
Wie man PDF-Dateien in C# liest
Die programmgesteuerte Verarbeitung von PDFs ist in Branchen wie Finanzen, Gesundheitswesen, Recht und Bildung von entscheidender Bedeutung, da kritische Informationen aus PDF-Dokumenten zu Zwecken wie Datenanalyse, Dokumentenmanagement und Automatisierung verarbeitet, analysiert und extrahiert werden müssen. Trotz ihrer Bedeutung kann diese Aufgabe herausfordernd sein.
IronPDF: Eine C# PDF-Bibliothek
IronPDF ermöglicht es Ihnen, unglaublich schwierige Aufgaben einfach zu bewältigen. Es erlaubt die einfache Bearbeitung von Text in einem PDF-Dokument, ähnlich wie man mit Textdateien in einem Textdokument arbeiten kann, und ermöglicht es gleichzeitig, Dateien in jedem Betriebssystem zu exportieren. Die IronPDF-Anwendung deckt den gesamten Prozess des Anzeigens, Bearbeitens und Extrahierens von Inhalten aus einem PDF ab.
Machen Sie den richtigen Schritt mit IronPDF
Text kann schnell und einfach im PDF-Dateiformat gelesen und geschrieben werden, indem man jeden Computer mit IronPDF-Software verwendet. Die Installation ist eine einfache Aufgabe. Dies ist der beste Weg, um zu lernen, PDF-Dateien in C# zu lesen. Sie können IronPDF auch kostenlos für die Entwicklung herunterladen. Wenn Sie IronPDF erkunden, werden Sie feststellen, dass die Bibliothek umfangreiche Funktionalitäten bietet, die es sehr einfach machen, mit PDFs zu arbeiten. Erkunden Sie Klassen in Ihrer Freizeit! Es gibt mehrere C#-Beispiele, die HTML verwenden, um ein PDF zu erstellen, die zeigen, wie man ein optimales Ergebnis beim Lesen von PDFs erzielt.
PDF-Dateien mit IronPDF lesen
Schritt 1: Installieren Sie das IronPDF-Paket
Um zu beginnen, müssen Sie das IronPDF NuGet-Paket in Ihr .NET-Projekt installieren. Sie können dies tun, indem Sie die Paket-Manager-Konsole in Visual Studio öffnen und den folgenden Befehl eingeben:
Install-Package IronPdf
Schritt 2: Importieren Sie die IronPDF-Bibliothek
Als Nächstes müssen Sie die IronPDF-Bibliothek in Ihren Code importieren, indem Sie die folgende Anweisung am Anfang Ihrer Datei hinzufügen:
using IronPdf;using IronPdf;Imports IronPdfSchritt 3: Laden Sie das PDF-Dokument
Sobald Sie die IronPDF-Bibliothek importiert haben, können Sie ein PDF-Dokument in Ihren Code laden, indem Sie den folgenden Code verwenden:
// Load the PDF document from file path
PdfDocument pdf = PdfDocument.FromFile(@"C:\dotnet.pdf");
// Define the output path for the saved PDF
var outputPath = "Example.pdf";
// Save the PDF document to the specified output path
pdf.SaveAs(outputPath);// Load the PDF document from file path
PdfDocument pdf = PdfDocument.FromFile(@"C:\dotnet.pdf");
// Define the output path for the saved PDF
var outputPath = "Example.pdf";
// Save the PDF document to the specified output path
pdf.SaveAs(outputPath);' Load the PDF document from file path
Dim pdf As PdfDocument = PdfDocument.FromFile("C:\dotnet.pdf")
' Define the output path for the saved PDF
Dim outputPath = "Example.pdf"
' Save the PDF document to the specified output path
pdf.SaveAs(outputPath)Schritt 4: Text aus dem PDF extrahieren
IronPDF bietet eine Reihe von Methoden, um Text aus einer bestehenden PDF-Datei zu extrahieren. Zum Beispiel können Sie anfangen, Text aus einem PDF zu extrahieren und ihn mit folgendem Code-Snippet in der Konsole auszugeben:
// Extract text from the loaded PDF document
string text = pdf.ExtractText();
// Print the extracted text to the console
Console.WriteLine(text);// Extract text from the loaded PDF document
string text = pdf.ExtractText();
// Print the extracted text to the console
Console.WriteLine(text);' Extract text from the loaded PDF document
Dim text As String = pdf.ExtractText()
' Print the extracted text to the console
Console.WriteLine(text)Mit dem obigen Code können Sie Text aus einer PDF-Datei extrahieren.
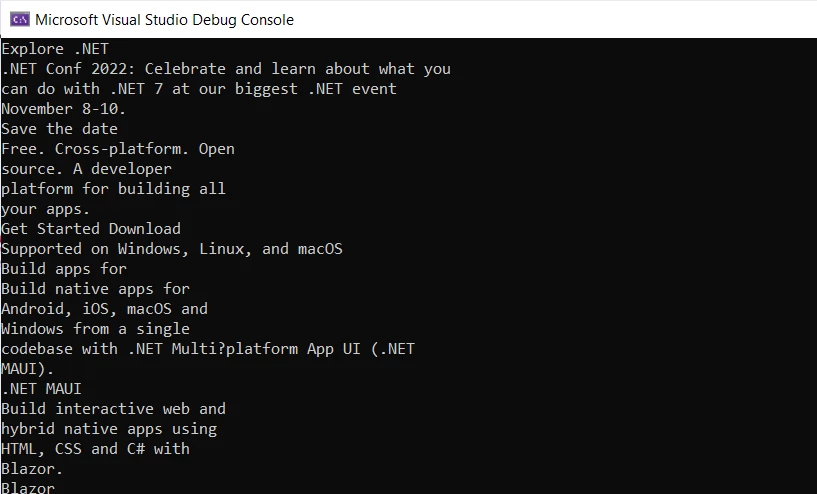 Text aus einem PDF extrahieren mit IronPDF
Text aus einem PDF extrahieren mit IronPDF
Schritt 5: Eine PDF in Bilder rasterisieren
Lassen Sie uns die PDF-Datei mit IronPDF in Bilder rasterisieren. Zuerst die erforderlichen Bibliotheken importieren:
using System.Linq;
using IronPdf;
using IronSoftware.Drawing;using System.Linq;
using IronPdf;
using IronSoftware.Drawing;Imports System.Linq
Imports IronPdf
Imports IronSoftware.DrawingDer Code verwendet dann die Methode RasterizeToImageFiles, um alle Seiten des PDF-Dokuments als Bilddateien in einen Ordner zu extrahieren. Die extrahierten Bilder können entweder als PNG- oder JPG-Dateien gespeichert werden, und die Dimensionen und Seitenbereiche der Bilder können ebenfalls angegeben werden.
// Extract all pages to a folder as image files with PNG format
pdf.RasterizeToImageFiles(@"C:\image\folder\*.png");
// Extract all pages to JPG images with specified dimensions
pdf.RasterizeToImageFiles(@"C:\image\folder\example_pdf_image_*.jpg", 100, 80);// Extract all pages to a folder as image files with PNG format
pdf.RasterizeToImageFiles(@"C:\image\folder\*.png");
// Extract all pages to JPG images with specified dimensions
pdf.RasterizeToImageFiles(@"C:\image\folder\example_pdf_image_*.jpg", 100, 80);' Extract all pages to a folder as image files with PNG format
pdf.RasterizeToImageFiles("C:\image\folder\*.png")
' Extract all pages to JPG images with specified dimensions
pdf.RasterizeToImageFiles("C:\image\folder\example_pdf_image_*.jpg", 100, 80)Schließlich verwendet der Code die Methode ToBitmap, um alle Seiten des PDF-Dokuments als AnyBitmap Objekte zu extrahieren, die innerhalb des Codes weiter verarbeitet und manipuliert werden können.
// Extract all pages as AnyBitmap objects for further processing
AnyBitmap[] pdfBitmaps = pdf.ToBitmap();// Extract all pages as AnyBitmap objects for further processing
AnyBitmap[] pdfBitmaps = pdf.ToBitmap();' Extract all pages as AnyBitmap objects for further processing
Dim pdfBitmaps() As AnyBitmap = pdf.ToBitmap()Der obige Code demonstriert, wie man mit IronPDF den Inhalt einer PDF-Datei extrahiert und die extrahierten Daten als Bilddateien oder AnyBitmap Objekte zur Weiterverarbeitung speichert.
Schritt 7: PDF-Seiten manipulieren
Lassen Sie uns lernen, wie man die Seiten eines PDF-Dokuments manipuliert, indem man mit IronPDF arbeitet.
Der Code entfernt zunächst die Seiten zwei und drei aus dem PDF-Dokument mithilfe der Methode RemovePages :
// Remove pages two and three from the PDF document
pdf.RemovePages(1, 2);// Remove pages two and three from the PDF document
pdf.RemovePages(1, 2);' Remove pages two and three from the PDF document
pdf.RemovePages(1, 2)Die Methode RemovePages benötigt zwei Argumente: die zu entfernende erste Seite (in diesem Fall Seite 2, dargestellt als 1 , da die Seitennummerierung bei 0 beginnt) und die Anzahl der zu entfernenden Seiten (in diesem Fall 2 Seiten).
Schritt 6: Die PDF speichern
Abschließend können Sie die PDF-Datei mit der Methode SaveAs auf Ihrem lokalen System speichern. Der Code zum Speichern der PDF-Datei lautet wie folgt:
// Save the PDF document to a specified output path
pdf.SaveAs(outputPath);// Save the PDF document to a specified output path
pdf.SaveAs(outputPath);' Save the PDF document to a specified output path
pdf.SaveAs(outputPath)IronPDF-Kompatibilität
IronPDF ist hochkompatibel mit allen neuesten .NET-Frameworks, einschließlich .NET 7. Es unterstützt auch .NET Blazor und .NET MAUI, die neuesten Angebote von Microsoft für Webentwicklung. Die Kompatibilität der Bibliothek mit diesen Frameworks ermöglicht es Entwicklern, IronPDF nahtlos in ihre Anwendungen zu integrieren und die leistungsstarken Funktionen zu nutzen.
Eines der Hauptmerkmale von IronPDF ist seine Fähigkeit, PDF-Dateien in .NET Blazor und .NET MAUI zu lesen. Dieses Feature ermöglicht es Entwicklern, schnell und einfach Daten aus PDF-Dateien zu lesen und in .NET-Anwendungen zu verwenden. Diese Fähigkeit kann besonders hilfreich sein, wenn mit einer großen Menge an Daten gearbeitet wird. Entwickler benötigen keine andere Bibliothek, um IronPDF in ihrem .NET-Projekt zu verwenden.
Erfahren Sie mehr über IronPDF, das mit .NET Blazor in diesem Tutorial arbeitet, und lernen Sie die Integration von IronPDF mit .NET MAUI auf der Website von IronPDF kennen.
Abschluss
Zusammenfassend ist das programmiertechnische Lesen von PDF-Dateien in verschiedenen Branchen von entscheidender Bedeutung. IronPDF bietet eine umfassende Lösung für diese Aufgabe, indem es umfangreiche Funktionalitäten zum Lesen, Ändern und Extrahieren von Inhalten aus einer PDF-Datei bietet. IronPDF ist einfach zu installieren und mit nur wenigen Schritten zu verwenden.
Die Bibliothek bietet Methoden, um Text aus PDF-Dokumenten zu extrahieren, ein PDF in ein Bild zu rasterisieren, Seiten zu manipulieren und PDF-Dateien zu speichern. Ob Sie neu im programmatischen PDF-Processing sind oder ein erfahrener Entwickler, IronPDF ist das ideale Werkzeug, um Ihre Fähigkeiten auf die nächste Ebene zu heben.
Wenn Sie nach einer zuverlässigen und effizienten Lösung für das Lesen von PDF-Dateien in C# suchen, ist IronPDF einen Versuch wert, insbesondere mit seinen Lizenzierungsoptionen und Preisangaben und einem kostenlosen Test. Sie können weitere von IronPDF bereitgestellte Pläne im Bild unten sehen. Sie können das Paket auswählen, das Ihren Bedürfnissen entspricht.
 IronPDF-Lizenzpreise
IronPDF-Lizenzpreise
Häufig gestellte Fragen
Wie kann ich PDF-Dateien in C# lesen?
Sie können IronPDF verwenden, indem Sie es zuerst über den NuGet-Paketmanager in Ihrem .NET-Projekt installieren. Importieren Sie dann die Bibliothek und verwenden Sie sie, um PDF-Dokumente zu laden und zu lesen, Text zu extrahieren und in der Konsole anzuzeigen.
Welche Branchen profitieren von der programmatischen PDF-Verarbeitung?
Branchen wie Finanzen, Gesundheitswesen, Recht und Bildung profitieren erheblich von der programmatischen PDF-Verarbeitung, da dies eine effiziente Datenanalyse, Dokumentenverwaltung und Automatisierung von Aufgaben mit Tools wie IronPDF ermöglicht.
Wie extrahiere ich Daten aus einem PDF-Dokument mit C#?
Mit IronPDF können Sie Daten aus einem PDF-Dokument extrahieren, indem Sie das PDF laden und Methoden wie ExtractText verwenden, um den Inhalt programmatisch zu lesen und zu verarbeiten.
Kann ich PDF-Dateien in C# in Bilder umwandeln?
Ja, mit IronPDF können Sie PDF-Dateien in Bilder umwandeln, indem Sie die RasterizeToImageFiles-Methode verwenden, die es Ihnen ermöglicht, Seiten als Bilddateien in Formaten wie PNG oder JPG zu speichern.
Ist IronPDF mit den neuesten .NET-Frameworks kompatibel?
IronPDF ist mit allen neuesten .NET-Frameworks kompatibel, einschließlich .NET 7. Es unterstützt auch .NET Blazor und .NET MAUI, was eine Integration in verschiedene Anwendungstypen ermöglicht.
Wie kann ich eine PDF-Datei mit C# ändern und speichern?
Nach dem Ändern einer PDF-Datei mit IronPDF können Sie die Änderungen speichern, indem Sie die SaveAs-Methode verwenden und den Ausgabepfad für das geänderte Dokument angeben.
Welche Schritte sind notwendig, um eine PDF-Bibliothek in einem .NET-Projekt zu verwenden?
Um IronPDF in einem .NET-Projekt zu verwenden, installieren Sie die Bibliothek über NuGet, importieren Sie sie in Ihr Projekt und nutzen Sie dann ihre Funktionen, um PDF-Dokumente programmatisch zu laden, zu lesen und zu bearbeiten.
Benötigt IronPDF andere Bibliotheken für die PDF-Verarbeitung in .NET?
Nein, IronPDF ist eine eigenständige Bibliothek, die keine zusätzlichen Bibliotheken erfordert, sodass sie einfach in Ihr .NET-Projekt für eine umfassende PDF-Verarbeitung integriert werden kann.
Was sind die Hauptfunktionen von IronPDF für die PDF-Verarbeitung?
IronPDF bietet Funktionen wie Textextraktion, PDF-Rasterung in Bilder, Seitenmanipulation und Kompatibilität mit den neuesten .NET-Frameworks und macht es zu einem leistungsstarken Werkzeug für die Bearbeitung von PDF-Dateien in C#.
Ist IronPDF vollständig mit .NET 10 kompatibel?
Ja, IronPDF unterstützt .NET 10 (sowie frühere Versionen wie .NET 9, 8, 7 und 6) standardmäßig. Sie können Anwendungen mit IronPDF unter .NET 10 entwickeln, ohne dass spezielle Konfigurationen oder Workarounds erforderlich sind.














