How to Read PDF Files in C++
PDF (Portable Document Format) files are widely used for document exchange, and being able to programmatically read their contents is valuable in various applications. The following libraries are available to read PDF in C++: Poppler, MuPDF, Haru free PDF library, Xpdf, and Qpdf.
In this article, we will explore how to read PDF files in C++ using the Xpdf command-line tool. Xpdf provides a range of utilities for working with PDF files, including extracting text content. By integrating Xpdf into a C++ program, we can extract the text from PDF files and process it programmatically.
Xpdf - Command-line Tools
Xpdf is an open-source software suite that provides a collection of tools and libraries for working with PDF (Portable Document Format) files. The Xpdf suite includes several command-line utilities and C++ libraries that enable various PDF-related functionalities, such as parsing, rendering, text extraction, and more. Some key components of Xpdf include pdfimages, pdftops, pdfinfo, and pdftotext. Here, we are going to use pdftotext to read PDF documents.
pdftotext is a command-line tool that extracts text content from PDF files and outputs it as plain text. This tool is particularly useful when you need to extract the textual information from PDFs for further processing or analysis. Using options, you can also specify which page or pages to extract text from.
Prerequisites
To make a PDF reader project to extract text, we need the following prerequisites to be in place:
- A C++ compiler such as GCC or Clang installed on your system. You can use any IDE that supports C++ programming.
- Xpdf command-line tools installed on your system. Xpdf is a collection of PDF utilities that can be obtained from the Xpdf website. Download it from the Xpdf Website. Set the bin directory of Xpdf in the Environment variables path, to access it from anywhere using the command-line tool.
Steps to Read PDF File Format in C++
Step 1: Including the Necessary Headers
First, let's add the necessary header files in our main.cpp file at the top:
#include <cstdlib> // For system call
#include <iostream> // For basic input and output
#include <fstream> // For file stream operations#include <cstdlib> // For system call
#include <iostream> // For basic input and output
#include <fstream> // For file stream operationsStep 2: Writing the C++ Code
Let's write the C++ code that invokes the Xpdf command-line tool to extract text content from the PDF document. We are going to use the following input.pdf file:

The code example goes as follows:
#include <cstdlib>
#include <iostream>
#include <fstream>
using namespace std;
int main() {
// Specify the input and output file paths
string pdfPath = "input.pdf";
string outputFilePath = "output.txt";
// Construct the command to run pdftotext
string command = "pdftotext " + pdfPath + " " + outputFilePath;
int status = system(command.c_str());
// Check if the command executed successfully
if (status == 0) {
cout << "Text extraction successful." << endl;
} else {
cout << "Text extraction failed." << endl;
return 1; // Exit the program with error code
}
// Open the output file to read the extracted text
ifstream outputFile(outputFilePath);
if (outputFile.is_open()) {
string textContent;
string line;
while (getline(outputFile, line)) {
textContent += line + "\n"; // Append each line to the textContent
}
outputFile.close();
// Display the extracted text
cout << "Text content extracted from PDF document:" << endl;
cout << textContent << endl;
} else {
cout << "Failed to open output file." << endl;
return 1; // Exit the program with error code
}
return 0; // Exit the program successfully
}#include <cstdlib>
#include <iostream>
#include <fstream>
using namespace std;
int main() {
// Specify the input and output file paths
string pdfPath = "input.pdf";
string outputFilePath = "output.txt";
// Construct the command to run pdftotext
string command = "pdftotext " + pdfPath + " " + outputFilePath;
int status = system(command.c_str());
// Check if the command executed successfully
if (status == 0) {
cout << "Text extraction successful." << endl;
} else {
cout << "Text extraction failed." << endl;
return 1; // Exit the program with error code
}
// Open the output file to read the extracted text
ifstream outputFile(outputFilePath);
if (outputFile.is_open()) {
string textContent;
string line;
while (getline(outputFile, line)) {
textContent += line + "\n"; // Append each line to the textContent
}
outputFile.close();
// Display the extracted text
cout << "Text content extracted from PDF document:" << endl;
cout << textContent << endl;
} else {
cout << "Failed to open output file." << endl;
return 1; // Exit the program with error code
}
return 0; // Exit the program successfully
}Code Explanation
In the above code, we define the pdfPath variable to hold the path to the input PDF file. Make sure to replace it with the appropriate path to your actual input PDF document.
We also define the outputFilePath variable to hold the path to the output text file that will be generated by Xpdf.
The code executes the pdftotext command using the system function, passing the input PDF file path and output text file path as command-line arguments. The status variable captures the exit status of the command.
If pdftotext executes successfully (indicated by a status of 0), we proceed to open the output text file using ifstream. We then read the text content line by line and store it in the textContent string.
Finally, we output the extracted text content to the console from the output file generated. If you do not need the editable output text file or want to free up disk space, at the end of the program simply delete it using the following command before ending the main function:
remove(outputFilePath.c_str());remove(outputFilePath.c_str());Step 3: Compiling and Running the Program
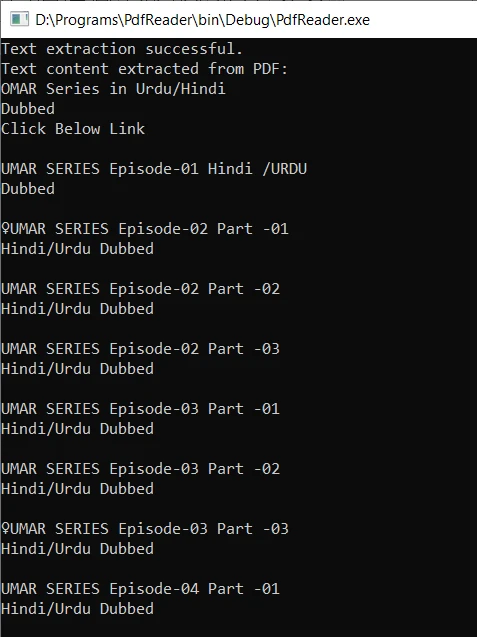
Compile the C++ code and run the executable. If the pdftotext is added to the Environment Variables System Path, its command will execute successfully. The program generates the output text file and extracts text content from the PDF document. The extracted text is then displayed on the console.
The output is as follows
Read PDF files in C#
IronPDF Library
IronPDF is a popular C# PDF library that provides powerful functionalities for working with PDF documents. It enables developers to create, edit, modify, and read PDF files programmatically.
Reading PDF documents using the IronPDF library is a straightforward process. The library offers various methods and properties that enable developers to extract text, images, metadata, and other data from PDF pages. The extracted information can be used for further processing, analysis, or display within the application.
Following code example will use IronPDF to read PDF files:
// Import necessary namespaces
using IronPdf; // For PDF functionalities
using IronSoftware.Drawing; // For handling images
using System.Collections.Generic; // For using the List
// Example of extracting text and images from PDF using IronPDF
// Open a 128-bit encrypted PDF
var pdf = PdfDocument.FromFile("encrypted.pdf", "password");
// Get all text from the PDF
string text = pdf.ExtractAllText();
// Extract all images from the PDF
var allImages = pdf.ExtractAllImages();
// Iterate over each page to extract text and images
for (var index = 0; index < pdf.PageCount; index++) {
int pageNumber = index + 1;
text = pdf.ExtractTextFromPage(index);
List<AnyBitmap> images = pdf.ExtractBitmapsFromPage(index);
// Perform actions with text and images...
}// Import necessary namespaces
using IronPdf; // For PDF functionalities
using IronSoftware.Drawing; // For handling images
using System.Collections.Generic; // For using the List
// Example of extracting text and images from PDF using IronPDF
// Open a 128-bit encrypted PDF
var pdf = PdfDocument.FromFile("encrypted.pdf", "password");
// Get all text from the PDF
string text = pdf.ExtractAllText();
// Extract all images from the PDF
var allImages = pdf.ExtractAllImages();
// Iterate over each page to extract text and images
for (var index = 0; index < pdf.PageCount; index++) {
int pageNumber = index + 1;
text = pdf.ExtractTextFromPage(index);
List<AnyBitmap> images = pdf.ExtractBitmapsFromPage(index);
// Perform actions with text and images...
}' Import necessary namespaces
Imports IronPdf ' For PDF functionalities
Imports IronSoftware.Drawing ' For handling images
Imports System.Collections.Generic ' For using the List
' Example of extracting text and images from PDF using IronPDF
' Open a 128-bit encrypted PDF
Private pdf = PdfDocument.FromFile("encrypted.pdf", "password")
' Get all text from the PDF
Private text As String = pdf.ExtractAllText()
' Extract all images from the PDF
Private allImages = pdf.ExtractAllImages()
' Iterate over each page to extract text and images
For index = 0 To pdf.PageCount - 1
Dim pageNumber As Integer = index + 1
text = pdf.ExtractTextFromPage(index)
Dim images As List(Of AnyBitmap) = pdf.ExtractBitmapsFromPage(index)
' Perform actions with text and images...
Next indexFor more detailed information on how to read PDF documents, please visit the IronPDF C# PDF Reading Guide.
Conclusion
In this article, we learned how to read the contents of a PDF document in C++ using the Xpdf command-line tool. By integrating Xpdf into a C++ program, we can programmatically extract text content from PDF files within seconds. This approach enables us to process and analyze the extracted text within our C++ applications.
IronPDF is a powerful C# library that facilitates reading and manipulating PDF files. Its extensive features, ease of use, and reliable rendering engine make it a popular choice for developers working with PDF documents in their C# projects.
IronPDF is free for development and provides a free trial for commercial use. Beyond this, it needs to be licensed for commercial purposes.