
Jak wyodrębnić konkretny tekst z PDF w Python
W tym artykule pokażemy, jak wyodrębnić elementy tekstowe z dokumentów PDF za pomocą biblioteki IronPDF for Python.
IronPDF
Python to język programowania, który pozwala programistom w prosty i szybki sposób tworzyć graficzne interfejsy użytkownika. W porównaniu z innymi językami Python jest również znacznie bardziej dynamiczny dla programistów. Dzięki temu dodanie biblioteki IronPDF do Pythona jest prostym procesem. Wiele preinstalowanych narzędzi, w tym PyQt, wxWidgets, Kivy oraz wiele dodatkowych pakietów i bibliotek Pythona, może służyć do szybkiego i bezpiecznego tworzenia kompletnego interfejsu graficznego. IronPDF obsługuje język Python, a także umożliwia integrację funkcji z innych frameworków, takich jak .NET Core.
IronPDF ułatwia tworzenie stron internetowych. Głównym powodem jest powszechne stosowanie paradygmatów tworzenia stron internetowych w języku Python, takich jak Django, Flask i Pyramid. Reddit, Mozilla i Spotify to tylko niektóre ze stron internetowych i usług online, które korzystają z tych frameworków.
Funkcje IronPDF
- Dzięki IronPDF pliki PDF można tworzyć z różnych źródeł, w tym HTML, HTML5, ASPX oraz Razor/MVC View. Oferuje możliwość konwersji stron HTML i obrazów do plików PDF.
- Tworzenie interaktywnych plików PDF, wypełnianie i przesyłanie interaktywnych formularzy, dzielenie i łączenie plików PDF, wyodrębnianie tekstu i obrazów, wyszukiwanie tekstu w plikach PDF, rasteryzacja plików PDF do obrazów, zmiana rozmiarów czcionek, przetwarzanie języka naturalnego przy użyciu ChatGPT oraz konwersja stron PDF to tylko niektóre z czynności, w których może pomóc zestaw narzędzi IronPDF.
- IronPDF oferuje walidację formularzy logowania HTML z obsługą agentów użytkownika, serwerów proxy, plików cookie, nagłówków HTTP i zmiennych formularza.
- IronPDF wykorzystuje nazwy użytkowników i hasła, aby zapewnić użytkownikom dostęp do chronionych dokumentów.
- Za pomocą zaledwie kilku wierszy kodu IronPDF może wydrukować plik PDF z różnych źródeł, w tym ciągu znaków, strumienia lub adresu URL.
Konfiguracja Python
Konfiguracja środowiska
Upewnij się, że na Twoim komputerze jest zainstalowany Python. Aby pobrać i zainstalować najnowszą wersję języka Python zgodną z Twoim systemem operacyjnym, przejdź na oficjalną stronę internetową języka Python. Po zainstalowaniu języka Python utwórz środowisko wirtualne, aby oddzielić potrzeby związane z Twoim projektem. Twórz i zarządzaj środowiskami wirtualnymi za pomocą modułu venv, aby zapewnić swojemu projektowi konwersji uporządkowane, oddzielne miejsce pracy.
Nowa inicjatywa w PyCharm
W tym przykładzie jako środowisko IDE do tworzenia kodu w języku Python zaleca się PyCharm.
Po uruchomieniu środowiska IDE PyCharm wybierz opcję "Nowy projekt".
 PyCharm
PyCharm
Po wybraniu opcji "Nowy projekt" otworzy się nowe okno, w którym można ustawić lokalizację i srodowisko projektu. Przykład można zobaczyć na poniższym obrazku.
 Nowy projekt
Nowy projekt
Po wybraniu lokalizacji projektu i ścieżki środowiska kliknij przycisk Utwórz, aby rozpocząć nowy projekt. Program można następnie uruchomić w nowym oknie, które otworzy się w wyniku tej operacji. W tej lekcji używany jest Python 3.9.
 Utwórz projekt w języku Python
Utwórz projekt w języku Python
Wymagania dotyczące biblioteki IronPDF
Biblioteka IronPDF dla języka Python w dużej mierze wykorzystuje platformę .NET 6.0. W związku z tym, aby korzystać z IronPDF for Python, na komputerze musi być zainstalowane środowisko uruchomieniowe .NET 6.0. Być może konieczne będzie zainstalowanie platformy .NET, zanim ten moduł Pythona będzie mógł być używany przez użytkowników systemów Linux i Mac. Odwiedź tę stronę pobierania firmy Microsoft, aby uzyskać potrzebne środowisko uruchomieniowe.
Konfiguracja biblioteki IronPDF
Aby generować, modyfikować i otwierać pliki z rozszerzeniem ".pdf", należy zainstalować pakiet "IronPDF". Otwórz okno terminala i wprowadź następujące polecenie, aby zainstalować pakiet w PyCharm:
pip install ironpdfpip install ironpdfInstalacja pakietu ironpdf została przedstawiona na poniższym zrzucie ekranu.
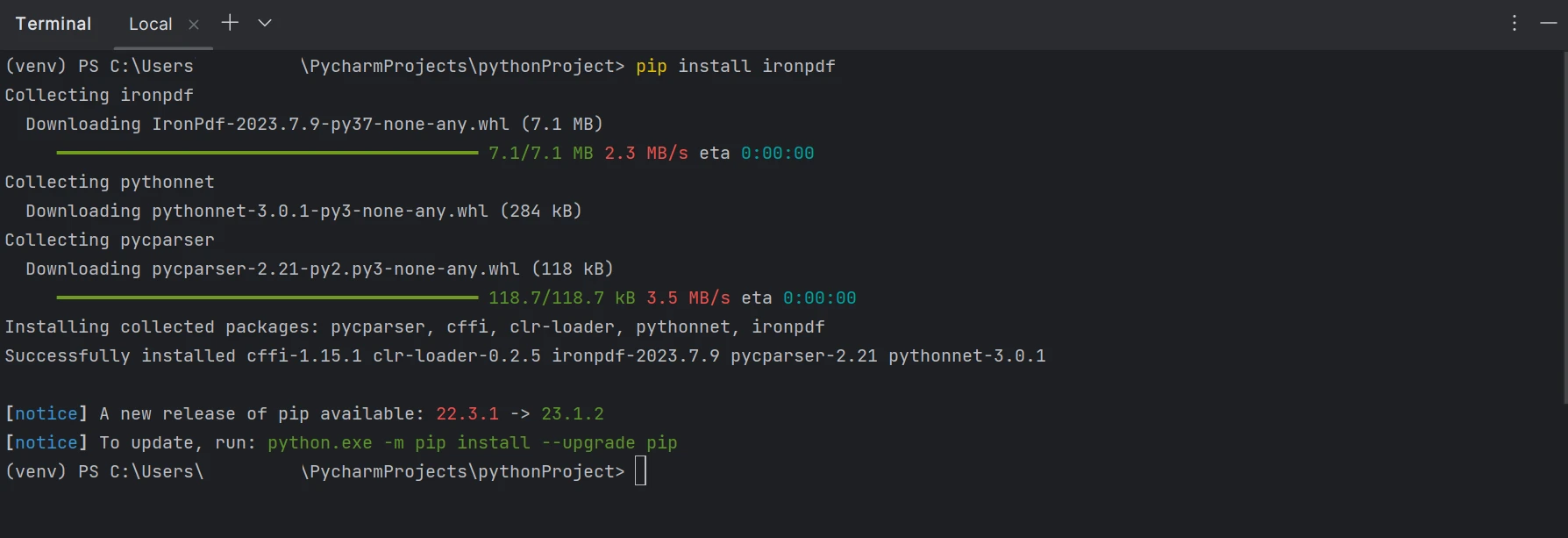 Zainstaluj IronPDF
Zainstaluj IronPDF
Wyodrębnianie określonych danych z pliku PDF
Za pomocą bibliotek IronPDF można wyodrębniać tekst z plików PDF. IronPDF oferuje wiele metod wyodrębniania tekstu. Pierwsza metoda polega na pobraniu całej zawartości strony jako pojedynczego ciągu znaków. Druga strategia polega na przeglądaniu treści strona po stronie, zaczynając od pierwszej strony. Istniejące pliki PDF można analizować za pomocą biblioteki IronPDF. Poniższy fragment kodu pokazuje, jak używać IronPDF do przeglądania plików PDF w czasie rzeczywistym.
Istnieją dwie opcje pobierania informacji z pliku PDF:
- Wyodrębnianie strona po stronie z pliku PDF
- Konwersja całego pliku PDF na tekst
Poniżej znajduje się przykładowy plik PDF do tego artykułu.
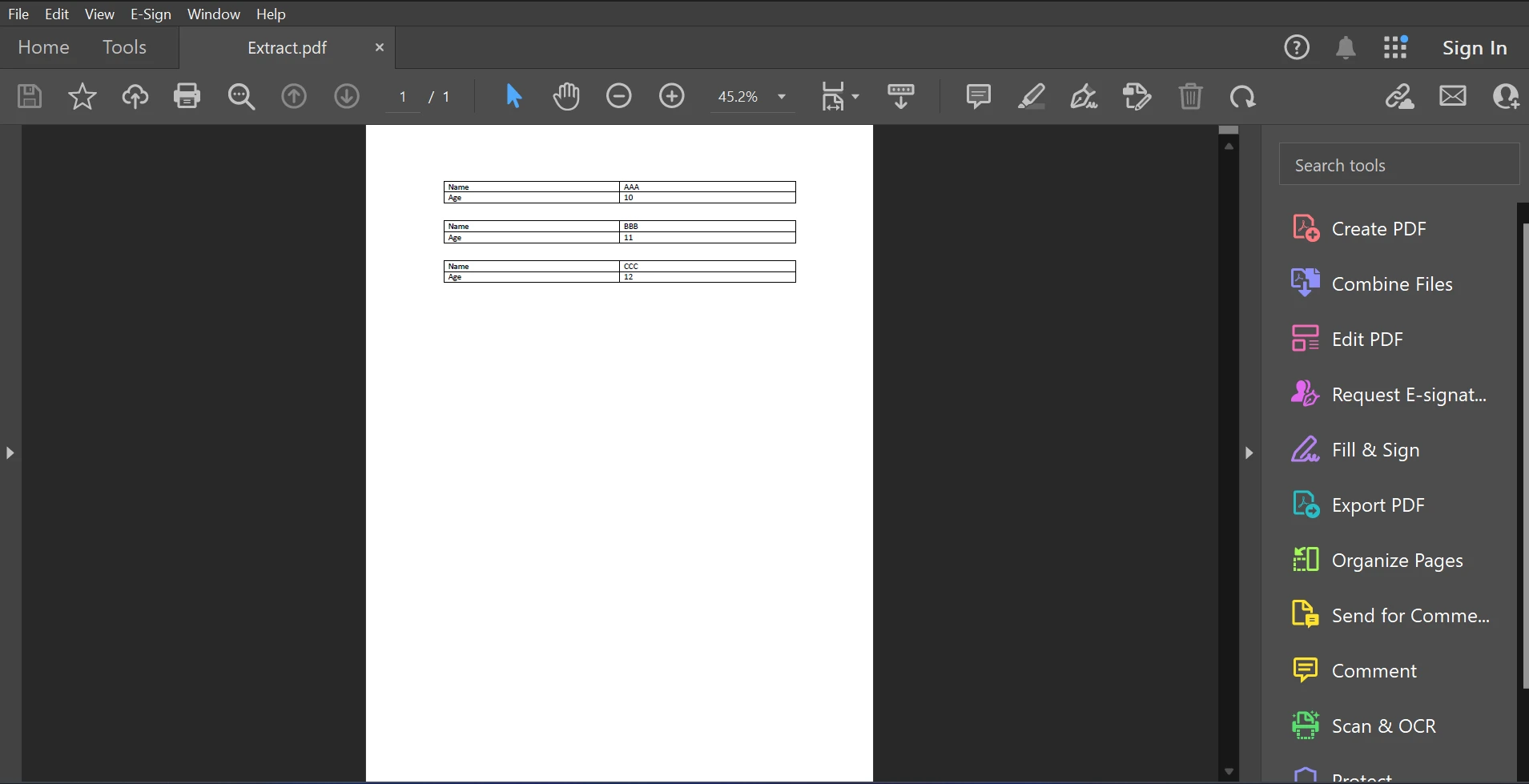 Plik PDF wejściowy
Plik PDF wejściowy
Wyodrębnianie strona po stronie z pliku PDF
Poniższy przykładowy kod pokazuje, jak uzyskać dane z pliku PDF na podstawie numeru strony.
from ironpdf import PdfDocument
# Load the PDF file
pdf = PdfDocument.FromFile('F:\\PDF\\Extract.pdf')
# Extract text from the first page of the PDF document
all_text = pdf.ExtractTextFromPage(0)
# Iterate over each line in the extracted text
for line in all_text.split('\n'):
# Check if the line contains the keyword "Name"
if 'Name' in line:
# Print the line if it contains the keyword
print(line)from ironpdf import PdfDocument
# Load the PDF file
pdf = PdfDocument.FromFile('F:\\PDF\\Extract.pdf')
# Extract text from the first page of the PDF document
all_text = pdf.ExtractTextFromPage(0)
# Iterate over each line in the extracted text
for line in all_text.split('\n'):
# Check if the line contains the keyword "Name"
if 'Name' in line:
# Print the line if it contains the keyword
print(line)Fragment kodu pokazuje, jak odczytać plik PDF i utworzyć obiekt PDF za pomocą funkcji FromFile. Ten obiekt może służyć do uzyskiwania dostępu do tekstu i obrazów w pliku PDF. Przekazując numer strony jako parametr do funkcji ExtractTextFromPage, można pobrać tekst z określonej strony. Ta metoda zwróci ciąg zawierający wszystkie słowa na wybranej stronie. Następnie użyj funkcji split w języku Python, aby rozdzielić wszystkie nowe linie z wyodrębnionego tekstu. Następnie sprawdź, czy każda linijka w wyodrębnionym tekście zawiera wymagane słowa kluczowe. Jeśli słowo kluczowe pasuje, wyświetli się konkretna linia w wierszu poleceń. W przeciwnym razie pominie tę linię i przejdzie do następnej. Wynik ekstrakcji tekstu będzie wyglądał tak, jak pokazano poniżej.
Konwersja całego pliku PDF na tekst
Poniższy przykład kodu ilustruje pierwszą metodę szybkiego i prostego pobierania całej zawartości pliku PDF jako ciągu znaków.
from ironpdf import PdfDocument
# Load the PDF file
pdf = PdfDocument.FromFile('F:\\PDF\\Extract.pdf')
# Extract all text from the PDF document
all_text = pdf.ExtractAllText()
# Iterate over each line in the extracted text
for line in all_text.split('\n'):
# Check if the line contains the keyword "Name"
if 'Name' in line:
# Print the line if it contains the keyword
print(line)from ironpdf import PdfDocument
# Load the PDF file
pdf = PdfDocument.FromFile('F:\\PDF\\Extract.pdf')
# Extract all text from the PDF document
all_text = pdf.ExtractAllText()
# Iterate over each line in the extracted text
for line in all_text.split('\n'):
# Check if the line contains the keyword "Name"
if 'Name' in line:
# Print the line if it contains the keyword
print(line)Powyższy przykładowy kod pokazuje, jak użyć funkcji FromFile do odczytania pliku PDF z istniejącej ścieżki i przekształcenia go w obiekt pliku PDF. W rezultacie możemy użyć tego obiektu czytnika PDF, aby wyświetlić tekst i obrazy zawarte w pliku PDF. Funkcja ExtractAllText obiektu zostanie wykorzystana do wyodrębnienia danych z pliku PDF do postaci zwykłego tekstu, przekształcenia ich na ciąg znaków oraz zastosowania logiki podobnej do powyższej w celu znalezienia konkretnego słowa kluczowego i wyświetlenia wyniku w terminalu. Wyniki są wyświetlane w następujący sposób.
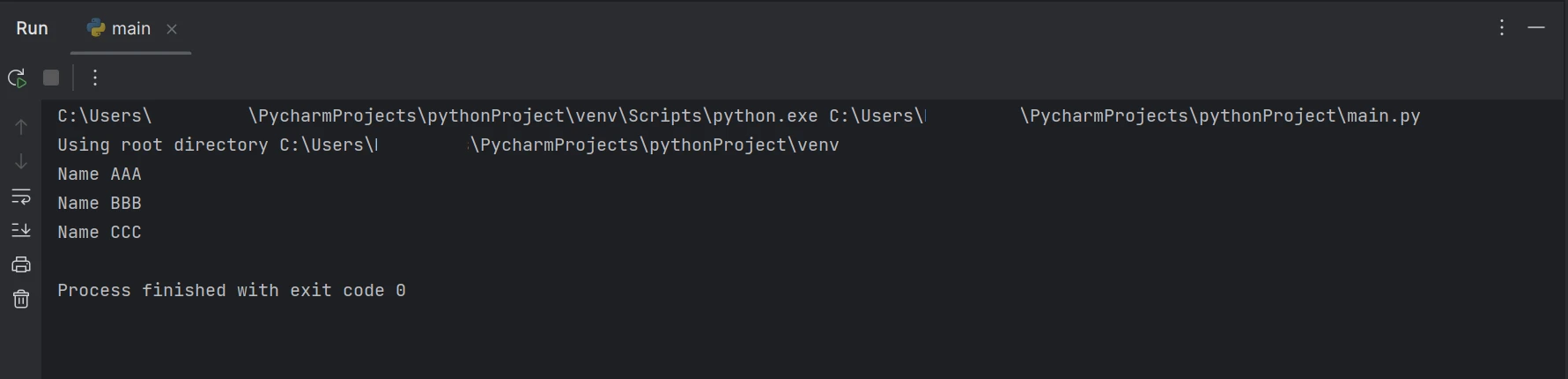 Wynik
Wynik
Powyższy kod/wynik pokazuje, że dany dokument PDF zawiera zarówno imię, jak i wiek, ale wynik pokazuje tylko imię dostępne w dokumencie PDF.
Wnioski
Biblioteka IronPDF oferuje silne mechanizmy bezpieczeństwa, które ograniczają zagrożenia i gwarantują bezpieczeństwo danych. Nie jest ograniczony do żadnej konkretnej przeglądarki i jest kompatybilny ze wszystkimi powszechnie używanymi przeglądarkami. Wystarczy kilka linii kodu, aby programiści mogli szybko tworzyć i odczytywać pliki PDF za pomocą IronPDF. Biblioteka IronPDF oferuje szereg opcji licencyjnych, w tym bezpłatną licencję dla programistów oraz dodatkowe licencje programistyczne dostępne w sprzedaży, aby sprostać różnorodnym wymaganiom programistów.
Pakiet Lite obejmuje Licencję wieczystą, 30-dniową gwarancję zwrotu pieniędzy, roczną konserwację oprogramowania oraz opcje aktualizacji. Licencje te mogą być używane we wszystkich środowiskach. Ponadto firma IronPDF udostępnia bezpłatne licencje z pewnymi ograniczeniami dotyczącymi redystrybucji. Licencja Trial pozwala użytkownikom na wypróbowanie produktu bez znaku wodnego.
Aby uzyskać więcej informacji na temat licencji komercyjnych, zapoznaj się z dostępnymi licencjami IronPDF.
Często Zadawane Pytania
Jak wyodrębnić określony tekst z pliku PDF za pomocą języka Python?
Możesz użyć biblioteki IronPDF for Python do wyodrębniania tekstu z plików PDF. Zapewnia ona funkcje wyodrębniania tekstu strona po stronie za pomocą ExtractTextFromPage lub z całego dokumentu za pomocą ExtractAllText.
Jakie kroki należy wykonać, aby skonfigurować IronPDF w projekcie Python?
Najpierw zainstaluj środowisko uruchomieniowe .NET 6.0, jeśli jeszcze go nie masz. Następnie skonfiguruj Python w swoim środowisku programistycznym, takim jak PyCharm. Zainstaluj IronPDF za pomocą polecenia pip install ironpdf, aby rozpocząć integrację funkcji PDF z projektem.
Czy IronPDF jest kompatybilny z frameworkami takimi jak Django i Flask?
Tak, IronPDF dobrze integruje się z frameworkami do tworzenia stron internetowych w języku Python, takimi jak Django i Flask, zapewniając wszechstronne opcje obsługi plików PDF w aplikacjach internetowych.
Jakie opcje licencyjne są dostępne dla korzystania z IronPDF w Pythonie?
IronPDF oferuje szereg opcji licencyjnych, w tym bezpłatną licencję deweloperską do użytku osobistego oraz różne licencje komercyjne, które zapewniają dodatkowe funkcje i korzyści.
Jak zainstalować IronPDF for Python?
Zainstaluj IronPDF za pomocą menedżera pakietów pip, uruchamiając polecenie pip install ironpdf w terminalu lub wierszu poleceń.
Jakie środowisko programistyczne jest zalecane do korzystania z IronPDF w języku Python?
PyCharm jest zalecanym zintegrowanym środowiskiem programistycznym (IDE) do tworzenia aplikacji w języku Python przy użyciu IronPDF, ze względu na jego wszechstronny zestaw funkcji i obsługę języka Python.
Jakie są kluczowe funkcje biblioteki IronPDF for Python?
IronPDF for Python oferuje takie funkcje, jak tworzenie plików PDF z HTML, konwersja obrazów do formatu PDF, obsługa formularzy, wyodrębnianie tekstu i obrazów oraz scalanie plików PDF.
Jak bezpieczna jest biblioteka IronPDF do obsługi plików PDF?
IronPDF został zaprojektowany z myślą o solidnych funkcjach bezpieczeństwa, zapewniających bezpieczną obsługę plików PDF. Obsługuje szyfrowanie i ochronę hasłem w celu zabezpieczenia poufnych informacji.
















