
Cómo Extraer Texto Específico De Un PDF en Python
Este artículo demostrará cómo extraer elementos de texto de documentos PDF con la ayuda de la biblioteca IronPDF for Python.
IronPDF
Python es un lenguaje de programación que facilita y agiliza la creación de interfaces gráficas de usuario para los desarrolladores. En comparación con otros lenguajes, Python también es mucho más dinámico para los programadores. Por esta razón, agregar la biblioteca IronPDF a Python es un proceso sencillo. Se puede utilizar una multitud de herramientas preinstaladas, incluyendo PyQt, wxWidgets, Kivy y muchos paquetes adicionales y bibliotecas de Python, para construir rápidamente y de forma segura una interfaz gráfica de usuario completa. IronPDF incorpora Python y también permite la integración de funciones de otros frameworks, como .NET Core.
IronPDF facilita el desarrollo web. La principal razón para esto es la adopción generalizada de paradigmas de desarrollo web en Python como Django, Flask y Pyramid. Reddit, Mozilla y Spotify son solo algunos de los sitios web y servicios en línea que han utilizado estos frameworks.
Características de IronPDF
- Con IronPDF, los archivos PDF pueden ser creados a partir de una variedad de fuentes, incluyendo HTML, HTML5, ASPX y Razor/MVC View. Ofrece la capacidad de convertir páginas HTML e imágenes en archivos PDF.
- Crear PDFs interactivos, completar y enviar formularios interactivos, dividir y combinar archivos PDF, extraer texto e imágenes, buscar texto dentro de archivos PDF, rasterizar PDFs a imágenes, cambiar el tamaño de fuente, procesamiento de lenguaje natural usando ChatGPT y convertir páginas PDF adecuadamente son solo algunas de las actividades que el conjunto de herramientas de IronPDF puede ayudar a realizar.
- IronPDF ofrece validación de formularios de inicio de sesión HTML con soporte para agentes de usuario, proxies, cookies, encabezados HTTP y variables de formulario.
- IronPDF usa nombres de usuario y contraseñas para proporcionar a los usuarios acceso a documentos protegidos.
- Con solo unas pocas líneas de código, IronPDF puede imprimir un archivo PDF de una variedad de fuentes, incluyendo una cadena, flujo o URL.
Configuración de Python
Configuración del entorno
Asegúrate de que Python esté instalado en tu computadora. Para descargar e instalar la versión más reciente de Python compatible con tu sistema operativo, visita el sitio web oficial de Python. Crea un entorno virtual una vez que Python esté instalado para separar las necesidades de tu proyecto. Cree y administre entornos virtuales con el módulo venv para darle a su proyecto de conversión un lugar de trabajo ordenado y separado.
Nueva iniciativa en PyCharm
Para esta demostración, se recomienda PyCharm como IDE para desarrollar código en Python.
Después de iniciar el IDE PyCharm, selecciona "Nuevo Proyecto".
 PyCharm
PyCharm
Se abrirá una nueva ventana al elegir "Nuevo Proyecto", permitiéndote configurar la ubicación y el entorno del proyecto. Esto puede verse en la imagen a continuación.
 Nuevo proyecto
Nuevo proyecto
Después de elegir la ubicación del proyecto y la ruta del entorno, haz clic en el botón Crear para comenzar un nuevo proyecto. El programa puede luego ser creado en una nueva ventana que se abrirá como resultado. Para esta lección, se está utilizando Python 3.9.
 Crear un proyecto de Python
Crear un proyecto de Python
Requisitos de la biblioteca IronPDF
La biblioteca de Python IronPDF utiliza en gran medida .NET 6.0. Como resultado, el runtime de .NET 6.0 debe estar instalado en tu computadora para usar IronPDF for Python. Podría ser necesario instalar .NET antes de que este módulo de Python pueda ser utilizado por usuarios de Linux y Mac. Visita esta página de descargas de Microsoft para obtener el entorno de ejecución necesario.
Configuración de la biblioteca IronPDF
Para generar, modificar y abrir archivos con la extensión ".pdf", se debe instalar el paquete "IronPDF". Abre una ventana de terminal e ingresa el siguiente comando para instalar el paquete en PyCharm:
pip install ironpdfpip install ironpdfLa instalación del paquete ironpdf se muestra en la siguiente captura de pantalla.
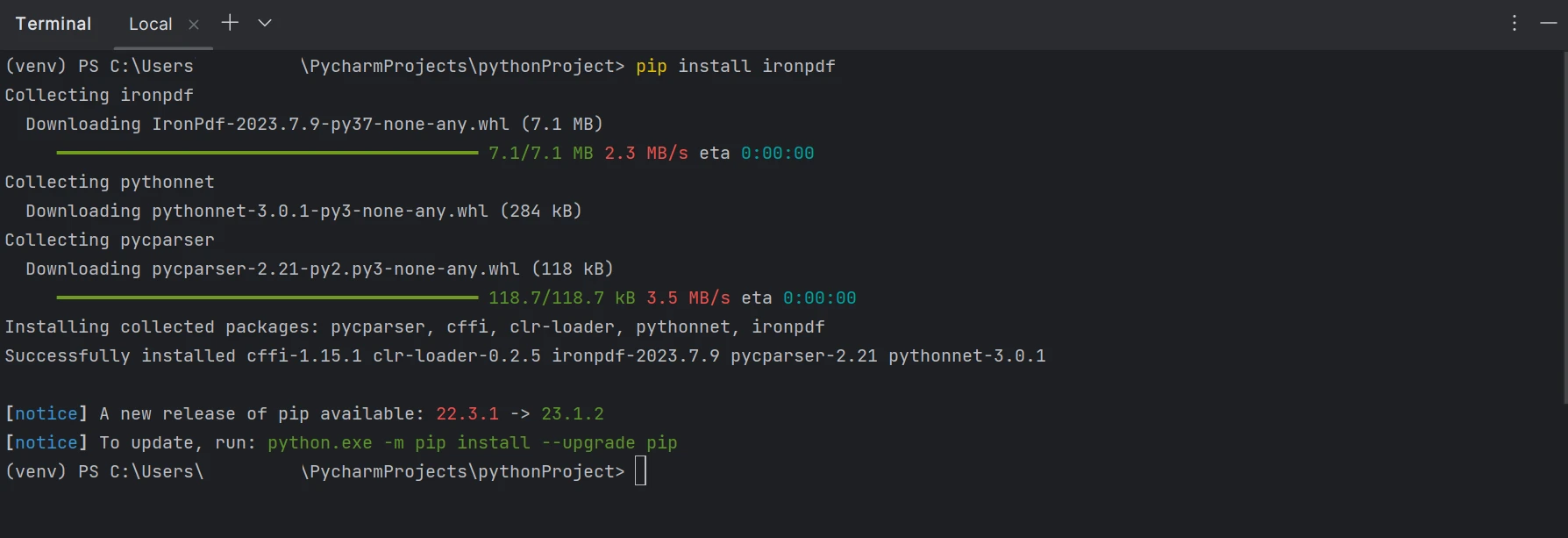 Instalar IronPDF
Instalar IronPDF
Extraer datos específicos de un archivo PDF
Es posible extraer texto de archivos PDF con la ayuda de las bibliotecas IronPDF. IronPDF ofrece una serie de métodos de extracción de texto. El primer método implica recuperar el contenido de toda la página como una sola cadena. La segunda estrategia implica recorrer el contenido página por página, comenzando por la primera página. Los archivos PDF existentes se pueden investigar utilizando la biblioteca IronPDF. El fragmento de código que sigue muestra cómo usar IronPDF para inspeccionar archivos PDF en vivo.
Existen dos opciones para extraer información de un PDF:
- Extracción página por página del PDF
- Convertir todo el PDF a texto
Aquí está el archivo PDF de muestra para este artículo disponible a continuación.
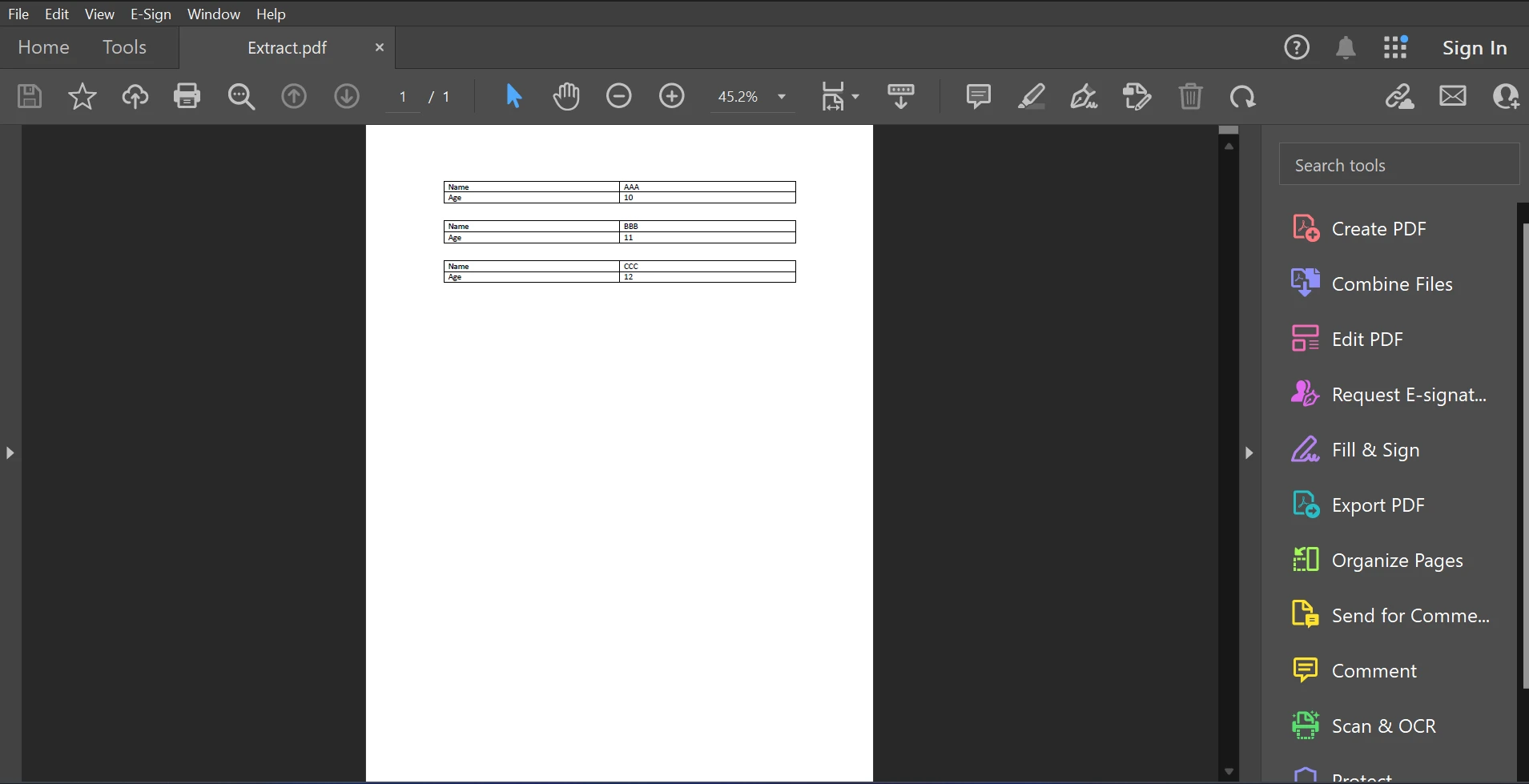 PDF de entrada
PDF de entrada
Extracción página por página del PDF
El código de ejemplo proporcionado a continuación muestra cómo obtener datos de un archivo PDF utilizando el número de página.
from ironpdf import PdfDocument
# Load the PDF file
pdf = PdfDocument.FromFile('F:\\PDF\\Extract.pdf')
# Extract text from the first page of the PDF document
all_text = pdf.ExtractTextFromPage(0)
# Iterate over each line in the extracted text
for line in all_text.split('\n'):
# Check if the line contains the keyword "Name"
if 'Name' in line:
# Print the line if it contains the keyword
print(line)from ironpdf import PdfDocument
# Load the PDF file
pdf = PdfDocument.FromFile('F:\\PDF\\Extract.pdf')
# Extract text from the first page of the PDF document
all_text = pdf.ExtractTextFromPage(0)
# Iterate over each line in the extracted text
for line in all_text.split('\n'):
# Check if the line contains the keyword "Name"
if 'Name' in line:
# Print the line if it contains the keyword
print(line)El fragmento de código muestra cómo leer un archivo PDF y crear un objeto PDF utilizando la función FromFile. Este objeto puede ser utilizado para acceder al texto e imágenes del PDF. Al pasar el número de página como parámetro a la función ExtractTextFromPage, se puede recuperar el texto de una página específica. Este método devolverá una cadena que contiene todas las palabras de la página elegida. Luego, use la función split en Python para dividir todas las nuevas líneas del texto extraído. Después de eso, verifica si cada línea en el texto extraído contiene las palabras clave requeridas. Si la palabra clave coincide, mostrará la línea específica en la línea de comandos. De lo contrario, ignorará esa línea y pasará a la siguiente. El resultado de la extracción de texto aparecerá como se muestra a continuación.
Convertir todo el PDF en texto
El siguiente ejemplo de código muestra el primer método para obtener rápida y simplemente todo el contenido del PDF como una cadena.
from ironpdf import PdfDocument
# Load the PDF file
pdf = PdfDocument.FromFile('F:\\PDF\\Extract.pdf')
# Extract all text from the PDF document
all_text = pdf.ExtractAllText()
# Iterate over each line in the extracted text
for line in all_text.split('\n'):
# Check if the line contains the keyword "Name"
if 'Name' in line:
# Print the line if it contains the keyword
print(line)from ironpdf import PdfDocument
# Load the PDF file
pdf = PdfDocument.FromFile('F:\\PDF\\Extract.pdf')
# Extract all text from the PDF document
all_text = pdf.ExtractAllText()
# Iterate over each line in the extracted text
for line in all_text.split('\n'):
# Check if the line contains the keyword "Name"
if 'Name' in line:
# Print the line if it contains the keyword
print(line)El código de ejemplo anterior demuestra cómo utilizar la función FromFile para leer un PDF desde una ruta de archivo existente y convertirlo en un objeto de archivo PDF. Como resultado, podemos usar este objeto lector de PDF para ver el texto y las imágenes en el PDF. La función ExtractAllText del objeto se utilizará para extraer datos del PDF en texto sin formato, convertirlos en una cadena y utilizar una lógica similar a la anterior para encontrar la palabra clave específica para mostrar el resultado en la terminal. - Los resultados se muestran así.
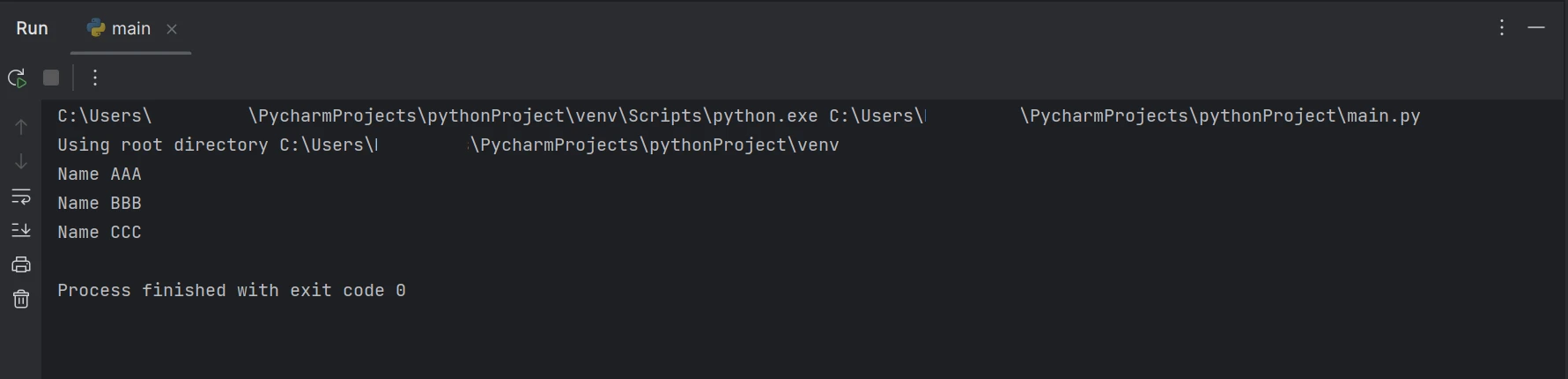 Salida
Salida
El código/salida anterior muestra que el documento PDF dado contiene tanto el nombre como la edad, pero el resultado muestra solo el nombre disponible en el documento PDF.
Conclusión
La biblioteca IronPDF ofrece mecanismos de seguridad sólidos para reducir amenazas y garantizar la seguridad de los datos. No está restringido a ningún navegador y es compatible con todos los navegadores más usados. Con solo unas pocas líneas de código, los programadores pueden crear y leer rápidamente archivos PDF utilizando IronPDF. La biblioteca IronPDF ofrece una variedad de opciones de licencia, incluyendo una licencia de desarrollador gratuita y licencias de desarrollo adicionales que están disponibles para su compra, para satisfacer las diversas demandas de los desarrolladores.
Una licencia perpetua, una garantía de devolución de dinero de 30 días, un año de mantenimiento de software y opciones de actualización están incluidas en el paquete Lite. Estas licencias se pueden usar en todos los entornos. Además, IronPDF proporciona licencias gratuitas con algunas restricciones de redistribución. Una licencia de prueba permite a los usuarios evaluar el producto sin una marca de agua.
Por favor, consulta las Licencias de IronPDF disponibles para obtener más información sobre licencias comerciales.
Preguntas Frecuentes
¿Cómo puedo extraer texto específico de un PDF usando Python?
Puede usar la biblioteca de Python de IronPDF para extraer texto de PDFs. Proporciona funcionalidades para extraer texto página por página usando ExtractTextFromPage o de todo el documento usando ExtractAllText.
¿Cuáles son los pasos para configurar IronPDF en un proyecto de Python?
Primero, instale el runtime de .NET 6.0 si no está ya instalado. Luego, configure Python en su entorno de desarrollo, como PyCharm. Instale IronPDF usando pip install ironpdf para comenzar a integrar funcionalidades PDF en su proyecto.
¿Es IronPDF compatible con frameworks como Django y Flask?
Sí, IronPDF se integra bien con frameworks de desarrollo web de Python como Django y Flask, proporcionando opciones versátiles para manejar PDFs en aplicaciones web.
¿Qué opciones de licenciamiento están disponibles para usar IronPDF con Python?
IronPDF ofrece una variedad de opciones de licenciamiento, incluyendo una licencia gratuita para desarrolladores de uso personal y varias licencias comerciales que proporcionan características y beneficios adicionales.
¿Cómo puedo instalar IronPDF for Python?
Instale IronPDF usando el gestor de paquetes pip ejecutando el comando pip install ironpdf en su terminal o símbolo del sistema.
¿Qué entorno de desarrollo se recomienda para usar IronPDF con Python?
PyCharm es un Entorno de Desarrollo Integrado (IDE) recomendado para desarrollar aplicaciones en Python usando IronPDF, debido a su conjunto de características completo y soporte for Python.
¿Cuáles son algunas características clave de la biblioteca IronPDF for Python?
IronPDF for Python ofrece características como la creación de PDFs a partir de HTML, la conversión de imágenes a PDFs, manejo de formularios, extracción de texto e imágenes y fusión de PDFs.
¿Qué tan segura es la biblioteca IronPDF para manejar archivos PDF?
IronPDF está diseñado con características de seguridad robustas, asegurando un manejo seguro de archivos PDF. Soporta encriptación y protección por contraseña para salvaguardar información sensible.
















