
How to Read PDF Files in C#
Programmatic PDF processing is crucial in industries like finance, healthcare, legal, and education, where critical information needs to be processed, analyzed, and extracted from PDF documents for purposes such as data analysis, document management, and automation. Despite its importance, this task can be challenging.
IronPDF: A C# PDF Library
IronPDF enables you to handle incredibly difficult tasks easily. It allows for the easy editing of text in a PDF document, in a similar way to how you can work with text files in a text document, all the while allowing you to export files in any operating system. The IronPDF application covers the complete process of viewing, modifying, and extracting content from a PDF.
Take the Right Step with IronPDF
Text can be read and written in PDF file format quickly and easily using any computer with IronPDF software. Installation is a simple task. This is the best way to learn to read PDF files in C#. You may also download IronPDF free of cost for development. If you explore IronPDF you will notice that the library provides extensive functionality that makes it very easy to use PDFs. Explore classes in your free time! There are several C# examples using HTML to create a PDF available to learn how to create an optimal output from reading PDFs.
Read PDF Files using IronPDF
Step 1: Install the IronPDF Package
To begin, you will need to install the IronPDF NuGet package into your .NET project. You can do this by opening the Package Manager Console in Visual Studio and entering the following command:
Install-Package IronPdf
Step 2: Import the IronPDF Library
Next, you need to import the IronPDF library into your code by adding the following statement at the top of your file:
using IronPdf;using IronPdf;Imports IronPdfStep 3: Load the PDF Document
Once you have imported the IronPDF library, you can load a PDF document into your code by using the following code:
// Load the PDF document from file path
PdfDocument pdf = PdfDocument.FromFile(@"C:\dotnet.pdf");
// Define the output path for the saved PDF
var outputPath = "Example.pdf";
// Save the PDF document to the specified output path
pdf.SaveAs(outputPath);// Load the PDF document from file path
PdfDocument pdf = PdfDocument.FromFile(@"C:\dotnet.pdf");
// Define the output path for the saved PDF
var outputPath = "Example.pdf";
// Save the PDF document to the specified output path
pdf.SaveAs(outputPath);' Load the PDF document from file path
Dim pdf As PdfDocument = PdfDocument.FromFile("C:\dotnet.pdf")
' Define the output path for the saved PDF
Dim outputPath = "Example.pdf"
' Save the PDF document to the specified output path
pdf.SaveAs(outputPath)Step 4: Extract Text from the PDF
IronPDF provides a range of methods to extract text from an existing PDF file. For example, you can begin extracting text from a PDF and print it on the console by using the following code snippet:
// Extract text from the loaded PDF document
string text = pdf.ExtractText();
// Print the extracted text to the console
Console.WriteLine(text);// Extract text from the loaded PDF document
string text = pdf.ExtractText();
// Print the extracted text to the console
Console.WriteLine(text);' Extract text from the loaded PDF document
Dim text As String = pdf.ExtractText()
' Print the extracted text to the console
Console.WriteLine(text)Using the above code, you can extract text from a PDF file.
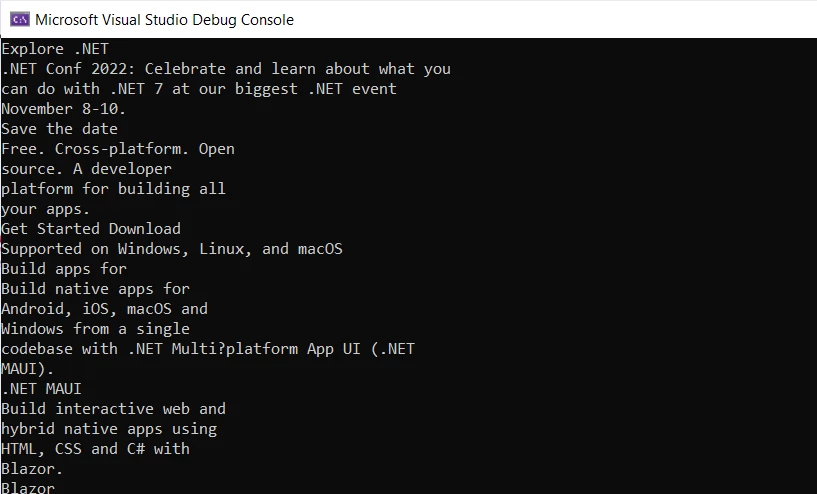 Extracting Text from a PDF Using IronPDF
Extracting Text from a PDF Using IronPDF
Step 5: Rasterize a PDF to Images
Let's rasterize the PDF file to Images with IronPDF using IronPDF. First, import the required libraries:
using System.Linq;
using IronPdf;
using IronSoftware.Drawing;using System.Linq;
using IronPdf;
using IronSoftware.Drawing;Imports System.Linq
Imports IronPdf
Imports IronSoftware.DrawingThe code then uses the RasterizeToImageFiles method to extract all the pages of the PDF document to a folder as image files. The extracted images can be saved as either PNG or JPG files, and the dimensions and page ranges of the images can also be specified.
// Extract all pages to a folder as image files with PNG format
pdf.RasterizeToImageFiles(@"C:\image\folder\*.png");
// Extract all pages to JPG images with specified dimensions
pdf.RasterizeToImageFiles(@"C:\image\folder\example_pdf_image_*.jpg", 100, 80);// Extract all pages to a folder as image files with PNG format
pdf.RasterizeToImageFiles(@"C:\image\folder\*.png");
// Extract all pages to JPG images with specified dimensions
pdf.RasterizeToImageFiles(@"C:\image\folder\example_pdf_image_*.jpg", 100, 80);' Extract all pages to a folder as image files with PNG format
pdf.RasterizeToImageFiles("C:\image\folder\*.png")
' Extract all pages to JPG images with specified dimensions
pdf.RasterizeToImageFiles("C:\image\folder\example_pdf_image_*.jpg", 100, 80)Finally, the code uses the ToBitmap method to extract all pages of the PDF document as AnyBitmap objects, which can be processed and manipulated further within the code.
// Extract all pages as AnyBitmap objects for further processing
AnyBitmap[] pdfBitmaps = pdf.ToBitmap();// Extract all pages as AnyBitmap objects for further processing
AnyBitmap[] pdfBitmaps = pdf.ToBitmap();' Extract all pages as AnyBitmap objects for further processing
Dim pdfBitmaps() As AnyBitmap = pdf.ToBitmap()The above code demonstrates how to extract the contents of a PDF file using IronPDF and save the extracted data as image files or AnyBitmap objects for further processing.
Step 7: Manipulate PDF Pages
Let's learn how to manipulate the pages of a PDF document by working with IronPDF.
The code first removes pages two and three from the PDF document using the RemovePages method:
// Remove pages two and three from the PDF document
pdf.RemovePages(1, 2);// Remove pages two and three from the PDF document
pdf.RemovePages(1, 2);' Remove pages two and three from the PDF document
pdf.RemovePages(1, 2)The RemovePages method takes two arguments: the starting page to remove (in this case, page 2, represented as 1 since page numbering starts at 0) and the number of pages to remove (in this case, 2 pages).
Step 6: Save the PDF
Finally, you can save the PDF file to your local system using the SaveAs method. The code for saving the PDF file is as follows:
// Save the PDF document to a specified output path
pdf.SaveAs(outputPath);// Save the PDF document to a specified output path
pdf.SaveAs(outputPath);' Save the PDF document to a specified output path
pdf.SaveAs(outputPath)IronPDF Compatibility
IronPDF is highly compatible with all the latest .NET Frameworks including the .NET 7. It also supports .NET Blazor and .NET MAUI, which are the latest offerings from Microsoft for web development. The library's compatibility with these frameworks makes it possible for developers to seamlessly integrate IronPDF into their applications and take advantage of its powerful features.
One of the main features of IronPDF is its ability to read PDF files in .NET Blazor and .NET MAUI. This feature enables developers to quickly and easily read and extract data from PDF files and use them in the .NET applications. This capability can be especially helpful when working with a large volume of data. Developers don't need any other library to use the IronPDF in their .NET project.
Get more information about IronPDF working with .NET Blazor in this tutorial and learn about integrating IronPDF with .NET MAUI on IronPDF's website.
Conclusion
In conclusion, reading PDF files programmatically is crucial in various industries. IronPDF provides a comprehensive solution to handle this task by offering extensive functionality to read, modify, and extract content from a PDF file. IronPDF is easy to install and use with just a few simple steps.
The library offers methods to extract text from PDF documents, rasterize a PDF to an image, manipulate pages, and save PDF files. Whether you are new to programmatic PDF processing or an experienced developer, IronPDF is the perfect tool to take your skills to the next level.
If you are looking for a reliable and efficient solution for reading PDF files in C#, IronPDF is worth exploring, especially with its license options and pricing information, and a free trial available. You can see more plans provided by IronPDF in the image below. You can select the package that matches your needs.
 IronPDF Licensing Prices
IronPDF Licensing Prices
Frequently Asked Questions
How can I read PDF files in C#?
You can use IronPDF by first installing it via the NuGet package manager in your .NET project. Then, import the library and use it to load and read PDF documents, extracting text and displaying it in the console.
What industries benefit from programmatic PDF processing?
Industries such as finance, healthcare, legal, and education benefit significantly from programmatic PDF processing, as it allows for efficient data analysis, document management, and automation of tasks using tools like IronPDF.
How do I extract data from a PDF document using C#?
Using IronPDF, you can extract data from a PDF document by loading the PDF and utilizing methods like ExtractText to read and process the content programmatically.
Can I convert PDF files to images in C#?
Yes, with IronPDF, you can convert PDF files to images using the RasterizeToImageFiles method, allowing you to save pages as image files in formats like PNG or JPG.
Is IronPDF compatible with the latest .NET frameworks?
IronPDF is compatible with all the latest .NET frameworks, including .NET 7. It also supports .NET Blazor and .NET MAUI, enabling integration into various application types.
How can I modify and save a PDF file using C#?
After making modifications to a PDF file using IronPDF, you can save the changes by using the SaveAs method, specifying the output path for the modified document.
What steps are involved in using a PDF library in a .NET project?
To use IronPDF in a .NET project, install the library via NuGet, import it into your project, and then use its functionalities to load, read, and manipulate PDF documents programmatically.
Does IronPDF require other libraries for PDF processing in .NET?
No, IronPDF is a standalone library that does not require additional libraries, making it simple to integrate into your .NET project for comprehensive PDF processing.
What are the key features of IronPDF for PDF processing?
IronPDF offers features such as text extraction, PDF rasterization to images, page manipulation, and compatibility with the latest .NET frameworks, making it a powerful tool for handling PDF files in C#.
Is IronPDF fully compatible with .NET 10?
Yes, IronPDF supports .NET 10 (along with previous versions like .NET 9, 8, 7, 6) out of the box. You can build applications using IronPDF in .NET 10 without needing special configuration or workarounds.











