
在 Python 中使用 WhisperX 進行轉录
Python 憑藉其龐大的程式庫和框架生態系統,鞏固了其作為世界上用途最廣泛、功能最強大的程式語言之一的地位。 WhisperX 就是這樣一個在機器學習和自然語言處理 (NLP) 領域引起轟動的函式庫。 在本文中,我們將探討 WhisperX 是什麼、它的主要功能以及如何在各種應用程式中使用它。 此外,我們將介紹另一個強大的 Python 函式庫IronPDF,並透過實際的程式碼範例示範如何將其與 WhisperX 一起使用。
WhisperX是什麼?
WhisperX 是一個高階 Python 函式庫,專為語音辨識和自然語言處理任務而設計。 它利用最先進的機器學習模型,將口語轉換為書面文本,具有高精度的語言檢測和時間精確的語音轉錄功能。 WhisperX 在即時翻譯至關重要的應用中特別有用,例如虛擬助理、自動化客戶服務系統和轉錄服務。
WhisperX 的主要功能
1.高精度: WhisperX 使用尖端演算法和大型資料集來訓練其模型,確保語音辨識的高精度。 2.即時處理:該庫針對即時處理進行了最佳化,使其成為需要立即轉錄和回應的應用程式的理想選擇。 3.語言支援: WhisperX 支援多種語言,滿足全球使用者和各種使用場景的需求。 4.易於整合:憑藉其完善的 API 文檔,WhisperX 可以輕鬆整合到現有的 Python 應用程式中。 5.自訂:使用者可以微調模型,以更好地適應特定的口音、方言和術語。
WhisperX 入門指南
要開始使用 WhisperX,您需要安裝該程式庫。 這可以透過 Python 套件安裝程式 pip 來完成。 假設您已安裝 Python 和 pip,您可以使用下列命令安裝 WhisperX:
pip install whisperxpip install whisperxWhisperX 基本用法 - 快速自動語音識別
以下是一個使用 WhisperX 轉錄音訊檔案的基本範例:
import whisperx
# Initialize the WhisperX recognizer
recognizer = whisperx.Recognizer()
# Load your audio
audio_file = "path_to_your_audio_file.wav"
# Perform transcription
transcription = recognizer.transcribe(audio_file)
# Print the transcription
print("Transcription:", transcription)import whisperx
# Initialize the WhisperX recognizer
recognizer = whisperx.Recognizer()
# Load your audio
audio_file = "path_to_your_audio_file.wav"
# Perform transcription
transcription = recognizer.transcribe(audio_file)
# Print the transcription
print("Transcription:", transcription)這個簡單的例子展示瞭如何初始化 WhisperX 識別器、載入音訊並執行轉錄,從而以高精度將口語轉換為文字。

WhisperX 的高級功能
WhisperX 還提供說話者識別等高級功能,這在多說話人環境中至關重要。 以下是如何使用此功能的範例:
import whisperx
# Initialize the WhisperX recognizer with speaker identification enabled
recognizer = whisperx.Recognizer(speaker_identification=True)
# Load your audio file
audio_file = "path_to_your_audio_file.wav"
# Perform transcription with speaker identification
transcription, speakers = recognizer.transcribe(audio_file)
# Print the transcription with speaker labels
for i, segment in enumerate(transcription):
print(f"Speaker {speakers[i]}: {segment}")import whisperx
# Initialize the WhisperX recognizer with speaker identification enabled
recognizer = whisperx.Recognizer(speaker_identification=True)
# Load your audio file
audio_file = "path_to_your_audio_file.wav"
# Perform transcription with speaker identification
transcription, speakers = recognizer.transcribe(audio_file)
# Print the transcription with speaker labels
for i, segment in enumerate(transcription):
print(f"Speaker {speakers[i]}: {segment}")在這個例子中,WhisperX 不僅可以轉錄音頻,還可以識別不同的說話人,並相應地標記每個片段。
IronPDF for Python
雖然 WhisperX 可以處理音訊到文字的轉錄,但通常需要以結構化和專業的格式呈現這些資料。 這時IronPDF for Python 就派上用場了。 IronPDF是一個功能強大的程式庫,可用於以程式設計方式產生、編輯和操作 PDF 文件。 它使開發人員能夠從頭開始產生 PDF、將 HTML 轉換為 PDF 等等。
安裝IronPDF
可以使用以下指令安裝IronPDF :
pip install ironpdfpip install ironpdf
結合 WhisperX 和IronPDF
現在讓我們建立一個實際範例,示範如何使用 WhisperX 轉錄音訊文件,然後使用IronPDF產生包含轉錄內容的 PDF 文件。
import whisperx
from ironpdf import IronPdf
# Initialize the WhisperX recognizer
recognizer = whisperx.Recognizer()
# Load your audio file
audio_file = "path_to_your_audio_file.wav"
# Perform transcription
transcription = recognizer.transcribe(audio_file)
# Create a PDF document using IronPDF
renderer = IronPdf.ChromePdfRenderer()
pdf_from_html = renderer.RenderHtmlAsPdf(f"<h1>Transcription</h1><p>{transcription}</p>")
# Save the PDF to a file
output_file = "transcription_output.pdf"
pdf_from_html.save(output_file)
print(f"Transcription saved to {output_file}")import whisperx
from ironpdf import IronPdf
# Initialize the WhisperX recognizer
recognizer = whisperx.Recognizer()
# Load your audio file
audio_file = "path_to_your_audio_file.wav"
# Perform transcription
transcription = recognizer.transcribe(audio_file)
# Create a PDF document using IronPDF
renderer = IronPdf.ChromePdfRenderer()
pdf_from_html = renderer.RenderHtmlAsPdf(f"<h1>Transcription</h1><p>{transcription}</p>")
# Save the PDF to a file
output_file = "transcription_output.pdf"
pdf_from_html.save(output_file)
print(f"Transcription saved to {output_file}")組合程式碼範例的解釋
1.使用 WhisperX 進行轉錄:
* 初始化 WhisperX 識別器並載入音訊檔案。
* `transcribe` 方法處理音訊並返回轉錄文字。2.使用IronPDF建立 PDF:
* 建立 `IronPdf.ChromePdfRenderer` 的實例。
* 使用 `RenderHtmlAsPdf` 方法,將包含轉錄文字的 HTML 格式字串新增至 PDF 。
* `save` 方法將 PDF 寫入檔案。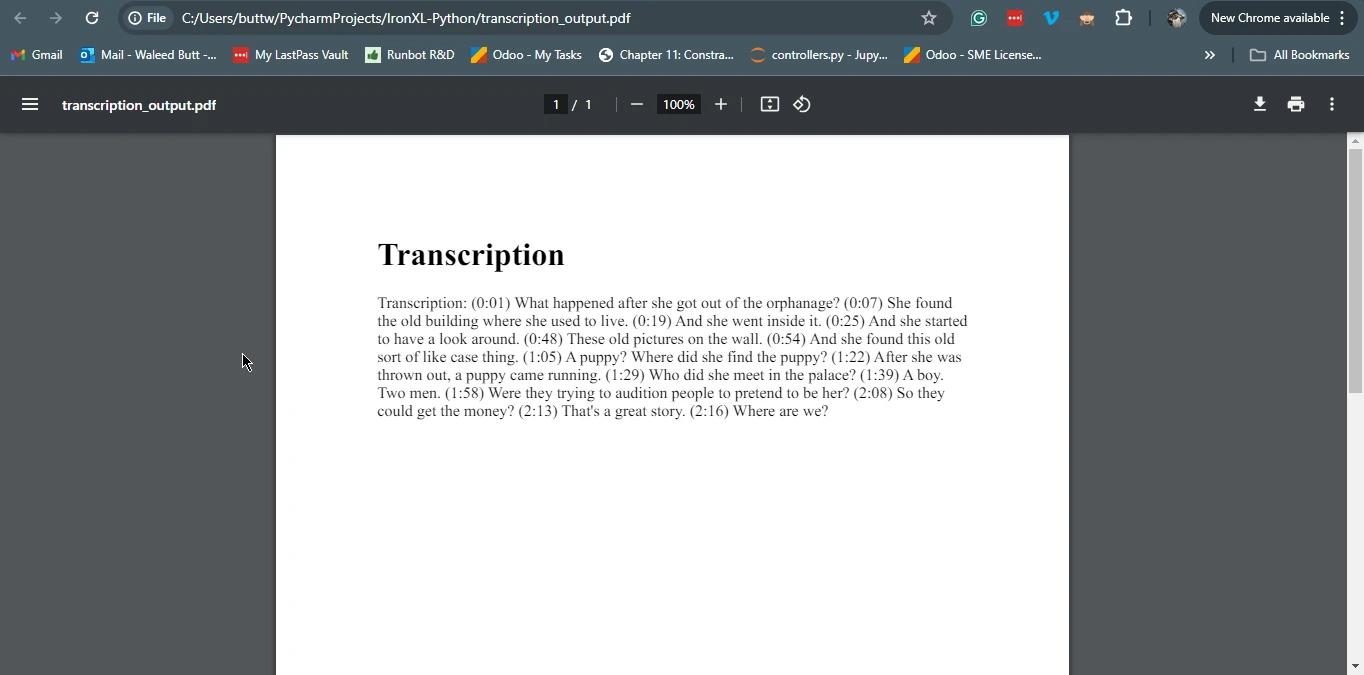
這個組合範例展示如何利用 WhisperX 和IronPDF的優勢來創建一個完整的解決方案,該方案可以轉錄音訊並產生包含轉錄內容的 PDF 文件。
結論
WhisperX 是一款功能強大的工具,適合任何希望在應用程式中實現語音辨識、說話者分割和轉錄功能的人。 其高精度、即時處理能力以及對多種語言的支持,使其成為自然語言處理領域的寶貴資產。另一方面, IronPDF提供了一種以程式設計方式建立和操作 PDF 文件的無縫方法。 透過將 WhisperX 和IronPDF結合起來,開發人員可以創建全面的解決方案,不僅可以轉錄音頻,還可以以精美、專業的格式呈現轉錄內容。
無論您是在建立虛擬助理、客戶服務聊天機器人還是轉錄服務,WhisperX 和IronPDF都能提供必要的工具來增強您的應用程式的功能,並為您的用戶提供高品質的結果。
要了解有關IronPDF許可的更多詳細信息,請訪問IronPDF許可頁面。 此外,我們也提供了關於HTML轉PDF轉換的詳細教程,供您進一步學習。
















