Cómo convertir un PDF a texto en Node.js
La conversión de PDF a texto en Node.js es una tarea común en muchas aplicaciones, especialmente cuando se trata de análisis de datos, sistemas de gestión de contenido o incluso utilidades de conversión simples. Con el entorno de Node.js y la biblioteca IronPDF, los desarrolladores pueden convertir documentos PDF en datos de texto utilizables sin esfuerzo. Este tutorial tiene como objetivo guiar a los principiantes a través del proceso de configuración de un proyecto Node.js para extraer texto de archivos de página PDF usando IronPDF, centrándose en aspectos clave como detalles de instalación, implementación de análisis de PDF, manejo de errores y aplicaciones prácticas.
Cómo convertir PDF a texto en Node.js
- Crea una aplicación Node.js en tu IDE.
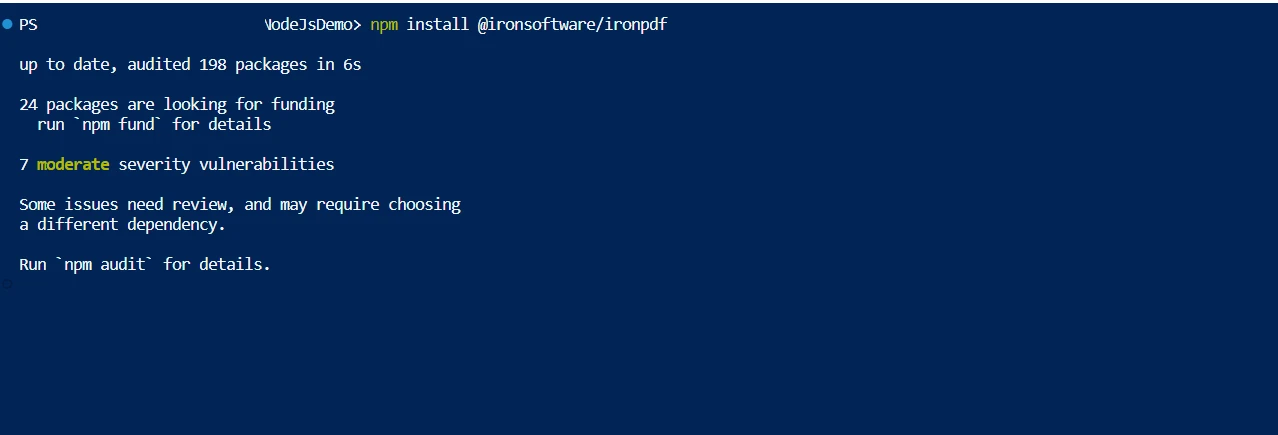
- Instala la biblioteca PDF usando npm.
- Carga las páginas PDF en la aplicación.
- Extrae texto usando el método extractText.
- Usa el texto extraído para el procesamiento y devuelve datos.
Requisitos previos
Antes de embarcarte en este viaje, asegúrate de tener lo siguiente:
- Node.js está instalado en tu máquina.
- Un conocimiento básico de JavaScript.
- Un archivo PDF para probar el proceso de extracción.
Cómo configurar tu proyecto Node.js
Paso 1: Inicializar su aplicación Node.js
Crea un nuevo directorio para tu proyecto e inicia una aplicación Node.js:
mkdir pdf-to-text-node
cd pdf-to-text-node
npm init -ymkdir pdf-to-text-node
cd pdf-to-text-node
npm init -yPaso 2: Instalación de IronPDF
Instala IronPDF usando npm:
npm install ironpdfnpm install ironpdfImplementación de la conversión de PDF a texto con IronPDF
Paso 1: Importación de los módulos necesarios
import { PdfDocument } from "@ironpdf/ironpdf";
import { IronPdfGlobalConfig } from "@ironpdf/ironpdf";
import fs from "fs";import { PdfDocument } from "@ironpdf/ironpdf";
import { IronPdfGlobalConfig } from "@ironpdf/ironpdf";
import fs from "fs";En este primer paso, importas los módulos necesarios. PdfDocument y IronPdfGlobalConfig se importan del paquete @ironpdf/ironpdf, que son esenciales para trabajar con documentos PDF y configurar IronPDF, respectivamente. El módulo fs, un módulo central de Node.js, también se importa para manejar operaciones del sistema de archivos.
Paso 2: Configuración de una función asíncrona
(async function createPDFs() {
// ...
})();(async function createPDFs() {
// ...
})();Aquí, se define e invoca inmediatamente una función anónima asíncrona llamada createPDFs. Esta configuración permite el uso de await dentro de la función, facilitando el manejo de operaciones asíncronas, que son comunes al tratar con E/S de archivos y bibliotecas externas como IronPDF.
Paso 3: Aplicación de la clave de licencia
const IronPdfConfig = {
licenseKey: "Your-License-Key",
};
IronPdfGlobalConfig.setConfig(IronPdfConfig);const IronPdfConfig = {
licenseKey: "Your-License-Key",
};
IronPdfGlobalConfig.setConfig(IronPdfConfig);En este paso, creas un objeto de configuración para IronPDF, incluida la clave de licencia, y aplicas esta configuración utilizando IronPdfGlobalConfig.setConfig. Esto es crucial para habilitar todas las funciones de IronPDF, particularmente si estás usando una versión con licencia.
Paso 4: Cargar el documento PDF
const pdf = await PdfDocument.fromFile("old-report.pdf");const pdf = await PdfDocument.fromFile("old-report.pdf");En este paso, el código utiliza correctamente el método fromFile de la clase PdfDocument para cargar un documento PDF existente. Esta es una operación asíncrona, de ahí el uso de await. Al especificar la ruta a tu archivo PDF (en este caso, "old-report.pdf"), la variable pdf se convierte en una representación de tu documento PDF, completamente cargado y listo para la extracción de texto. Este paso es crucial ya que es donde se analiza el archivo PDF y se prepara para cualquier operación que desees realizar en él, como extraer texto.
Paso 5: Extraer texto del PDF
const text = await pdf.extractText();const text = await pdf.extractText();Aquí, se llama al método extractText en el objeto pdf. Esta operación asíncrona extrae todo el texto del documento PDF cargado, almacenándolo en la variable text.
Paso 6: Procesamiento del texto extraído
const wordCount = text.split(/\s+/).length;
console.log("Word Count:", wordCount);const wordCount = text.split(/\s+/).length;
console.log("Word Count:", wordCount);En este paso, se procesa el texto extraído para contar el número de palabras. Esto se logra dividiendo la cadena de texto en un arreglo de palabras utilizando una expresión regular que coincide con uno o más caracteres de espacio en blanco y luego contando la longitud del arreglo resultante.
Paso 7: Guardar el texto extraído en un archivo
fs.writeFileSync("extracted_text.txt", text);fs.writeFileSync("extracted_text.txt", text);Esta línea corregida usa el método writeFileSync del módulo fs para escribir de forma síncrona el texto extraído en un archivo.
Paso 8: Tratamiento de errores
} catch (error) {
console.error("An error occurred:", error); // Log error
}} catch (error) {
console.error("An error occurred:", error); // Log error
}Finalmente, el código incluye un bloque try-catch para el manejo de errores. Si alguna parte de las operaciones asíncronas dentro del bloque try falla, el bloque catch capturará el error, y el mensaje se registrará en la consola. Esto es importante para la depuración y para asegurar que tu aplicación pueda manejar problemas inesperados de manera elegante.
Código completo
A continuación se muestra el código completo que encapsula todos los pasos que hemos discutido para extraer texto de un documento PDF usando IronPDF en un entorno Node.js:
import { PdfDocument } from "@ironpdf/ironpdf";
import { IronPdfGlobalConfig } from "@ironpdf/ironpdf";
import fs from "fs";
(async function createPDFs() {
try {
// Input the license key
const IronPdfConfig = {
licenseKey: "Your-License-Key",
};
// Set the config with the license key
IronPdfGlobalConfig.setConfig(IronPdfConfig);
// Import existing PDF document
const pdf = await PdfDocument.fromFile("old-report.pdf");
// Get all text to put in a search index
const text = await pdf.extractText();
// Process the extracted text
// Example: Count words
const wordCount = text.split(/\s+/).length;
console.log("Word Count:", wordCount);
// Save the extracted text to a text file
fs.writeFileSync("extracted_text.txt", text);
console.log("Extracted text saved to extracted_text.txt");
} catch (error) {
// Handle errors here
console.error("An error occurred:", error);
}
})();import { PdfDocument } from "@ironpdf/ironpdf";
import { IronPdfGlobalConfig } from "@ironpdf/ironpdf";
import fs from "fs";
(async function createPDFs() {
try {
// Input the license key
const IronPdfConfig = {
licenseKey: "Your-License-Key",
};
// Set the config with the license key
IronPdfGlobalConfig.setConfig(IronPdfConfig);
// Import existing PDF document
const pdf = await PdfDocument.fromFile("old-report.pdf");
// Get all text to put in a search index
const text = await pdf.extractText();
// Process the extracted text
// Example: Count words
const wordCount = text.split(/\s+/).length;
console.log("Word Count:", wordCount);
// Save the extracted text to a text file
fs.writeFileSync("extracted_text.txt", text);
console.log("Extracted text saved to extracted_text.txt");
} catch (error) {
// Handle errors here
console.error("An error occurred:", error);
}
})();Este script incluye todos los componentes necesarios para extraer texto de un archivo PDF: configuración de IronPDF con una clave de licencia, carga del documento PDF, extracción del texto, realización de un análisis de texto simple (conteo de palabras en este caso) y guardado del texto extraído en un archivo. El código está envuelto en una función asíncrona para manejar la naturaleza asíncrona de las operaciones de archivos y el procesamiento de PDF en Node.js.
Análisis del resultado: PDF y texto extraído
Una vez que hayas ejecutado el script, tendrás dos componentes clave para analizar: el archivo PDF original y el archivo de texto que contiene el texto extraído. Esta sección te guiará para entender y evaluar el resultado del script.
El documento PDF original
El archivo PDF que elijas para este proceso, en este caso, llamado "old-report.pdf", es el punto de partida. Los documentos PDF pueden variar enormemente en complejidad y contenido. Pueden contener texto simple y directo, o podrían estar llenos de imágenes, tablas y varios formatos de texto. La estructura y complejidad de tu PDF impactarán directamente en el proceso de extracción.

Archivo de texto extraído
Después de ejecutar el script, se creará un nuevo archivo de texto llamado "extracted_text.txt". Este archivo contiene todo el texto que se extrajo del documento PDF.

Y este es el resultado en la consola:

Aplicaciones prácticas y casos de uso
Minería y análisis de datos
Extraer texto de PDFs es particularmente útil en la minería y el análisis de datos. Ya sea extrayendo informes financieros, documentos de investigación o cualquier otro documento en PDF, la capacidad de convertir PDFs a texto es crucial para las tareas de análisis de datos.
Sistemas de gestión de contenidos
En los sistemas de gestión de contenido, a menudo necesitas manejar varios formatos de archivo. IronPDF puede ser un componente clave en un sistema que gestiona, archiva y recupera contenido almacenado en formato PDF.
Conclusión
Esta guía completa te ha guiado a través del proceso de configuración de un proyecto Node.js para extraer texto de documentos PDF usando IronPDF. Desde manejar la extracción de texto básica hasta sumergirse en características más complejas como la extracción de objetos de texto y la optimización de rendimiento, ahora estás equipado con el conocimiento para implementar una extracción eficiente de texto de PDF en tus aplicaciones Node.js.
Recuerda, el viaje no termina aquí. El campo del procesamiento de PDF y la extracción de texto es vasto, con muchas más características y técnicas para explorar. Acepta el desafío y continúa mejorando tus habilidades en este emocionate dominio del desarrollo de software.
Vale la pena señalar que IronPDF ofrece una prueba gratuita para los usuarios. Para aquellos que buscan integrar IronPDF en un entorno profesional, hay opciones de licencias disponibles.
Preguntas Frecuentes
¿Cómo puedo configurar un proyecto de Node.js para extracción de texto de PDF?
Para configurar un proyecto de Node.js para extracción de texto de PDF, primero asegúrate de que Node.js esté instalado en tu máquina. Luego, crea una nueva aplicación Node.js e instala la librería IronPDF usando npm con el comando: npm install ironpdf.
¿Qué método debo usar para extraer texto de un PDF usando IronPDF en Node.js?
En Node.js, puedes usar el método extractText del objeto PdfDocument en IronPDF para extraer texto de un documento PDF cargado.
¿Por qué es necesaria una clave de licencia para usar una librería PDF en Node.js?
Una clave de licencia es necesaria para desbloquear todas las funciones de la librería IronPDF, especialmente en un entorno de producción, asegurando que tengas acceso a todas sus capacidades.
¿Qué debo hacer si encuentro errores durante el proceso de extracción de texto de PDF?
Usa un bloque try-catch para manejar errores durante la extracción de texto de PDF. Este enfoque te permite capturar y registrar errores, asegurando que tu aplicación Node.js pueda gestionar los problemas con gracia.
¿Cuáles son los usos prácticos de convertir PDFs a texto en Node.js?
Convertir PDFs a texto en Node.js es útil para minería de datos, automatización de sistemas de gestión de contenido e integración con utilidades de conversión para manejar formatos de archivos diversos.
¿Es posible probar la librería PDF sin comprar una licencia?
Sí, IronPDF ofrece una versión de prueba gratuita, permitiendo a los desarrolladores explorar las funciones de la librería antes de decidirse por una opción de licencia para uso profesional.
¿Cómo beneficia la programación asíncrona al procesamiento de PDF en Node.js?
La programación asíncrona permite operaciones no bloqueantes en Node.js, lo cual es crítico para I/O de archivos y uso de librerías externas como IronPDF, mejorando así el rendimiento y la eficiencia.