
Biblioteka Python Requests (jak działa dla programistów)
Python jest powszechnie ceniony za swoją prostotę i czytelność, co sprawia, że jest popularnym wyborem wśród programistów do scrapingu stron internetowych i interakcji z interfejsami API. Jedną z kluczowych bibliotek umożliwiających takie interakcje jest biblioteka Python Requests. Requests to biblioteka żądań HTTP dla języka Python, która pozwala w prosty sposób wysyłać żądania HTTP. W tym artykule zagłębimy się w funkcje biblioteki Python Requests, omówimy jej zastosowanie na praktycznych przykładach oraz przedstawimy IronPDF, pokazując, jak można połączyć go z Requests w celu tworzenia i edycji plików PDF na podstawie danych internetowych.
Wprowadzenie do biblioteki Requests
Biblioteka Python Requests została stworzona w celu uproszczenia żądań HTTP i uczynienia ich bardziej przyjaznymi dla użytkownika. Upraszcza złożoność wysyłania żądań za pomocą prostego interfejsu API, dzięki czemu możesz skupić się na interakcji z usługami i danymi w sieci. Niezależnie od tego, czy chcesz pobierać strony internetowe, korzystać z interfejsów API REST, wyłączyć weryfikację certyfikatów SSL czy wysyłać dane na serwer, biblioteka Requests spełni Twoje oczekiwania.
Najważniejsze cechy
- Prostota: Łatwa w użyciu i zrozumiała składnia.
- Metody HTTP: Obsługuje wszystkie metody HTTP — GET, POST, PUT, DELETE itp.
- Obiekty sesji: Utrzymują pliki cookie między żądaniami.
- Uwierzytelnianie: Upraszcza dodawanie nagłówków uwierzytelniających.
- Serwery proxy: Obsługa serwerów proxy HTTP.
- Limity czasu: Skutecznie zarządza limitami czasu żądań.
- Weryfikacja SSL: domyślnie weryfikuje certyfikaty SSL.
Instalacja Requests
Aby rozpocząć korzystanie z Requests, należy je zainstalować. Można to zrobić za pomocą pip:
pip install requestspip install requestsPodstawowe zastosowanie
Oto prosty przykład wykorzystania Requests do pobrania strony internetowej:
import requests
# Send a GET request to the specified URL
response = requests.get('https://www.example.com')
# Print the status code of the response (e.g., 200 for success)
print(response.status_code)
# Print the HTML content of the page
print(response.text)import requests
# Send a GET request to the specified URL
response = requests.get('https://www.example.com')
# Print the status code of the response (e.g., 200 for success)
print(response.status_code)
# Print the HTML content of the page
print(response.text)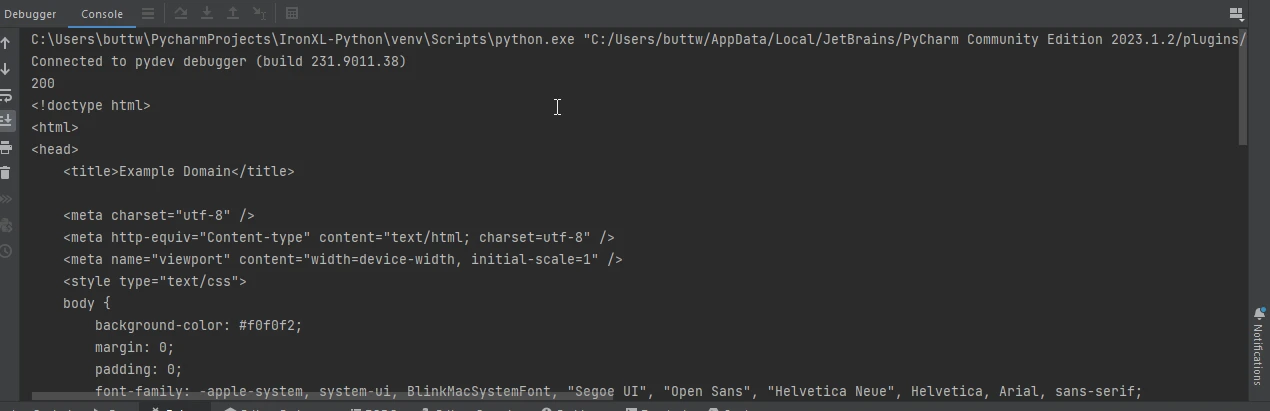
Przesyłanie parametrów w adresach URL
Często konieczne jest przekazanie parametrów do adresu URL. Moduł Python Requests ułatwia to dzięki słowu kluczowemu params:
import requests
# Define the parameters to be sent in the URL
params = {'key1': 'value1', 'key2': 'value2'}
# Send a GET request with parameters
response = requests.get('https://www.example.com', params=params)
# Print the full URL including the parameters
print(response.url)import requests
# Define the parameters to be sent in the URL
params = {'key1': 'value1', 'key2': 'value2'}
# Send a GET request with parameters
response = requests.get('https://www.example.com', params=params)
# Print the full URL including the parameters
print(response.url)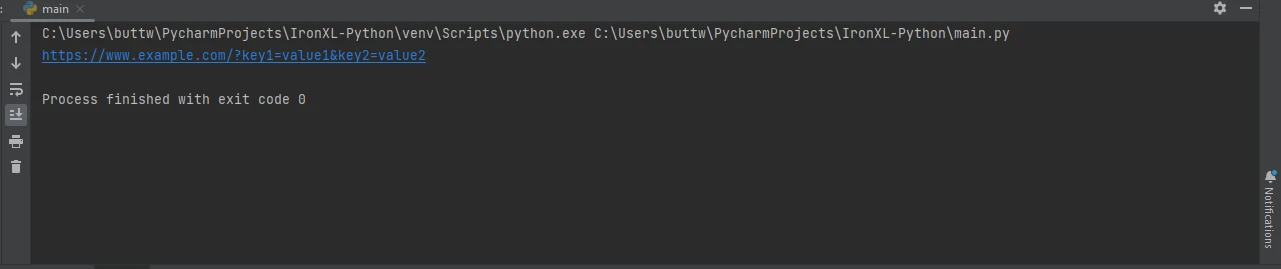
Obsługa danych JSON
Interakcja z interfejsami API zazwyczaj wiąże się z danymi JSON. Requests upraszcza to dzięki wbudowanej obsłudze JSON:
import requests
# Send a GET request to retrieve JSON data
response = requests.get('https://jsonplaceholder.typicode.com/todos/1')
# Convert the JSON response to a Python dictionary
data = response.json()
# Print the JSON data
print(data)import requests
# Send a GET request to retrieve JSON data
response = requests.get('https://jsonplaceholder.typicode.com/todos/1')
# Convert the JSON response to a Python dictionary
data = response.json()
# Print the JSON data
print(data)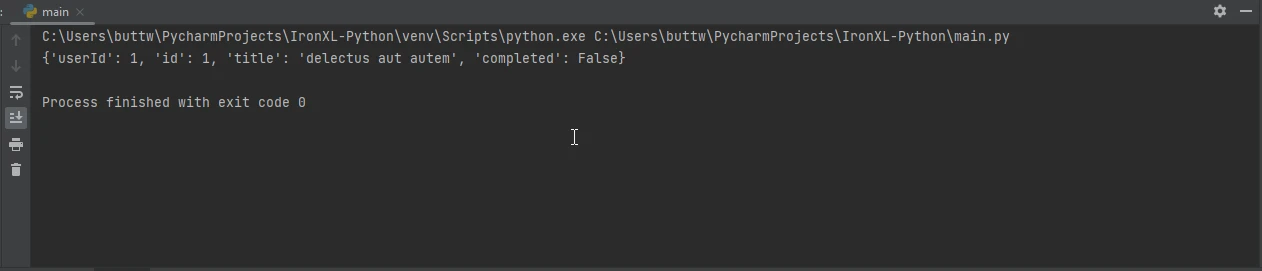
Praca z nagłówkami
Nagłówki mają kluczowe znaczenie dla żądań HTTP. Możesz dodawać własne nagłówki do swoich żądań w następujący sposób:
import requests
# Define custom headers
headers = {'User-Agent': 'my-app/0.0.1'}
# Send a GET request with custom headers
response = requests.get('https://www.example.com', headers=headers)
# Print the response text
print(response.text)import requests
# Define custom headers
headers = {'User-Agent': 'my-app/0.0.1'}
# Send a GET request with custom headers
response = requests.get('https://www.example.com', headers=headers)
# Print the response text
print(response.text)
Przesyłanie plików
Requests obsługuje również przesyłanie plików. Oto jak można przesłać plik:
import requests
# Define the files to be uploaded
files = {'file': open('report.txt', 'rb')}
# Send a POST request with the file
response = requests.post('https://www.example.com/upload', files=files)
# Print the status code of the response
print(response.status_code)import requests
# Define the files to be uploaded
files = {'file': open('report.txt', 'rb')}
# Send a POST request with the file
response = requests.post('https://www.example.com/upload', files=files)
# Print the status code of the response
print(response.status_code)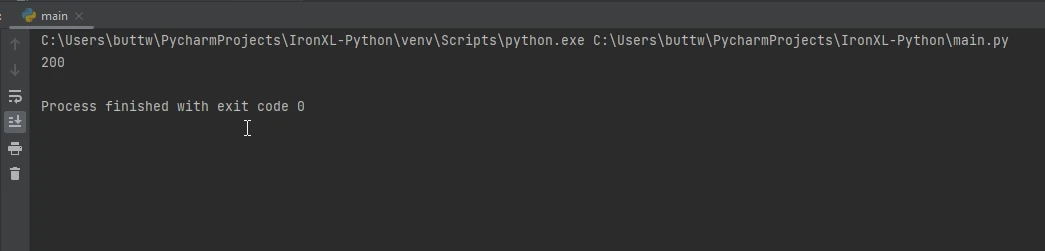
Przedstawiamy IronPDF for Python
IronPDF to wszechstronna biblioteka do generowania plików PDF, którą można wykorzystać do tworzenia, edytowania i manipulowania plikami PDF w aplikacjach napisanych w języku Python. Jest to szczególnie przydatne, gdy trzeba wygenerować pliki PDF z treści HTML, co czyni to narzędzie doskonałym rozwiązaniem do tworzenia raportów, faktur lub wszelkiego rodzaju dokumentów, które muszą być dystrybuowane w formacie przenośnym.
Instalacja IronPDF
Aby zainstalować IronPDF, użyj pip:
pip install ironpdf
Korzystanie z IronPDF z Requests
Połączenie Requests i IronPDF pozwala pobierać dane z sieci i bezpośrednio konwertować je na dokumenty PDF. Może to być szczególnie przydatne przy tworzeniu raportów na podstawie danych internetowych lub zapisywaniu stron internetowych w formacie PDF.
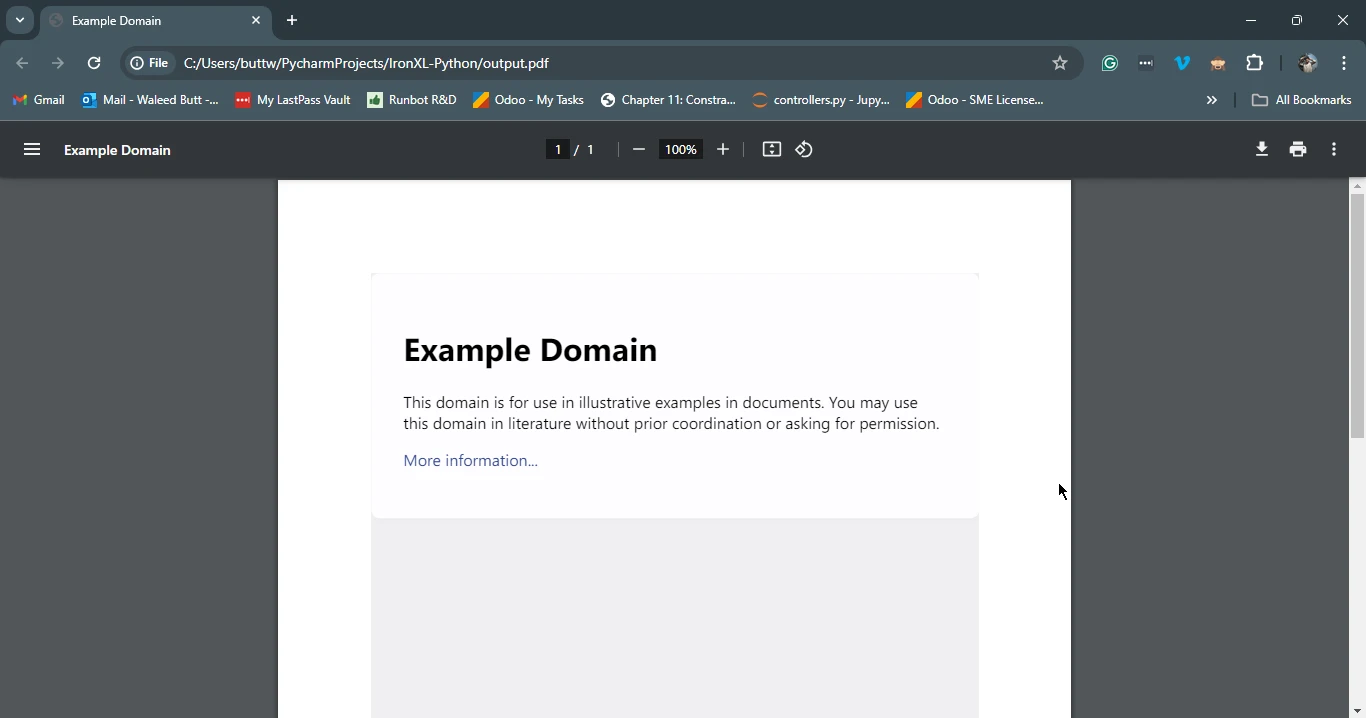
Oto przykład wykorzystania Requests do pobrania strony internetowej, a następnie użycia IronPDF do zapisania jej w formacie PDF:
import requests
from ironpdf import ChromePdfRenderer
# Fetch a web page
url = 'https://www.example.com'
response = requests.get(url)
if response.status_code == 200:
# Extract the HTML content from the response
html_content = response.text
# Initialize the PDF renderer
renderer = ChromePdfRenderer()
# Render the HTML content as a PDF
pdf = renderer.RenderHtmlAsPdf(html_content)
# Save the generated PDF to a file
pdf.save('output.pdf')
print('PDF created successfully')
else:
# Print an error message if the request was not successful
print(f'Failed to retrieve the webpage. Status code: {response.status_code}')import requests
from ironpdf import ChromePdfRenderer
# Fetch a web page
url = 'https://www.example.com'
response = requests.get(url)
if response.status_code == 200:
# Extract the HTML content from the response
html_content = response.text
# Initialize the PDF renderer
renderer = ChromePdfRenderer()
# Render the HTML content as a PDF
pdf = renderer.RenderHtmlAsPdf(html_content)
# Save the generated PDF to a file
pdf.save('output.pdf')
print('PDF created successfully')
else:
# Print an error message if the request was not successful
print(f'Failed to retrieve the webpage. Status code: {response.status_code}')Skrypt ten najpierw pobiera zawartość HTML z podanego adresu URL za pomocą Requests. Następnie wykorzystuje IronPDF do konwersji zawartości HTML tego obiektu odpowiedzi do formatu PDF i zapisuje wynikowy plik PDF.
Wnioski
Biblioteka Requests jest niezbędnym narzędziem dla każdego programisty Pythona, który musi współpracować z internetowymi interfejsami API. Jej prostota i łatwość użytkowania sprawiają, że jest to najlepszy wybór do wysyłania żądań HTTP. W połączeniu z IronPDF otwiera to jeszcze więcej możliwości, pozwalając na pobieranie danych z sieci i konwertowanie ich na profesjonalnej jakości dokumenty PDF. Niezależnie od tego, czy tworzysz raporty, faktury, czy archiwizujesz treści internetowe, połączenie Requests i IronPDF zapewnia potężne rozwiązanie dla Twoich potrzeb w zakresie generowania plików PDF.
Więcej informacji na temat licencji IronPDF można znaleźć na stronie licencji IronPDF. Możesz również zapoznać się z naszym szczegółowym samouczkiem na temat konwersji HTML do PDF, aby uzyskać więcej informacji.
















