
How to Add or Remove PDF Pages Using Python
This article will demonstrate how to add or remove PDF pages using Python and a PDF library named IronPDF for Python.
1. IronPDF for Python
IronPDF is a market-leading PDF Python library that provides developers with the capability to effortlessly generate, manipulate, and work with PDF documents in their applications. With IronPDF, developers can seamlessly integrate PDF functionality into their Python projects, whether it be for creating dynamic reports, generating invoices, or converting web content into PDF files. This library offers a user-friendly and efficient way to handle PDF-related tasks, enabling you to create and manipulate PDFs with ease.
Whether you're building web applications, desktop software, or automating document workflows, IronPDF is a valuable tool that empowers you to work with PDFs in the Python environment, making it an essential addition to any developer's toolkit. This introductory guide will explore the key features and capabilities of IronPDF for Python. Using IronPDF, developers can merge several PDF files into a single document, extract text from a particular page, add watermarks, and perform other operations such as deleting pages, removing a blank page, rotating pages, adding pages, and reading PDF files.
2. Installing IronPDF
To install IronPDF, just open PyCharm or any other Python compiler, and create a new Python project or open an existing one. Once the project is created or opened, open the terminal.
IronPDF for Python can be easily installed using the terminal command. Just run the following command in the terminal, and IronPDF should be installed in a minute.
pip install ironpdf
 Install IronPDF package
Install IronPDF package
Once the installation is completed, you are all set to start playing with the code.
3. Code Examples
Before adding and removing PDF pages from a PDF document, let's create a 4-page simple PDF file using HTML to PDF conversion. The code below creates PDF files to use as an input PDF document for the upcoming code examples.
from ironpdf import *
# HTML content to be converted to PDF
html = """
<p> Hello Iron</p>
<p> This is 1st Page </p>
<div style='page-break-after: always;'></div>
<p> This is 2nd Page</p>
<div style='page-break-after: always;'></div>
<p> This is 3rd Page</p>
<div style='page-break-after: always;'></div>
<p> This is 4th Page</p>
"""
# Initialize the renderer
renderer = ChromePdfRenderer()
# Render the HTML as a PDF document
pdf = renderer.RenderHtmlAsPdf(html)
# Save the PDF to a file
pdf.SaveAs("Page1And4.pdf")from ironpdf import *
# HTML content to be converted to PDF
html = """
<p> Hello Iron</p>
<p> This is 1st Page </p>
<div style='page-break-after: always;'></div>
<p> This is 2nd Page</p>
<div style='page-break-after: always;'></div>
<p> This is 3rd Page</p>
<div style='page-break-after: always;'></div>
<p> This is 4th Page</p>
"""
# Initialize the renderer
renderer = ChromePdfRenderer()
# Render the HTML as a PDF document
pdf = renderer.RenderHtmlAsPdf(html)
# Save the PDF to a file
pdf.SaveAs("Page1And4.pdf")This Python code uses the IronPDF library to create a PDF document from HTML content. The HTML content is defined as a string, containing paragraphs and "page-break-after" div tags, indicating page breaks. It's structured to have four pages. The code then uses the ChromePdfRenderer to convert this HTML into a PDF document. Finally, it saves the resulting PDF as "Page1And4.pdf".
Essentially, this code generates a PDF with multiple pages, where each page corresponds to the content between two consecutive "page-break" div tags in the HTML, and it saves this HTML content to a PDF file.
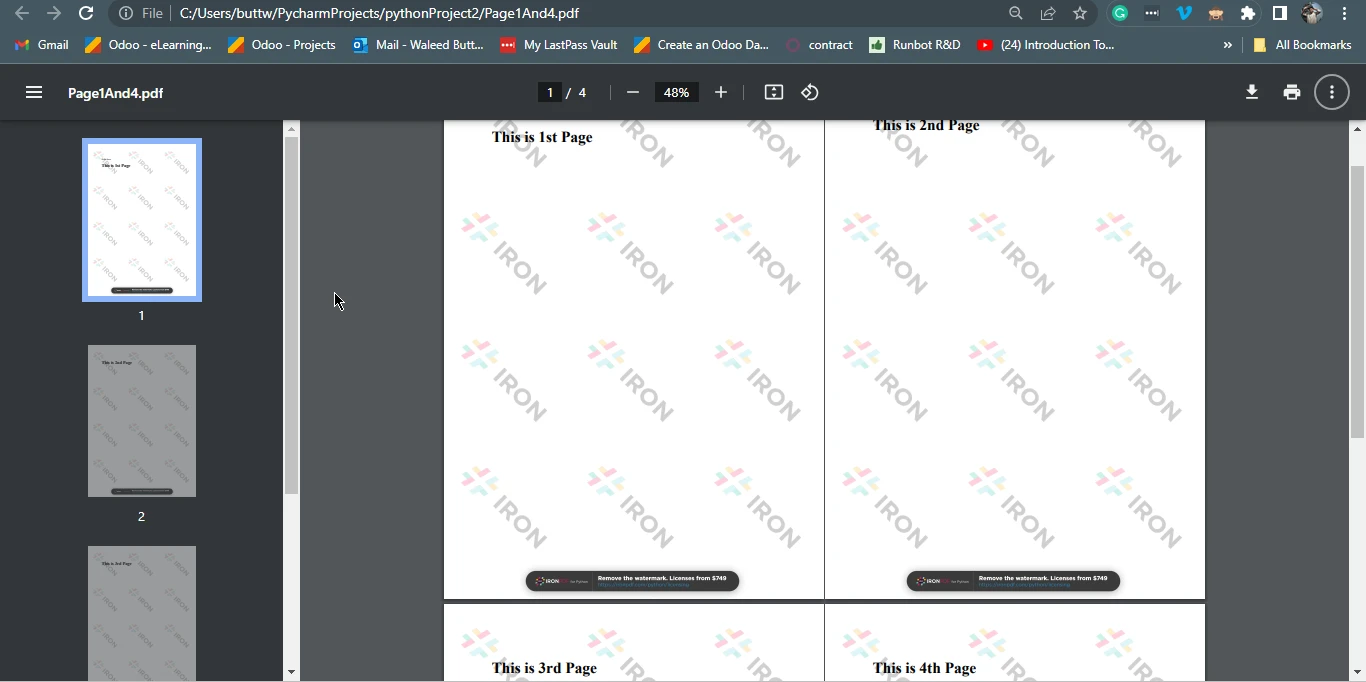 Page1And4.pdf
Page1And4.pdf
3.1. Removing Specific Page From PDF Files Using IronPDF
This section will remove pages from a PDF created earlier. The following code will remove a page from the PDF file.
from ironpdf import *
# Load the existing PDF document
pdf = PdfDocument.FromFile("Page1And4.pdf")
# Remove the page at index 1 (second page)
pdf.RemovePage(1)
# Save the modified PDF to a new file
pdf.SaveAs("removed.pdf")from ironpdf import *
# Load the existing PDF document
pdf = PdfDocument.FromFile("Page1And4.pdf")
# Remove the page at index 1 (second page)
pdf.RemovePage(1)
# Save the modified PDF to a new file
pdf.SaveAs("removed.pdf")The above code utilizes the IronPDF library to manipulate a PDF document. It begins by importing the necessary components and then loads an existing PDF document called "Page1And4.pdf" using the FromFile() method. It proceeds to delete a page from the PDF, identified by its index '1', and subsequently calls the SaveAs method that saves the modified document as a new PDF file named removed.pdf. In essence, the code performs the task of removing the second page from the original PDF document and saving the resulting document as a separate file.
3.1.1. Output PDF file
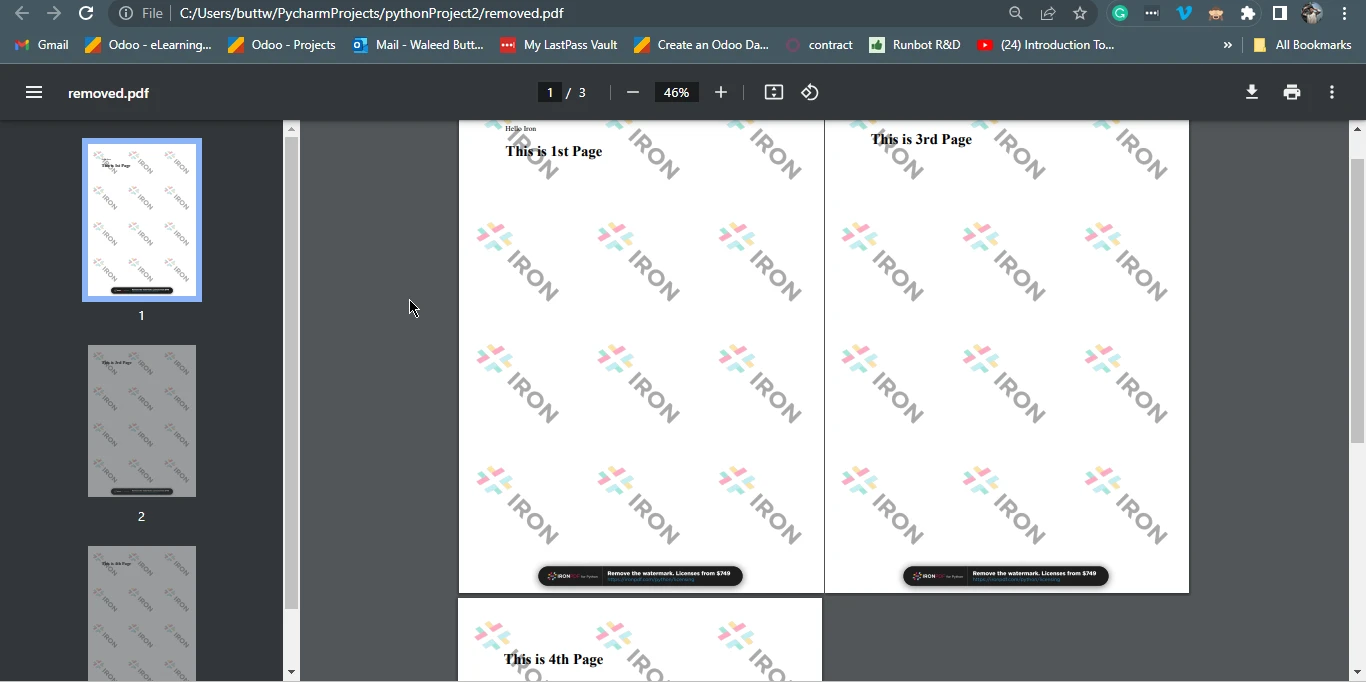 Output file
Output file
3.2. Add A Page in PDF Document Using IronPDF
This section will discuss how to add a new page in existing PDF files. For this, let's create a new PDF file and then add the newly created PDF to the previously created PDF file using page numbers with just a few lines of code.
Below is the sample code of adding a new PDF page into the original document.
from ironpdf import *
# HTML content to represent a new page
pdf_page = """
<h1> Cover Page</h1>
"""
# Initialize the renderer and render the new PDF page
renderer = ChromePdfRenderer()
pdfdoc_a = renderer.RenderHtmlAsPdf(pdf_page)
# Load the existing PDF file
pdf = PdfDocument.FromFile("removed.pdf")
# Prepend the new page to the beginning of the existing PDF
pdf.PrependPdf(pdfdoc_a)
# Save the combined PDF to a new file
pdf.SaveAs("addPage.pdf")from ironpdf import *
# HTML content to represent a new page
pdf_page = """
<h1> Cover Page</h1>
"""
# Initialize the renderer and render the new PDF page
renderer = ChromePdfRenderer()
pdfdoc_a = renderer.RenderHtmlAsPdf(pdf_page)
# Load the existing PDF file
pdf = PdfDocument.FromFile("removed.pdf")
# Prepend the new page to the beginning of the existing PDF
pdf.PrependPdf(pdfdoc_a)
# Save the combined PDF to a new file
pdf.SaveAs("addPage.pdf")This Python code snippet leverages the IronPDF library to manipulate PDF documents. Initially, it defines an HTML content snippet representing a cover page with a title. Then, it employs the ChromePdfRenderer() method to convert this HTML into a PDF document, storing it in pdfdoc_a.
Then, it loads an existing PDF document, "removed.pdf," using PdfDocument.FromFile("removed.pdf"). The code proceeds to prepend the content of pdfdoc_a to this existing PDF using the pdf.PrependPdf(pdfdoc_a) method. Essentially, this code combines the cover page PDF with the "removed.pdf", creating a new PDF document named "addPage.pdf", effectively adding the cover page to the beginning of the original PDF.
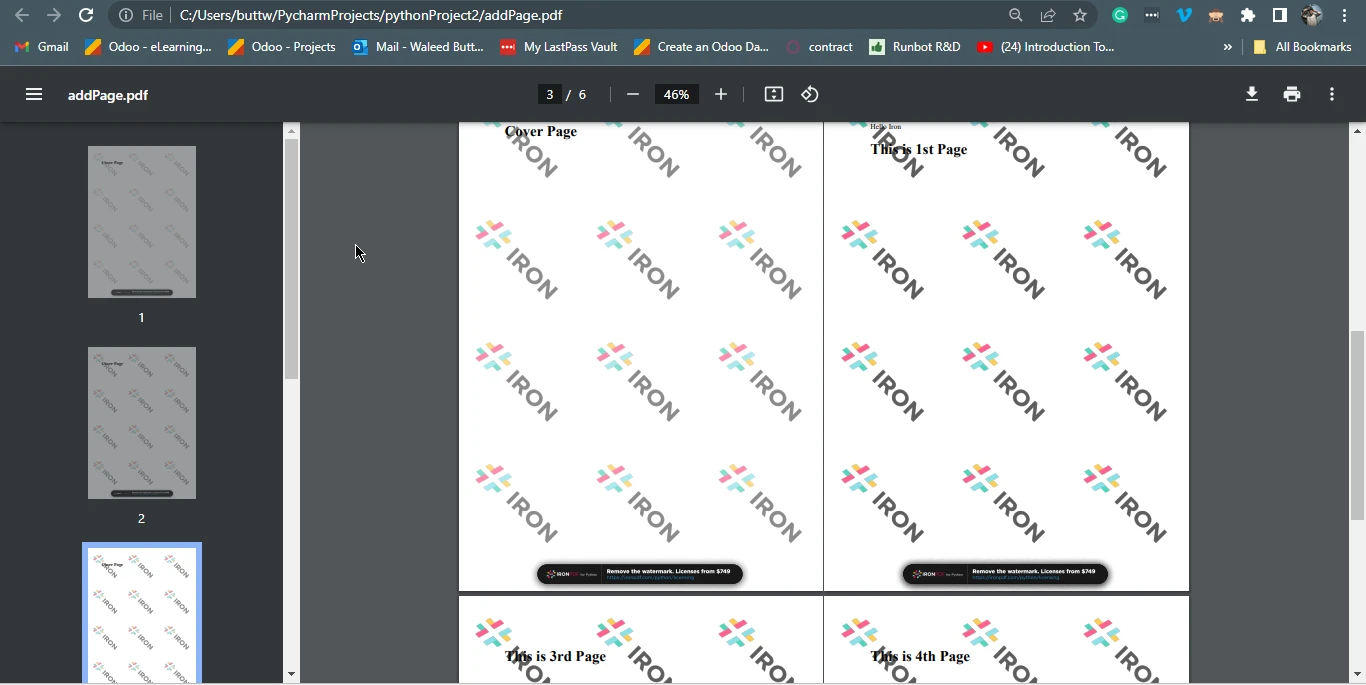 Output file
Output file
4. Conclusion
This article explored the world of PDF manipulation using Python, with a focus on the IronPDF library. The ability to add or remove pages from PDF documents is a valuable skill in today's digital landscape, and Python offers an accessible and powerful way to achieve these tasks. The article covered the essential steps for installing IronPDF and provided code examples to illustrate the process of creating, removing, and adding pages in PDFs.
With IronPDF, Python developers can efficiently work with PDF documents, whether for generating reports, customizing content, or improving document workflows. As the digital world continues to rely on PDFs for various purposes, mastering these techniques empowers developers to meet a wide range of needs, making Python and IronPDF a dynamic combination for PDF manipulation.
The code example of removing PDF pages can be found at the following sample code. The code example of adding PDF pages can be found in another Python code example. Also, if you are curious about how HTML to PDF conversion works, please visit this tutorial page.
Explore the versatile features of IronPDF for Python library and experience the transformation by opting for a free trial today.
Frequently Asked Questions
How can I add a new cover page to a PDF in Python?
You can add a new cover page to a PDF document in Python by using IronPDF's ChromePdfRenderer to create a new page from HTML content. Then, use the PrependPdf method to add this new page to the front of an existing PDF document.
What steps are involved in removing a page from a PDF using IronPDF?
To remove a page from a PDF using IronPDF, first load your PDF using PdfDocument.FromFile. Identify the page you wish to remove by its index and use the RemovePage method to delete it.
Can I merge multiple PDF files using a PDF library in Python?
Yes, with IronPDF for Python, you can easily merge multiple PDF files into a single document by using methods like MergePdf that combine PDFs seamlessly.
What features does IronPDF offer for editing PDFs in Python?
IronPDF offers a range of features for editing PDFs, including adding and removing pages, merging documents, extracting text, adding watermarks, and rotating pages, making it a comprehensive tool for PDF manipulation.
How do I convert HTML content into a PDF document using IronPDF?
To convert HTML content into a PDF document using IronPDF, utilize the RenderHtmlAsPdf method, which processes HTML strings and outputs them as PDF files.
Is there a trial version available for the IronPDF library?
Yes, a free trial of IronPDF is available, allowing users to explore the library's features and capabilities in handling PDF documents within Python applications.
What types of applications can benefit from PDF manipulation using IronPDF?
Applications ranging from web platforms to desktop software can benefit from PDF manipulation using IronPDF. It supports tasks like generating reports, automating document workflows, and customizing PDF content.
Where can I find Python code examples for adding or removing PDF pages?
Code examples for adding or removing PDF pages using IronPDF can be found in the article on the IronPDF website, which provides practical Python code snippets for these operations.
Why is managing PDF pages important in digital workflows?
Managing PDF pages is crucial in digital workflows for customizing document layouts, removing unnecessary content, and automating report generation, which enhances the efficiency and adaptability of document management.
















