IRONPDFの使用 C# PDFからテキストを抽出する(コードサンプルチュートリアル) Kye Stuart 更新日:2025年7月28日 IronPDF をダウンロード NuGet ダウンロード DLL ダウンロード Windows 版 無料トライアル LLM向けのコピー LLM向けのコピー LLM 用の Markdown としてページをコピーする ChatGPTで開く このページについてChatGPTに質問する ジェミニで開く このページについてGeminiに問い合わせる Grokで開く このページについてGrokに質問する 困惑の中で開く このページについてPerplexityに問い合わせる 共有する Facebook で共有 Xでシェア(Twitter) LinkedIn で共有 URLをコピー 記事をメールで送る PDF のセキュリティとコンプライアンスに年間契約料を払いすぎています。IronSecureDoc by Iron Software をご検討ください。これは、デジタル署名、再編集、暗号化、保護などの SaaS サービスを管理するソリューションを、すべて 1 回限りの支払いで提供するものです。今すぐIronSecureDocを体験する。 PDF(ポータブル・ドキュメント・フォーマット)ファイルは、無数の業界で重要な役割を果たしており、企業が安全にドキュメントを共有、保存、管理することを可能にします。 開発者にとって、PDFを扱うことは、クライアントのニーズをサポートするために、内容の作成、読み取り、変換、抽出を伴うことがよくあります。 PDFからのテキストの抽出は、データ分析、ドキュメントのインデックス化、コンテンツの移行、またはアクセシビリティ機能の有効化などのタスクに必要不可欠です。 近代的なライブラリのIronPDFのようなものがこれらのタスクをこれまで以上に簡単にし、PDFファイルの操作のための強力なツールを最小限の労力で提供します。 このガイドは、最も一般的な要求の1つである、C#でのPDFからのテキストの抽出に焦点を当てます。 Visual Studioでのプロジェクトのセットアップ、IronPDFのインストール、および簡潔なコード例を使用したテキスト抽出の実行方法について手順を紹介します。 途中で、.NETを使用してPDFファイルを作成、操作、変換する、IronPDFの強力な機能を強調します。 ドキュメントに重心を置いたアプリケーションを構築する場合でも、効率的なPDFの取り扱いが必要な場合でも、このチュートリアルが役立ちます。 C#でPDFからテキストを抽出する方法 PDFからテキストを抽出するC#ライブラリをダウンロードする。 Visual Studioで新しいプロジェクトを作成する プロジェクトにライブラリをインストールする PDFファイルからのテキスト抽出を実行 PDFドキュメントからのテキスト出力を表示 1. IronPDFの機能 IronPDFは、ブラウザが行うほぼすべての操作を実行できる頑健なPDFコンバーターです。 開発者向けに、.NETライブラリを使用すると、PDFドキュメントを簡単に作成、読み取り、および操作できます。 IronPDFは、Chromeエンジンを使用してHTML-to-PDFドキュメントを変換します。IronPDFはHTML、ASPX、Razor HTML、およびその他のWebコンポーネントなどをサポートしています。 Microsoft .NETアプリケーションは、IronPDF(ASP.NET Webアプリケーションと従来のWindowsアプリケーションの両方)によりサポートされています。 IronPDFは、視覚的に魅力的なPDFドキュメントを作成するためにも使用できます。 IronPDFを使用してHTML5、JavaScript、CSS、および画像からPDFドキュメントを作成できます。 ファイルにはヘッダーとフッターを追加することもできます。 IronPDFのおかげで、PDFドキュメントを簡単に読むことができます。 IronPDFには、包括的なPDF変換エンジンと、PDFドキュメントを処理できる強力なHTML-to-PDFコンバーターもあります。 PDFの作成: HTML、JavaScript、CSS、画像、またはURLからPDFを生成します。 ヘッダー、フッター、ブックマーク、透かしなどのカスタム要素を追加して、デザインを向上させます。 HTML-to-PDF変換: HTML、Razor/MVCビュー、およびメディアタイプのCSSファイルを直接PDF形式に変換します。 インタラクティブなPDFの機能: インタラクティブなPDFフォームを作成、記入、および送信します。 テキストと画像の抽出: データ処理や再利用のために、既存のPDFドキュメントからテキストや画像を抽出します。 ドキュメント操作: マージ、スプリット、および新規または既存のPDFファイルのページを再配置します。 画像とページのハンドリング: PDFページを画像にラスタライズし、画像をPDF形式に変換します。 カスタムログインクレデンシャルの使用: IronPDFはURLからドキュメントを作成できます。 カスタムネットワークログインクレデンシャル、ユーザーエージェント、プロキシ、クッキー、HTTPヘッダー、およびHTMLログインフォームの背後でのログイン用のフォーム変数もサポートしています。 検索とアクセシビリティ: PDFドキュメント内のテキストを検索し、アクセシビリティ基準を満たしていることを確認します。 変換の柔軟性: PDFをHTMLなどの他の形式に変換し、CSSファイルを使用してPDFを生成します。 スタンドアロン機能: Adobe Acrobatや追加のサードパーティツールを必要とせずに独立して操作します。 2. Visual Studioでプロジェクトを作成する Visual Studioソフトウェアを開き、ファイルメニューに移動します。 "新しいプロジェクト"を選択し、"コンソールアプリケーション"を選択します。 この記事では、コンソールアプリケーションを使用してPDFドキュメントを生成します。 Visual Studio で新しいプロジェクトを作成する 次に、**作成**ボタンをクリックし、以下のスクリーンショットのように必要な.NET Frameworkを選択します。  **Visual Studio で新しいプロジェクトを構成する** Visual Studio プロジェクトは選択したアプリケーションの構造を生成し、コンソール、Windows、Web アプリケーションを選択した場合は、コードを入力してアプリケーションをビルド/実行できる `program.cs` ファイルが開きます。  **.NET Coreの選択** 次に、コードをテストするためにライブラリを追加できます。 ## 3. IronPDFライブラリのインストール IronPDFライブラリは4つの方法でダウンロードとインストールが可能です。 以下のような方法です: - Visual Studioを使用する。 - Visual Studioコマンドラインを使用して。 - NuGetウェブサイトから直接ダウンロードして。 - IronPDFウェブサイトから直接ダウンロード。 ### 3.1 Visual Studioを使用する Visual Studioソフトウェアは、ソリューションにパッケージを直接インストールするためのNuGetパッケージマネージャーオプションを提供します。 以下のスクリーンショットは、NuGetパッケージマネージャーを開く方法を示しています。  **Visual Studio program.cs ファイル** NuGetウェブサイトからパッケージのリストを表示する検索ボックスを提供します。パッケージマネージャで、"IronPdf"というキーワードを検索する必要があります。下記のスクリーンショットのように。  **NuGetパッケージ マネージャー** 上記の画像では、関連する検索項目のリストを見ることができます。 解決策にパッケージをインストールするために必要なオプションを選択する必要があります。 ### 3.2 Visual Studioのコマンドラインを使用する #### 2.2.2 Visual Studioコマンドラインの使用 パッケージマネージャーコンソールタブに次の行を入力します: ```shell :ProductInstall ``` 今、パッケージは現在のプロジェクトにダウンロード/インストールされ、使用可能になります。 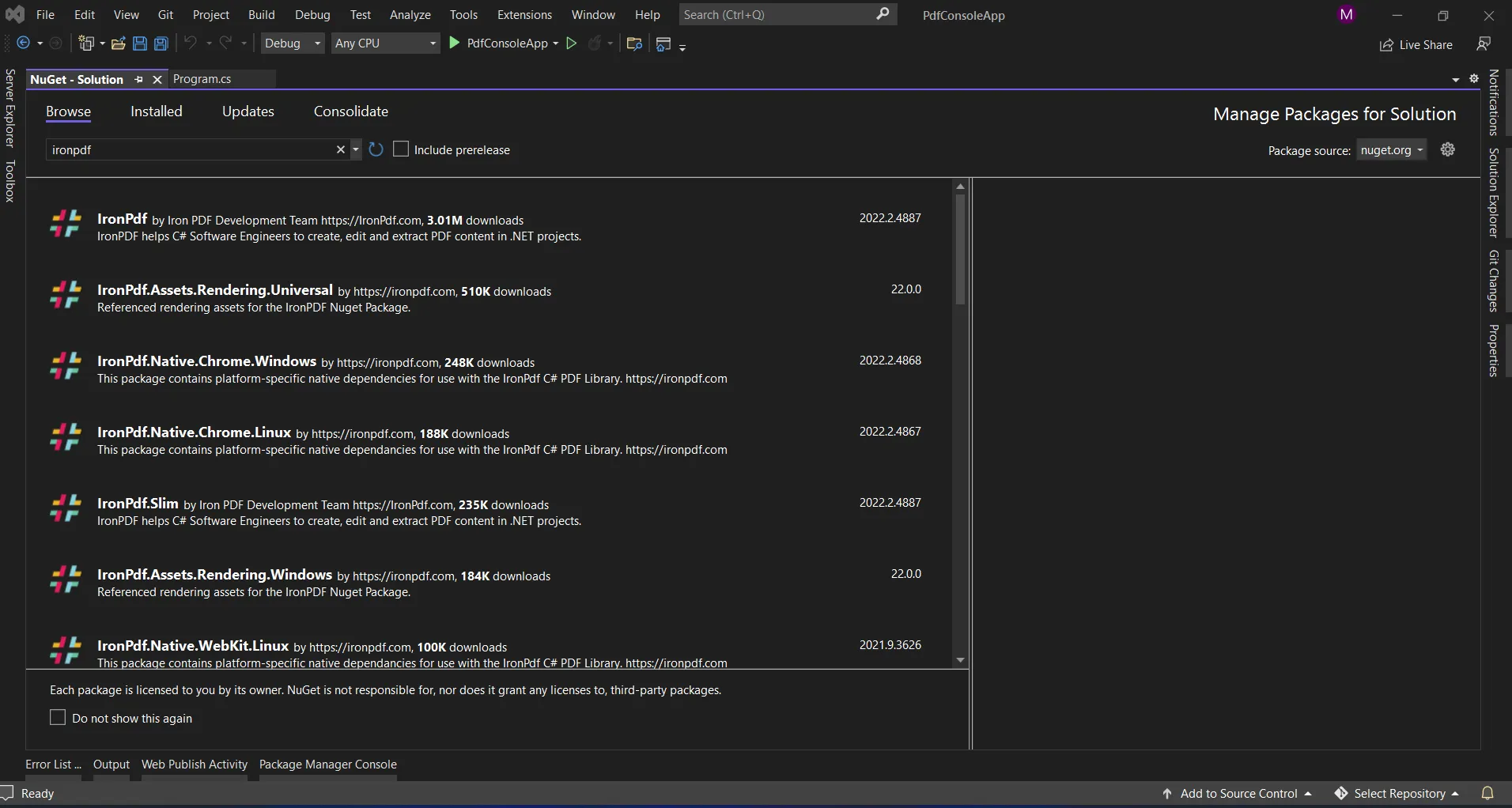 **NuGetパッケージ マネージャーのIronPDFライブラリ** ### 3.3 NuGetウェブサイトからの直接ダウンロード 3番目の方法は、[IronPDF NuGetパッケージ](https://www.nuget.org/packages/IronPdf/)をそのウェブサイトから直接ダウンロードすることです。 - NuGetでIronPDFパッケージに移動します。 - [NuGetリンク](https://www.nuget.org/packages/Barcode/)に移動します - ダウンロードしたパッケージをダブルクリックします。 自動的にインストールされます。 - 次に、ソリューションを再読み込みし、プロジェクトで使用を開始します。 ### 3.4 Direct download from the IronPDF website [IronPDF公式サイト](https://ironpdf.com)を訪れて、最新のパッケージを直接ダウンロードしてください。ダウンロード後、以下の手順に従ってプロジェクトにパッケージを追加してください。 - ソリューションウィンドウからプロジェクトを右クリックします。 - 次に、選択オプションの参照とダウンロードした参照の場所を参照します。 - 次に、参照を追加するにはOKをクリックします。 ## 4. Extract Text Using IronPDF IronPDFプログラムを使ってPDFファイルからテキストを抽出し、PDFページをPDFオブジェクトに変換できるようになります。 以下は、IronPDFを使用して既存のPDFを読み取る方法の例です。 最初のアプローチではPDFからテキストを抽出し、以下のサンプルコードスニペットがそれを示しています。 ```csharp using IronPdf; // Load an existing PDF document from a file var pdfDocument = PdfDocument.FromFile("result.pdf"); // Extract all text from the entire PDF document string allText = pdfDocument.ExtractAllText(); ``` 上記のコードに示すように、静的メソッド `FromFile` は、既存のファイルから PDF ドキュメントを読み込み、それを `PDFDocument` オブジェクトに変換するために使用されます。 このオブジェクトを使用して、PDFページにアクセス可能なテキストと画像を読み取ることができます。 オブジェクトには、PDF ドキュメント全体からすべてのテキストを抽出し、抽出したテキストを処理に使用できる文字列に保持する `ExtractAllText` というメソッドがあります。 以下は、PDFファイルからページ単位でテキストを抽出するために使用できる2番目の方法のコード例です。 ```csharp using IronPdf; // Load an existing PDF document from a file using PdfDocument pdf = PdfDocument.FromFile("result.pdf"); // Loop through each page of the PDF document for (var index = 0; index < pdf.PageCount; index++) { // Extract text from the current page string text = pdf.ExtractTextFromPage(index); } ``` 上記のコードで、最初にPDFドキュメント全体がロードされ、PDFオブジェクトに変換されます。 次に、`PageCount` という組み込みプロパティを使用して PDF ドキュメント全体のページ数を取得します。このプロパティは、読み込まれた PDF ドキュメントで使用可能なページの合計数を取得します。 "for ループ"と `ExtractTextFromPage` 関数を使用すると、ページ番号をパラメーターとして渡し、読み込まれたドキュメントからテキストを抽出することができます。 それから正確なテキストを文字列変数に保持します。 同様に、"for"または"for each"ループを使用してページごとにPDFからテキストを抽出します。 ## 5. 結論 IronPDFは、多用途で強力なPDFライブラリで、.NETアプリケーションでのPDFの取り扱いをシームレスにします。 その強力な機能は、開発者がPDFからコンテンツを作成、操作、抽出することを可能にし、Adobe Readerなどのサードパーティの依存性を必要としません。 IronPDFの注目すべき機能の1つは、PDFドキュメントからテキストを抽出する能力です。 この機能は、データ分析、ドキュメントのインデックス化、コンテンツの移行、アクセシビリティ機能の提供など、自動化タスクにとって非常に貴重です。 開発者がテキストをプログラム的に取得して処理できることにより、IronPDFはワークフローを簡略化し、PDFコンテンツの扱いに新たな可能性を開きます。 簡単な統合とクロスプラットフォームのサポートにより、IronPDFはPDFドキュメントを効率的に扱う開発者にとって優れた選択肢です。 さらに、IronPDFは[無料トライアル](trial-license)を提供しており、購入する前にその完全な機能をリスクなく探索できます。 価格の詳細やライセンスオプションについては、[価格ページ](https://ironpdf.com/licensing/)を訪れてください。 よくある質問 C#を使用してPDFドキュメントからテキストを抽出するにはどうすればよいですか? C#でIronPDFを使用してPDFドキュメントからテキストを抽出できます。まず、PdfDocument.FromFileメソッドを使ってPDFを読み込み、その後ExtractAllTextメソッドを適用してドキュメントからテキストを取得します。 Visual StudioプロジェクトにIronPDFを設定する際の手順は何ですか? Visual StudioプロジェクトにIronPDFを設定するには、NuGetパッケージマネージャー経由でインストールできます。または、Visual Studioのコマンドラインを使用したり、NuGetまたはIronPDFのウェブサイトから直接ダウンロードすることもできます。 IronPDFを包括的なPDFライブラリにする特徴は何ですか? IronPDFは、PDFの作成、HTMLからPDFへの変換、テキストと画像の抽出、ドキュメントの操作、インタラクティブなPDFフォームのサポートなど、幅広い機能を提供します。 IronPDFはC#でHTMLをPDFに変換できますか? はい、IronPDFはRazor/MVCビューやメディアタイプのCSSファイルを含むHTMLを、統合されたChromeエンジンを使用して直接PDF形式に変換できます。 IronPDFはあらゆる種類 for .NETアプリケーションに互換性がありますか? はい、IronPDFはASP.NETウェブアプリケーションと従来のWindowsアプリケーションの両方に互換性があり、.NET開発者にとっての柔軟性を提供します。 IronPDFはPDFドキュメントのアクセシビリティをどのように促進しますか? IronPDFは、PDFドキュメント内のテキスト検索を可能にし、アクセシビリティ標準に準拠することでアクセシビリティを向上させます。 IronPDFに必要なサードパーティの依存関係はありますか? IronPDFは独立して動作するため、Adobe Acrobatのようなサードパーティツールを必要とせず、.NETアプリケーション内でシームレスなPDF操作が可能です。 PDFからのテキスト抽出にIronPDFを使用する利点は何ですか? IronPDFはプログラムによるテキスト抽出を可能にすることで、データ分析、ドキュメントインデキシング、コンテンツ移行に利用できるワークフローを合理化します。 IronPDFの試用版は利用できますか? はい、IronPDFは無料試用版を提供しており、開発者が購入を決定する前にその機能と能力を探索できます。 IronPDFを使用したPDF管理の重要性は何ですか? C#のテキスト抽出 この記事のC# PDFテキスト抽出コードは.NET 10と互換性がありますか? はい。このチュートリアルの PdfDocument.FromFile と ExtractText の例は、.NET 10 でも以前のバージョンの .NET と同じように動作します。.NET 10 プロジェクトを作成したら、NuGet から最新の IronPDF パッケージをインストールすると、同じコードを実行して最新の .NET 10 アプリケーションで PDF の読み取りやテキストの抽出を行うことができます。 Kye Stuart 今すぐエンジニアリングチームとチャット テクニカルライター Kye Stuartは、Iron Softwareでコーディングへの情熱と執筆スキルを融合させています。ソフトウェアデプロイメントを学んでいるYoobeeカレッジで教育を受け、今では複雑な技術的概念を明瞭な教育コンテンツに変換しています。Kyeは生涯学習を重視し、新しい技術的課題を受け入れています。仕事の外では、PCゲームを楽しんだり、Twitchでストリーミングをしたり、Jaiyaという犬と庭仕事や散歩をするなど、アウトドア活動を楽しんでいます。Kyeの明確なアプローチは、Iron Softwareの技術を世界中の開発者に親しみやすくするという使命の重要な部分を担っています。 関連する記事 更新日 2026年3月1日 .NETでIronPDFを使用してPDFファイルを作成する方法 (C#チュートリアル) C#で開発者向けにPDFファイルを作成する効果的な方法を発見します。コーディングスキルを向上させ、プロジェクトを効率化します。この記事を今すぐお読みください! 詳しく読む 更新日 2026年2月27日 C#でPDFファイルをマージする方法 IronPDF で PDF をマージします。シンプルな VB.NET コードを使用して、複数の PDF ファイルを1つのドキュメントに結合する方法を学びます。ステップバイステップの例が含まれています。 詳しく読む 更新日 2026年3月1日 .NET 10 開発者向け C# PDFWriter チュートリアル このステップバイステップガイドで開発者がC# PDFWriterを使用してPDFを効率的に作成する方法を学びます。記事を読んでスキルを向上させましょう! 詳しく読む C#を使用してASP.NETでPDFを生成する方法C# で PDF からデータを抽出...
更新日 2026年3月1日 .NETでIronPDFを使用してPDFファイルを作成する方法 (C#チュートリアル) C#で開発者向けにPDFファイルを作成する効果的な方法を発見します。コーディングスキルを向上させ、プロジェクトを効率化します。この記事を今すぐお読みください! 詳しく読む
更新日 2026年2月27日 C#でPDFファイルをマージする方法 IronPDF で PDF をマージします。シンプルな VB.NET コードを使用して、複数の PDF ファイルを1つのドキュメントに結合する方法を学びます。ステップバイステップの例が含まれています。 詳しく読む
更新日 2026年3月1日 .NET 10 開発者向け C# PDFWriter チュートリアル このステップバイステップガイドで開発者がC# PDFWriterを使用してPDFを効率的に作成する方法を学びます。記事を読んでスキルを向上させましょう! 詳しく読む