
在 Python 中使用 WhisperX 进行转录
Python 已经巩固了其作为世界上最通用和强大的编程语言之一的地位,这主要归功于其广泛的库和框架生态系统。 在机器学习和自然语言处理(NLP)领域引起轰动的一个库是 WhisperX。 在本文中,我们将探讨 WhisperX 是什么、其关键特性以及如何在各种应用中加以利用。 此外,我们将介绍另一个强大的 Python 库 IronPDF,并通过一个实用的代码示例展示如何将其与 WhisperX 一起使用。
什么是 WhisperX?
WhisperX 是一个为语音识别和 NLP 任务设计的高级 Python 库。 它利用最先进的机器学习模型将口语转换为书面文本,具有高精度语言检测和时间准确的语音转录。 WhisperX 在需要实时翻译的应用中特别有用,如虚拟助手、自动客户服务系统和转录服务。
WhisperX 的关键特性
1.高精度: WhisperX 使用尖端算法和大型数据集来训练其模型,从而确保语音识别的高精度。 2.实时处理:该库针对实时处理进行了优化,使其成为需要立即转录和响应的应用程序的理想选择。 3.语言支持: WhisperX 支持多种语言,满足全球用户和各种使用场景的需求。 4.易于集成:凭借其完善的 API 文档,WhisperX 可以轻松集成到现有的 Python 应用程序中。 5.自定义:用户可以微调模型,以更好地适应特定的口音、方言和术语。
WhisperX 入门
要开始使用 WhisperX,您需要安装该库。 可以通过pip完成,这是Python的软件包安装工具。 假设您已安装Python和pip,您可以使用以下命令安装WhisperX:
pip install whisperxpip install whisperxWhisperX 的基本用法 - 快速自动语音识别
以下是演示如何使用 WhisperX 转录音频文件的基本示例:
import whisperx
# Initialize the WhisperX recognizer
recognizer = whisperx.Recognizer()
# Load your audio
audio_file = "path_to_your_audio_file.wav"
# Perform transcription
transcription = recognizer.transcribe(audio_file)
# Print the transcription
print("Transcription:", transcription)import whisperx
# Initialize the WhisperX recognizer
recognizer = whisperx.Recognizer()
# Load your audio
audio_file = "path_to_your_audio_file.wav"
# Perform transcription
transcription = recognizer.transcribe(audio_file)
# Print the transcription
print("Transcription:", transcription)这个简单的例子展示了如何初始化 WhisperX 识别器、加载音频并执行转录以将口语准确地转换为文本。

WhisperX 的高级特性
WhisperX 还提供诸如说话者识别等高级功能,这在多说话者环境中至关重要。 以下是如何使用此功能的示例:
import whisperx
# Initialize the WhisperX recognizer with speaker identification enabled
recognizer = whisperx.Recognizer(speaker_identification=True)
# Load your audio file
audio_file = "path_to_your_audio_file.wav"
# Perform transcription with speaker identification
transcription, speakers = recognizer.transcribe(audio_file)
# Print the transcription with speaker labels
for i, segment in enumerate(transcription):
print(f"Speaker {speakers[i]}: {segment}")import whisperx
# Initialize the WhisperX recognizer with speaker identification enabled
recognizer = whisperx.Recognizer(speaker_identification=True)
# Load your audio file
audio_file = "path_to_your_audio_file.wav"
# Perform transcription with speaker identification
transcription, speakers = recognizer.transcribe(audio_file)
# Print the transcription with speaker labels
for i, segment in enumerate(transcription):
print(f"Speaker {speakers[i]}: {segment}")在此示例中,WhisperX 不仅能转录音频,还能识别不同的说话者,并相应地对每个片段进行标记。
IronPDF for Python
虽然 WhisperX 处理的是音频转文字的转录,但通常需要以结构化和专业的格式呈现这些数据。 这就是 Python 的 IronPDF 发挥作用的地方。 IronPDF 是一个用于生成、编辑和程序化操作 PDF 文档的强大库。 它使开发人员能够从头生成 PDF,将 HTML 转换为 PDF 等。
安装 IronPDF
可以使用pip安装IronPDF:
pip install ironpdfpip install ironpdf
结合使用 WhisperX 和 IronPDF
现在让我们创建一个实用示例,演示如何使用 WhisperX 转录音频文件,然后使用 IronPDF 生成包含转录内容的 PDF 文档。
import whisperx
from ironpdf import IronPdf
# Initialize the WhisperX recognizer
recognizer = whisperx.Recognizer()
# Load your audio file
audio_file = "path_to_your_audio_file.wav"
# Perform transcription
transcription = recognizer.transcribe(audio_file)
# Create a PDF document using IronPDF
renderer = IronPdf.ChromePdfRenderer()
pdf_from_html = renderer.RenderHtmlAsPdf(f"<h1>Transcription</h1><p>{transcription}</p>")
# Save the PDF to a file
output_file = "transcription_output.pdf"
pdf_from_html.save(output_file)
print(f"Transcription saved to {output_file}")import whisperx
from ironpdf import IronPdf
# Initialize the WhisperX recognizer
recognizer = whisperx.Recognizer()
# Load your audio file
audio_file = "path_to_your_audio_file.wav"
# Perform transcription
transcription = recognizer.transcribe(audio_file)
# Create a PDF document using IronPDF
renderer = IronPdf.ChromePdfRenderer()
pdf_from_html = renderer.RenderHtmlAsPdf(f"<h1>Transcription</h1><p>{transcription}</p>")
# Save the PDF to a file
output_file = "transcription_output.pdf"
pdf_from_html.save(output_file)
print(f"Transcription saved to {output_file}")结合代码示例的解释
1.使用 WhisperX 进行转录:
* 初始化 WhisperX 识别器并加载一个音频文件。
* `transcribe`方法处理音频并返回转录文本。2.使用IronPDF创建 PDF:
* 创建`IronPdf.ChromePdfRenderer`的实例。
* 使用`RenderHtmlAsPdf`方法,将包含转录文本的HTML格式字符串添加到PDF中。
* `save`方法将PDF写入文件。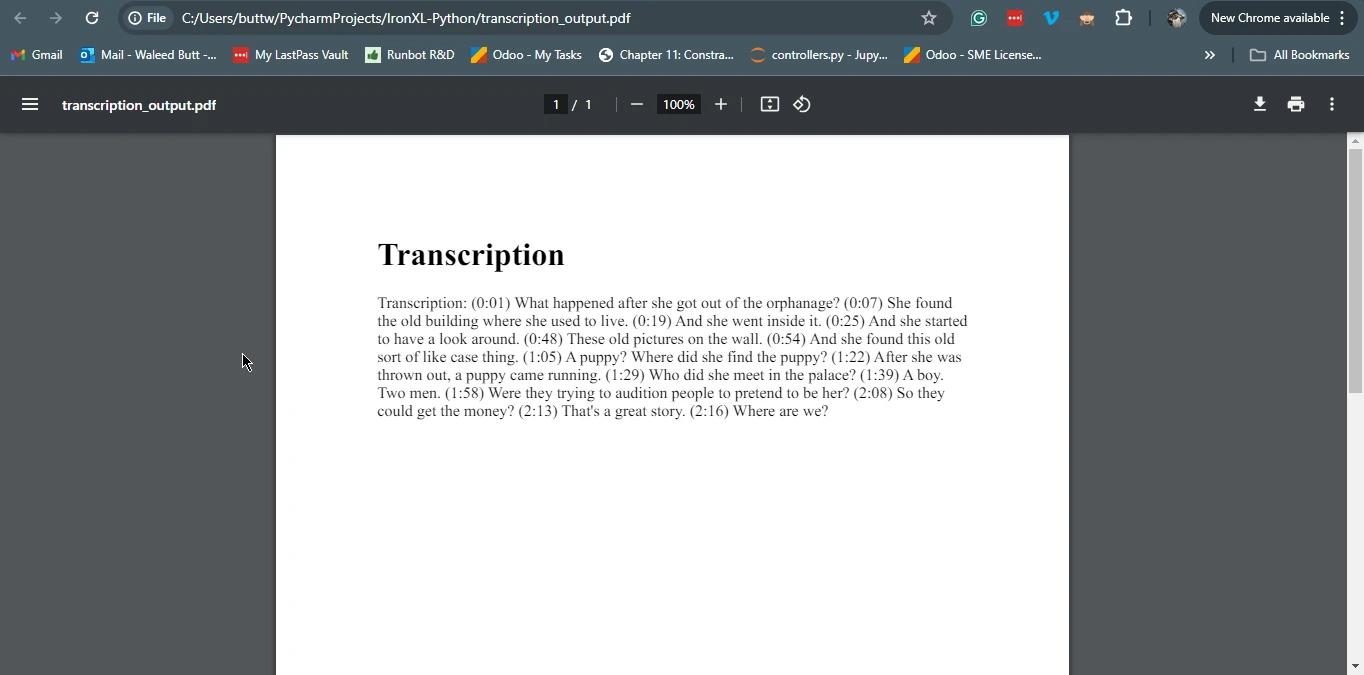
这个结合示例展示了如何利用 WhisperX 和 IronPDF 的优势,创建一个完整的解决方案,将音频转录并生成包含转录内容的 PDF 文档。
结论
WhisperX 是任何希望在应用中实现语音识别、说话者分离和转录的人的强大工具。 其高精度、实时处理能力和对多种语言的支持,使其在 NLP 领域中成为一项有价值的资产。另一方面,IronPDF 提供了一种无缝的方法来程序化创建和操作 PDF 文档。 通过结合使用 WhisperX 和 IronPDF,开发人员可以创建综合解决方案,不仅能转录音频,还能以精美、专业的格式呈现转录内容。
无论您是构建虚拟助手、客户服务聊天机器人,还是转录服务,WhisperX 和 IronPDF 都提供了增强您的应用功能并为用户提供优质结果所需的工具。
要了解有关 IronPDF 授权的更多详细信息,请访问 IronPDF 许可证页面。 此外,我们关于 HTML 到 PDF 转换的详细教程可供进一步探索。
















