
如何在 Python 中从 PDF 中提取表格
本文将演示如何使用 IronPDF,一个强大的 PDF 处理库,从任何 PDF 文件中的复杂表格中轻松提取数据。
IronPDF
相比其他语言,Python 为程序员提供了更多的灵活性,并允许开发人员轻松高效地设计图形用户界面。 因此,将 IronPDF 库集成到 Python 中是一个简单的过程。 为了快速、安全地创建一个功能齐全的图形用户界面,可以利用一系列预装的工具,包括 PyQt、wxWidgets、Kivy 及其他各种包和库。
IronPDF 简化了 Python 的网页设计和开发。 这主要是由于 Python 可用的 web 开发框架的丰富性,例如 Django、Flask 和 Pyramid。 一些著名的网站和在线服务使用了这些框架,包括 Reddit、Mozilla 和 Spotify。
- 下载从 PDF 中提取表格的 Python 模块。
- 使用 `FromFile` 方法导入 PDF 文件
- 使用 `ExtractAllText` 方法从表格中提取文本
- 遍历提取的文本以拆分行
- 将提取的文本输出到控制台或文本文件
IronPDF。 的功能
以下是 IronPDF 的一些功能:
- PDF 文件可以从多种来源创建,如 HTML、HTML5、ASP、PHP 等。 此外,图像文件可以转换为 PDF,并与 HTML 文件一起使用。
- IronPDF 使创建交互式 PDF 文档成为可能。 它提供了诸如拆分和组合 PDF 文件、从 PDF 文件中提取文本和图像、将 PDF 页面栅格化为图像、将 PDF 转换为 HTML、打印 PDF 文件、填写和提交交互式表单以及拆分和合并 PDF 文件等功能。
- 使用 IronPDF,可以从 URL 生成文档。 它还支持使用 HTML 登录表单、代理、Cookie、HTTP 头、特殊网络登录凭据、表单变量和用户代理进行登录的用户代理。
- IronPDF 程序允许对 PDF 文件进行检查和注释。
- IronPDF 能够从文档中提取图像。
- IronPDF 提供用户添加页眉、页脚、文本、照片、书签、水印等功能到文档中。
- 使用 IronPDF,您可以在新文档或现有文档中拆分和合并页面。
- 无需 Acrobat 查看器即可进行文档转换为 PDF 对象。
- IronPDF 允许从 CSS 文件中创建 PDF 文档。
- 可以使用包含媒体类型定义的 CSS 文件来创建文档。
配置 Python 环境
设置 Python
确保计算机上已安装 Python。 要下载并设置适用于您操作系统的最新版本的 Python,请访问Python 官方网站。 安装 Python 后,通过创建虚拟环境来分隔项目的需求。 借助venv模块,您可以创建和管理虚拟环境,为您的转换项目提供一个整洁有序的工作空间。
在 PyCharm 中新建项目
本教程推荐使用 PyCharm 作为 Python 开发的集成开发环境(IDE)。
启动 PyCharm IDE 后,如下图所示从菜单中选择"新建项目"。
 PyCharm IDE
PyCharm IDE
如下图所示,当您选择"新建项目"时,将出现一个新窗口,您可以在其中定义项目的位置和 Python 环境。
 创建 PyCharm 中的新项目
创建 PyCharm 中的新项目
选择项目的位置和环境后,单击创建按钮以启动项目。 可以打开新启动窗口中的 Python 文件以便输入代码。 本指南使用的是 Python 3.9。
 主 Python 文件
主 Python 文件
IronPDF。库需求
IronPDF for Python 依赖于 .NET 6.0 作为其核心技术。 因此,为了使用 IronPDF for Python,您的计算机上必须安装 .NET 6.0 运行时。 Linux 和 Mac 用户可能需要在使用该 Python 模块之前安装 .NET。 从 Microsoft 下载必要的运行时环境。
IronPDF。库安装
需要安装ironpdf包才能创建、编辑和打开".pdf"扩展名的文件。 要在 PyCharm 中安装包,打开终端窗口并键入以下命令:
pip install ironpdf
下图展示了ironpdf包的安装过程。
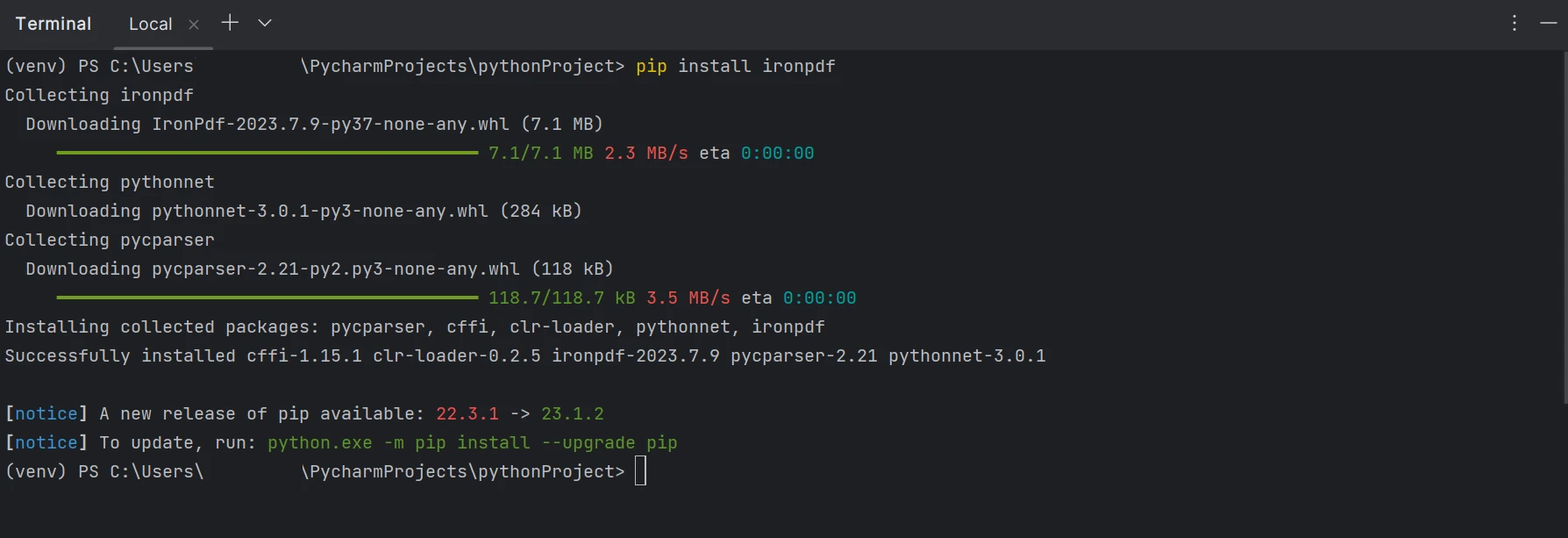 安装 IronPDF 包
安装 IronPDF 包
从 PDF 文件中提取表格数据
我们可以使用 IronPDF for Python 库轻松地从 PDF 文件中提取数据。 IronPDF 促进了文本数据的分析以及从 PDF 文件中提取表格。 以下是一个演示如何从 PDF 表格中提取数据的示例代码,使用提供的图像作为参考。
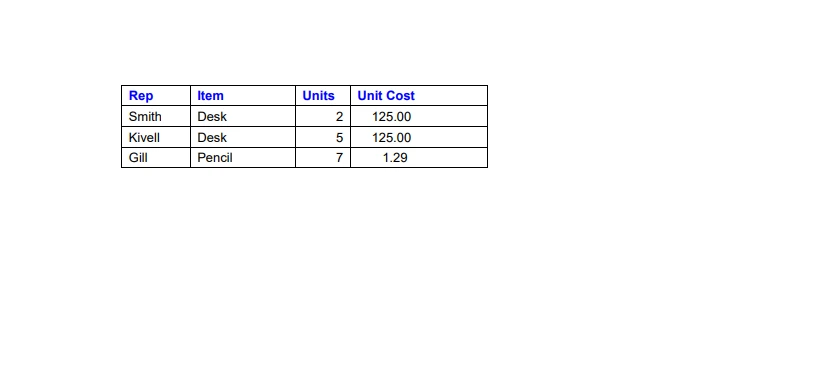 PDF 文件中的示例数据
PDF 文件中的示例数据
from ironpdf import PdfDocument
# Load the PDF document
pdf = PdfDocument.FromFile("sampleData.pdf")
# Extract all text from the PDF document
all_text = pdf.ExtractAllText()
# Split the extracted text into rows and print each row
for row in all_text.split("\n"):
print(row)from ironpdf import PdfDocument
# Load the PDF document
pdf = PdfDocument.FromFile("sampleData.pdf")
# Extract all text from the PDF document
all_text = pdf.ExtractAllText()
# Split the extracted text into rows and print each row
for row in all_text.split("\n"):
print(row)提供的代码展示了如何使用 IronPDF 通过几行 Python 代码从 PDF 文件中提取表格。 首先,我们导入 IronPDF 库以访问其功能并获取 IronPDF 的所有功能。 接下来,借助PdfDocument类,可以处理现有的PDF文件以对其执行各种操作。
使用FromFile函数时,可用的参数用于加载输入的PDF文件。 之后,ExtractAllText函数从PDF文件中的所有页面提取所有表格数据。 然后,使用split函数将提取的表格数据分成多行并显示在控制台屏幕上。
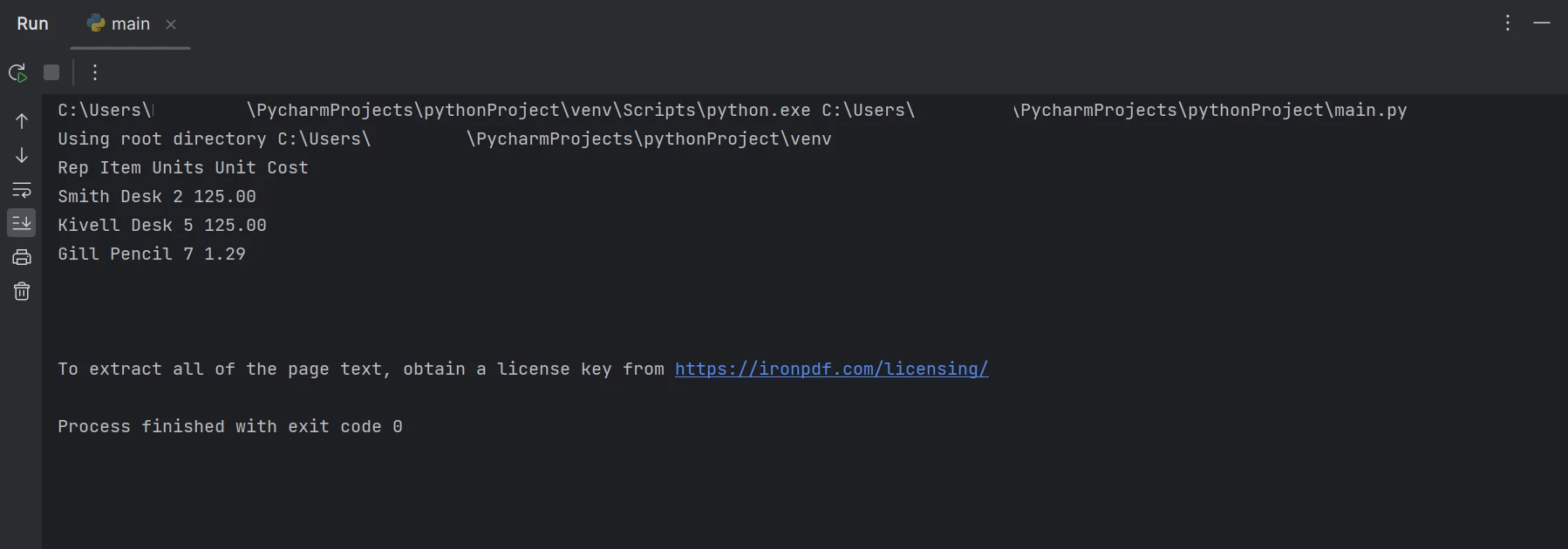 提取的数据
提取的数据
在上述输出中,数据逐行显示,展示了如何提取表格数据。 了解有关 IronPDF 的更多信息,请参阅产品文档。
结论
IronPDF 库提供了强大的安全措施,以尽量减少潜在风险并确保数据安全。 它兼容所有流行的浏览器,并不限于任何特定的浏览器。 通过 IronPDF,程序员可以通过几行代码高效地创建和读取 PDF 文件。 为了满足开发人员的多样化需求,IronPDF 库提供了多种许可选项,包括免费开发者许可证和其他可以购买的开发许可证。
Lite软件包,价格为$799,包含永久许可证、30天退款保证、一年的软件维护和升级可能性。 初次购买后不再有额外费用,并且这些许可证可以在生产、测试和开发环境中使用。 IronPDF 还提供了一些有时间和重新分发限制的免费许可证。 用户可以通过没有水印的免费试用期在真实环境中测试产品。 有关 IronPDF 试用版的成本和许可的详细信息,请点击以下许可页面。
常见问题解答
如何在 Python 中从 PDF 中提取表格?
要使用 IronPDF 在 Python 中从 PDF 提取表格,您可以利用 PdfDocument.FromFile() 方法加载 PDF,然后使用 ExtractAllText() 提取文本。随后可以处理文本并将其拆分为行以检索表格数据。
设置使用 IronPDF 的 Python 环境的步骤是什么?
要设置使用 IronPDF 的 Python 环境,确保已安装 Python,创建一个虚拟环境,并安装 .NET 6.0 运行时。然后可以使用命令 pip install ironpdf 安装 IronPDF。
IronPDF 在 Python 中提供了哪些 PDF 操作功能?
IronPDF 在 Python 中提供了广泛的 PDF 操作功能,包括从 HTML、图像和其他来源创建 PDF,提取文本和图像,创建带有注释、页眉、页脚和水印的交互式 PDF。
我可以在 Python 中使用 IronPDF 将 HTML 转换为 PDF 吗?
是的,IronPDF 允许您在 Python 中将 HTML 转换为 PDF。您可以使用 IronPDF 的方法将 HTML 字符串或文件呈现为 PDF,促进从网络内容创建 PDF 文档。
IronPDF 在 Python 中有哪些许可选项?
IronPDF 提供多种许可选项,包括用于测试的免费开发者许可、永久许可的 Lite 套装以及支持30天退款保证的额外许可套餐。
如何排除使用 IronPDF 从 PDF 提取表格时的常见问题?
要排除 IronPDF 的提取问题,请确保您的 Python 环境正确设置并安装了所有必要的组件。确认 PDF 文件可访问,并检查使用 PdfDocument.FromFile() 和 ExtractAllText() 方法的代码语法。请查阅 IronPDF 文档以获得进一步的指导。
IronPDF 在 PDF 处理方面提供了哪些安全功能?
IronPDF 集成了强大的安全功能来处理 PDF,例如密码保护和加密,确保文档在处理和分发过程中是安全的。
IronPDF 在 Python 中是否支持提取 PDF 中的图像?
是的,IronPDF 支持在 Python 中从 PDF 中提取图像,允许您在数据处理任务中分离和保存 PDF 文档中的图像。
推荐的 IronPDF 的 Python 开发 IDE 是哪个?
推荐使用 PyCharm 进行 IronPDF 的 Python 开发,因为它提供了一个全面的 IDE,具有用于编写代码、调试和有效管理 Python 项目的高级功能。
















