
Comment convertir HTML en PDF en C++
La capacité de convertir des fichiers ou du contenu HTML en pages PDF est une fonctionnalité précieuse dans de nombreuses applications. En C++, il peut être assez fastidieux de créer une application à partir de zéro pour générer des fichiers au format HTML vers PDF. Dans cet article, nous explorerons comment convertir HTML en PDF en C++ en utilisant la bibliothèque wkhtmltopdf.
Bibliothèque WKHTMLTOPDF
wkhtmltopdf est un outil en ligne de commande open-source qui transforme sans effort les pages en texte simple HTML en documents PDF de haute qualité. En tirant parti de ses fonctionnalités dans les programmes C++, nous pouvons facilement convertir du contenu de chaîne HTML en format PDF. Explorons le processus étape par étape de conversion de page HTML en PDF en C++ en utilisant la bibliothèque wkhtmltopdf.
Prérequis
Pour créer un convertisseur de fichier HTML en PDF en C++, assurez-vous que les prérequis suivants sont remplis :
- Un compilateur C++ comme GCC ou Clang installé sur votre système.
- bibliothèque wkhtmltopdf installée. Vous pouvez télécharger la dernière version depuis le site officiel de wkhtmltopdf et l'installer selon les instructions de votre système d'exploitation.
- Connaissances de base en programmation C++.
Créer un projet C++ HtmltoPdf dans Code::Blocks
Pour créer un projet de conversion PDF en C++ dans Code::Blocks, suivez ces étapes :
- Ouvrez l'IDE Code::Blocks.
- Allez dans le menu "File" et sélectionnez "New" puis "Project" pour ouvrir l'assistant de nouveau projet.
- Dans l'assistant de nouveau projet, sélectionnez "Console Application".
- Sélectionnez le langage C++.
- Définissez le titre du projet et l'emplacement où vous souhaitez le sauvegarder. Cliquez sur "Next" pour continuer.
- Sélectionnez le compilateur C++ approprié et l'objectif de construction, tel que Debug ou Release. Cliquez sur "Finish" pour créer le projet.
Configuration des répertoires de recherche
Pour garantir que Code::Blocks peut trouver les fichiers d'en-tête nécessaires, nous devons configurer les répertoires de recherche :
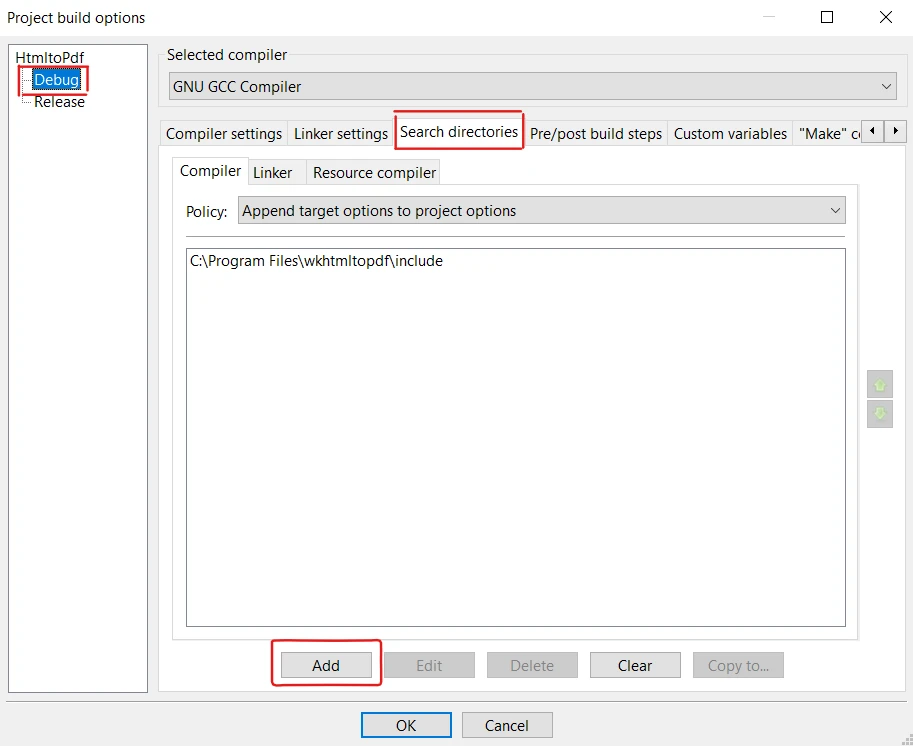
- Cliquez sur le menu "Projet" dans la barre de menu et sélectionnez "Options de compilation". Assurez-vous de sélectionner "Débogage".
- Dans la boîte de dialogue "Build options", sélectionnez l'onglet "Search directories".
- Sous l'onglet "Compilateur", cliquez sur le bouton "Ajouter".
- Parcourez le répertoire où se trouvent les fichiers d'en-tête wkhtmltox (par ex., C:\Program Files\wkhtmltopdf\include), et sélectionnez-le.
- Enfin, cliquez sur "OK" pour fermer la boîte de dialogue.
Liaison des bibliothèques
Pour lier la bibliothèque wkhtmltox, suivez ces étapes :
- Cliquez de nouveau sur le menu "Project" dans la barre de menus et sélectionnez "Build options". Assurez-vous de sélectionner "Débogage".
- Dans la boîte de dialogue "Build options", sélectionnez l'onglet "Linker settings".
- Sous l'onglet "Linker les bibliothèques", cliquez sur le bouton "Ajouter".
- Parcourez le répertoire où se trouvent les fichiers de la bibliothèque wkhtmltox (par ex., C:\Program Files\wkhtmltopdf\lib), et sélectionnez le fichier de bibliothèque approprié.
- Cliquez sur "Ouvrir" pour ajouter la bibliothèque à votre projet.
- Enfin, cliquez sur "OK" pour fermer la boîte de dialogue.

Étapes pour convertir facilement HTML en PDF en C++
Étape 1 : Inclure la bibliothèque pour convertir des fichiers HTML
Pour commencer, incluez les fichiers d'en-tête nécessaires pour utiliser les fonctionnalités de la bibliothèque wkhtmltopdf dans votre programme C++. Incluez les fichiers d'en-tête suivants au début du fichier de code source main.cpp comme indiqué dans l'exemple suivant :
#include <iostream>
#include <fstream>
#include <string>
#include <wkhtmltox/pdf.h>#include <iostream>
#include <fstream>
#include <string>
#include <wkhtmltox/pdf.h>Étape 2 : Initialisation du convertisseur
Pour convertir HTML en PDF, nous devons initialiser le convertisseur wkhtmltopdf. Le code se présente comme suit :
// Initialize the wkhtmltopdf library
wkhtmltopdf_init(false);
// Create global settings object
wkhtmltopdf_global_settings* gs = wkhtmltopdf_create_global_settings();
// Create object settings object
wkhtmltopdf_object_settings* os = wkhtmltopdf_create_object_settings();
// Create the PDF converter with global settings
wkhtmltopdf_converter* converter = wkhtmltopdf_create_converter(gs);// Initialize the wkhtmltopdf library
wkhtmltopdf_init(false);
// Create global settings object
wkhtmltopdf_global_settings* gs = wkhtmltopdf_create_global_settings();
// Create object settings object
wkhtmltopdf_object_settings* os = wkhtmltopdf_create_object_settings();
// Create the PDF converter with global settings
wkhtmltopdf_converter* converter = wkhtmltopdf_create_converter(gs);Étape 3 : Définition du contenu HTML
Maintenant, fournissons le contenu HTML qui doit être converti en PDF. Vous pouvez soit charger un fichier HTML, soit fournir directement la chaîne.
std::string htmlString = "<html><body><h1>Hello, World!</h1></body></html>";
// Add the HTML content to the converter
wkhtmltopdf_add_object(converter, os, htmlString.c_str());std::string htmlString = "<html><body><h1>Hello, World!</h1></body></html>";
// Add the HTML content to the converter
wkhtmltopdf_add_object(converter, os, htmlString.c_str());Étape 4 : Conversion de HTML en PDF
Avec le convertisseur et le contenu HTML prêts, nous pouvons procéder à la conversion du HTML en fichier PDF. Utilisez l'extrait de code suivant :
// Perform the actual conversion
if (!wkhtmltopdf_convert(converter)) {
std::cerr << "Conversion failed!" << std::endl;
}// Perform the actual conversion
if (!wkhtmltopdf_convert(converter)) {
std::cerr << "Conversion failed!" << std::endl;
}Étape 5 : Obtention du résultat sous forme de mémoire tampon
Avec la fonction wkhtmltopdf_get_output, nous pouvons obtenir les données PDF existantes sous forme de flux de mémoire tampon. Elle renvoie également la longueur du PDF. L'exemple suivant réalisera cette tâche :
// Retrieve the PDF data in memory buffer
const unsigned char* pdfData;
int pdfLength = wkhtmltopdf_get_output(converter, &pdfData);// Retrieve the PDF data in memory buffer
const unsigned char* pdfData;
int pdfLength = wkhtmltopdf_get_output(converter, &pdfData);Étape 6 : Sauvegarde du fichier PDF
Une fois la conversion terminée, nous devons sauvegarder le fichier PDF généré sur le disque. Spécifiez le chemin du fichier où vous souhaitez enregistrer le PDF. Ensuite, à l'aide d'un flux de fichier de sortie, ouvrez le fichier en mode binaire et écrivez le pdfData dedans. Enfin, fermez le fichier :
const char* outputPath = "file.pdf";
std::ofstream outputFile(outputPath, std::ios::binary);
// Write the PDF data to the file
outputFile.write(reinterpret_cast<const char*>(pdfData), pdfLength);
outputFile.close();const char* outputPath = "file.pdf";
std::ofstream outputFile(outputPath, std::ios::binary);
// Write the PDF data to the file
outputFile.write(reinterpret_cast<const char*>(pdfData), pdfLength);
outputFile.close();Étape 7 : Nettoyage
Après avoir converti HTML en PDF, il est essentiel de nettoyer les ressources allouées par wkhtmltopdf :
// Clean up the converter and settings
wkhtmltopdf_destroy_converter(converter);
wkhtmltopdf_destroy_object_settings(os);
wkhtmltopdf_destroy_global_settings(gs);
// Deinitialize the wkhtmltopdf library
wkhtmltopdf_deinit();
std::cout << "PDF saved successfully." << std::endl;// Clean up the converter and settings
wkhtmltopdf_destroy_converter(converter);
wkhtmltopdf_destroy_object_settings(os);
wkhtmltopdf_destroy_global_settings(gs);
// Deinitialize the wkhtmltopdf library
wkhtmltopdf_deinit();
std::cout << "PDF saved successfully." << std::endl;Étape 8 : Exécutez le code et générez le fichier PDF
Maintenant, construisez le projet et exécutez le code en utilisant F9. La sortie est générée et enregistrée dans le dossier du projet. Le PDF résultant est le suivant :
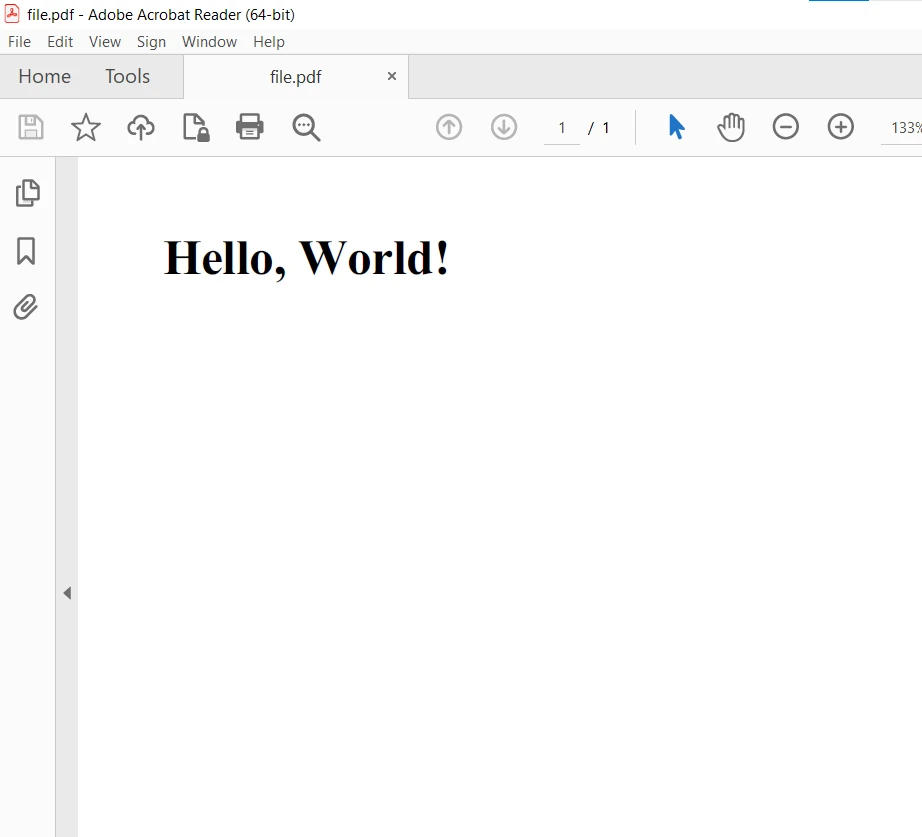
Convertir un fichier HTML en PDF avec C
IronPDF
IronPDF est une bibliothèque robuste .NET et .NET Core C# qui permet aux développeurs de générer facilement des documents PDF à partir de contenu HTML. Elle fournit une API simple et intuitive qui simplifie le processus de conversion des pages web HTML en PDF, en faisant un choix populaire pour diverses applications et cas d'utilisation.
L'un des principaux avantages de IronPDF est sa polyvalence. Elle prend en charge non seulement la conversion de documents HTML simples, mais aussi de pages web complexes avec styles CSS, interactions JavaScript et même du contenu dynamique. De plus, vous pouvez développer différents convertisseurs PDF avec un accès rapide à ses méthodes de conversion.
Voici l'exemple de code pour convertir HTML String en PDF en utilisant IronPDF en C# :
using IronPdf;
// Instantiate Renderer
var renderer = new ChromePdfRenderer();
// Create PDF content from an HTML string using C#
var pdf = renderer.RenderHtmlAsPdf("<h1>Hello World</h1>");
// Export to a file or Stream
pdf.SaveAs("output.pdf");using IronPdf;
// Instantiate Renderer
var renderer = new ChromePdfRenderer();
// Create PDF content from an HTML string using C#
var pdf = renderer.RenderHtmlAsPdf("<h1>Hello World</h1>");
// Export to a file or Stream
pdf.SaveAs("output.pdf");Imports IronPdf
' Instantiate Renderer
Private renderer = New ChromePdfRenderer()
' Create PDF content from an HTML string using C#
Private pdf = renderer.RenderHtmlAsPdf("<h1>Hello World</h1>")
' Export to a file or Stream
pdf.SaveAs("output.pdf")Le résultat PDF :
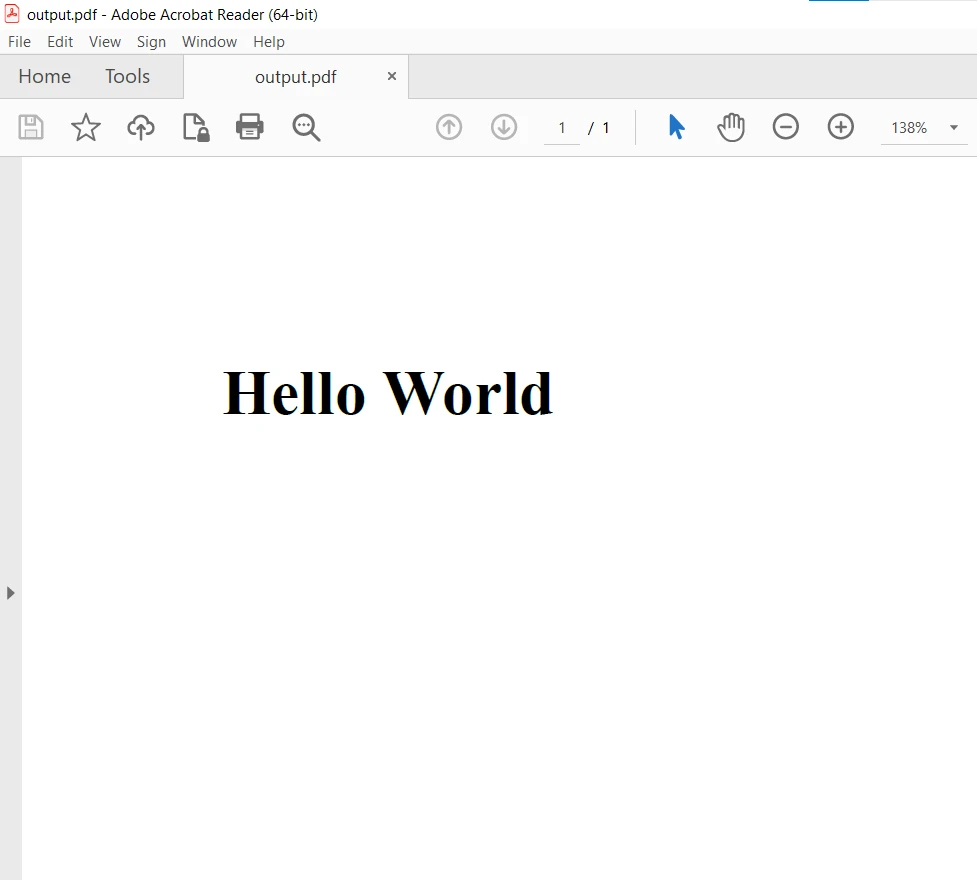
Pour plus de détails sur comment convertir différents fichiers HTML, URLs de pages web et images en PDF, veuillez visiter ces Exemples de code HTML vers PDF.
Avec IronPDF, la génération de fichiers PDF à partir de contenu HTML devient une tâche simple dans les langages du .NET Framework. Son API intuitive et son ensemble de fonctionnalités étendu en font un outil précieux pour les développeurs souhaitant convertir HTML en PDF dans leurs projets C#. Que ce soit pour générer des rapports, des factures, ou tout autre document nécessitant une conversion HTML en PDF précise, IronPDF est une solution fiable et efficace.
IronPDF est gratuit pour le développement, mais pour une utilisation commerciale, il doit être sous licence. Il fournit également un essai gratuit de la version complète d'IronPDF pour un usage commercial afin de tester sa fonctionnalité complète. Vous pouvez télécharger le logiciel depuis télécharger IronPDF.














