Como assinar um documento PDF com ferramentas online
Os arquivos PDF (Portable Document Format) são amplamente utilizados para troca de documentos, e a capacidade de ler seu conteúdo programaticamente é valiosa em diversas aplicações. As seguintes bibliotecas estão disponíveis para leitura de PDF em C++: Poppler, MuPDF, Haru (biblioteca gratuita para PDF), Xpdf e Qpdf.
Neste artigo, exploraremos como ler arquivos PDF em C++ usando a ferramenta de linha de comando Xpdf. O Xpdf oferece uma variedade de utilitários para trabalhar com arquivos PDF, incluindo a extração de conteúdo de texto. Ao integrar o Xpdf em um programa C++, podemos extrair o texto de arquivos PDF e processá-lo programaticamente.
Xpdf - Ferramentas de linha de comando
O Xpdf é um pacote de software de código aberto que fornece uma coleção de ferramentas e bibliotecas para trabalhar com arquivos PDF (Portable Document Format). O pacote Xpdf inclui diversos utilitários de linha de comando e bibliotecas C++ que permitem várias funcionalidades relacionadas a PDFs, como análise sintática, renderização, extração de texto e muito mais. Alguns componentes principais do Xpdf incluem pdfimages , pdftops , pdfinfo e pdftotext . Aqui, vamos usar pdftotext para ler documentos PDF.
pdftotext é uma ferramenta de linha de comando que extrai o conteúdo de texto de arquivos PDF e o exibe como texto simples. Essa ferramenta é particularmente útil quando você precisa extrair informações textuais de PDFs para processamento ou análise posterior. Utilizando as opções, você também pode especificar de qual página ou páginas extrair o texto.
Pré-requisitos
Para criar um projeto de leitura de PDF para extrair texto, precisamos que os seguintes pré-requisitos sejam atendidos:
- Um compilador C++, como o GCC ou o Clang, instalado em seu sistema. Você pode usar qualquer IDE que suporte programação em C++.
- Ferramentas de linha de comando Xpdf instaladas em seu sistema. O Xpdf é uma coleção de utilitários para PDF que pode ser obtida no site do Xpdf. Faça o download no site do Xpdf . Defina o diretório bin do Xpdf nas variáveis de ambiente PATH para poder acessá-lo de qualquer lugar usando a ferramenta de linha de comando.
Passos para ler um arquivo PDF em C++
Passo 1: Incluindo os cabeçalhos necessários
Primeiro, vamos adicionar os arquivos de cabeçalho necessários no nosso arquivo main.cpp no topo:
#include <cstdlib> // For system call
#include <iostream> // For basic input and output
#include <fstream> // For file stream operations#include <cstdlib> // For system call
#include <iostream> // For basic input and output
#include <fstream> // For file stream operationsEtapa 2: Escrevendo o código C++
Vamos escrever o código C++ que invoca a ferramenta de linha de comando Xpdf para extrair o conteúdo de texto do documento PDF. Vamos usar o seguinte arquivo input.pdf:

O exemplo de código é o seguinte:
#include <cstdlib>
#include <iostream>
#include <fstream>
using namespace std;
int main() {
// Specify the input and output file paths
string pdfPath = "input.pdf";
string outputFilePath = "output.txt";
// Construct the command to run pdftotext
string command = "pdftotext " + pdfPath + " " + outputFilePath;
int status = system(command.c_str());
// Check if the command executed successfully
if (status == 0) {
cout << "Text extraction successful." << endl;
} else {
cout << "Text extraction failed." << endl;
return 1; // Exit the program with error code
}
// Open the output file to read the extracted text
ifstream outputFile(outputFilePath);
if (outputFile.is_open()) {
string textContent;
string line;
while (getline(outputFile, line)) {
textContent += line + "\n"; // Append each line to the textContent
}
outputFile.close();
// Display the extracted text
cout << "Text content extracted from PDF document:" << endl;
cout << textContent << endl;
} else {
cout << "Failed to open output file." << endl;
return 1; // Exit the program with error code
}
return 0; // Exit the program successfully
}#include <cstdlib>
#include <iostream>
#include <fstream>
using namespace std;
int main() {
// Specify the input and output file paths
string pdfPath = "input.pdf";
string outputFilePath = "output.txt";
// Construct the command to run pdftotext
string command = "pdftotext " + pdfPath + " " + outputFilePath;
int status = system(command.c_str());
// Check if the command executed successfully
if (status == 0) {
cout << "Text extraction successful." << endl;
} else {
cout << "Text extraction failed." << endl;
return 1; // Exit the program with error code
}
// Open the output file to read the extracted text
ifstream outputFile(outputFilePath);
if (outputFile.is_open()) {
string textContent;
string line;
while (getline(outputFile, line)) {
textContent += line + "\n"; // Append each line to the textContent
}
outputFile.close();
// Display the extracted text
cout << "Text content extracted from PDF document:" << endl;
cout << textContent << endl;
} else {
cout << "Failed to open output file." << endl;
return 1; // Exit the program with error code
}
return 0; // Exit the program successfully
}Explicação do código
No código acima, definimos a variável pdfPath para armazenar o caminho para o arquivo PDF de entrada. Certifique-se de substituí-la pelo caminho apropriado para o seu documento PDF de entrada real.
Também definimos a variável outputFilePath para armazenar o caminho para o arquivo de texto de saída que será gerado pelo Xpdf.
O código executa o comando pdftotext usando a função system, passando o caminho do arquivo PDF de entrada e o caminho do arquivo de texto de saída como argumentos de linha de comando. A variável status captura o status de saída do comando.
Se pdftotext executar com sucesso (indicado por um status de 0), prosseguimos para abrir o arquivo de texto de saída usando ifstream. Em seguida, lemos o conteúdo do texto linha por linha e o armazenamos na string textContent.
Por fim, exibimos o conteúdo de texto extraído no console a partir do arquivo de saída gerado. Se você não precisar do arquivo de texto editável gerado ou quiser liberar espaço em disco, basta excluí-lo ao final do programa usando o seguinte comando antes de encerrar a função principal:
remove(outputFilePath.c_str());remove(outputFilePath.c_str());Etapa 3: Compilando e executando o programa
Compile o código C++ e execute o arquivo executável. Se pdftotext for adicionado ao Caminho do Sistema de Variáveis de Ambiente, seu comando será executado com sucesso. O programa gera o arquivo de texto de saída e extrai o conteúdo textual do documento PDF. O texto extraído é então exibido no console.
O resultado é o seguinte:
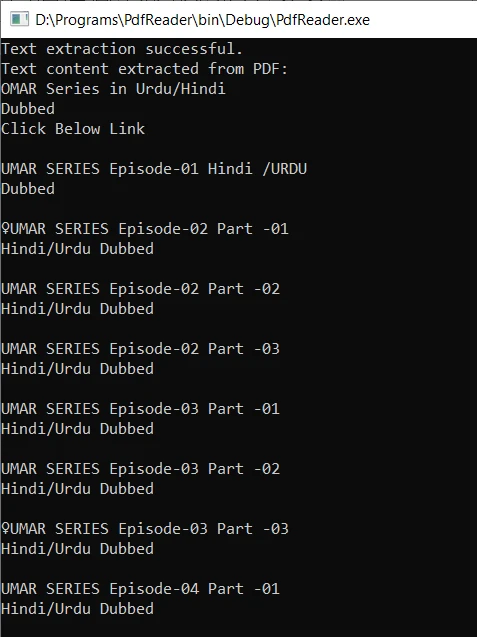
Leia arquivos PDF em C
Biblioteca IronPDF
IronPDF é uma biblioteca C# popular para PDF que oferece funcionalidades poderosas para trabalhar com documentos PDF. Permite aos desenvolvedores criar, editar, modificar e ler arquivos PDF programaticamente.
Ler documentos PDF usando a biblioteca IronPDF é um processo simples. A biblioteca oferece diversos métodos e propriedades que permitem aos desenvolvedores extrair texto, imagens, metadados e outros dados de páginas PDF. As informações extraídas podem ser usadas para processamento, análise ou exibição adicionais dentro do aplicativo.
O exemplo de código a seguir usará o IronPDF para ler arquivos PDF :
// Import necessary namespaces
using IronPdf; // For PDF functionalities
using IronSoftware.Drawing; // For handling images
using System.Collections.Generic; // For using the List
// Example of extracting text and images from PDF using IronPDF
// Open a 128-bit encrypted PDF
var pdf = PdfDocument.FromFile("encrypted.pdf", "password");
// Get all text from the PDF
string text = pdf.ExtractAllText();
// Extract all images from the PDF
var allImages = pdf.ExtractAllImages();
// Iterate over each page to extract text and images
for (var index = 0; index < pdf.PageCount; index++) {
int pageNumber = index + 1;
text = pdf.ExtractTextFromPage(index);
List<AnyBitmap> images = pdf.ExtractBitmapsFromPage(index);
// Perform actions with text and images...
}// Import necessary namespaces
using IronPdf; // For PDF functionalities
using IronSoftware.Drawing; // For handling images
using System.Collections.Generic; // For using the List
// Example of extracting text and images from PDF using IronPDF
// Open a 128-bit encrypted PDF
var pdf = PdfDocument.FromFile("encrypted.pdf", "password");
// Get all text from the PDF
string text = pdf.ExtractAllText();
// Extract all images from the PDF
var allImages = pdf.ExtractAllImages();
// Iterate over each page to extract text and images
for (var index = 0; index < pdf.PageCount; index++) {
int pageNumber = index + 1;
text = pdf.ExtractTextFromPage(index);
List<AnyBitmap> images = pdf.ExtractBitmapsFromPage(index);
// Perform actions with text and images...
}' Import necessary namespaces
Imports IronPdf ' For PDF functionalities
Imports IronSoftware.Drawing ' For handling images
Imports System.Collections.Generic ' For using the List
' Example of extracting text and images from PDF using IronPDF
' Open a 128-bit encrypted PDF
Private pdf = PdfDocument.FromFile("encrypted.pdf", "password")
' Get all text from the PDF
Private text As String = pdf.ExtractAllText()
' Extract all images from the PDF
Private allImages = pdf.ExtractAllImages()
' Iterate over each page to extract text and images
For index = 0 To pdf.PageCount - 1
Dim pageNumber As Integer = index + 1
text = pdf.ExtractTextFromPage(index)
Dim images As List(Of AnyBitmap) = pdf.ExtractBitmapsFromPage(index)
' Perform actions with text and images...
Next indexPara obter informações mais detalhadas sobre como ler documentos PDF, visite o Guia de Leitura de PDF em C# do IronPDF .
Conclusão
Neste artigo, aprendemos como ler o conteúdo de um documento PDF em C++ usando a ferramenta de linha de comando Xpdf. Ao integrar o Xpdf em um programa C++, podemos extrair programaticamente o conteúdo de texto de arquivos PDF em segundos. Essa abordagem nos permite processar e analisar o texto extraído em nossos aplicativos C++.
IronPDF é uma poderosa biblioteca C# que facilita a leitura e manipulação de arquivos PDF. Suas amplas funcionalidades, facilidade de uso e mecanismo de renderização confiável fazem dele uma escolha popular para desenvolvedores que trabalham com documentos PDF em seus projetos C#.
O IronPDF é gratuito para desenvolvimento e oferece um período de teste gratuito para uso comercial . Além disso, é necessário obter uma licença para fins comerciais .