Çevrimiçi Araçlarla PDF Belgesi Nasıl İmzalanır
PDF (Taşınabilir Belge Biçimi) dosyaları, belge değiş tokuşu için yaygın olarak kullanılır ve içeriklerini programatik olarak okuyabilmek, çeşitli uygulamalar için değerlidir. C++'da PDF okumak için mevcut kütüphaneler şunlardır: Poppler, MuPDF, Haru ücretsiz PDF kütüphanesi, Xpdf ve Qpdf.
Bu makalede, Xpdf komut satırı aracını kullanarak C++'da PDF dosyalarını nasıl okuyacağımızı inceleyeceğiz. Xpdf, PDF dosyaları ile çalışmak için çeşitli yardımcı programlar sunar, metin içeriğini çıkartma dahil olmak üzere. Xpdf'i bir C++ programına entegre ederek, PDF dosyalarından metin çıkarabilir ve bunu programatik olarak işleyebiliriz.
Xpdf - Komut Satırı Araçları
Xpdf, PDF (Taşınabilir Belge Biçimi) dosyalarıyla çalışmak için bir araç ve kütüphane koleksiyonu sunan açık kaynaklı bir yazılım setidir. Xpdf suite, ayrıştırma, işleme, metin çıkarma ve daha birçok PDF ile ilgili fonksiyonları sağlayan birkaç komut satırı yardımcı programları ve C++ kütüphanelerini içerir. Xpdf'in bazı ana bileşenleri pdfimages, pdftops, pdfinfo ve pdftotext içerir. Burada, PDF belgelerini okumak için pdftotext kullanacağız.
pdftotext, PDF dosyalarından metin içeriğini çıkarıp düz metin olarak çıktı veren bir komut satırı aracıdır. Bu araç, PDF'lerden çıkarılan metinsel bilgileri daha fazla işlem veya analiz için çıkartmanız gerektiğinde özellikle faydalıdır. Seçenekleri kullanarak, hangi sayfanın veya sayfaların metninin çıkarılacağını da belirleyebilirsiniz.
Gereksinimler
Metin çıkarmak için bir PDF okuma projesi yapmak için, aşağıdaki ön koşullara ihtiyacımız var:
- Sisteminizde yüklü bir C++ derleyicisi, örneğin GCC veya Clang. C++ programlamayı destekleyen herhangi bir IDE'yi kullanabilirsiniz.
- Sisteminizde yüklü Xpdf komut satırı araçları. Xpdf, Xpdf web sitesinden elde edilebilecek bir PDF yardımcı programlar koleksiyonudur. Xpdf Web Sitesinden indirin. Komut satırı aracı kullanarak her yerden erişmek için Xpdf'in bin dizinini Ortam değişkenleri yoluna ayarlayın.
C++ ile PDF Dosya Formatını Okuma Adımları
Adım 1: Gerekli Başlıkları Dahil Etme
İlk olarak, gerekli başlık dosyalarını main.cpp dosyamızın en üstüne ekleyelim:
#include <cstdlib> // For system call
#include <iostream> // For basic input and output
#include <fstream> // For file stream operations#include <cstdlib> // For system call
#include <iostream> // For basic input and output
#include <fstream> // For file stream operationsAdım 2: C++ Kodu Yazma
PDF belgesinden metin içeriğini çıkarmak için Xpdf komut satırı aracını çağıran C++ kodunu yazalım. Aşağıdaki input.pdf dosyasını kullanacağız:

Kod örneği şu şekildedir:
#include <cstdlib>
#include <iostream>
#include <fstream>
using namespace std;
int main() {
// Specify the input and output file paths
string pdfPath = "input.pdf";
string outputFilePath = "output.txt";
// Construct the command to run pdftotext
string command = "pdftotext " + pdfPath + " " + outputFilePath;
int status = system(command.c_str());
// Check if the command executed successfully
if (status == 0) {
cout << "Text extraction successful." << endl;
} else {
cout << "Text extraction failed." << endl;
return 1; // Exit the program with error code
}
// Open the output file to read the extracted text
ifstream outputFile(outputFilePath);
if (outputFile.is_open()) {
string textContent;
string line;
while (getline(outputFile, line)) {
textContent += line + "\n"; // Append each line to the textContent
}
outputFile.close();
// Display the extracted text
cout << "Text content extracted from PDF document:" << endl;
cout << textContent << endl;
} else {
cout << "Failed to open output file." << endl;
return 1; // Exit the program with error code
}
return 0; // Exit the program successfully
}#include <cstdlib>
#include <iostream>
#include <fstream>
using namespace std;
int main() {
// Specify the input and output file paths
string pdfPath = "input.pdf";
string outputFilePath = "output.txt";
// Construct the command to run pdftotext
string command = "pdftotext " + pdfPath + " " + outputFilePath;
int status = system(command.c_str());
// Check if the command executed successfully
if (status == 0) {
cout << "Text extraction successful." << endl;
} else {
cout << "Text extraction failed." << endl;
return 1; // Exit the program with error code
}
// Open the output file to read the extracted text
ifstream outputFile(outputFilePath);
if (outputFile.is_open()) {
string textContent;
string line;
while (getline(outputFile, line)) {
textContent += line + "\n"; // Append each line to the textContent
}
outputFile.close();
// Display the extracted text
cout << "Text content extracted from PDF document:" << endl;
cout << textContent << endl;
} else {
cout << "Failed to open output file." << endl;
return 1; // Exit the program with error code
}
return 0; // Exit the program successfully
}Kod Açıklaması
Yukarıdaki kodda, girdi PDF dosyasının yolunu tutmak için pdfPath değişkenini tanımlıyoruz. Onu, gerçek girdi PDF belgenizin uygun yolu ile değiştirdiğinizden emin olun.
Ayrıca, Xpdf tarafından üretilecek çıktı metin dosyasının yolunu tutmak için outputFilePath değişkenini tanımlıyoruz.
Kod, system işlevini kullanarak, girdi PDF dosyası yolunu ve çıktı metin dosyası yolunu komut satırı argümanları olarak geçerek pdftotext komutunu çalıştırır. status değişkeni, komutun çıkış durumunu yakalar.
pdftotext başarıyla çalıştırılırsa (0 durumu ile belirtilir), ifstream kullanarak çıktı metin dosyasını açmaya devam ederiz. Ardından, metin içeriğini satır satır okuyup textContent dizgesinde saklarız.
Son olarak, üretilen çıktı dosyasından konsola çıkarılmış metin içeriğini çıkartıyoruz. Düzenlenebilir metin dosyasına ihtiyacınız yoksa veya disk alanını boşaltmak istiyorsanız, ana işlevi bitirmeden önce aşağıdaki komutla programın sonunda basitçe silin:
remove(outputFilePath.c_str());remove(outputFilePath.c_str());Adım 3: Programı Derleme ve Çalıştırma
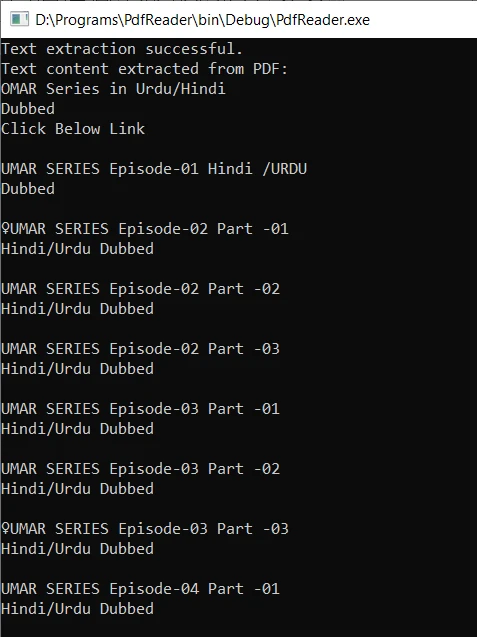
C++ kodunu derleyin ve çalıştırılabilir dosyayı başlatın. Eğer pdftotext, Ortam Değişkenleri Sistem Yoluna eklenirse, komutu başarıyla çalışacaktır. Program, çıktıyı metin dosyasını üretir ve PDF belgesinden metin içeriğini çıkarır. Çıkarılan metin daha sonra konsolda görüntülenir.
Çıktı şu şekilde
C#'ta PDF dosyalarını okuyun
IronPDF Kütüphanesi
IronPDF, PDF belgeleriyle çalışmak için güçlü işlevler sunan popüler bir C# PDF kütüphanesidir. Geliştiricilerin PDF dosyalarını programlı olarak oluşturmasına, düzenlemesine, değiştirmesine ve okumasına olanak tanır.
IronPDF kütüphanesini kullanarak PDF belgelerini okumak basit bir süreçtir. Kütüphane, geliştiricilerin PDF sayfalarından metin, görseller, meta veriler ve diğer verileri çıkarmalarına olanak tanıyan çeşitli yöntemler ve özellikler sunar. Çıkarılan bilgiler, uygulama içerisinde daha fazla işleme, analize veya görüntülemeye tabi tutulabilir.
Aşağıdaki kod örneği, IronPDF kullanarak PDF dosyalarını okuyacaktır:
// Import necessary namespaces
using IronPdf; // For PDF functionalities
using IronSoftware.Drawing; // For handling images
using System.Collections.Generic; // For using the List
// Example of extracting text and images from PDF using IronPDF
// Open a 128-bit encrypted PDF
var pdf = PdfDocument.FromFile("encrypted.pdf", "password");
// Get all text from the PDF
string text = pdf.ExtractAllText();
// Extract all images from the PDF
var allImages = pdf.ExtractAllImages();
// Iterate over each page to extract text and images
for (var index = 0; index < pdf.PageCount; index++) {
int pageNumber = index + 1;
text = pdf.ExtractTextFromPage(index);
List<AnyBitmap> images = pdf.ExtractBitmapsFromPage(index);
// Perform actions with text and images...
}// Import necessary namespaces
using IronPdf; // For PDF functionalities
using IronSoftware.Drawing; // For handling images
using System.Collections.Generic; // For using the List
// Example of extracting text and images from PDF using IronPDF
// Open a 128-bit encrypted PDF
var pdf = PdfDocument.FromFile("encrypted.pdf", "password");
// Get all text from the PDF
string text = pdf.ExtractAllText();
// Extract all images from the PDF
var allImages = pdf.ExtractAllImages();
// Iterate over each page to extract text and images
for (var index = 0; index < pdf.PageCount; index++) {
int pageNumber = index + 1;
text = pdf.ExtractTextFromPage(index);
List<AnyBitmap> images = pdf.ExtractBitmapsFromPage(index);
// Perform actions with text and images...
}' Import necessary namespaces
Imports IronPdf ' For PDF functionalities
Imports IronSoftware.Drawing ' For handling images
Imports System.Collections.Generic ' For using the List
' Example of extracting text and images from PDF using IronPDF
' Open a 128-bit encrypted PDF
Private pdf = PdfDocument.FromFile("encrypted.pdf", "password")
' Get all text from the PDF
Private text As String = pdf.ExtractAllText()
' Extract all images from the PDF
Private allImages = pdf.ExtractAllImages()
' Iterate over each page to extract text and images
For index = 0 To pdf.PageCount - 1
Dim pageNumber As Integer = index + 1
text = pdf.ExtractTextFromPage(index)
Dim images As List(Of AnyBitmap) = pdf.ExtractBitmapsFromPage(index)
' Perform actions with text and images...
Next indexPDF belgelerini nasıl okuyacağınız hakkında daha detaylı bilgi için, IronPDF C# PDF Okuma Kılavuzunu ziyaret ediniz.
Sonuç
Bu makalede, Xpdf komut satırı aracını kullanarak C++ ile bir PDF belgesinin içeriğini nasıl okuyacağımızı öğrendik. Xpdf'yi bir C++ programına entegre ederek, PDF dosyalarından metin içeriğini saniyeler içinde programlı olarak çıkarabiliriz. Bu yaklaşım, çıkarılan metni C++ uygulamalarımızda işlememize ve analiz etmemize olanak tanır.
IronPDF, PDF dosyalarını okumayı ve manipüle etmeyi kolaylaştıran güçlü bir C# kütüphanesidir. Geniş kapsamlı özellikleri, kullanımı kolay yapısı ve güvenilir işleme motoru, C# projelerinde PDF belgeleriyle çalışan geliştiriciler için popüler bir seçim haline getirir.
IronPDF geliştirme için ücretsizdir ve ticari kullanım için ücretsiz deneme sağlar. Bunun ötesinde, ticari amaçlarla lisanslanması gereklidir.