
Tutorial fácil para ler arquivos PDF em C#
O processamento programático de PDFs é crucial em setores como finanças, saúde, direito e educação, onde informações críticas precisam ser processadas, analisadas e extraídas de documentos PDF para fins como análise de dados, gerenciamento de documentos e automação. Apesar de sua importância, essa tarefa pode ser desafiadora.
IronPDF: Uma Biblioteca C# PDF
O IronPDF permite que você execute tarefas incrivelmente difíceis com facilidade. Permite editar facilmente o texto em um documento PDF, de forma semelhante a como se trabalha com arquivos de texto em um documento de texto, possibilitando ainda a exportação de arquivos em qualquer sistema operacional. O aplicativo IronPDF abrange todo o processo de visualização, modificação e extração de conteúdo de um PDF.
Dê o passo certo com o IronPDF
É possível ler e escrever textos em formato PDF de forma rápida e fácil usando qualquer computador com o Iron SoftwarePDF . A instalação é uma tarefa simples. Esta é a melhor maneira de aprender a ler arquivos PDF em C#. Você também pode baixar o IronPDF gratuitamente para desenvolvimento. Ao explorar o IronPDF, você perceberá que a biblioteca oferece ampla funcionalidade, o que facilita muito o uso de PDFs. Explore as aulas no seu tempo livre! Existem vários exemplos em C# que utilizam HTML para criar um PDF, permitindo que você aprenda a gerar uma saída otimizada a partir da leitura de PDFs.
Leia arquivos PDF usando o IronPDF
Passo 1: Instale o pacote IronPDF
Para começar, você precisará instalar o pacote NuGet IronPDF em seu projeto .NET . Você pode fazer isso abrindo o Console do Gerenciador de Pacotes no Visual Studio e digitando o seguinte comando:
Install-Package IronPdf
Passo 2: Importe a biblioteca IronPDF
Em seguida, você precisa importar a biblioteca IronPDF para o seu código, adicionando a seguinte instrução no início do seu arquivo:
using IronPdf;using IronPdf;Imports IronPdfPasso 3: Carregar o documento PDF
Após importar a biblioteca IronPDF , você pode carregar um documento PDF em seu código usando o seguinte código:
// Load the PDF document from file path
PdfDocument pdf = PdfDocument.FromFile(@"C:\dotnet.pdf");
// Define the output path for the saved PDF
var outputPath = "Example.pdf";
// Save the PDF document to the specified output path
pdf.SaveAs(outputPath);// Load the PDF document from file path
PdfDocument pdf = PdfDocument.FromFile(@"C:\dotnet.pdf");
// Define the output path for the saved PDF
var outputPath = "Example.pdf";
// Save the PDF document to the specified output path
pdf.SaveAs(outputPath);' Load the PDF document from file path
Dim pdf As PdfDocument = PdfDocument.FromFile("C:\dotnet.pdf")
' Define the output path for the saved PDF
Dim outputPath = "Example.pdf"
' Save the PDF document to the specified output path
pdf.SaveAs(outputPath)Etapa 4: Extrair o texto do PDF
O IronPDF oferece diversos métodos para extrair texto de um arquivo PDF existente. Por exemplo, você pode começar a extrair texto de um PDF e imprimi-lo no console usando o seguinte trecho de código:
// Extract text from the loaded PDF document
string text = pdf.ExtractText();
// Print the extracted text to the console
Console.WriteLine(text);// Extract text from the loaded PDF document
string text = pdf.ExtractText();
// Print the extracted text to the console
Console.WriteLine(text);' Extract text from the loaded PDF document
Dim text As String = pdf.ExtractText()
' Print the extracted text to the console
Console.WriteLine(text)Usando o código acima, você pode extrair texto de um arquivo PDF .
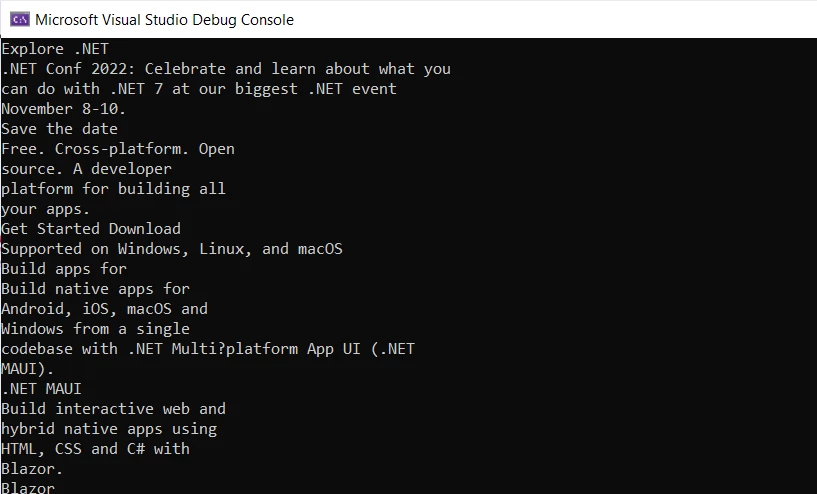 Extraindo texto de um PDF usando o IronPDF
Extraindo texto de um PDF usando o IronPDF
Etapa 5: Rasterizar um PDF em imagens
Vamos rasterizar o arquivo PDF em imagens com o IronPDF usando o IronPDF. Primeiro, importe as bibliotecas necessárias:
using System.Linq;
using IronPdf;
using IronSoftware.Drawing;using System.Linq;
using IronPdf;
using IronSoftware.Drawing;Imports System.Linq
Imports IronPdf
Imports IronSoftware.DrawingO código então usa o RasterizeToImageFiles método para extrair todas as páginas do documento PDF para uma pasta como arquivos de imagem. As imagens extraídas podem ser salvas como arquivos PNG ou JPG, e as dimensões e intervalos de páginas das imagens também podem ser especificados.
// Extract all pages to a folder as image files with PNG format
pdf.RasterizeToImageFiles(@"C:\image\folder\*.png");
// Extract all pages to JPG images with specified dimensions
pdf.RasterizeToImageFiles(@"C:\image\folder\example_pdf_image_*.jpg", 100, 80);// Extract all pages to a folder as image files with PNG format
pdf.RasterizeToImageFiles(@"C:\image\folder\*.png");
// Extract all pages to JPG images with specified dimensions
pdf.RasterizeToImageFiles(@"C:\image\folder\example_pdf_image_*.jpg", 100, 80);' Extract all pages to a folder as image files with PNG format
pdf.RasterizeToImageFiles("C:\image\folder\*.png")
' Extract all pages to JPG images with specified dimensions
pdf.RasterizeToImageFiles("C:\image\folder\example_pdf_image_*.jpg", 100, 80)Finalmente, o código usa o ToBitmap método para extrair todas as páginas do documento PDF como objetos AnyBitmap, que podem ser processados e manipulados adiante no código.
// Extract all pages as AnyBitmap objects for further processing
AnyBitmap[] pdfBitmaps = pdf.ToBitmap();// Extract all pages as AnyBitmap objects for further processing
AnyBitmap[] pdfBitmaps = pdf.ToBitmap();' Extract all pages as AnyBitmap objects for further processing
Dim pdfBitmaps() As AnyBitmap = pdf.ToBitmap()O código acima demonstra como extrair o conteúdo de um arquivo PDF usando IronPDF e salvar os dados extraídos como arquivos de imagem ou objetos AnyBitmap para processamento adicional.
Etapa 7: Manipular páginas do PDF
Vamos aprender como manipular as páginas de um documento PDF usando o IronPDF.
O código primeiro remove as páginas duas e três do documento PDF usando o RemovePages método:
// Remove pages two and three from the PDF document
pdf.RemovePages(1, 2);// Remove pages two and three from the PDF document
pdf.RemovePages(1, 2);' Remove pages two and three from the PDF document
pdf.RemovePages(1, 2)O método RemovePages leva dois argumentos: a página inicial para remover (neste caso, a página 2, representada como 1 já que a numeração começa em 0) e o número de páginas a remover (neste caso, 2 páginas).
Passo 6: Salve o PDF
Finalmente, você pode salvar o arquivo PDF no seu sistema local usando o SaveAs método. O código para salvar o arquivo PDF é o seguinte:
// Save the PDF document to a specified output path
pdf.SaveAs(outputPath);// Save the PDF document to a specified output path
pdf.SaveAs(outputPath);' Save the PDF document to a specified output path
pdf.SaveAs(outputPath)Compatibilidade com IronPDF
O IronPDF é altamente compatível com todas as versões mais recentes do .NET Framework, incluindo o .NET 7. Ele também oferece suporte ao .NET Blazor e ao .NET MAUI, que são as ofertas mais recentes da Microsoft para desenvolvimento web. A compatibilidade da biblioteca com essas estruturas permite que os desenvolvedores integrem o IronPDF em seus aplicativos sem problemas e aproveitem seus recursos avançados.
Uma das principais características do IronPDF é sua capacidade de ler arquivos PDF em .NET Blazor e .NET MAUI. Este recurso permite que os desenvolvedores leiam e extraiam dados de arquivos PDF de forma rápida e fácil, utilizando-os em aplicativos .NET . Essa funcionalidade pode ser especialmente útil ao trabalhar com um grande volume de dados. Os desenvolvedores não precisam de nenhuma outra biblioteca para usar o IronPDF em seus projetos .NET .
Obtenha mais informações sobre como o IronPDF funciona com o .NET Blazor neste tutorial e aprenda sobre como integrar o IronPDF com o .NET MAUI no site do IronPDF.
Conclusão
Em conclusão, a leitura programática de arquivos PDF é crucial em diversos setores. O IronPDF oferece uma solução completa para essa tarefa, disponibilizando ampla funcionalidade para ler, modificar e extrair conteúdo de um arquivo PDF. O IronPDF é fácil de instalar e usar, exigindo apenas alguns passos simples.
A biblioteca oferece métodos para extrair texto de documentos PDF , rasterizar um PDF em uma imagem , manipular páginas e salvar arquivos PDF. Seja você um iniciante no processamento programático de PDFs ou um desenvolvedor experiente, o IronPDF é a ferramenta perfeita para levar suas habilidades para o próximo nível.
Se você procura uma solução confiável e eficiente para leitura de arquivos PDF em C#, vale a pena explorar o IronPDF , especialmente considerando suas opções de licença, informações de preços e a disponibilidade de um período de teste gratuito . Você pode ver mais projetos fornecidos pela IronPDF na imagem abaixo. Você pode selecionar o pacote que melhor atenda às suas necessidades.
 Preços de licenciamento do IronPDF
Preços de licenciamento do IronPDF
Perguntas frequentes
Como posso ler arquivos PDF em C#?
Você pode usar o IronPDF instalando-o primeiro através do gerenciador de pacotes NuGet em seu projeto .NET. Em seguida, importe a biblioteca e use-a para carregar e ler documentos PDF, extraindo o texto e exibindo-o no console.
Quais setores se beneficiam do processamento programático de PDFs?
Setores como o financeiro, o da saúde, o jurídico e o da educação se beneficiam significativamente do processamento programático de PDFs, pois ele permite uma análise de dados eficiente, o gerenciamento de documentos e a automação de tarefas usando ferramentas como o IronPDF.
Como posso extrair dados de um documento PDF usando C#?
Com o IronPDF, você pode extrair dados de um documento PDF carregando o PDF e utilizando métodos como ExtractText para ler e processar o conteúdo programaticamente.
É possível converter arquivos PDF em imagens usando C#?
Sim, com o IronPDF, você pode converter arquivos PDF em imagens usando o método RasterizeToImageFiles , permitindo salvar páginas como arquivos de imagem em formatos como PNG ou JPG.
O IronPDF é compatível com as versões mais recentes do .NET Framework?
O IronPDF é compatível com todas as versões mais recentes do .NET Framework, incluindo o .NET 7. Ele também oferece suporte ao .NET Blazor e ao .NET MAUI, permitindo a integração em diversos tipos de aplicativos.
Como posso modificar e salvar um arquivo PDF usando C#?
Após fazer modificações em um arquivo PDF usando o IronPDF, você pode salvar as alterações usando o método SaveAs , especificando o caminho de saída para o documento modificado.
Quais são os passos envolvidos na utilização de uma biblioteca PDF em um projeto .NET?
Para usar o IronPDF em um projeto .NET, instale a biblioteca via NuGet, importe-a para o seu projeto e, em seguida, use suas funcionalidades para carregar, ler e manipular documentos PDF programaticamente.
O IronPDF requer outras bibliotecas para processamento de PDF no .NET?
Não, o IronPDF é uma biblioteca independente que não requer bibliotecas adicionais, o que facilita a integração em seu projeto .NET para processamento completo de PDFs.
Quais são as principais funcionalidades do IronPDF para processamento de PDFs?
O IronPDF oferece recursos como extração de texto, rasterização de PDFs para imagens, manipulação de páginas e compatibilidade com as mais recentes estruturas .NET, tornando-o uma ferramenta poderosa para lidar com arquivos PDF em C#.
O IronPDF é totalmente compatível com o .NET 10?
Sim, o IronPDF é compatível com o .NET 10 (assim como com versões anteriores como .NET 9, 8, 7 e 6) nativamente. Você pode criar aplicativos usando o IronPDF no .NET 10 sem precisar de configurações especiais ou soluções alternativas.











