
如何在 Python 中讀取 PDF 文件
PDF(便攜式文件格式)文件已成為共用文件的通用標準。 它們因能夠保持文件的佈局和格式而被廣泛使用。 然而,使用 Python 等程式語言處理 PDF 檔案可能會有些挑戰。 本文介紹了IronPDF,這是一個 Python PDF 庫,它允許我們對 PDF 文件執行各種操作。
IronPDF for Python PDF 函式庫
IronPDF是一個高級的Python PDF 庫,可以方便地處理 PDF 格式檔案。 它提供了一個易於使用的 API,用於各種 PDF 操作。 您可以讀取和寫入 PDF 文件,將 PDF 文件轉換為不同的格式,合併多個 PDF 文件等等。 除了其他功能外,它還可以處理頁面物件、從 PDF 文件的所有頁面中提取文字以及旋轉 PDF 頁面。
如何在 Python 中讀取 PDF 文件
- 使用 Pip 安裝 Python PDF 函式庫。
- 在 Python 腳本中匯入 Python PDF 函式庫。
- 應用 PDFReader Python 函式庫的許可證金鑰。
- 透過提供文件路徑載入任何 PDF 文件。
- 在 Python 控制台中讀取 PDF 內容。
使用IronPDF讀取 PDF 文件
使用IronPDF閱讀 PDF 文件需要幾個步驟。 以下是一份簡單的入門指南:
步驟 1:在 Visual Studio 中建立虛擬環境
在使用 Python 時,建立一個稱為虛擬環境的隔離環境至關重要。 此環境可讓您管理目前專案特有的依賴項,而不會幹擾其他專案。 在像 Visual Studio Code 這樣的整合開發環境 (IDE) 中,建立虛擬環境變得更加簡單直接。 為此,請按照以下步驟操作:
在 Visual Studio Code 中開啟資料夾。 按 Ctrl+Shift+P 開啟指令面板。 在命令面板中,搜尋"Python: 建立環境"。

選擇第一個選項,然後選擇"Venv"作為環境類型。

之後,選擇 Python 解釋器,它將開始建立虛擬環境。

現在,您的 Python 腳本已經準備就緒,擁有了獨立的運行空間,確保專案依賴項都限制在這個環境中。
![]()
步驟 2 安裝IronPDF for Python 函式庫
虛擬環境設定完畢後,就可以安裝IronPDF for Python 庫了。 您可以使用 Python 套件安裝程式"pip"來安裝它:
pip install ironpdfpip install ironpdf步驟 3:安裝.NET 6.0
IronPDF for Python 需要安裝.NET 6.0 SDK。
請從微軟.NET網站下載並安裝.NET 6.0 SDK。
步驟 4:導入IronPDF
成功安裝IronPDF後,下一步是將其匯入到您的 Python 腳本中。 匯入該庫後,即可在腳本中使用該庫的所有函數和方法。 您可以使用以下程式碼行匯入IronPDF :
from ironpdf import *from ironpdf import *這行程式碼將IronPDF庫中所有可用的模組、函數和類別匯入到您的腳本中。
步驟五:應用許可證密鑰
要完全解鎖IronPDF庫的功能,您需要套用許可證密鑰。 應用程式許可證金鑰就像將金鑰指派給 @@--CODE-1095--CODE-1094--CODE-1095 類別的 @@--CODE-1094--CODE-1095 屬性一樣簡單。 具體操作方法如下:
License.LicenseKey = "License-Key-Here"License.LicenseKey = "License-Key-Here"請將 "License-Key-Here" 替換為您的IronPDF實際許可證金鑰。 有了許可證金鑰,您現在可以在 Python 腳本中充分利用IronPDF庫的全部潛力。
步驟 6 設定日誌路徑
接下來,設定IronPDF操作的日誌記錄。 透過設定自訂日誌路徑,您可以儲存庫產生的運行時日誌,幫助您偵錯和診斷執行過程中可能出現的問題。 設定方法如下:
# Enable debugging mode for detailed logs
Logger.EnableDebugging = True
# Set the path for the log file
Logger.LogFilePath = "Custom.log"
# Set logging mode to capture all log types
Logger.LoggingMode = Logger.LoggingModes.All# Enable debugging mode for detailed logs
Logger.EnableDebugging = True
# Set the path for the log file
Logger.LogFilePath = "Custom.log"
# Set logging mode to capture all log types
Logger.LoggingMode = Logger.LoggingModes.All在此程式碼片段中,Logger.EnableDebugging = True 啟用偵錯,Logger.LogFilePath = "Custom.log" 將輸出日誌檔案設定為"Custom.log",而 Logger.LoggingMode = Logger.LoggingModes.All 確保記錄所有類型的日誌資訊。
步驟 7:載入 PDF 文檔
使用IronPDF載入 PDF 文件就像呼叫一個方法一樣簡單。 PdfDocument.FromFile 方法將給定路徑中的 PDF 文件載入到 PDF 文件物件中。 您只需提供PDF檔案的路徑(以字串形式):
pdf = PdfDocument.FromFile("PDF B.pdf")pdf = PdfDocument.FromFile("PDF B.pdf")在此程式碼中,pdf 變成表示指定 PDF 檔案的 PdfDocument 物件。
步驟 8:讀取 PDF 檔案內容
IronPDF提供了一個名為 ExtractAllText() 的方法,可以幫助從 PDF 文件中提取文字內容。 當您需要閱讀和分析 PDF 文件的內容時,這尤其方便:
all_text = pdf.ExtractAllText() # Extracts all text from the PDF document
print(all_text) # Prints the extracted text to the consoleall_text = pdf.ExtractAllText() # Extracts all text from the PDF document
print(all_text) # Prints the extracted text to the console在這個例子中,all_text 將保存來自 pdf 物件的所有 PDF 檔案文字。 您將能夠在控制台上閱讀 PDF 內容。
步驟 9 載入第二個 PDF 文件
就像你載入第一個 PDF 文件一樣,你也可以載入第二個 PDF 文件。 當您需要處理多個PDF文件時,此功能非常有用:
pdf_2 = PdfDocument.FromFile("PDF A.pdf")pdf_2 = PdfDocument.FromFile("PDF A.pdf")在此程式碼中,pdf_2 是另一個 PdfDocument 對象,表示第二個 PDF 檔案。
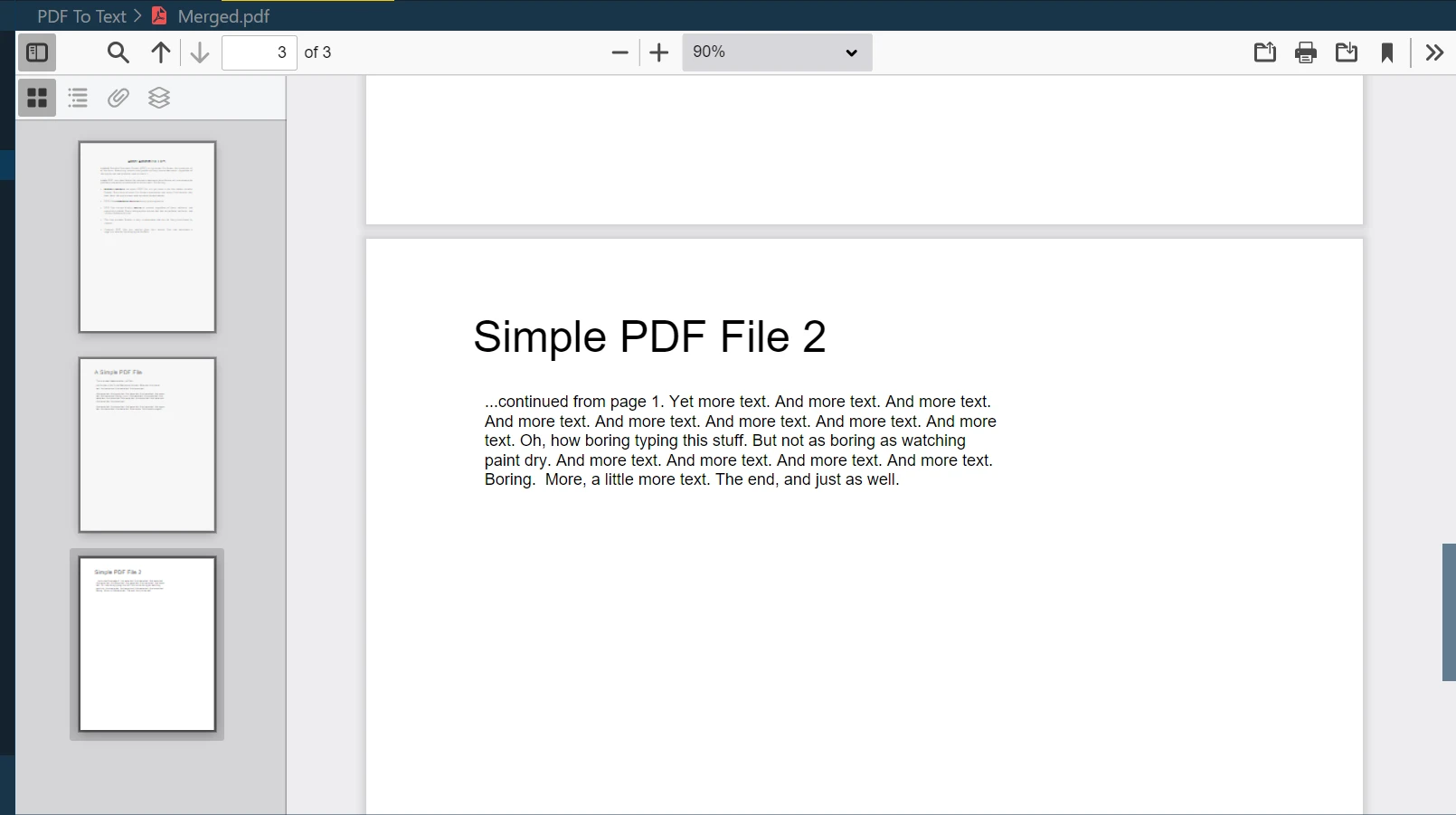
步驟 10:合併兩個文件
IronPDF的強大功能之一是將多個 PDF 文件合併成一個新的 PDF 文件。您可以使用以下方法輕鬆合併兩個或更多 PDF 文件:
merged = PdfDocument.Merge(pdf, pdf_2) # Merges pdf and pdf_2 documents
merged.SaveAs("Merged.pdf") # Saves the merged document as 'Merged.pdf'merged = PdfDocument.Merge(pdf, pdf_2) # Merges pdf and pdf_2 documents
merged.SaveAs("Merged.pdf") # Saves the merged document as 'Merged.pdf'在這個例子中,merged 是一個新的 PdfDocument 對象,它是合併 pdf 和 pdf_2 的結果。 然後,SaveAs 方法將合併後的文件儲存為"Merged.pdf"。
第 11 步 拆分第一個 PDF
IronPDF還允許您拆分 PDF 文件並將特定頁面提取到新的 PDF 文件中。 這是使用 CopyPage 方法完成的:
page1doc = pdf.CopyPage(0) # Copies the first page of the pdf document
page1doc.SaveAs("Split1.pdf") # Saves the copied page as a new document 'Split1.pdf'page1doc = pdf.CopyPage(0) # Copies the first page of the pdf document
page1doc.SaveAs("Split1.pdf") # Saves the copied page as a new document 'Split1.pdf'這裡,page1doc 是一個新的 PdfDocument 對象,其中包含 pdf 文件的第一頁。 然後,此頁面將儲存為名為"Split1.pdf"的輸出PDF檔案。

第 12 步 新增浮水印
水印功能是IronPDF提供的另一個令人印象深刻的功能。 您可以為PDF文件新增所需的文字或圖片浮水印。 ApplyWatermark 方法用於在 pdf 物件表示的 PDF 中新增浮水印。
pdf.ApplyWatermark("<h2 style='color:red'>SAMPLE</h2>", 30, VerticalAlignment.Middle, HorizontalAlignment.Center)
pdf.SaveAs("Watermarked.pdf")pdf.ApplyWatermark("<h2 style='color:red'>SAMPLE</h2>", 30, VerticalAlignment.Middle, HorizontalAlignment.Center)
pdf.SaveAs("Watermarked.pdf")在此程式碼片段中,ApplyWatermark 在 PDF 的中間位置新增了帶有"SAMPLE"字樣的紅色浮水印。 然後,SaveAs 將帶有浮水印的文件儲存為"Watermarked.pdf"。
IronPDF相容性
IronPDF是一個功能全面的 Python 函式庫,相容於多種 Python 版本。 它支援從 Python 3.6 開始的所有現代 Python 版本。 IronPDF不限於單一作業系統。 它與平台無關,因此可以在各種作業系統上使用。 無論是 Windows、Mac 還是 Linux, IronPDF都能在這些平台上無縫運作。 這種跨平台相容性是一個巨大的優勢,使得IronPDF成為開發人員的首選,無論他們的作業系統偏好如何。
結論
總之, IronPDF是一個優秀的 Python 函式庫,可以簡化 PDF 文件的處理。 無論您需要合併多個 PDF 檔案、擷取文字、分割 PDF 檔案或新增浮水印, IronPDF都能滿足您的需求。 它相容於多種平台且易於使用,對於任何處理 PDF 文件的開發人員來說,都是一款非常有價值的工具。
IronPDF提供免費試用。 試用期為您提供了充足的機會來體驗其各項功能,並評估其是否符合您的特定需求。 測試完成後,您可以從 $799 開始購買許可證。
















