온라인 도구로 PDF 문서에 서명하는 방법
PDF(Portable Document Format) 파일은 문서 교환에 널리 사용되며, 프로그램적으로 내용을 읽을 수 있는 것은 다양한 애플리케이션에서 가치가 있습니다. C++에서 PDF를 읽기 위해 사용할 수 있는 라이브러리로는 Poppler, MuPDF, Haru 무료 PDF 라이브러리, Xpdf, Qpdf 등이 있습니다.
이 기사에서는 Xpdf 명령줄 도구를 사용하여 C++에서 PDF 파일을 읽는 방법을 탐구하겠습니다. Xpdf는 PDF 파일과 작업할 수 있는 여러 유틸리티를 제공하며, 텍스트 내용 추출을 포함합니다. Xpdf를 C++ 프로그램에 통합하면 PDF 파일에서 텍스트를 추출하고 이를 프로그램적으로 처리할 수 있습니다.
Xpdf - 명령줄 도구
Xpdf는 PDF(Portable Document Format) 파일과 작업할 수 있는 도구 및 라이브러리 모음을 제공하는 오픈 소스 소프트웨어 Suite입니다. Xpdf Suite는 여러 명령줄 유틸리티와 C++ 라이브러리를 포함하며, PDF 관련 기능, 예를 들어 파싱, 렌더링, 텍스트 추출 등을 가능하게 합니다. Xpdf의 주요 구성 요소에는 pdfimages, pdftops, pdfinfo, pdftotext 등이 포함됩니다. 여기에서는 PDF 문서를 읽기 위해 pdftotext를 사용할 것입니다.
pdftotext은 PDF 파일에서 텍스트 내용을 추출하고 이를 일반 텍스트로 출력하는 명령줄 도구입니다. 이 도구는 PDF에서 텍스트 정보를 추출하여 추가 처리나 분석할 때 특히 유용합니다. 옵션을 사용하면 텍스트를 추출할 페이지를 지정할 수도 있습니다.
필수 조건
텍스트를 추출할 PDF 리더 프로젝트를 만들기 위해 다음 전제 조건이 필요합니다:
- 시스템에 설치된 GCC 또는 Clang과 같은 C++ 컴파일러. C++ 프로그래밍을 지원하는 어떤 IDE도 사용할 수 있습니다.
- 시스템에 설치된 Xpdf 명령줄 도구. Xpdf는 Xpdf 웹사이트에서 다운로드할 수 있는 PDF 유틸리티 모음입니다. Xpdf 웹사이트에서 다운로드하세요. 명령줄 도구를 사용하여 어디에서든지 액세스할 수 있도록 Xpdf의 bin 디렉토리를 환경 변수 경로에 설정하세요.
C++에서 PDF 파일 형식을 읽는 단계
단계 1: 필요한 헤더 포함하기
먼저, 필요한 헤더 파일을 main.cpp 파일의 맨 위에 추가합시다:
#include <cstdlib> // For system call
#include <iostream> // For basic input and output
#include <fstream> // For file stream operations#include <cstdlib> // For system call
#include <iostream> // For basic input and output
#include <fstream> // For file stream operations단계 2: C++ 코드 작성하기
PDF 문서에서 텍스트 내용을 추출하기 위해 Xpdf 명령줄 도구를 호출하는 C++ 코드를 작성해 보겠습니다. 다음과 같은 input.pdf 파일을 사용할 것입니다:

코드 예제는 다음과 같습니다:
#include <cstdlib>
#include <iostream>
#include <fstream>
using namespace std;
int main() {
// Specify the input and output file paths
string pdfPath = "input.pdf";
string outputFilePath = "output.txt";
// Construct the command to run pdftotext
string command = "pdftotext " + pdfPath + " " + outputFilePath;
int status = system(command.c_str());
// Check if the command executed successfully
if (status == 0) {
cout << "Text extraction successful." << endl;
} else {
cout << "Text extraction failed." << endl;
return 1; // Exit the program with error code
}
// Open the output file to read the extracted text
ifstream outputFile(outputFilePath);
if (outputFile.is_open()) {
string textContent;
string line;
while (getline(outputFile, line)) {
textContent += line + "\n"; // Append each line to the textContent
}
outputFile.close();
// Display the extracted text
cout << "Text content extracted from PDF document:" << endl;
cout << textContent << endl;
} else {
cout << "Failed to open output file." << endl;
return 1; // Exit the program with error code
}
return 0; // Exit the program successfully
}#include <cstdlib>
#include <iostream>
#include <fstream>
using namespace std;
int main() {
// Specify the input and output file paths
string pdfPath = "input.pdf";
string outputFilePath = "output.txt";
// Construct the command to run pdftotext
string command = "pdftotext " + pdfPath + " " + outputFilePath;
int status = system(command.c_str());
// Check if the command executed successfully
if (status == 0) {
cout << "Text extraction successful." << endl;
} else {
cout << "Text extraction failed." << endl;
return 1; // Exit the program with error code
}
// Open the output file to read the extracted text
ifstream outputFile(outputFilePath);
if (outputFile.is_open()) {
string textContent;
string line;
while (getline(outputFile, line)) {
textContent += line + "\n"; // Append each line to the textContent
}
outputFile.close();
// Display the extracted text
cout << "Text content extracted from PDF document:" << endl;
cout << textContent << endl;
} else {
cout << "Failed to open output file." << endl;
return 1; // Exit the program with error code
}
return 0; // Exit the program successfully
}코드 설명
위 코드에서는 입력 PDF 파일의 경로를 저장할 pdfPath 변수를 정의합니다. 실제 입력 PDF 문서 경로로 적절히 교체해야 합니다.
또한, Xpdf가 생성할 출력 텍스트 파일 경로를 저장할 outputFilePath 변수를 정의합니다.
코드는 pdftotext 명령을 system 함수를 사용하여 실행하며, 입력 PDF 파일 경로와 출력 텍스트 파일 경로를 명령줄 인수로 전달합니다. status 변수는 명령의 종료 상태를 캡처합니다.
pdftotext이 성공적으로 실행되면(상태가 0으로 표시됨), ifstream을 사용하여 출력 텍스트 파일을 여는 것으로 진행합니다. 그 후 텍스트 내용을 한 줄씩 읽고 textContent 문자열에 저장합니다.
마지막으로 추출된 텍스트 내용을 생성된 출력 파일에서 콘솔에 출력합니다. 편집 가능한 출력 텍스트 파일이 필요 없거나 디스크 공간을 확보하고 싶다면, 메인 함수를 끝내기 전에 다음 명령을 사용해 프로그램 끝에서 간단히 삭제하십시오.
remove(outputFilePath.c_str());remove(outputFilePath.c_str());단계 3: 프로그램 컴파일 및 실행하기
C++ 코드를 컴파일하고 실행 파일을 실행하세요. 만약 pdftotext가 환경 변수 시스템 경로에 추가되면, 명령이 성공적으로 실행됩니다. 프로그램은 출력 텍스트 파일을 생성하고 PDF 문서에서 텍스트 내용을 추출합니다. 추출된 텍스트는 콘솔에 표시됩니다.
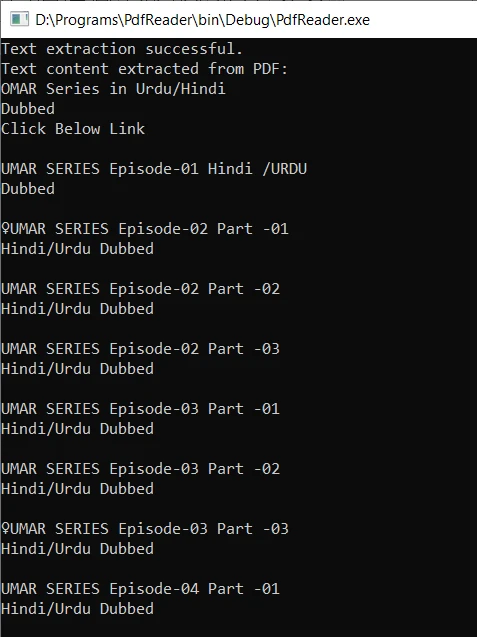
출력은 다음과 같습니다
C#에서 PDF 파일 읽기
IronPDF 라이브러리
IronPDF는 PDF 문서 작업을 위한 강력한 기능을 제공하는 인기 있는 C# PDF 라이브러리입니다. 이는 개발자가 프로그램적으로 PDF 파일을 생성, 편집, 수정 및 읽을 수 있도록 합니다.
IronPDF 라이브러리를 사용하여 PDF 문서를 읽는 것은 간단한 프로세스입니다. 라이브러리는 개발자가 PDF 페이지에서 텍스트, 이미지, 메타데이터 및 기타 데이터를 추출할 수 있는 다양한 메서드와 속성을 제공합니다. 추출된 정보는 추가 처리, 분석 또는 애플리케이션 내에서의 표시를 위해 사용될 수 있습니다.
다음 코드 예제는 IronPDF를 사용하여 PDF 파일을 읽을 것입니다:
// Import necessary namespaces
using IronPdf; // For PDF functionalities
using IronSoftware.Drawing; // For handling images
using System.Collections.Generic; // For using the List
// Example of extracting text and images from PDF using IronPDF
// Open a 128-bit encrypted PDF
var pdf = PdfDocument.FromFile("encrypted.pdf", "password");
// Get all text from the PDF
string text = pdf.ExtractAllText();
// Extract all images from the PDF
var allImages = pdf.ExtractAllImages();
// Iterate over each page to extract text and images
for (var index = 0; index < pdf.PageCount; index++) {
int pageNumber = index + 1;
text = pdf.ExtractTextFromPage(index);
List<AnyBitmap> images = pdf.ExtractBitmapsFromPage(index);
// Perform actions with text and images...
}// Import necessary namespaces
using IronPdf; // For PDF functionalities
using IronSoftware.Drawing; // For handling images
using System.Collections.Generic; // For using the List
// Example of extracting text and images from PDF using IronPDF
// Open a 128-bit encrypted PDF
var pdf = PdfDocument.FromFile("encrypted.pdf", "password");
// Get all text from the PDF
string text = pdf.ExtractAllText();
// Extract all images from the PDF
var allImages = pdf.ExtractAllImages();
// Iterate over each page to extract text and images
for (var index = 0; index < pdf.PageCount; index++) {
int pageNumber = index + 1;
text = pdf.ExtractTextFromPage(index);
List<AnyBitmap> images = pdf.ExtractBitmapsFromPage(index);
// Perform actions with text and images...
}' Import necessary namespaces
Imports IronPdf ' For PDF functionalities
Imports IronSoftware.Drawing ' For handling images
Imports System.Collections.Generic ' For using the List
' Example of extracting text and images from PDF using IronPDF
' Open a 128-bit encrypted PDF
Private pdf = PdfDocument.FromFile("encrypted.pdf", "password")
' Get all text from the PDF
Private text As String = pdf.ExtractAllText()
' Extract all images from the PDF
Private allImages = pdf.ExtractAllImages()
' Iterate over each page to extract text and images
For index = 0 To pdf.PageCount - 1
Dim pageNumber As Integer = index + 1
text = pdf.ExtractTextFromPage(index)
Dim images As List(Of AnyBitmap) = pdf.ExtractBitmapsFromPage(index)
' Perform actions with text and images...
Next indexPDF 문서를 읽는 방법에 대한 더 자세한 정보는 IronPDF C# PDF 읽기 안내서를 방문하십시오.
결론
이 기사에서는 Xpdf 명령어 도구를 사용하여 C++에서 PDF 문서의 내용을 읽는 방법을 배웠습니다. Xpdf를 C++ 프로그램에 통합함으로써 PDF 파일에서 텍스트 콘텐츠를 프로그래밍적으로 몇 초 만에 추출할 수 있습니다. 이 접근 방식은 C++ 애플리케이션 내에서 추출된 텍스트를 처리하고 분석할 수 있게 해줍니다.
IronPDF는 PDF 파일을 읽고 조작하는 일을 용이하게 해주는 강력한 C# 라이브러리입니다. 광범위한 기능, 사용의 용이성, 안정적인 렌더링 엔진은 C# 프로젝트에서 PDF 문서를 다루는 개발자들에게 인기 있는 선택이 됩니다.
IronPDF는 개발을 위한 무료이며 상업적 사용을 위한 무료 체험판을 제공합니다. 이 외에도 상업적 목적으로 라이선스가 필요합니다.