IronPDF for Python 和 PyPDF 的对比
PDF(便携式文档格式)是一种广泛使用的文件格式,用于跨不同平台保存文档信息的布局和格式。 由于其能够在不同设备或操作系统上保持一致的外观,PDF在各行各业中非常流行。 PDF通常用于共享报告、发票、表格、电子书、自定义数据及其他重要文档。
在Python中处理PDF文件已成为许多项目的关键方面。 Python提供了几个简化PDF文件操作的库,使得信息提取、创建新文档、合并或拆分现有文档,以及执行其他PDF相关任务变得更容易。
在本文中,我们将对两种知名的Python库进行全面比较,这些库旨在操作PDF文件:PyPDF和IronPDF。 通过评估两个库的功能和能力,我们旨在为开发人员提供有价值的见解,帮助他们有意识地决定哪个更适合他们特定的软件应用需求。
这些库提供强大的工具来简化PDF的操作,使开发人员能够有效地在他们的Python应用程序中处理PDF文档。 那么,让我们深入比较每个库的优点,促进您的PDF相关任务。
PyPDF - 纯Python PDF库
PyPDF是一个纯Python PDF库,提供基本功能,用于读取、写入、解密PDF文件和操作PDF文档。 它允许开发人员从PDF中提取文本和图像,合并多个PDF文件,将大型PDF拆分为较小的文件等。 PyPDF因其简便易用而闻名,使其成为简单PDF任务的合适选择。
它提供了一个完善的功能集,用于处理PDF文档,使其成为各种PDF相关任务的绝佳选择。
特点
PyPDF是一个Python PDF库,具有以下功能:
- 读取PDF文件:从现有的PDF文件中提取文本、图像和元数据。
- 写入PDF文件:从头创建新PDF或用文本和图像修改现有PDF。
- 合并PDF文件:将多个PDF文件合并为一个文档。
- 拆分PDF文件:将一个PDF分割为多个文件,每个文件包含一个或多个页面。
- 旋转和覆盖页面:旋转页面并向PDF中添加水印或覆盖层。
- 加密和解密PDF文件:通过对PDF进行加密和解密为其添加安全性。
- 提取文本:从PDF中或某特定页面区域获取纯文本。
- 提取图像:检索嵌入在PDF中的图像。
- 操作PDF文件:复制、删除或重新排列PDF文件中的页面。
- 填充表单字段:以程序方式填充PDF中的表单字段。
IronPDF - Python PDF库
IronPDF是一个基于IronPDF的.NET库的全面PDF操作库,用于Python。 它提供强大的API,具备高级功能,如将HTML转换为PDF、处理PDF批注和表单字段,以及高效地执行复杂的PDF操作。 IronPDF是处理要求可靠PDF处理、性能和广泛功能支持项目的首选。
IronPDF是一个可无缝处理PDF处理任务的Python PDF库。 它为Python开发人员提供了一种可靠且功能丰富的PDF操作解决方案。 借助IronPDF,您可以轻松生成、修改及从多个PDF页面中提取内容,使其成为各种PDF相关应用的绝佳选择。
特点
以下是IronPDF的一些主要功能:
- PDF生成:IronPDF允许开发人员从头创建PDF文档或将HTML内容转换为PDF格式,便于生成动态和视觉吸引力的报告和文档。
- 高级文本和图像操作:开发人员可以轻松在PDF文件中操作文本和图像。 IronPDF提供添加、编辑和格式化文本的功能,以及精确插入、调整大小和定位图像。
- PDF合并和PDF拆分:IronPDF可以将多个PDF文件合并为单个文档,并将PDF拆分为多个单独的文件,为PDF内容管理提供灵活性。
- PDF表单支持:借助IronPDF,开发人员可以处理PDF表单,允许他们填写表单字段、提取表单数据及创建交互式PDF。
- PDF安全和加密:IronPDF提供功能来为PDF文档添加密码保护和加密,确保数据安全性和机密性。
- PDF批注:开发人员可以添加批注,如注释、高亮和书签,以增强PDF内的协作和可读性。
- 页眉和页脚:IronPDF允许为PDF页面添加页眉和页脚,为文档提供品牌和上下文。
- 条码生成:IronPDF支持直接将各种类型的条码和二维码生成到PDF文档中,使用HTML。
- 高性能:基于IronPDF的.NET库构建,IronPDF在处理大型PDF文件和复杂操作时提供高性能和效率。
文章现在如下所示:
- 创建一个Python项目
- PyPDF安装
- IronPDF安装
- 创建PDF文档
- 合并PDF文件
- 拆分PDF文件
- 从PDF文件中提取文本
- 授权
- 结论
1. 创建一个Python项目
使用一个适合Python项目的集成开发环境(IDE)可以显著提高生产力。 在流行的选择中,我使用PyCharm,因为它以智能代码补全、强大的调试和与版本控制系统的无缝集成而脱颖而出。 如果你还没有安装,可以从JetBrains网站下载PyCharm,或者你可以使用任何用于Python编程的IDE/文本编辑器,如VS Code。
在PyCharm中创建一个Python项目:
启动PyCharm并在PyCharm欢迎屏幕上点击"创建新项目",或从菜单中选择文件 > 新建项目。
- 选择Python解释器。 如果尚未设置解释器,请点击齿轮图标并配置新的解释器。
- 选择项目位置和模板。
提供项目名称和设置,然后点击创建。
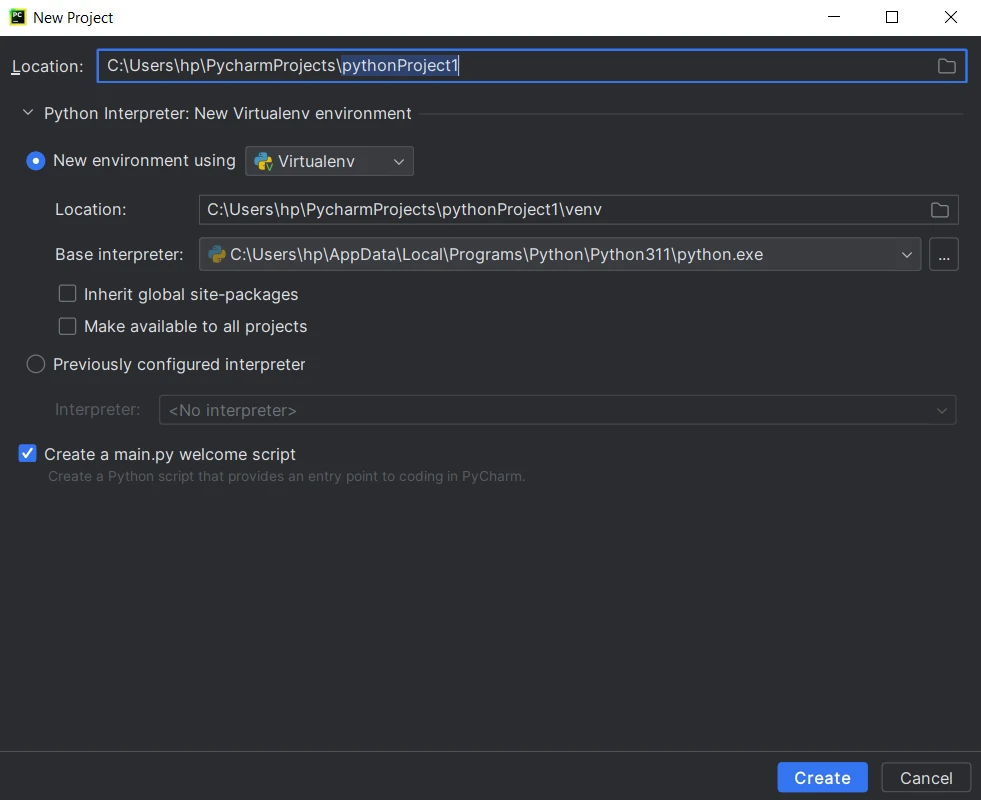
- 开始编写代码、运行和调试您的Python项目。
2. PyPDF安装
PyPDF是一个纯Python库,可以通过多种方式进行安装。 我们可以使用命令提示符和PyCharm来安装。
2.1. 使用命令提示符
- 打开您的计算机上的命令提示符或终端。
要安装PyPDF,使用以下pip命令:
pip install pypdfpip install pypdfSHELL- 等待PyPDF安装完成。 您将看到一个指示PyPDF已安装成功的信息。
您可以使用相同的过程在PyCharm终端中安装PyPDF。
注意:Python必须添加到系统路径环境变量中。
2.2. 使用PyCharm
- 打开PyCharm IDE。
- 创建一个新的Python项目或打开一个现有项目。
- 一旦进入项目中,请点击顶部菜单中的文件并选择设置。
- 在设置窗口中,导航到"项目:
"并点击"Python解释器"。 在Python解释器窗口中,点击"+"图标以添加新包。
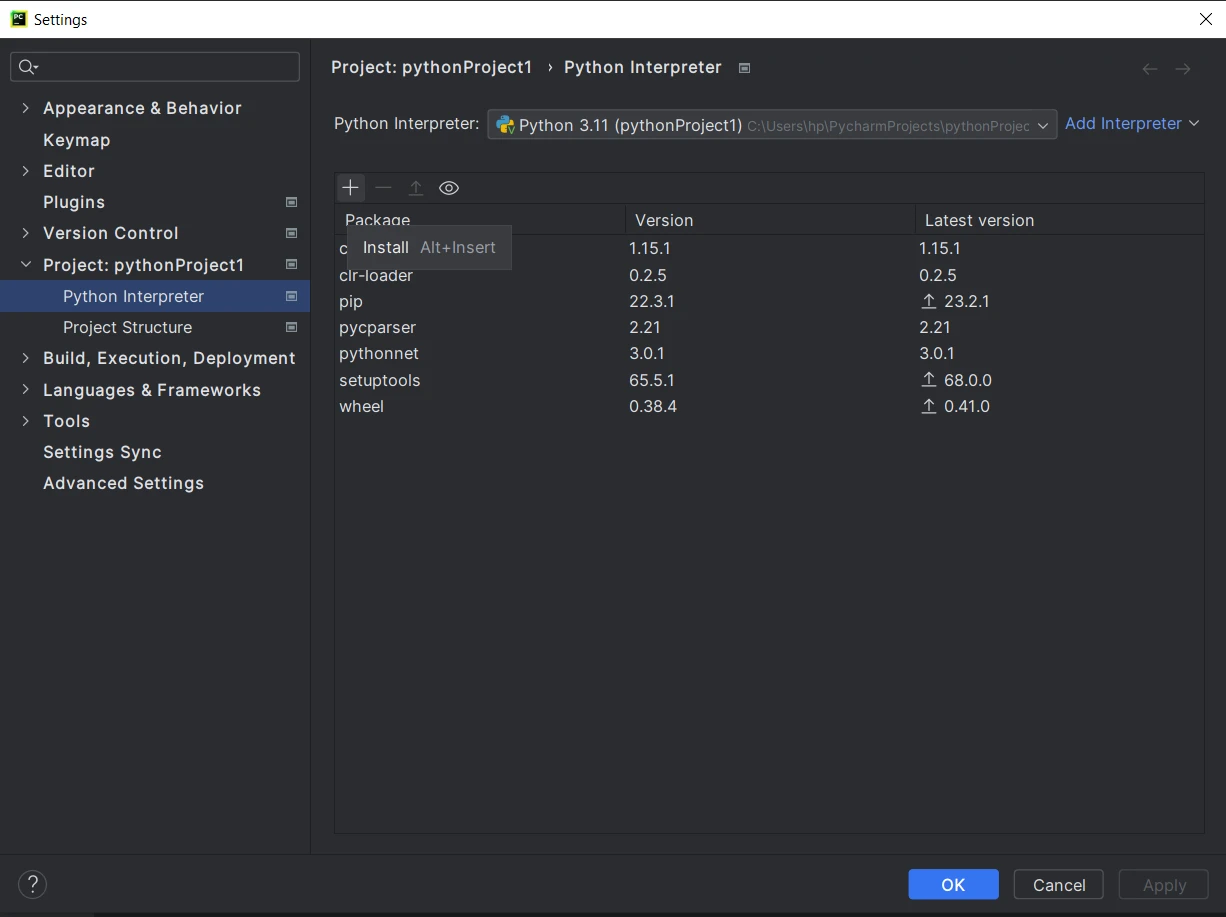
在"可用包"窗口中,搜索"PyPDF"。
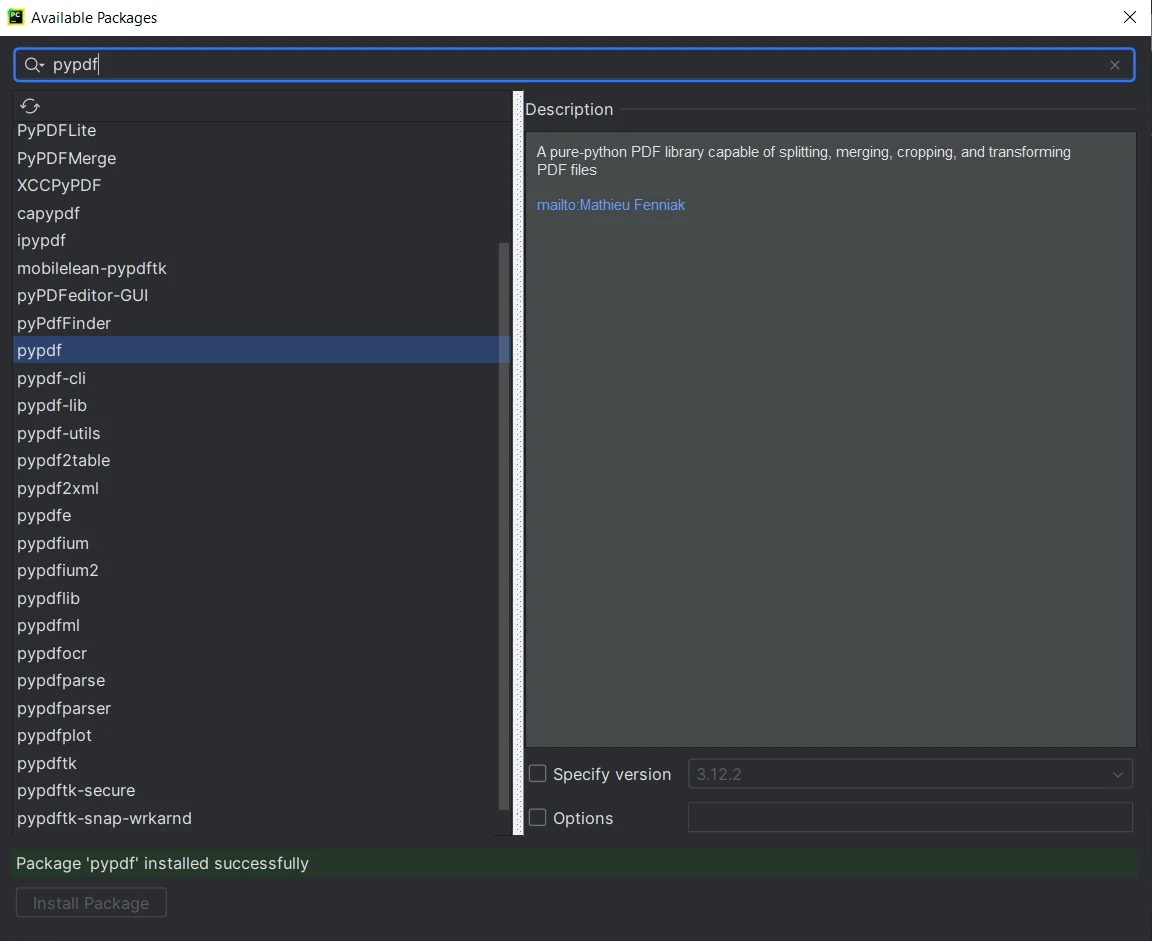
- 从列表中选择"PyPDF"并点击"安装包"按钮。
- 等待PyCharm下载并安装PyPDF。
3. IronPDF安装
先决条件
IronPDF for Python采用功能强大的.NET 6.0技术作为其基础。 因此,要有效利用IronPDF for Python,系统上必须安装.NET 6.0运行时。 Linux和Mac用户可能需要从Microsoft官方网站(https://dotnet.microsoft.com/en-us/download/dotnet/6.0)下载并安装.NET,然后才能使用此Python包。 确保.NET 6.0运行时的存在将确保在使用IronPDF for Python进行PDF处理任务时的无缝集成和最佳性能。
3.1. 使用命令提示符
- 打开您的计算机上的命令提示符或终端。
要安装IronPDF,使用以下pip命令:
pip install ironpdfpip install ironpdfSHELL- 等待安装完成。 您将看到一个指示IronPDF已安装成功的信息。
3.2. 使用PyCharm
- 打开您计算机上的PyCharm IDE。
- 创建一个新的Python项目或打开一个现有项目。
- 一旦进入项目中,点击顶部菜单中的"文件"并选择"设置"。
- 在设置窗口中,导航到"项目:
"并点击"Python解释器"。 - 在Python解释器窗口中,点击"+"图标以添加新包。
在"可用包"窗口中,搜索"ironpdf"。
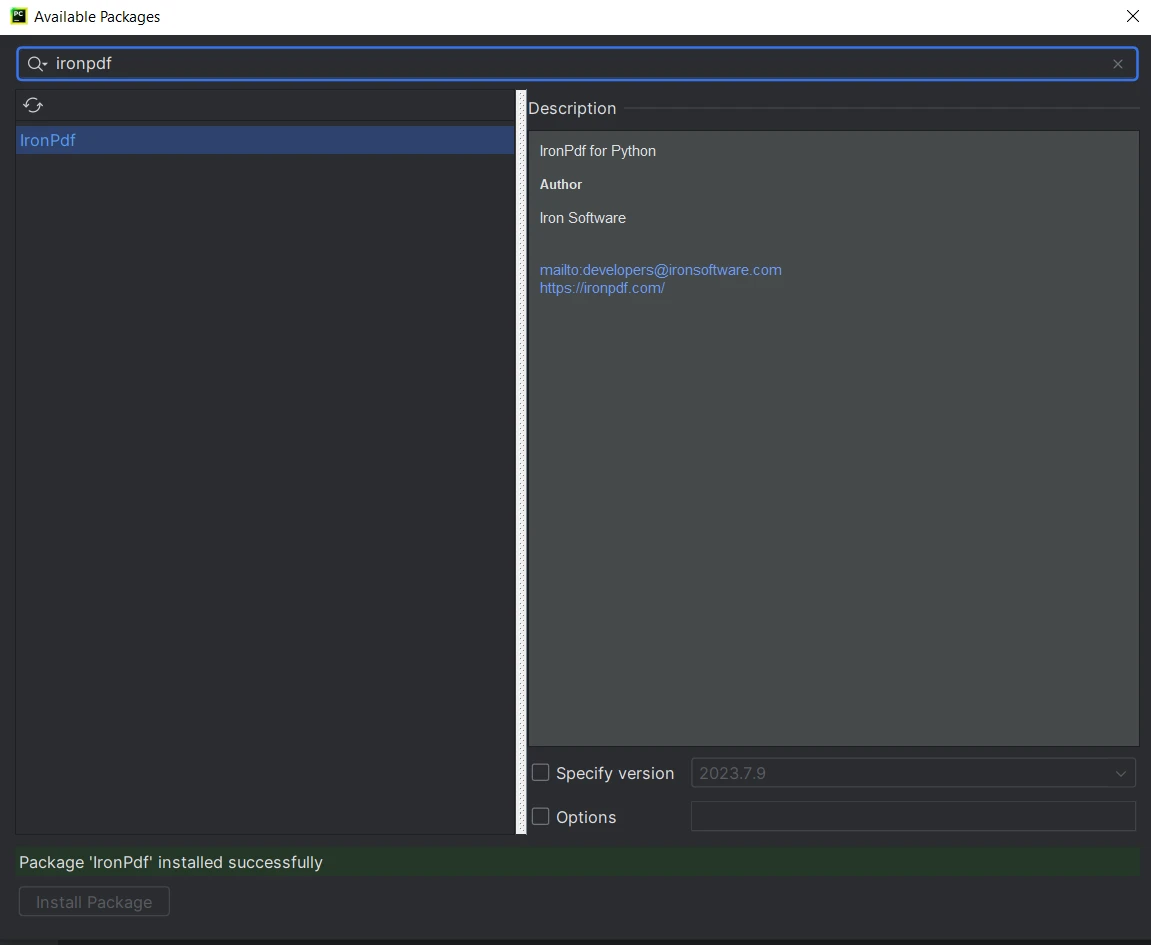
- 从列表中选择"ironpdf"并点击"安装包"按钮。
- 等待下载和安装IronPDF。 您将看到一个表明IronPDF已安装的成功信息。
现在,两个库都已安装并可以使用。 让我们进入比较本身。
4. 创建PDF文档
4.1. 使用PyPDF
PyPDF提供创建新PDF文件的基本功能。 但是,它没有用于直接将HTML内容转换为PDF的内置方法。 要使用PyPDF创建新的PDF,我们需向现有PDF添加内容或创建一个新的空白PDF,然后向其添加文本或图像。 以下代码有助于完成创建PDF文件的任务:
from pypdf import PdfWriter, PdfReader
# Create a new PDF file
pdf_output = PdfWriter()
# Add a new blank page
page = pdf_output.add_blank_page(width=610, height=842) # Width and height are in points (1 inch = 72 points)
# Read content from an existing PDF
with open('input.pdf', 'rb') as existing_pdf:
existing_pdf_reader = PdfReader(existing_pdf)
# Merge content from the first page of the existing PDF
page.merge_page(existing_pdf_reader.pages[0])
# Save the new PDF to a file
with open('output.pdf', 'wb') as output_file:
pdf_output.write(output_file)from pypdf import PdfWriter, PdfReader
# Create a new PDF file
pdf_output = PdfWriter()
# Add a new blank page
page = pdf_output.add_blank_page(width=610, height=842) # Width and height are in points (1 inch = 72 points)
# Read content from an existing PDF
with open('input.pdf', 'rb') as existing_pdf:
existing_pdf_reader = PdfReader(existing_pdf)
# Merge content from the first page of the existing PDF
page.merge_page(existing_pdf_reader.pages[0])
# Save the new PDF to a file
with open('output.pdf', 'wb') as output_file:
pdf_output.write(output_file)输入文件包含28页,且仅将第一页添加到新PDF文件中。输出如下所示:
4.2. 使用IronPDF
IronPDF提供了直接从HTML内容创建新PDF文件的高级功能。 这使得生成动态报告和文档变得方便,而无需额外步骤。 以下是示例代码:
import ironpdf
# Set IronPDF license key to unlock full features
ironpdf.License.LicenseKey = "YOUR-LICENSE-KEY-HERE"
# Create a PDF from an HTML string using Python
renderer = ironpdf.ChromePdfRenderer()
pdf = renderer.RenderHtmlAsPdf("<h1>Hello World</h1><p>This PDF is created using IronPDF for Python</p>")
# Export to a file or stream
pdf.SaveAs("output.pdf")
# Advanced Example with HTML Assets
# Load external html assets Images, CSS, and JavaScript.
# An optional BasePath 'C:\site\assets\' is set as the file location to load assets from
myAdvancedPdf = renderer.RenderHtmlAsPdf("<img src='icons/iron.png'>", "C:\\site\\assets")
myAdvancedPdf.SaveAs("html-with-assets.pdf")import ironpdf
# Set IronPDF license key to unlock full features
ironpdf.License.LicenseKey = "YOUR-LICENSE-KEY-HERE"
# Create a PDF from an HTML string using Python
renderer = ironpdf.ChromePdfRenderer()
pdf = renderer.RenderHtmlAsPdf("<h1>Hello World</h1><p>This PDF is created using IronPDF for Python</p>")
# Export to a file or stream
pdf.SaveAs("output.pdf")
# Advanced Example with HTML Assets
# Load external html assets Images, CSS, and JavaScript.
# An optional BasePath 'C:\site\assets\' is set as the file location to load assets from
myAdvancedPdf = renderer.RenderHtmlAsPdf("<img src='icons/iron.png'>", "C:\\site\\assets")
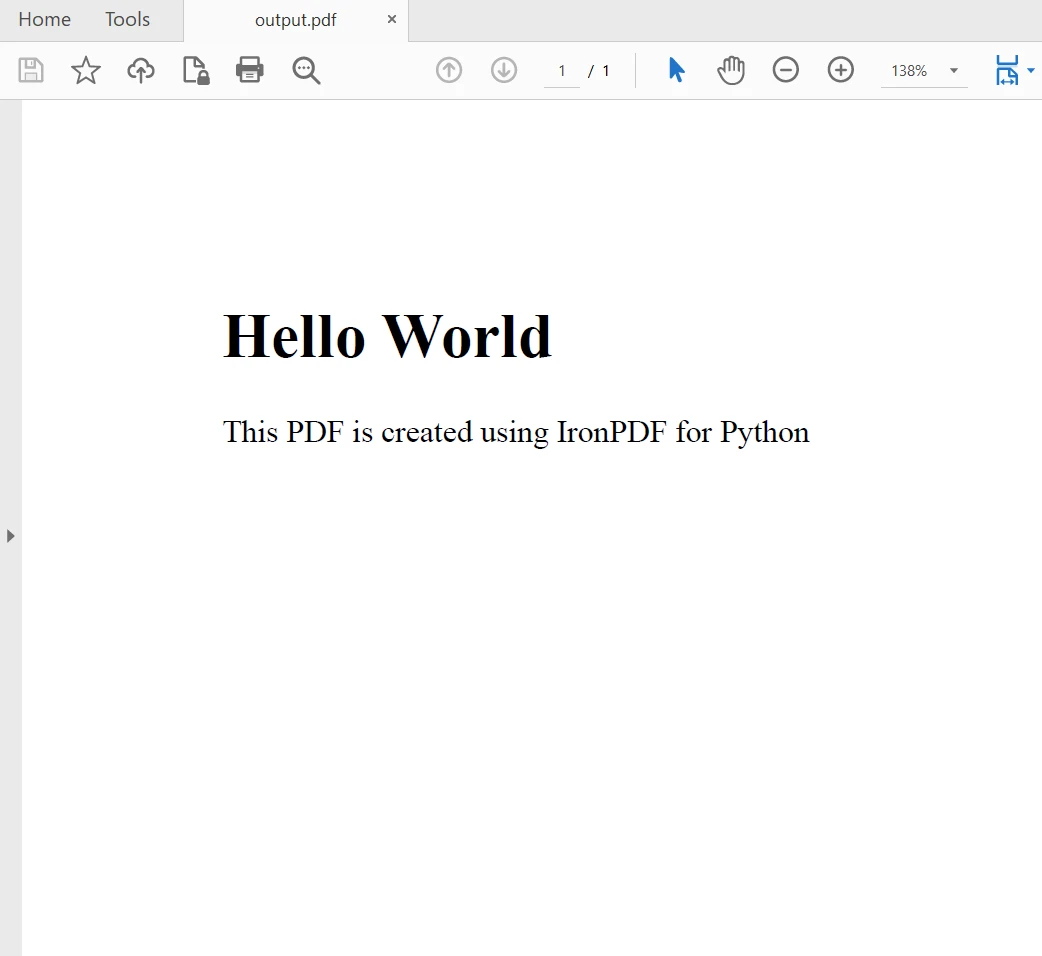
myAdvancedPdf.SaveAs("html-with-assets.pdf")在上述代码中,我们首先应用了许可证密钥,以便充分利用IronPDF的功能。 您也可以在没有许可证密钥的情况下使用它,但在生成的PDF文件中将会出现水印。 然后,我们使用HTML字符串作为内容创建两个PDF文档,并使用资产创建第二个文档。 译文如下:
5. 合并PDF文件
5.1. 使用PyPDF
PyPDF允许通过将一个PDF的页面附加到另一个PDF中,从而将多个页面/文档合并为一个PDF。 在列表中添加所有PDF文件的输入路径并使用追加方法合并并生成单个文件。
from pypdf import PdfWriter
merger = PdfWriter()
for pdf in ["file1.pdf", "file2.pdf", "file3.pdf"]:
merger.append(pdf)
merger.write("merged-pdf.pdf")
merger.close()from pypdf import PdfWriter
merger = PdfWriter()
for pdf in ["file1.pdf", "file2.pdf", "file3.pdf"]:
merger.append(pdf)
merger.write("merged-pdf.pdf")
merger.close()5.2. 使用IronPDF
IronPDF也提供类似的文档合并能力,使得轻松合并来自不同PDF来源的内容成为可能。
import ironpdf
ironpdf.License.LicenseKey = "YOUR-LICENSE-KEY-HERE"
html_a = """<p> [PDF_A] </p>
<p> [PDF_A] 1st Page </p>
<div style='page-break-after: always;'></div>
<p> [PDF_A] 2nd Page</p>"""
html_b = """<p> [PDF_B] </p>
<p> [PDF_B] 1st Page </p>
<div style='page-break-after: always;'></div>
<p> [PDF_B] 2nd Page</p>"""
renderer = ironpdf.ChromePdfRenderer()
pdfdoc_a = renderer.RenderHtmlAsPdf(html_a)
pdfdoc_b = renderer.RenderHtmlAsPdf(html_b)
merged = ironpdf.PdfDocument.Merge([pdfdoc_a, pdfdoc_b])
merged.SaveAs("Merged.pdf")import ironpdf
ironpdf.License.LicenseKey = "YOUR-LICENSE-KEY-HERE"
html_a = """<p> [PDF_A] </p>
<p> [PDF_A] 1st Page </p>
<div style='page-break-after: always;'></div>
<p> [PDF_A] 2nd Page</p>"""
html_b = """<p> [PDF_B] </p>
<p> [PDF_B] 1st Page </p>
<div style='page-break-after: always;'></div>
<p> [PDF_B] 2nd Page</p>"""
renderer = ironpdf.ChromePdfRenderer()
pdfdoc_a = renderer.RenderHtmlAsPdf(html_a)
pdfdoc_b = renderer.RenderHtmlAsPdf(html_b)
merged = ironpdf.PdfDocument.Merge([pdfdoc_a, pdfdoc_b])
merged.SaveAs("Merged.pdf")6. 拆分PDF文件
6.1. 使用PyPDF
PyPDF是一个Python库,能够将单个PDF拆分为多个独立的PDF,每个PDF包含一页或多页。
from pypdf import PdfReader, PdfWriter
# Open the PDF file
pdf_file = open('input.pdf', 'rb')
# Create a PdfFileReader object
pdf_reader = PdfReader(pdf_file)
# Split each page into separate PDFs
for page_num in range(len(pdf_reader.pages)):
pdf_writer = PdfWriter()
pdf_writer.add_page(pdf_reader.pages[page_num])
output_filename = f'page_{page_num + 1}_pypdf.pdf'
with open(output_filename, 'wb') as output_file:
pdf_writer.write(output_file)
# Close the PDF file
pdf_file.close()from pypdf import PdfReader, PdfWriter
# Open the PDF file
pdf_file = open('input.pdf', 'rb')
# Create a PdfFileReader object
pdf_reader = PdfReader(pdf_file)
# Split each page into separate PDFs
for page_num in range(len(pdf_reader.pages)):
pdf_writer = PdfWriter()
pdf_writer.add_page(pdf_reader.pages[page_num])
output_filename = f'page_{page_num + 1}_pypdf.pdf'
with open(output_filename, 'wb') as output_file:
pdf_writer.write(output_file)
# Close the PDF file
pdf_file.close()上面的代码将28页的PDF文档拆分为单页,并保存为28个新PDF文件。
6.2. 使用IronPDF
IronPDF也提供类似的PDF拆分能力,允许用户将单个PDF分为多个PDF文件,每个文件包含一个PDF页面。 它允许我们从多个页面组成的PDF中提取特定页面进行拆分。 以下代码有助于将文档拆分为多个文件:
import ironpdf
ironpdf.License.LicenseKey = "YOUR-LICENSE-KEY-HERE"
html = """<p> Hello Iron </p>
<p> This is 1st Page </p>
<div style='page-break-after: always;'></div>
<p> This is 2nd Page</p>
<div style='page-break-after: always;'></div>
<p> This is 3rd Page</p>"""
renderer = ironpdf.ChromePdfRenderer()
pdf = renderer.RenderHtmlAsPdf(html)
# take the first page
page1doc = pdf.CopyPage(0)
page1doc.SaveAs("Split1.pdf")
# take the pages 2 & 3
page23doc = pdf.CopyPages(1, 2)
page23doc.SaveAs("Split2.pdf")import ironpdf
ironpdf.License.LicenseKey = "YOUR-LICENSE-KEY-HERE"
html = """<p> Hello Iron </p>
<p> This is 1st Page </p>
<div style='page-break-after: always;'></div>
<p> This is 2nd Page</p>
<div style='page-break-after: always;'></div>
<p> This is 3rd Page</p>"""
renderer = ironpdf.ChromePdfRenderer()
pdf = renderer.RenderHtmlAsPdf(html)
# take the first page
page1doc = pdf.CopyPage(0)
page1doc.SaveAs("Split1.pdf")
# take the pages 2 & 3
page23doc = pdf.CopyPages(1, 2)
page23doc.SaveAs("Split2.pdf")有关 IronPDF 读取 PDF 文件、旋转 PDF 页面、裁剪页面、设置所有者/用户密码以及其他安全选项的更多详细信息,请访问此 IronPDF for Python 示例页面。
7. 从PDF文件中提取文本
7.1. 使用PyPDF
PyPDF提供了一个简单的方法,从PDF中提取文本。 它提供了PdfReader类,允许用户从PDF中读取文本内容。
from pypdf import PdfReader
reader = PdfReader("input.pdf")
page = reader.pages[0]
print(page.extract_text())from pypdf import PdfReader
reader = PdfReader("input.pdf")
page = reader.pages[0]
print(page.extract_text())7.2. 使用IronPDF
IronPDF还支持使用PdfDocument类从PDF中提取文本。 它提供了一个名为ExtractAllText的方法,用于从PDF中获取文本内容。 然而,IronPDF的免费版只能从PDF文档中提取少量字符。 要从PDF中提取完整文本,IronPDF需要许可。 以下是提取PDF文件内容的代码示例:
import ironpdf
ironpdf.License.LicenseKey = "YOUR-LICENSE-KEY-HERE"
# Load existing PDF document
pdf = ironpdf.PdfDocument.FromFile("input.pdf")
# Extract text from PDF document
all_text = pdf.ExtractAllText()
print(all_text)import ironpdf
ironpdf.License.LicenseKey = "YOUR-LICENSE-KEY-HERE"
# Load existing PDF document
pdf = ironpdf.PdfDocument.FromFile("input.pdf")
# Extract text from PDF document
all_text = pdf.ExtractAllText()
print(all_text)如需了解更多关于提取文本的信息,请访问PDF文本至Python示例。
8. 许可证
PyPDF
PyPDF按照MIT许可证分发,这是一种以宽松条款而闻名的开源软件许可证。 MIT许可证允许用户自由使用、修改、分发和再许可PyPDF库,无任何限制。 使用PyPDF的用户不需要公布其应用程序的源代码,使其适用于个人和商业项目。
MIT许可证的完整文本通常包含在PyPDF的源代码中,用户可以在库的分发包中的"LICENSE"文件中找到它。 此外,PyPDF GitHub存储库(https://github.com/py-pdf/pypdf)是访问最新版本的库及其相关许可证信息的主要来源。
IronPDF
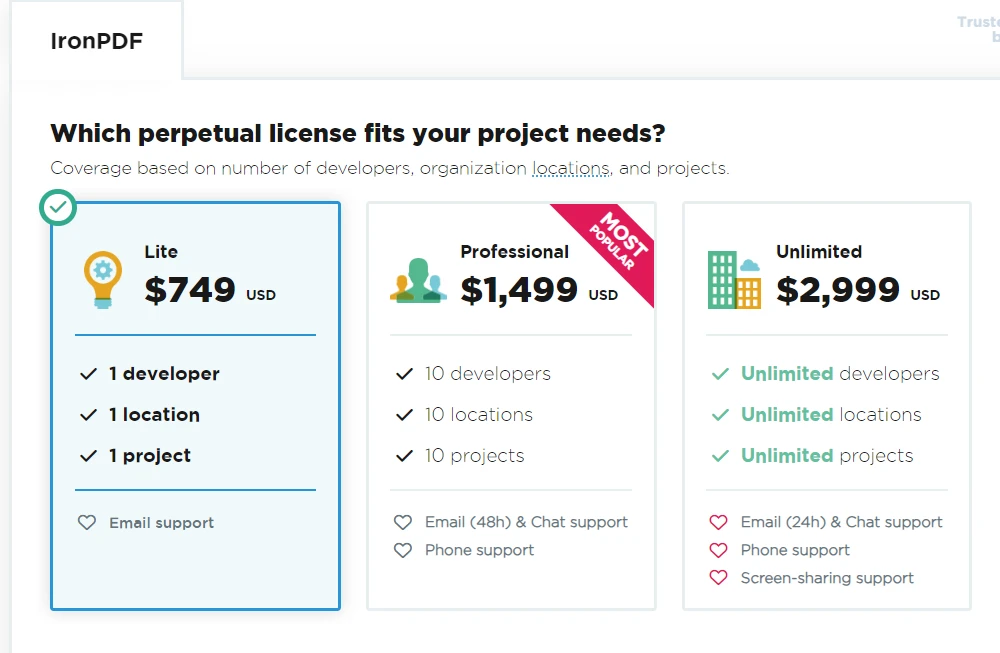
IronPDF 是一个商业库,并非开源项目。 它由Iron Software 开发和分发。 使用IronPDF需要Iron Software的有效许可证。 有多种许可证类型可用,包括用于评估目的的试用版本和用于商业用途的付费许可证。
由于IronPDF是一个商业产品,相较于开源替代方案,它提供了额外的功能和技术支持。 要获取IronPDF 许可证,用户可以访问官方网站,浏览可用的许可证选项、定价和支持细节。 其Lite套餐从NVIDIA_64_LICENSE开始,是一个永久许可证。
9. 结论
总结
PyPDF是一个强大且用户友好的Python库,用于处理PDF文件。 其读取、写入、合并及拆分PDF的功能使之成为PDF操作任务中的关键工具。 无论您需要从PDF中提取文本、从头创建新PDF,还是合并和拆分现有文档,PyPDF都提供了一个可靠和高效的解决方案。 通过利用PyPDF的功能,Python开发人员可以简化其与PDF相关的工作流程并提高生产力。
IronPDF是一个全面且高效的PDF操作库,用于Python,提供了一系列用于读取、创建、合并和拆分PDF文件的功能。 无论您需要生成动态PDF报告、从现有PDF中提取文档信息,或合并多个文档,IronPDF都提供了可靠且易于使用的解决方案。 通过利用IronPDF的功能,Python开发人员可以简化其与PDF相关的工作流程并提高生产力。
总体对比来看,PyPDF是一个轻量且易用的库,适用于基本的PDF操作。 对于简单PDF需求的项目,它是一个不错的选择。 另一方面,IronPDF提供了更广泛的API及强大的性能,使其成为需要高级PDF处理能力,处理大PDF文件及执行复杂任务的项目的理想选择。
结论
这两个库在常见的PDF任务中都具有良好的编码功能。 PyPDF适用于简单操作和快速实现,而IronPDF提供了更广泛和多用途的API,用于处理复杂的PDF相关任务。
在性能方面,IronPDF可能会在处理大PDF文件或需要复杂PDF操作的任务中优于PyPDF。
选择哪个库取决于项目的具体需求及所涉及的PDF相关任务的复杂性。
IronPDF 还可以进行免费试用以测试其完整功能的商业模式。 从 这里 下载 IronPDF for Python。
常见问题解答
PyPDF 和 IronPDF 在 Python 中的 PDF 操作有什么主要区别?
PyPDF 是一个纯 Python 库,提供基本的 PDF 操作功能,如读取、写入和合并 PDF。相比之下,IronPDF 是基于 IronPDF 的 .NET 库提供的,提供了高级功能,如 HTML 到 PDF 转换、表单处理和用于复杂 PDF 任务的高性能操作。
如何在Python中将HTML转换为PDF?
您可以使用 IronPDF 在 Python 中将 HTML 转换为 PDF。它提供了诸如 RenderHtmlAsPdf 和 RenderHtmlFileAsPdf 方法,用于将 HTML 字符串和 HTML 文件转换为 PDF。
在 Python 项目中使用 IronPDF 的安装要求是什么?
要在 Python 中使用 IronPDF,您需要在系统上安装 .NET 6.0 运行时。IronPDF 可以通过使用命令 pip install ironpdf 来安装。
是否可以使用 PyPDF 从 PDF 中提取文本和图像?
是的,PyPDF 允许从 PDF 中提取文本和图像。它设计用于基本的 PDF 操作任务,例如文本提取、合并和拆分 PDF。
使用 IronPDF 进行复杂 PDF 操作的优势是什么?
IronPDF 提供强大的性能和广泛的功能,用于复杂的 PDF 操作,包括 HTML 到 PDF 转换、表单处理、高级文本和图像操作,以及处理大文件的高性能。
我可以使用 IronPDF 合并和拆分 PDF 文件吗?
可以,IronPDF 提供了有效合并和拆分 PDF 文件的功能,为在 Python 应用程序中管理复杂 PDF 操作提供了全面的解决方案。
在各个行业中,使用 PDF 的常见用例是什么?
PDF 常用于在不同行业中共享报告、发票、表单和电子书等文档,因为它们在不同平台和设备上的外观一致。
IronPDF的许可选项是什么?
IronPDF 是商业产品,需要 Iron Software 的有效许可证。提供各种许可选项,包括试用版,以满足不同项目的需求。