
Wie man Daten aus PDF-Dokumenten parst
Die Fähigkeit, Daten effizient aus PDFs programmatisch zu extrahieren und zu nutzen, stellt für den angehenden Entwickler aufgrund der Komplexität des internen Formats von PDFs einzigartige Herausforderungen dar.
IronPDF ist eine der vielen verfügbaren .NET-Programmierbibliotheken, die Entwicklern in einzigartiger Weise helfen kann, die Herausforderungen der Extraktion von Inhalten (Texten und Bildern) aus PDFs zuverlässig zu überwinden, neben vielen anderen Aufgaben im Zusammenhang mit PDFs. IronPDF erspart Ihnen das Verständnis der Feinheiten der internen Struktur von PDFs und ermöglicht es Ihnen, Ihre Zeit und Mühe darauf zu konzentrieren, Ihr Projekt schnell und pünktlich zu liefern.
In diesem Artikel werden die Feinheiten der PDF-Dokumentanalyse, die beteiligten Werkzeuge und Techniken sowie die transformierende Wirkung der IronPDF für .NET-Bibliothek untersucht, die Ihnen hilft, den Inhalt Ihres PDFs zu verstehen.
Schlüsselkonzepte
- PDF-Parsing: Die Extraktion strukturierter Daten aus PDF-Dokumenten ist das Herzstück des PDF-Parsings. Es erfordert das Erkennen von Dokumentenmustern und das Definieren von Regeln, um bestimmte Datenpunkte abzurufen. Die extrahierten Informationen werden häufig in Datenbanken gespeichert oder in anderen Anwendungen verwendet.
- PDF-Parser-Tools: Diese Tools, wie IronPDF, Tabula, PyPDF2 und PDFMiner, automatisieren den Extraktionsprozess. Sie nutzen Algorithmen zur Interpretation der PDF-Struktur und zur genauen Extraktion von Informationen.
- Datenextraktionsprozess: Die Extraktion von Daten aus PDFs umfasst typischerweise das Importieren von Dateien in ein Parsing-Tool, das Analysieren der Dokumentstruktur und das Konvertieren der geparsten Daten in Formate wie HTML, CSV, XML oder direkt in Anwendungen wie Excel oder Word.
- Strukturierte vs. unstrukturierte Daten: PDFs enthalten oft sowohl strukturierte (z. B. Tabellen) als auch unstrukturierte Daten. Parsing-Tools müssen beide Typen handhaben, um eine sinnvolle Datenextraktion zu gewährleisten.
Wie man Daten aus PDF-Dokumenten parst: Schritt-für-Schritt-Anleitung
Schritt 1: Öffnen Sie den kostenlosen Online-PDF-Extractor, um PDF-Dateien zu parsen
Ein einfach zu verwendendes Tool ist der kostenlose Online-PDF-Extractor. Navigieren Sie zur Website, wo Sie eine Übersicht über das Tool sehen können, einschließlich wie es PDFs importiert und welche Daten es extrahieren kann.
Schritt 2: Laden Sie die PDF-Datei hoch
Klicken Sie auf "Durchsuchen", um die PDF-Datei auszuwählen, aus der Sie Daten extrahieren möchten.
Alternativ können Sie die Datei hochladen, indem Sie einen Link zum PDF einfügen.
Schritt 3: Starten der Extraktion
Nach dem Hochladen der Datei klicken Sie auf "Start", um den Datenextraktionsprozess zu beginnen. Das Tool zeigt während der Verarbeitung einen Ladebildschirm an.
Schritt 4: Herunterladen der extrahierten Daten
Sobald die Extraktion abgeschlossen ist, können Sie die Daten herunterladen. Das Tool stellt den Text, die Bilder, die Schriftarten und die Metadaten bereit, die aus dem PDF in einem tabellarischen Format extrahiert wurden.
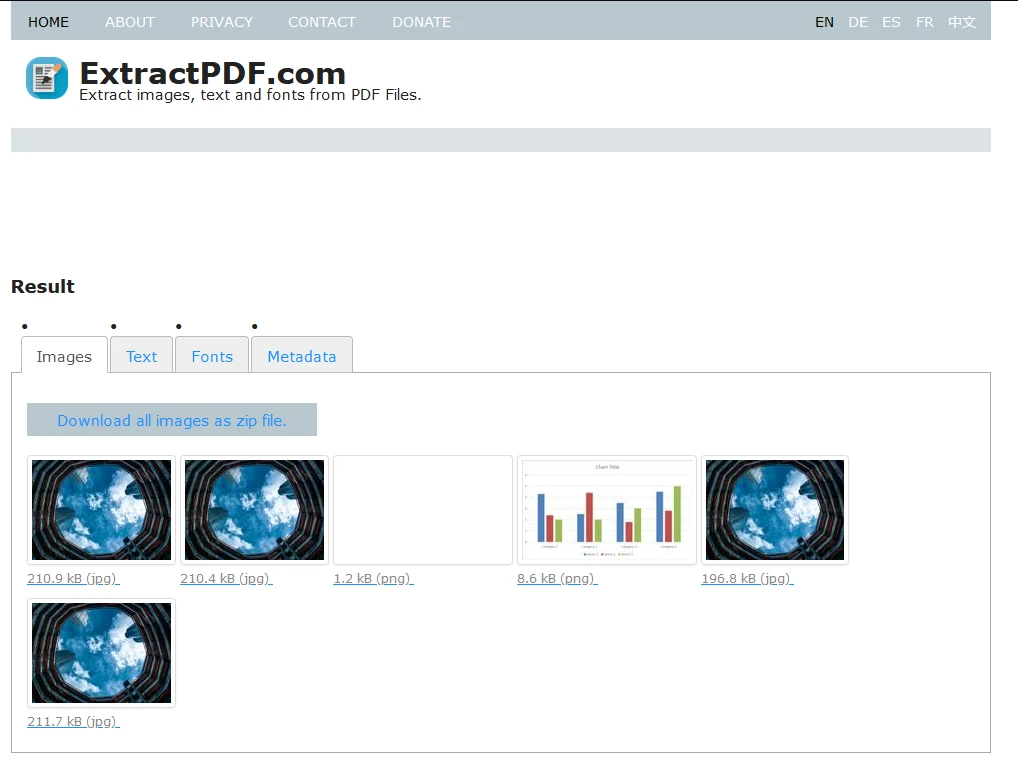
Text, der in Datenbanken kopiert werden kann, befindet sich unter der Registerkarte 'Text'.
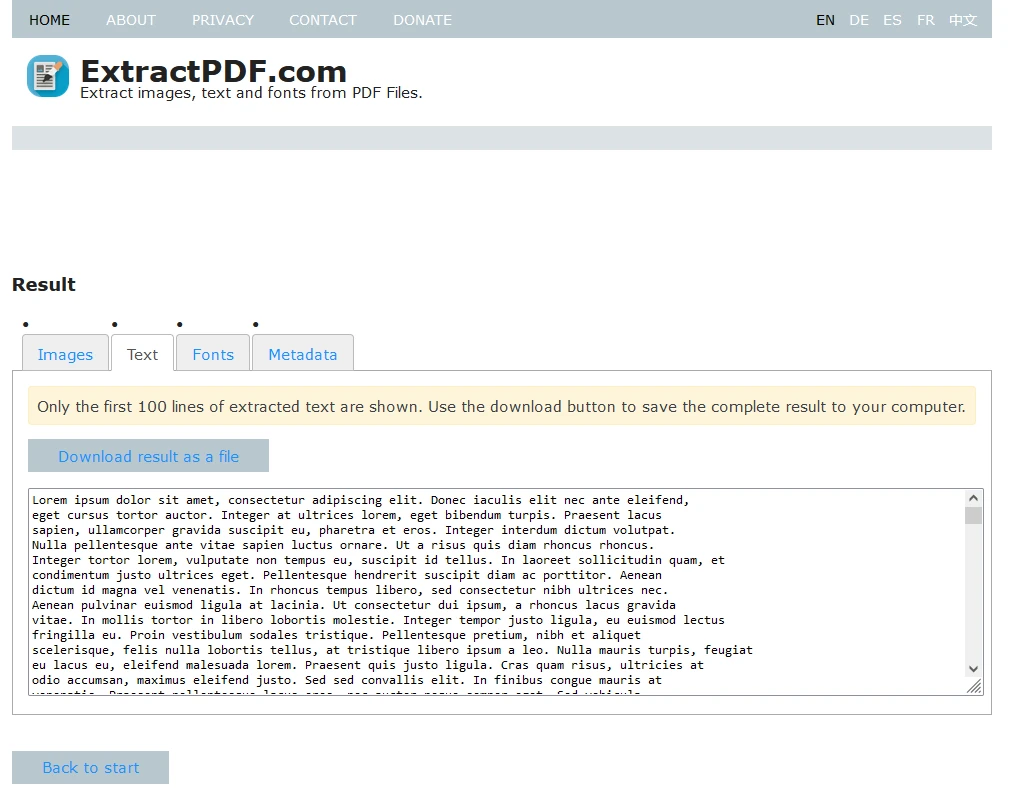
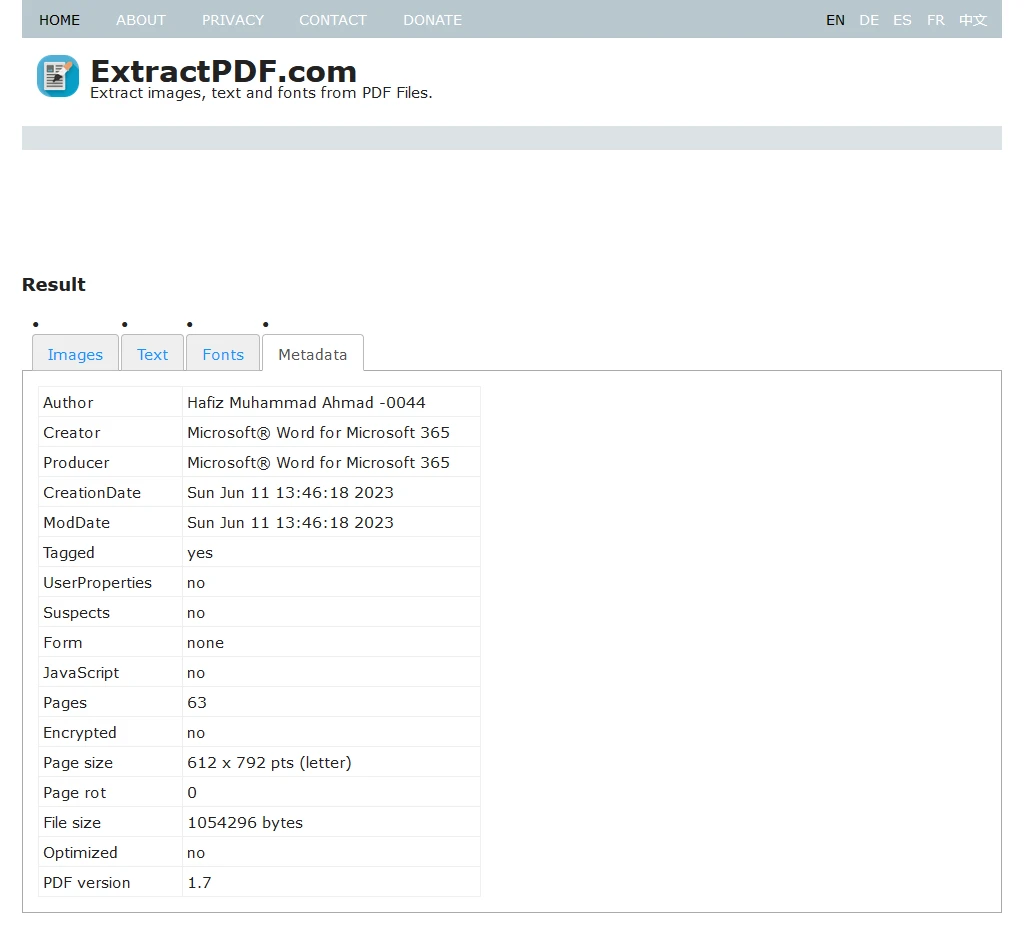
Metadaten, einschließlich Dokumenttitel, Autor, Erstellungsdatum und mehr, sind unter der Registerkarte 'Metadaten' verfügbar.
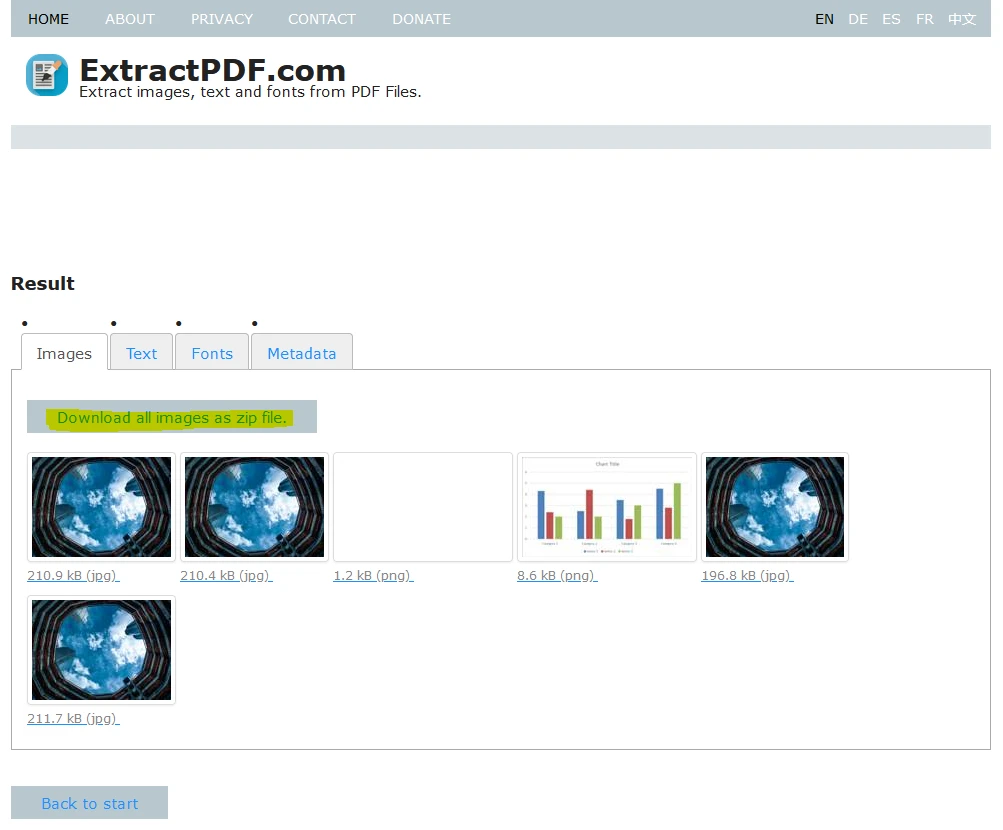
Schließlich können Sie alle extrahierten Daten als ZIP-Datei herunterladen.
Vorteile der PDF-Parsing
- Geschäftsprozessautomatisierung: PDF-Parsing automatisiert den Datenextraktionsprozess, reduziert manuelle Arbeit und verbessert die Geschäftsabläufe. Diese Automatisierung ermöglicht schnellere Entscheidungen und größere Skalierbarkeit.
- Fehlerreduktion: Manuelle Dateneingabe ist anfällig für Fehler. PDF-Parsing-Tools reduzieren menschliche Fehler und stellen sicher, dass Daten genauer verarbeitet werden, wodurch teure Fehler vermieden werden.
- Zeit- und Kosteneinsparung: Die Automatisierung der PDF-Datenextraktion spart erheblich Zeit und Ressourcen, die Organisationen auf strategischere Aufgaben umleiten können.
- Vielseitigkeit bei der Datennutzung: Extrahierte Daten können in verschiedene Formate konvertiert werden, was die Integration in Tools wie Excel, Word oder Google Sheets erleichtert.
Parsing von PDF-Daten mit IronPDF
IronPDF ist eine leistungsstarke Bibliothek von Iron Software, die Entwickler nutzen können, um Daten aus PDFs programmatisch zu extrahieren. Sie unterstützt das Extrahieren von Texten, Tabellen, Bildern und PDF-Metadatenextraktion mit hoher Effizienz.
Installation von IronPDF
Sie können IronPDF über den IronPDF auf NuGet Paketmanager in Visual Studio installieren.
Installation über den NuGet-Paketmanager
Suchen Sie in Visual Studio im NuGet-Paketmanager nach "IronPDF" und klicken Sie auf Installieren.

Installation über die Paket-Manager-Konsole
Alternativ verwenden Sie diesen Befehl in der Paket-Manager-Konsole:
Install-Package IronPdf
Codebeispiel: Parsing eines PDFs mit IronPDF
using IronPdf;
namespace ParsePdf
{
public partial class Form1 : Form
{
public Form1()
{
InitializeComponent();
// Select the Desired PDF File
using PdfDocument pdf = PdfDocument.FromFile("MyDocument.pdf");
// Extract text from the PDF
string allText = pdf.ExtractAllText();
// Display the extracted text in a MessageBox
// Only the first 1000 characters are shown for brevity
MessageBox.Show(allText.Substring(0, 1000), "Text Content", MessageBoxButtons.OK);
}
}
}using IronPdf;
namespace ParsePdf
{
public partial class Form1 : Form
{
public Form1()
{
InitializeComponent();
// Select the Desired PDF File
using PdfDocument pdf = PdfDocument.FromFile("MyDocument.pdf");
// Extract text from the PDF
string allText = pdf.ExtractAllText();
// Display the extracted text in a MessageBox
// Only the first 1000 characters are shown for brevity
MessageBox.Show(allText.Substring(0, 1000), "Text Content", MessageBoxButtons.OK);
}
}
}Imports IronPdf
Namespace ParsePdf
Partial Public Class Form1
Inherits Form
Public Sub New()
InitializeComponent()
' Select the Desired PDF File
Using pdf As PdfDocument = PdfDocument.FromFile("MyDocument.pdf")
' Extract text from the PDF
Dim allText As String = pdf.ExtractAllText()
' Display the extracted text in a MessageBox
' Only the first 1000 characters are shown for brevity
MessageBox.Show(allText.Substring(0, 1000), "Text Content", MessageBoxButtons.OK)
End Using
End Sub
End Class
End NamespaceIn diesem Beispiel erstellen wir eine Windows Forms-Anwendung, die IronPDF verwendet, um Text aus einer ausgewählten PDF-Datei zu extrahieren. Der extrahierte Text wird dann in einem Nachrichtenfeld angezeigt.
Lizenzierung von IronPDF
IronPDF erfordert einen Lizenzschlüssel von IronPDF, den Sie im Rahmen einer kostenlosen Testlizenz erhalten können. Fügen Sie den Lizenzschlüssel zu Ihrer appsettings.json Datei hinzu:
{
"IronPdf.LicenseKey": "your license key here"
}Fordern Sie eine kostenlose Testlizenz von der Produkt-Lizenzierungsseite von IronPDF an.
Abschluss
Effizientes PDF-Parsing erschließt das volle Potenzial digitaler Dokumente, ermöglicht es Unternehmen, Prozesse zu automatisieren, Fehler zu reduzieren und Zeit und Geld zu sparen. Indem sie sich auf PDF-Parsing-Techniken und -Tools spezialisieren, können Organisationen die Produktivität steigern und mehr mit ihren digitalen Assets erreichen. IronPDF bietet eine ideale Lösung für Entwickler, die programmgesteuert mit PDF-Dokumenten arbeiten möchten.
Häufig gestellte Fragen
Wie kann ich mit C# Text aus PDF-Dokumenten extrahieren?
Sie können die PdfDocument-Klasse von IronPDF verwenden, um eine PDF-Datei zu laden und die ExtractAllText()-Methode, um Text zu extrahieren. Dies ermöglicht eine einfache Abfrage von Textdaten aus PDFs.
Welche Methoden bietet IronPDF zur Extraktion von Bildern aus einer PDF?
IronPDF bietet Methoden wie ExtractImages(), die verwendet werden können, um eingebettete Bilder aus PDF-Dateien zu extrahieren und sie in Formate wie JPEG oder PNG zu konvertieren.
Wie kann ich PDF-Daten mit einer .NET-Bibliothek in ein CSV-Format umwandeln?
IronPDF ermöglicht es Ihnen, Daten aus PDFs zu analysieren und extrahieren, die dann programmgesteuert in das CSV-Format mithilfe von standardmäßigen .NET-Datenmanipulationstechniken umgewandelt werden können.
Was sind die häufigen Herausforderungen bei der Analyse von PDF-Dokumenten?
Die Analyse von PDFs kann aufgrund ihrer komplexen Struktur, die unterschiedliche Elemente wie Text, Bilder und Metadaten umfasst, herausfordernd sein. Tools wie IronPDF helfen, diese Herausforderungen zu überwinden, indem sie unkomplizierte Methoden zur Extraktion und Manipulation von PDF-Inhalten bereitstellen.
Kann IronPDF zur Analyse der PDF-Struktur vor der Extraktion verwendet werden?
Ja, IronPDF bietet Tools zur Analyse der PDF-Struktur, die es Entwicklern ermöglichen, Muster zu identifizieren und die effizientesten Methoden zur Extraktion der benötigten Daten zu bestimmen.
Welche Lizenzanforderungen gibt es für die Verwendung von IronPDF?
IronPDF erfordert eine gültige Lizenz für den Einsatz in Produktionsumgebungen. Allerdings steht eine kostenlose Testversion zu Evaluationszwecken zur Verfügung, wodurch Benutzer die Funktionen testen können, bevor sie sich zum Kauf verpflichten.
Wie profitieren Unternehmen von der Automatisierung der PDF-Datenauswertung?
Die Automatisierung der PDF-Datenauswertung mit Tools wie IronPDF kann die manuelle Dateneingabe erheblich reduzieren, Fehler minimieren, Zeit sparen und die Betriebskosten senken, was die Gesamteffizienz des Unternehmens verbessert.
Welche Programmiersprachen werden von IronPDF zur Auswertung von PDF-Daten unterstützt?
IronPDF ist für die Verwendung mit .NET-Sprachen konzipiert, hauptsächlich C#, was eine nahtlose Integration mit anderen .NET-Anwendungen und -Diensten zur effizienten PDF-Datenauswertung ermöglicht.
Ist IronPDF beim Parsen von PDF-Daten vollständig mit .NET 10 kompatibel?
Ja – IronPDF bietet volle Unterstützung für .NET 10, was bedeutet, dass Sie die Parsing-Funktionen wie Text- und Bildextraktion, Metadatenlesen, Tabellenanalyse und HTML-zu-PDF-Konvertierung in .NET 10-Projekten ohne Workarounds oder Kompatibilitätsprobleme nutzen können.














