
如何在 Python 中從 PDF 提取文本
本文將示範如何使用 Python 中的IronPDF從 PDF 檔案中提取所有文本,並為您提供高效完成此任務所需的知識和 Python 程式碼片段。
如何使用 Python 從 PDF 提取文本
- 下載用於從 PDF 檔案中提取文字的 Python 模組
- 使用`FromFile`方法匯入 PDF 文件
- 使用`ExtractText`方法從匯入的 PDF 中提取文本
- 使用`ExtractTextFromPage`方法從特定頁面提取文本
- 將提取的文字輸出到控制台或文字文件
IronPDF - Python 函式庫
IronPDF for Python是一個功能強大的 Python PDF 庫,可讓開發人員從 PDF 文件中提取文字。 使用IronPDF,您可以自動從 PDF 文件中提取文字內容的數據,從而更輕鬆地處理和分析 PDF 文件中包含的資訊。
IronPDF為 Python 程式設計師提供了使用 Python 操作 PDF 文件、從 PDF 文件中提取資料以及與 PDF 文件互動的功能,從而更容易實現各種與 PDF 相關的任務的自動化。 無論您需要產生 PDF、修改現有 PDF、從內容中提取數據,還是執行其他 PDF 操作, IronPDF都能憑藉其直覺的 API 和強大的功能簡化流程。
主要特點
IronPDF for Python 函式庫的一些功能包括:
先決條件
在使用IronPDF進行文字擷取之前,請確保已滿足以下先決條件:
- Python 安裝:請確保您的系統上已安裝 Python。 IronPDF與 Python 3.x 版本相容,因此請確保您已安裝相容的 Python 版本。
IronPDF庫:使用 Python 套件管理器安裝IronPDF庫。 打開命令列介面並執行以下命令:
pip install ironpdfpip install ironpdfSHELL注意:必須將 Python 加入 PATH 環境變數才能使用 pip 指令。
3.整合開發環境 (IDE):雖然並非絕對必要,但使用 IDE 可以大幅提升您的開發體驗。 它提供了程式碼自動完成、調試和更簡化的工作流程等功能。 PyCharm 是 Python 開發中一款受歡迎的 IDE。 您可以從 JetBrains 網站https://www.jetbrains.com/pycharm/下載並安裝 PyCharm。 4.文字編輯器:或者,如果您喜歡使用輕量級的文字編輯器,您可以選擇任何文字編輯器,例如 Visual Studio Code、Sublime Text 或 Atom。 這些編輯器為 Python 開發提供了語法高亮和其他實用功能。 你也可以使用 Python 自帶的 IDLE 應用程式。
使用 PyCharm 建立 Python 項目
安裝 PyCharm IDE 後,請依照下列步驟建立一個 PyCharm Python 專案:
1.啟動 PyCharm:從系統應用程式啟動器或桌面捷徑開啟 PyCharm。 2.建立新專案:點選"建立新專案"或開啟一個現有的 Python 專案。
**PyCharm IDE**3.配置項目設定:為您的專案提供名稱,並選擇建立專案目錄的位置。 為您的專案選擇 Python 解釋器。 然後點擊"創建"。
**在 PyCharm 中建立一個新的 Python 項目**4.建立原始檔案: PyCharm 將建立專案結構,包括一個主 Python 檔案和一個用於存放其他來源檔案的目錄。 開始編寫程式碼,然後按一下執行按鈕或按 Shift+F10 執行腳本。
使用IronPDF在 Python 中從 PDF 中提取文本
現在讓我們深入了解使用 Python 程式語言中的IronPDF從 PDF 檔案中提取純文字的步驟。
導入所需庫
首先,在你的Python腳本中導入必要的函式庫。 在這種情況下,程式碼範例需要匯入IronPDF庫,該庫提供了處理 PDF 文件的功能。
import ironpdfimport ironpdf設定許可證密鑰
要使用IronPDF從 PDF 文件中提取全文,您需要擁有IronPDF許可證。 使用以下命令應用許可證或試用金鑰:
# Apply your license key
License.LicenseKey = "YOUR-LICENSE-KEY-HERE"# Apply your license key
License.LicenseKey = "YOUR-LICENSE-KEY-HERE"注意:如果沒有許可證密鑰, IronPDF只能從 PDF 文件中提取少量字元。您可以透過購買IronPDF或註冊免費試用版來取得許可證密鑰。
載入 PDF 文件
接下來,使用IronPDF的 PdfDocument.FromFile() 方法載入 PDF 檔案。 請將 PDF 檔案的路徑作為參數傳遞給此方法。 這將把 PDF 檔案載入到 PdfDocument 物件中。
pdf = ironpdf.PdfDocument.FromFile("path/to/your/pdf_file.pdf")pdf = ironpdf.PdfDocument.FromFile("path/to/your/pdf_file.pdf")輸入檔
若要從輸入的 PDF 檔案中提取文字並將其列印到螢幕上,請使用以下文件:
 輸入檔
輸入檔
從 PDF 文件中提取文本
PDF 文件載入完成後,您可以使用 ExtractText 方法來擷取文字內容。 此方法將提取的文字作為字串傳回。
text = pdf.ExtractText()text = pdf.ExtractText()處理並利用提取的文本
現在您已經從 PDF 中提取了文本,可以根據您的需求進行處理和利用。 您可以執行諸如解析文字、分析文字、將文字儲存在資料庫中或用於進一步資料處理等任務。
# Process and utilize the extracted text
print(text)
# Perform other operations with the extracted text# Process and utilize the extracted text
print(text)
# Perform other operations with the extracted text輸出
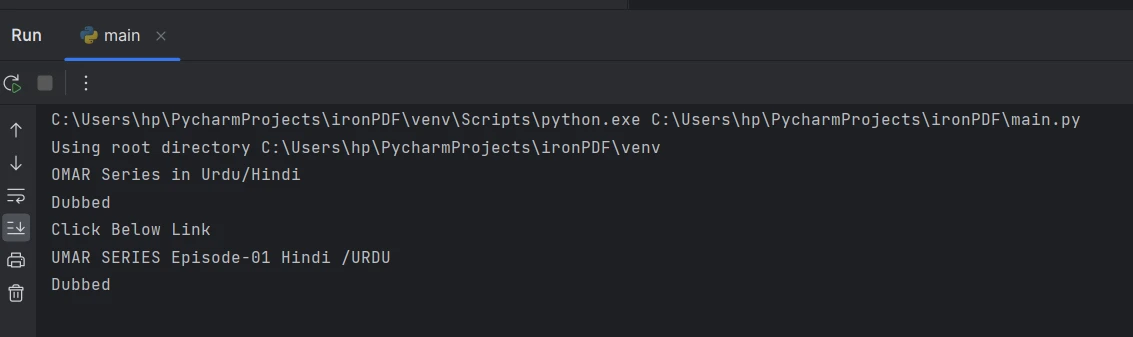 從控制台提取的文本
從控制台提取的文本
從 PDF 文件中的特定頁面提取文本
IronPDF也提供了一種便捷的方法來從 PDF 文件的特定頁面中提取文字。本節將探討如何使用IronPDF提供的 ExtractTextFromPage 方法從特定頁面擷取文字。
以下程式碼示範如何從特定頁面中提取文字:
# Extract text from a specific page in the document
page_2_text = pdf.ExtractTextFromPage(1)# Extract text from a specific page in the document
page_2_text = pdf.ExtractTextFromPage(1)在上面的範例程式碼中,pdf 表示載入 PDF 文件後所獲得的 PdfDocument 物件。 ExtractTextFromPage() 方法用於從指定頁面提取文本,該指定頁面由作為參數傳遞的頁面索引指示。 在這種情況下,文字是從第二頁或頁碼 2 中提取的,對應於頁碼索引 1。
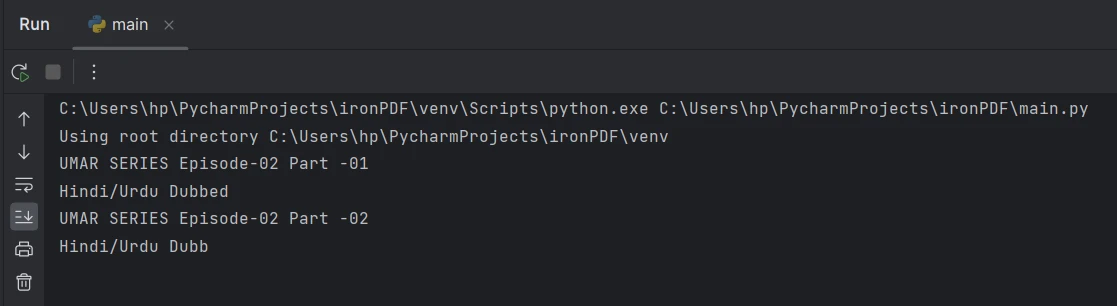 從第 2 頁擷取文本
從第 2 頁擷取文本
結論
本文探討如何使用 Python 中的IronPDF從 PDF 檔案中提取文字。 它涵蓋了必要的步驟,包括匯入所需的庫、載入 PDF 文件、提取文字內容以及處理提取的文字。
IronPDF 強大的文本提取功能,可自動從 PDF 中提取和進一步處理文本,使您能夠輕鬆處理和分析 PDF 文件中的文本資訊。 它直覺的 API 和強大的功能使其成為 Python 開發中各種 PDF 相關任務的理想選擇。
IronPDF可免費用於開發用途,但商業用途需要獲得許可。 若要在生產模式下進行測試,請取得免費試用版。 下載並安裝最新版本的IronPDF for Python ,然後試試看。
常見問題解答
我如何使用 Python 提取整個 PDF 文檔中的文本?
您可以通過使用 IronPDF 的 PdfDocument.FromFile() 方法加載 PDF,然後調用 ExtractText() 方法來提取整個 PDF 文檔中的文本內容。
在 Python 中,從特定頁面提取 PDF 文本的過程是什麼?
要從 PDF 的特定頁面提取文本,可以使用 IronPDF 的 ExtractTextFromPage() 方法,這允許您指定頁面索引以從該特定頁面檢索文本。
我該如何安裝 IronPDF 的 Python 庫?
通過運行命令 pip install ironpdf 使用 pip 包管理器安裝 IronPDF 的 Python 庫。
在 Python 中從 PDF 提取文本的前提條件是什麼?
前提條件包括在您的系統上安裝 Python,通過 pip 安裝 IronPDF,以及使用如 PyCharm 的集成開發環境。
IronPDF 的 Python 庫有免費版嗎?
IronPDF 在開發中免費使用,但商業用途需要許可證。提供免費試用以便在生產模式下測試該庫。
使用 IronPDF 從 PDF 提取完整文本需要許可證嗎?
是的,從 PDF 使用 IronPDF 完整提取文本需要許可證鑰。在未獲許可時,提取僅限於幾個字符。
IronPDF for Python 的一些關鍵功能是什麼?
IronPDF for Python 的關鍵功能包括創建和編輯 PDF、提取文本、元數據和圖像,轉換 PDF 到其他格式,以及添加如密碼等安全功能。
IronPDF for Python 可以幫助自動化 PDF 數據提取嗎?
是的,IronPDF 提供如 FromFile 及 ExtractText 等方法,有助於實現 PDF 數據提取自動化,有助於數據分析和操作。
推薦哪個 IDE 來使用 IronPDF 在 Python 中?
由於 PyCharm 的代碼完成、調試工具和流暢的工作流程,推薦在 Python 中使用 IronPDF 的開發。
IronPDF 如何提高我在處理 PDF 文檔時的工作效率?
IronPDF 通過提供一個直觀的 API,用於文本提取、PDF 創建和編輯、格式轉換及安全設置,優化了各種 PDF 相關任務的工作流程。
















