udostępnia również bezplatną licencję probną, umożliwiającą przetestowanie możliwości produktu.

















