
Comment lire des fichiers PDF en C++
Les fichiers PDF (Portable Document Format) sont largement utilisés pour l'échange de documents, et pouvoir lire leur contenu par programme est précieux dans diverses applications. Les bibliothèques suivantes sont disponibles pour lire des PDF en C++ : Poppler, MuPDF, Haru free PDF library, Xpdf, et Qpdf.
Dans cet article, nous explorerons comment lire des fichiers PDF en C++ en utilisant l'outil en ligne de commande Xpdf. Xpdf fournit une gamme d'utilitaires pour travailler avec des fichiers PDF, y compris pour extraire le contenu textuel. En intégrant Xpdf dans un programme C++, nous pouvons extraire le texte des fichiers PDF et le traiter par programme.
Xpdf - Outils en ligne de commande
Xpdf est une suite logicielle open-source qui fournit une collection d'outils et de bibliothèques pour travailler avec des fichiers PDF (Portable Document Format). La suite Xpdf inclut plusieurs utilitaires en ligne de commande et bibliothèques C++ qui permettent diverses fonctionnalités liées aux PDF, telles que l'analyse, le rendu, l'extraction de texte, et plus encore. Certains des composants clés de Xpdf incluent pdfimages, pdftops, pdfinfo, et pdftotext. Ici, nous allons utiliser pdftotext pour lire des documents PDF.
pdftotext est un outil en ligne de commande qui extrait le contenu textuel des fichiers PDF et le restitue sous forme de texte brut. Cet outil est particulièrement utile lorsque vous devez extraire l'information textuelle des PDF pour un traitement ou une analyse ultérieure. En utilisant des options, vous pouvez également spécifier quelle page ou quelles pages extraire le texte.
Prérequis
Pour créer un projet de lecteur PDF pour extraire du texte, nous avons besoin que les prérequis suivants soient en place :
- Un compilateur C++ comme GCC ou Clang installé sur votre système. Vous pouvez utiliser n'importe quel IDE qui prend en charge la programmation C++.
- Outils en ligne de commande Xpdf installés sur votre système. Xpdf est une collection d'utilitaires PDF qui peut être obtenue depuis le site Web de Xpdf. Téléchargez-le à partir du site Web de Xpdf. Définissez le répertoire bin de Xpdf dans le chemin des variables d'environnement pour y accéder de n'importe où en utilisant l'outil en ligne de commande.
Étapes pour lire le format de fichier PDF en C++
Étape 1 : Inclure les en-têtes nécessaires
Tout d'abord, ajoutons les fichiers d'en-tête nécessaires dans notre fichier main.cpp en haut :
#include <cstdlib> // For system call
#include <iostream> // For basic input and output
#include <fstream> // For file stream operations#include <cstdlib> // For system call
#include <iostream> // For basic input and output
#include <fstream> // For file stream operationsÉtape 2 : Écrire le code C++
Écrivons le code C++ qui invoque l'outil en ligne de commande Xpdf pour extraire le contenu textuel du document PDF. Nous allons utiliser le fichier suivant input.pdf :

L'exemple de code est le suivant :
#include <cstdlib>
#include <iostream>
#include <fstream>
using namespace std;
int main() {
// Specify the input and output file paths
string pdfPath = "input.pdf";
string outputFilePath = "output.txt";
// Construct the command to run pdftotext
string command = "pdftotext " + pdfPath + " " + outputFilePath;
int status = system(command.c_str());
// Check if the command executed successfully
if (status == 0) {
cout << "Text extraction successful." << endl;
} else {
cout << "Text extraction failed." << endl;
return 1; // Exit the program with error code
}
// Open the output file to read the extracted text
ifstream outputFile(outputFilePath);
if (outputFile.is_open()) {
string textContent;
string line;
while (getline(outputFile, line)) {
textContent += line + "\n"; // Append each line to the textContent
}
outputFile.close();
// Display the extracted text
cout << "Text content extracted from PDF document:" << endl;
cout << textContent << endl;
} else {
cout << "Failed to open output file." << endl;
return 1; // Exit the program with error code
}
return 0; // Exit the program successfully
}#include <cstdlib>
#include <iostream>
#include <fstream>
using namespace std;
int main() {
// Specify the input and output file paths
string pdfPath = "input.pdf";
string outputFilePath = "output.txt";
// Construct the command to run pdftotext
string command = "pdftotext " + pdfPath + " " + outputFilePath;
int status = system(command.c_str());
// Check if the command executed successfully
if (status == 0) {
cout << "Text extraction successful." << endl;
} else {
cout << "Text extraction failed." << endl;
return 1; // Exit the program with error code
}
// Open the output file to read the extracted text
ifstream outputFile(outputFilePath);
if (outputFile.is_open()) {
string textContent;
string line;
while (getline(outputFile, line)) {
textContent += line + "\n"; // Append each line to the textContent
}
outputFile.close();
// Display the extracted text
cout << "Text content extracted from PDF document:" << endl;
cout << textContent << endl;
} else {
cout << "Failed to open output file." << endl;
return 1; // Exit the program with error code
}
return 0; // Exit the program successfully
}Explication du code
Dans le code ci-dessus, la variable pdfPath est définie pour contenir le chemin d'accès au fichier PDF d'entrée. Veillez à la remplacer par le chemin d'accès correct à votre document PDF.
Nous définissons également la variable outputFilePath pour contenir le chemin d'accès au fichier texte de sortie qui sera généré par Xpdf.
Le code exécute la commande pdftotext en utilisant la fonction system, en passant le chemin du fichier PDF d'entrée et le chemin du fichier texte de sortie comme arguments de ligne de commande. La variable status capture le statut de sortie de la commande.
Si pdftotext s'exécute avec succès (indiqué par un statut de 0), nous procédons à l'ouverture du fichier texte de sortie à l'aide de ifstream. Nous lisons ensuite le contenu du texte ligne par ligne et le stockons dans la chaîne textContent.
Enfin, nous affichons le contenu texte extrait dans la console depuis le fichier de sortie généré. Si vous n'avez pas besoin du fichier texte de sortie modifiable ou si vous souhaitez libérer de l'espace disque, à la fin du programme, il suffit de le supprimer avant de terminer la fonction main avec la commande suivante :
remove(outputFilePath.c_str());remove(outputFilePath.c_str());Étape 3 : Compiler et exécuter le programme
Compilez le code C++ et exécutez l'exécutable. Si le pdftotext est ajouté au chemin système des variables d'environnement, sa commande s'exécutera avec succès. Le programme génère le fichier texte de sortie et extrait le contenu textuel du document PDF. Le texte extrait est ensuite affiché sur la console.
La sortie est la suivante :
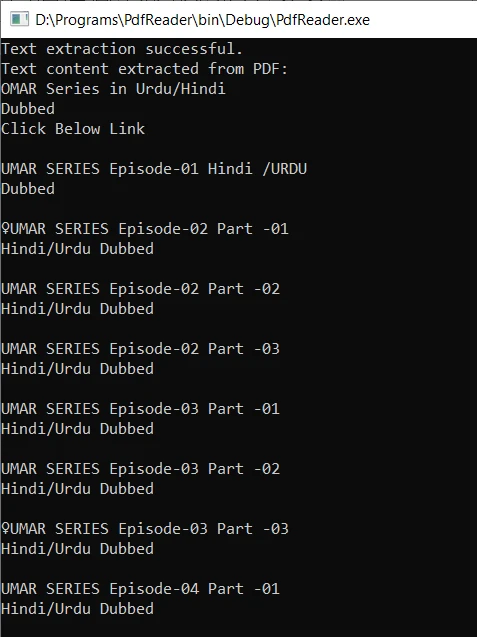
Lire des fichiers PDF en C
La bibliothèque IronPDF
IronPDF est une bibliothèque PDF populaire pour C# qui fournit de puissantes fonctionnalités pour travailler avec des documents PDF. Elle permet aux développeurs de créer, éditer, modifier, et lire des fichiers PDF par programme.
Lire des documents PDF en utilisant la bibliothèque IronPDF est un processus simple. La bibliothèque offre diverses méthodes et propriétés qui permettent aux développeurs d'extraire du texte, des images, des métadonnées, et d'autres données des pages PDF. Les informations extraites peuvent être utilisées pour un traitement ultérieur, une analyse, ou un affichage dans l'application.
L'exemple de code suivant va utiliser IronPDF pour lire des fichiers PDF :
// Import necessary namespaces
using IronPdf; // For PDF functionalities
using IronSoftware.Drawing; // For handling images
using System.Collections.Generic; // For using the List
// Example of extracting text and images from PDF using IronPDF
// Open a 128-bit encrypted PDF
var pdf = PdfDocument.FromFile("encrypted.pdf", "password");
// Get all text from the PDF
string text = pdf.ExtractAllText();
// Extract all images from the PDF
var allImages = pdf.ExtractAllImages();
// Iterate over each page to extract text and images
for (var index = 0; index < pdf.PageCount; index++) {
int pageNumber = index + 1;
text = pdf.ExtractTextFromPage(index);
List<AnyBitmap> images = pdf.ExtractBitmapsFromPage(index);
// Perform actions with text and images...
}// Import necessary namespaces
using IronPdf; // For PDF functionalities
using IronSoftware.Drawing; // For handling images
using System.Collections.Generic; // For using the List
// Example of extracting text and images from PDF using IronPDF
// Open a 128-bit encrypted PDF
var pdf = PdfDocument.FromFile("encrypted.pdf", "password");
// Get all text from the PDF
string text = pdf.ExtractAllText();
// Extract all images from the PDF
var allImages = pdf.ExtractAllImages();
// Iterate over each page to extract text and images
for (var index = 0; index < pdf.PageCount; index++) {
int pageNumber = index + 1;
text = pdf.ExtractTextFromPage(index);
List<AnyBitmap> images = pdf.ExtractBitmapsFromPage(index);
// Perform actions with text and images...
}' Import necessary namespaces
Imports IronPdf ' For PDF functionalities
Imports IronSoftware.Drawing ' For handling images
Imports System.Collections.Generic ' For using the List
' Example of extracting text and images from PDF using IronPDF
' Open a 128-bit encrypted PDF
Private pdf = PdfDocument.FromFile("encrypted.pdf", "password")
' Get all text from the PDF
Private text As String = pdf.ExtractAllText()
' Extract all images from the PDF
Private allImages = pdf.ExtractAllImages()
' Iterate over each page to extract text and images
For index = 0 To pdf.PageCount - 1
Dim pageNumber As Integer = index + 1
text = pdf.ExtractTextFromPage(index)
Dim images As List(Of AnyBitmap) = pdf.ExtractBitmapsFromPage(index)
' Perform actions with text and images...
Next indexPour plus d'informations détaillées sur la lecture de documents PDF, veuillez visiter le Guide de Lecture de PDF IronPDF C#.
Conclusion
Dans cet article, nous avons appris comment lire le contenu d'un document PDF en C++ en utilisant l'outil en ligne de commande Xpdf. En intégrant Xpdf dans un programme C++, nous pouvons extraire le contenu texte des fichiers PDF par programme en quelques secondes. Cette approche nous permet de traiter et d'analyser le texte extrait dans nos applications C++.
IronPDF est une bibliothèque C# puissante qui facilite la lecture et la manipulation des fichiers PDF. Ses nombreuses fonctionnalités, sa facilité d'utilisation, et son moteur de rendu fiable en font un choix populaire pour les développeurs travaillant avec des documents PDF dans leurs projets C#.
IronPDF est gratuit pour le développement et propose un essai gratuit pour une utilisation commerciale. Au-delà de cela, il doit être licencié à des fins commerciales.














