
Cómo Ver Un Archivo PDF en Python
Este artículo explorará cómo ver archivos PDF en Python utilizando la biblioteca IronPDF.
IronPDF - Biblioteca Python
IronPDF es una poderosa biblioteca de Python que permite a los desarrolladores trabajar con archivos PDF de manera programática. Con IronPDF, puedes generar, manipular y extraer datos de documentos PDF fácilmente, convirtiéndolo en una herramienta versátil para diversas tareas relacionadas con PDF. Ya sea que necesites crear PDFs desde cero, modificar PDFs existentes o extraer contenido de PDFs, IronPDF proporciona un conjunto completo de características para simplificar tu flujo de trabajo.
Algunas características de la biblioteca IronPDF for Python incluyen:
- Crear nuevo archivo PDF desde cero usando HTML o URL
- Editar archivos PDF existentes
- Rotar páginas de PDF
- Extraer texto, metadatos e imágenes de archivos PDF
- Convertir archivos PDF a otros formatos
- Proteger archivos PDF con contraseñas y restricciones
- Dividir y fusionar PDFs
Nota: IronPDF produce un archivo de datos PDF con marca de agua. Para eliminar la marca de agua, necesitas licenciar IronPDF. Si deseas usar una versión licenciada de IronPDF, visita el sitio web de IronPDF para obtener una clave de licencia.
Requisitos previos
Antes de trabajar con IronPDF en Python, hay algunos requisitos previos:
- Instalación de Python: asegúrese de tener Python instalado en su sistema. IronPDF es compatible con versiones de Python 3.x, así que asegúrate de tener una instalación de Python compatible.
Biblioteca IronPDF : instale la biblioteca IronPDF para acceder a su funcionalidad. Puedes instalarla usando el gestor de paquetes de Python (pip) ejecutando el siguiente comando en tu interfaz de línea de comandos:
pip install ironpdfpip install ironpdfSHELLBiblioteca Tkinter: Tkinter es el kit de herramientas GUI estándar for Python. Se utiliza para crear la interfaz gráfica de usuario para el visor de PDF en el fragmento de código proporcionado. Tkinter suele venir preinstalado con Python, pero si encuentras algún problema, puedes instalarlo usando el gestor de paquetes:
pip install tkinterpip install tkinterSHELLBiblioteca Pillow: La biblioteca Pillow es una bifurcación de la biblioteca de imágenes de Python (PIL) y proporciona capacidades adicionales de procesamiento de imágenes. Se utiliza en el fragmento de código para cargar y mostrar las imágenes extraídas del PDF. Instala Pillow usando el gestor de paquetes:
pip install pillowpip install pillowSHELL- Entorno de desarrollo integrado (IDE): el uso de un IDE para gestionar proyectos de Python puede mejorar enormemente su experiencia de desarrollo. Proporciona características como autocompletar código, depuración y un flujo de trabajo más eficiente. Un IDE popular para el desarrollo en Python es PyCharm. Puedes descargar e instalar PyCharm desde el sitio web de JetBrains (https://www.jetbrains.com/pycharm/).
- Editor de texto: como alternativa, si prefiere trabajar con un editor de texto liviano, puede usar cualquier editor de texto de su elección, como Visual Studio Code, Sublime Text o Atom. Estos editores proporcionan resaltado de sintaxis y otras características útiles para el desarrollo en Python. También puedes usar la propia aplicación IDE de Python para crear scripts de Python.
Creación de un proyecto de visor de PDF con PyCharm
Después de instalar el IDE PyCharm, crea un proyecto de Python en PyCharm siguiendo los pasos a continuación:
- Lanzar PyCharm: Abra PyCharm desde el lanzador de aplicaciones de su sistema o el acceso directo del escritorio.
Crear un Nuevo Proyecto: Haga clic en "Crear Nuevo Proyecto" o abra un proyecto Python existente.
 PyCharm IDE
PyCharm IDEConfigurar Configuración del Proyecto: Proporcione un nombre para su proyecto y elija la ubicación para crear el directorio del proyecto. Seleccione el intérprete de Python para su proyecto. Luego haga clic en "Crear".
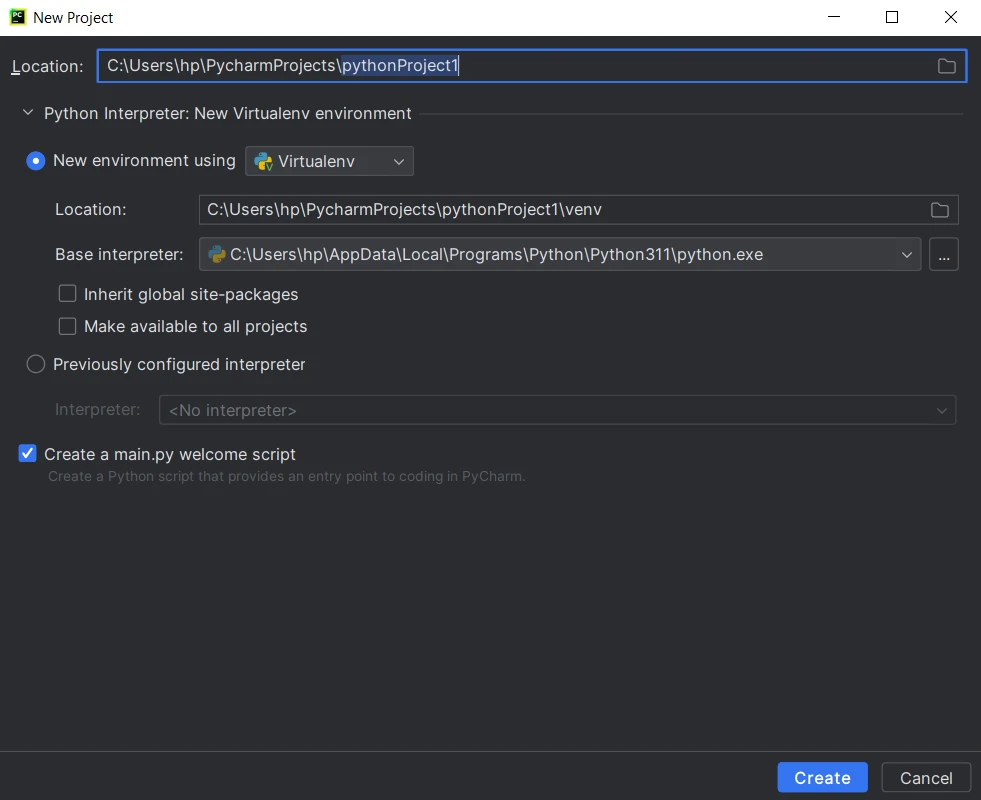 Crea un nuevo proyecto de Python
Crea un nuevo proyecto de Python- Crear Archivos Fuente: PyCharm creará la estructura del proyecto, incluyendo un archivo Python principal y un directorio para archivos fuente adicionales. Comience a escribir el código y haga clic en el botón de ejecución o presione Shift+F10 para ejecutar el script.
Pasos para ver archivos PDF en Python usando IronPDF
Importe las bibliotecas necesarias
Para comenzar, importa las bibliotecas necesarias. En este caso, se necesitarán las bibliotecas os, shutil, ironpdf, tkinter y PIL. Las bibliotecas os y shutil se utilizan para operaciones con archivos y carpetas, ironpdf es la biblioteca para trabajar con archivos PDF, tkinter se utiliza para crear la interfaz gráfica de usuario (GUI) y PIL se utiliza para la manipulación de imágenes.
import os
import shutil
import ironpdf
from tkinter import *
from PIL import Image, ImageTkimport os
import shutil
import ironpdf
from tkinter import *
from PIL import Image, ImageTkConvertir documentos PDF en imágenes
A continuación, defina una función llamada convert_pdf_to_images. Esta función toma como entrada la ruta del archivo PDF. Dentro de la función, se usa la biblioteca IronPDF para cargar el documento PDF desde el archivo. Luego, especifica una ruta de carpeta para almacenar los archivos de imagen extraídos. El método pdf.RasterizeToImageFiles de IronPDF se utiliza para convertir cada página del PDF en un archivo de imagen y guardarlo en la carpeta especificada. Se usa una lista para almacenar las rutas de las imágenes. El ejemplo de código completo es el siguiente:
def convert_pdf_to_images(pdf_file):
"""Convert each page of a PDF file to an image."""
pdf = ironpdf.PdfDocument.FromFile(pdf_file)
# Extract all pages to a folder as image files
folder_path = "images"
pdf.RasterizeToImageFiles(os.path.join(folder_path, "*.png"))
# List to store the image paths
image_paths = []
# Get the list of image files in the folder
for filename in os.listdir(folder_path):
if filename.lower().endswith((".png", ".jpg", ".jpeg", ".gif")):
image_paths.append(os.path.join(folder_path, filename))
return image_pathsdef convert_pdf_to_images(pdf_file):
"""Convert each page of a PDF file to an image."""
pdf = ironpdf.PdfDocument.FromFile(pdf_file)
# Extract all pages to a folder as image files
folder_path = "images"
pdf.RasterizeToImageFiles(os.path.join(folder_path, "*.png"))
# List to store the image paths
image_paths = []
# Get the list of image files in the folder
for filename in os.listdir(folder_path):
if filename.lower().endswith((".png", ".jpg", ".jpeg", ".gif")):
image_paths.append(os.path.join(folder_path, filename))
return image_pathsPara extraer texto de documentos PDF, visita esta página de ejemplos de código.
Manejar el cierre de ventanas
Para limpiar los archivos de imagen extraídos cuando se cierra la ventana de la aplicación, defina una función on_closing. Dentro de esta función, utilice el método shutil.rmtree() para eliminar toda la carpeta images. A continuación, establece esta función como el protocolo para ejecutarse cuando se cierra la ventana. El siguiente código ayuda a lograr la tarea:
def on_closing():
"""Handle the window closing event by cleaning up the images."""
# Delete the images in the 'images' folder
shutil.rmtree("images")
window.destroy()
window.protocol("WM_DELETE_WINDOW", on_closing)def on_closing():
"""Handle the window closing event by cleaning up the images."""
# Delete the images in the 'images' folder
shutil.rmtree("images")
window.destroy()
window.protocol("WM_DELETE_WINDOW", on_closing)Crear la ventana GUI
Ahora, creemos la ventana GUI principal usando el constructor Tk(), establezcamos el título de la ventana en "Visor de imágenes" y configuremos la función on_closing() como el protocolo para manejar el cierre de la ventana.
window = Tk()
window.title("Image Viewer")
window.protocol("WM_DELETE_WINDOW", on_closing)window = Tk()
window.title("Image Viewer")
window.protocol("WM_DELETE_WINDOW", on_closing)Crear un lienzo desplazable
Para mostrar las imágenes y habilitar el desplazamiento, cree un widget Canvas. El widget Canvas está configurado para llenar el espacio disponible y expandirse en ambas direcciones usando pack(side=LEFT, fill=BOTH, expand=True). Además, crea un widget Scrollbar y configúralo para controlar el desplazamiento vertical de todas las páginas y el lienzo.
canvas = Canvas(window)
canvas.pack(side=LEFT, fill=BOTH, expand=True)
scrollbar = Scrollbar(window, command=canvas.yview)
scrollbar.pack(side=RIGHT, fill=Y)
canvas.configure(yscrollcommand=scrollbar.set)
# Update the scrollregion to encompass the entire canvas
canvas.bind("<Configure>", lambda e: canvas.configure(
scrollregion=canvas.bbox("all")))
# Configure the vertical scrolling using mouse wheel
canvas.bind_all("<MouseWheel>", lambda e: canvas.yview_scroll(
int(-1*(e.delta/120)), "units"))canvas = Canvas(window)
canvas.pack(side=LEFT, fill=BOTH, expand=True)
scrollbar = Scrollbar(window, command=canvas.yview)
scrollbar.pack(side=RIGHT, fill=Y)
canvas.configure(yscrollcommand=scrollbar.set)
# Update the scrollregion to encompass the entire canvas
canvas.bind("<Configure>", lambda e: canvas.configure(
scrollregion=canvas.bbox("all")))
# Configure the vertical scrolling using mouse wheel
canvas.bind_all("<MouseWheel>", lambda e: canvas.yview_scroll(
int(-1*(e.delta/120)), "units"))Crear un marco para imágenes
A continuación, cree un widget Frame dentro del lienzo para contener las imágenes usando create_window() para colocar el marco dentro del lienzo. Las coordenadas (0, 0) y el parámetro anchor='nw' garantizan que el marco comience en la esquina superior izquierda del lienzo.
frame = Frame(canvas)
canvas.create_window((0, 0), window=frame, anchor="nw")frame = Frame(canvas)
canvas.create_window((0, 0), window=frame, anchor="nw")Convertir archivo PDF en imágenes y mostrar
El siguiente paso es llamar a la función convert_pdf_to_images() con la ruta del archivo PDF de entrada. Esta función extrae las páginas PDF como imágenes y devuelve una lista de rutas de imágenes. Al iterar a través de las rutas de las imágenes y cargar cada imagen utilizando el método Image.open() de la biblioteca PIL, se crea un objeto PhotoImage utilizando ImageTk.PhotoImage(). Luego crea un widget Label para mostrar la imagen.
images = convert_pdf_to_images("input.pdf")
# Load and display the images in the Frame
for image_path in images:
image = Image.open(image_path)
photo = ImageTk.PhotoImage(image)
label = Label(frame, image=photo)
label.image = photo # Store a reference to prevent garbage collection
label.pack(pady=10)images = convert_pdf_to_images("input.pdf")
# Load and display the images in the Frame
for image_path in images:
image = Image.open(image_path)
photo = ImageTk.PhotoImage(image)
label = Label(frame, image=photo)
label.image = photo # Store a reference to prevent garbage collection
label.pack(pady=10) El archivo de entrada
El archivo de entrada
Ejecutar el bucle principal de GUI
Por último, ejecutemos el bucle de evento principal usando window.mainloop(). Esto asegura que la ventana de la GUI permanezca abierta y receptiva hasta que sea cerrada por el usuario.
window.mainloop()window.mainloop() La salida de la UI
La salida de la UI
Conclusión
Este tutorial exploró cómo ver documentos PDF en Python usando la biblioteca IronPDF. Cubrió los pasos necesarios para abrir un archivo PDF y convertirlo en una serie de archivos de imagen, luego mostrarlos en un lienzo desplazable y manejar la limpieza de imágenes extraídas cuando se cierra la aplicación.
Para más detalles sobre la biblioteca IronPDF for Python, por favor consulta la documentación.
Descarga e instala la biblioteca IronPDF for Python y obtén también una prueba gratuita para probar su funcionalidad completa en el desarrollo comercial.
Preguntas Frecuentes
¿Cómo puedo ver archivos PDF en Python?
Puede usar la biblioteca IronPDF para ver archivos PDF en Python. Le permite convertir páginas de PDF en imágenes, las cuales pueden mostrarse en una aplicación GUI usando Tkinter.
¿Cuáles son los pasos necesarios para crear un visor de PDF en Python?
Para crear un visor de PDF en Python, necesita instalar IronPDF, usar Tkinter para la interfaz gráfica y Pillow para el procesamiento de imágenes. Convierta las páginas PDF en imágenes usando IronPDF y muéstrelas en un lienzo desplazable creado con Tkinter.
¿Cómo instalo IronPDF para usarlo en un proyecto de Python?
Puede instalar IronPDF usando pip ejecutando el comando pip install ironpdf en su terminal o símbolo del sistema.
¿Qué bibliotecas se requieren para construir una aplicación de visor de PDF en Python?
Necesitará IronPDF para manejo de PDFs, Tkinter para la interfaz gráfica y Pillow para el procesamiento de imágenes.
¿Puedo extraer imágenes de un PDF usando Python?
Sí, IronPDF le permite extraer imágenes de PDFs, las cuales pueden ser procesadas o mostradas usando la biblioteca Pillow.
¿Cómo puedo convertir una página de PDF en una imagen en Python?
Puede usar la funcionalidad de IronPDF para convertir páginas de PDF en formatos de imagen, que luego pueden ser manipuladas o mostradas en una aplicación Python.
¿Cómo manejo el cierre de ventana en una aplicación de visor de PDF en Python?
En una aplicación de visor de PDF, puede manejar el cierre de la ventana limpiando las imágenes extraídas y asegurándose de que todos los recursos sean liberados adecuadamente, a menudo usando las funciones de manejo de eventos de Tkinter.
¿Cómo puedo asegurar archivos PDF en Python?
IronPDF proporciona opciones para mejorar la seguridad de PDF añadiendo contraseñas y restricciones de uso a los archivos PDF.
¿Cuál es la ventaja de usar Tkinter en una aplicación de visualización de PDF?
Tkinter le permite crear una interfaz gráfica fácil de usar para su visor de PDF, habilitando funciones como vistas desplazables para navegar a través de las páginas del PDF.
¿Cuál es el propósito de usar Pillow en un proyecto de PDF?
Pillow se usa en un proyecto de PDF para procesar imágenes, como cargar y mostrar imágenes que han sido extraídas de archivos PDF usando IronPDF.
















