
IronPDFを使用してBlazor PDFビューアーを作成する方法
C#で2つのPDFバイト配列をマージするには、IronPDFのPdfDocument.Merge()メソッドを使用します。このメソッドはバイト配列をPdfDocumentオブジェクトに読み込み、構造、フォーマット、およびフォームフィールドを保ちながらそれらを結合します。ファイルシステムへのアクセスは必要ありません。
メモリ内のPDFファイルを扱うことは、現代の.NETアプリケーションにおいて一般的な要件です。 ウェブAPIから複数のPDFファイルを受け取ったり、データベースのBLOB列から取得したり、サーバーからアップロードされたファイルを処理したりする際に、ファイルシステムに触れることなく、複数のPDFバイト配列を単一のPDFドキュメントに結合する必要がよくあります。 この記事では、 IronPDF がPDF をプログラム的に結合するための直感的な API を使用して、いかにして PDF の結合を驚くほど簡単にするのかを説明します。
なぜPDFファイルのバイト配列を単純に連結できないのか?
テキストファイルとは異なり、PDFドキュメントは交差参照テーブル、オブジェクト定義、特定のフォーマット要件を持つ複雑な内部構造を持っています。 2つのPDFファイルをバイト配列として単純に連結すると、ドキュメント構造が破損し、読み取り不可能なPDFファイルが生成されます。そのため、IronPDFのような専用のPDFライブラリが不可欠です。これらのライブラリはPDF仕様を理解し、整合性を維持しながらPDFファイルを適切に結合します。 Stack Overflowフォーラムのディスカッションによると、バイト配列の直接連結を試みることは、PDF コンテンツを結合するときに開発者が犯す一般的な間違いです。
PDF バイトを直接連結すると何が起こりますか?
PDF バイトが適切な解析なしに連結されると、結果のファイルには複数の PDF ヘッダー、競合する相互参照テーブル、壊れたオブジェクト参照が含まれます。 PDF リーダーはこの不正な構造を解釈できないため、破損エラーが発生したり、ドキュメントが空白になったりします。 PDF/A 形式では特に構造標準に厳密に準拠する必要があるため、アーカイブ ドキュメントでは適切な結合が不可欠です。
PDF 構造に特別な処理が必要なのはなぜですか?
PDF には相互接続されたオブジェクト、フォント定義、ページ ツリーが含まれており、これらは慎重に結合する必要があります。 各 PDF の内部参照を更新して、結合されたドキュメント内の正しい場所を指すようにする必要があります。そのためには、PDF 仕様を理解する必要があります。 マージ操作中にフォントを管理し、メタデータを保持するには、専用の PDF ライブラリだけが提供する高度な解析機能が必要です。

PDF を結合するために IronPDF を設定する方法
.NETプロジェクト内でNuGetパッケージマネージャーを通じてIronPDFをインストールします:
Install-Package IronPdf
またはここに画像をドラッグアンドドロップしてください
ライブラリをインポートするために必要なusingステートメントを追加します:
using IronPdf;
using System.IO; // For MemoryStream
using System.Threading.Tasks;
using System.Collections.Generic; // For List operations
using System.Linq; // For LINQ transformationsusing IronPdf;
using System.IO; // For MemoryStream
using System.Threading.Tasks;
using System.Collections.Generic; // For List operations
using System.Linq; // For LINQ transformationsImports IronPdf
Imports System.IO ' For MemoryStream
Imports System.Threading.Tasks
Imports System.Collections.Generic ' For List operations
Imports System.Linq ' For LINQ transformations実稼働サーバー環境では、ライセンス キーを適用して、パスワード制限なしですべての機能にアクセスします。
IronPdf.License.LicenseKey = "YOUR-LICENSE-KEY";IronPdf.License.LicenseKey = "YOUR-LICENSE-KEY";IronPdf.License.LicenseKey = "YOUR-LICENSE-KEY"IronPDF はWindows、Linux、macOS、Docker コンテナーをサポートしているため、 ASP.NET Coreやクラウドネイティブ アプリケーションに最適です。 ライブラリのネイティブ エンジンとリモート エンジンのアーキテクチャにより、 Windows サーバーからLinux コンテナーまで、さまざまな展開シナリオに柔軟に対応できます。
コンテナの展開要件は何ですか?
IronPDF は、外部依存関係なしでDocker コンテナー内でネイティブに実行されます。 ライブラリには必要なすべてのコンポーネントが含まれているため、コンテナ イメージで Chrome をインストールしたり、複雑なフォント構成を行う必要がなくなります。 コンテナ化された環境で最適なパフォーマンスを得るには、 IronPDFランタイム フォルダーを構成し、適切なリソース監視を実装します。 AWS LambdaまたはAzure Functionsにデプロイする場合、ライブラリはプラットフォーム固有の最適化を自動的に処理します。
IronPDF はクロスプラットフォームの互換性をどのように処理しますか?
このライブラリは、プラットフォーム固有の操作を抽象化する自己完結型アーキテクチャを使用しており、プラットフォーム固有のコードを必要とせずに、Windows Server、Linux ディストリビューション、コンテナー化された環境全体で一貫した動作を保証します。 Chrome レンダリング エンジンはプラットフォーム間でピクセル単位の完璧な一貫性を提供し、 IronPDFEngine Docker コンテナはリソースを大量に消費する操作のリモート処理を可能にします。

IronPDFを使用してC#で2つのPDFバイト配列をマージする方法は?
var PDF = PdfDocument.Merge(
PdfDocument.FromBytes(pdfBytes1),
PdfDocument.FromBytes(pdfBytes2));var PDF = PdfDocument.Merge(
PdfDocument.FromBytes(pdfBytes1),
PdfDocument.FromBytes(pdfBytes2));Dim PDF = PdfDocument.Merge( _
PdfDocument.FromBytes(pdfBytes1), _
PdfDocument.FromBytes(pdfBytes2))Here's the core code sample for merging two PDF files from byte array data:
public byte[] MergePdfByteArrays(byte[] firstPdf, byte[] secondPdf)
{
// Load the first PDF file from byte array
var pdf1 = new PdfDocument(firstPdf);
// Load the second PDF file from byte array
var pdf2 = new PdfDocument(secondPdf);
// Merge PDF documents into one PDF
var mergedPdf = PdfDocument.Merge(pdf1, pdf2);
// Return the combined PDF as byte array
return mergedPdf.BinaryData;
}public byte[] MergePdfByteArrays(byte[] firstPdf, byte[] secondPdf)
{
// Load the first PDF file from byte array
var pdf1 = new PdfDocument(firstPdf);
// Load the second PDF file from byte array
var pdf2 = new PdfDocument(secondPdf);
// Merge PDF documents into one PDF
var mergedPdf = PdfDocument.Merge(pdf1, pdf2);
// Return the combined PDF as byte array
return mergedPdf.BinaryData;
}Public Function MergePdfByteArrays(firstPdf As Byte(), secondPdf As Byte()) As Byte()
' Load the first PDF file from byte array
Dim pdf1 = New PdfDocument(firstPdf)
' Load the second PDF file from byte array
Dim pdf2 = New PdfDocument(secondPdf)
' Merge PDF documents into one PDF
Dim mergedPdf = PdfDocument.Merge(pdf1, pdf2)
' Return the combined PDF as byte array
Return mergedPdf.BinaryData
End FunctionThis method accepts two PDF byte arrays as input parameters. PdfDocumentオブジェクトに読み込みます。 Merge()メソッドは2つのPDFドキュメントを1つの新しいPDFに結合し、すべてのコンテンツ、フォーマット、およびフォームフィールドを保持します。 より複雑なシナリオでは、高度なレンダリング オプションを使用してマージ動作を制御できます。
マージされた出力はどのようになりますか?
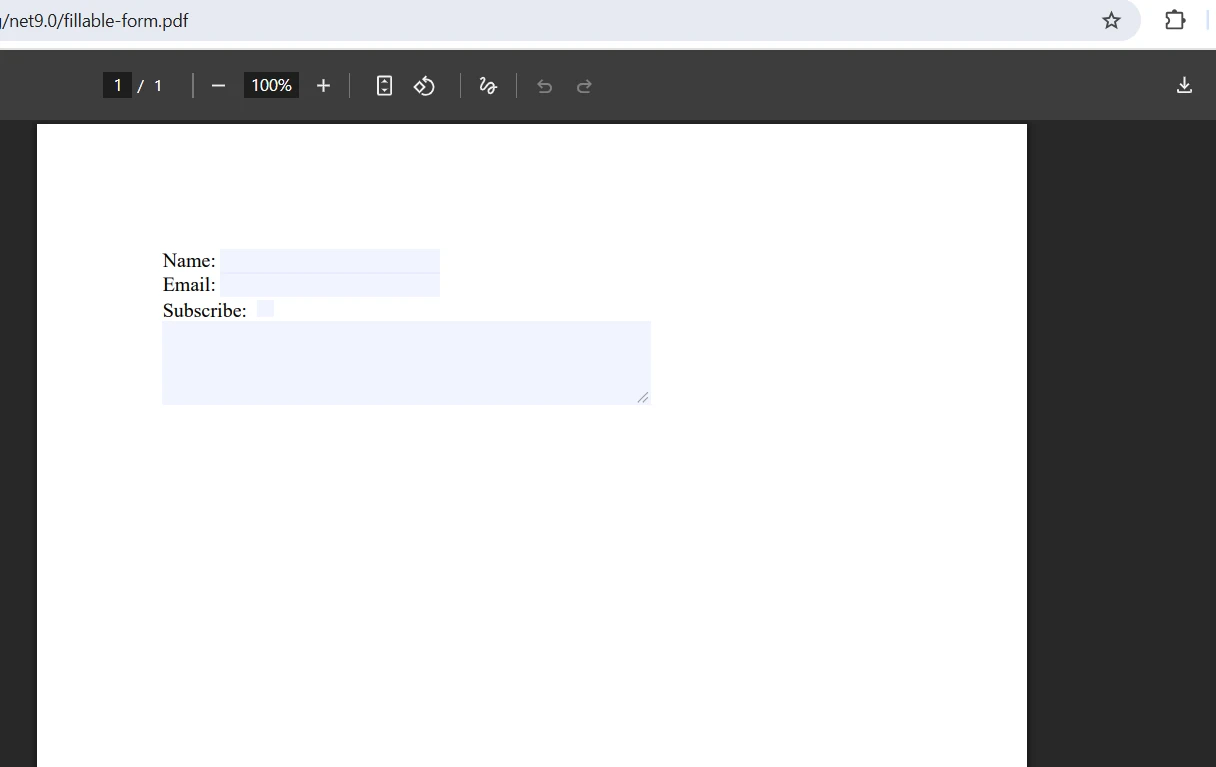
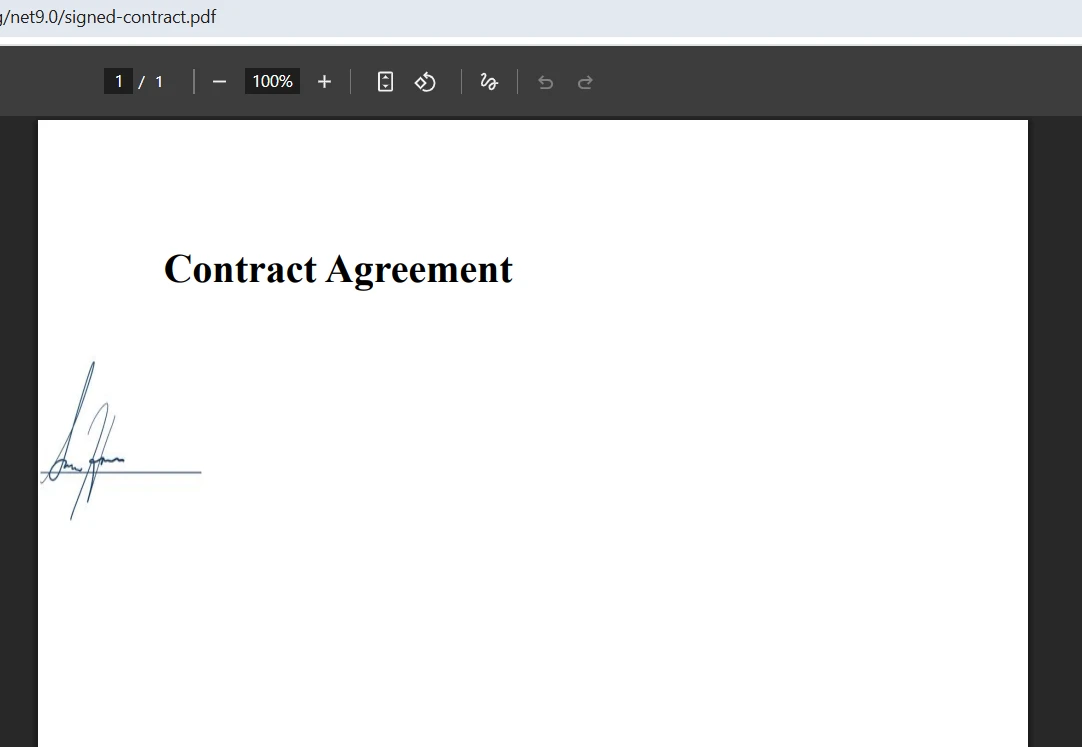
マージ中にフォーム フィールドの競合を処理するにはどうすればよいでしょうか?
より多くの制御が必要な場合、新しいMemoryStreamを直接操作することもできます。
public byte[] MergePdfsWithStream(byte[] src1, byte[] src2)
{
using (var stream = new MemoryStream())
{
var pdf1 = new PdfDocument(src1);
var pdf2 = new PdfDocument(src2);
var combined = PdfDocument.Merge(pdf1, pdf2);
// Handle form field name conflicts
if (combined.Form != null && combined.Form.Fields.Count > 0)
{
// Access and modify form fields if needed
foreach (var field in combined.Form.Fields)
{
// Process form fields
Console.WriteLine($"Field: {field.Name}");
}
}
return combined.BinaryData;
}
}public byte[] MergePdfsWithStream(byte[] src1, byte[] src2)
{
using (var stream = new MemoryStream())
{
var pdf1 = new PdfDocument(src1);
var pdf2 = new PdfDocument(src2);
var combined = PdfDocument.Merge(pdf1, pdf2);
// Handle form field name conflicts
if (combined.Form != null && combined.Form.Fields.Count > 0)
{
// Access and modify form fields if needed
foreach (var field in combined.Form.Fields)
{
// Process form fields
Console.WriteLine($"Field: {field.Name}");
}
}
return combined.BinaryData;
}
}Imports System
Imports System.IO
Public Function MergePdfsWithStream(src1 As Byte(), src2 As Byte()) As Byte()
Using stream As New MemoryStream()
Dim pdf1 As New PdfDocument(src1)
Dim pdf2 As New PdfDocument(src2)
Dim combined As PdfDocument = PdfDocument.Merge(pdf1, pdf2)
' Handle form field name conflicts
If combined.Form IsNot Nothing AndAlso combined.Form.Fields.Count > 0 Then
' Access and modify form fields if needed
For Each field In combined.Form.Fields
' Process form fields
Console.WriteLine($"Field: {field.Name}")
Next
End If
Return combined.BinaryData
End Using
End Function両方のPDFファイルが同じ名前のフォームフィールドを含む場合、IronPDFは自動的にアンダースコアを追加して名前の競合を処理します。 入力可能な PDF フォームを使用する場合、結合されたドキュメントを保存する前に、プログラムでフォーム フィールドにアクセスして変更できます。 PDF DOM オブジェクト モデルは、フォーム要素を完全に制御できます。 最後に、BinaryDataプロパティが結合されたPDFをバイト配列形式の新しいドキュメントとして返します。 結果を他のメソッドに渡すには、このバイト配列を返すだけです。必要がない限り、ディスクに保存する必要はありません。
パフォーマンス向上のために非同期マージを実装するにはどうすればよいでしょうか?
次のコードは、PDFドキュメントを非同期的に結合する方法を示しています。 この非同期実装は、PDFの結合操作をTask.Run()でラップし、バックグラウンドスレッドで実行できるようにします。
public async Task<byte[]> MergePdfByteArraysAsync(byte[] firstPdf, byte[] secondPdf)
{
return await Task.Run(() =>
{
var pdf1 = new PdfDocument(firstPdf);
var pdf2 = new PdfDocument(secondPdf);
var PDF = PdfDocument.Merge(pdf1, pdf2);
return PDF.BinaryData;
});
}public async Task<byte[]> MergePdfByteArraysAsync(byte[] firstPdf, byte[] secondPdf)
{
return await Task.Run(() =>
{
var pdf1 = new PdfDocument(firstPdf);
var pdf2 = new PdfDocument(secondPdf);
var PDF = PdfDocument.Merge(pdf1, pdf2);
return PDF.BinaryData;
});
}Imports System.Threading.Tasks
Public Class PdfMerger
Public Async Function MergePdfByteArraysAsync(firstPdf As Byte(), secondPdf As Byte()) As Task(Of Byte())
Return Await Task.Run(Function()
Dim pdf1 = New PdfDocument(firstPdf)
Dim pdf2 = New PdfDocument(secondPdf)
Dim PDF = PdfDocument.Merge(pdf1, pdf2)
Return PDF.BinaryData
End Function)
End Function
End Classこの非同期実装はPDFマージ操作をTask.Run()でラップし、バックグラウンドスレッドで実行できるようにします。 This approach is particularly valuable in ASP.NET web applications where you want to maintain responsive request handling while processing multiple PDF documents. このメソッドはTask<byte[]>を返し、呼び出し元がメインスレッドをブロックせずに結果を待機できるようにします。 上記のコードは、大きなPDFファイル操作を扱う際の効率的なメモリ管理を確保します。 より高度なシナリオについては、 IronPDFの非同期およびマルチスレッド パターンを調べてください。
非同期 PDF 操作はいつ使用すればよいですか?
10MBを超えるPDFを処理する場合、複数の同時リクエストを処理する場合、または非同期Web APIと統合する場合は、非同期マージを使用してください。これにより、高トラフィックのシナリオにおけるスレッドプールの枯渇を防止できます。 外部リソースが関係する操作に対してレンダリング遅延とタイムアウトを実装することを検討してください。 マイクロサービス アーキテクチャでは、非同期操作によってリソースの使用率が向上し、ピーク負荷時の連鎖的な障害を防ぐことができます。
パフォーマンスにはどのような影響がありますか?
非同期操作により、同時実行性の高いシナリオでメモリ負荷が最大 40% 軽減されます。 これらにより、CPU とメモリの制限が厳密に適用されるコンテナ化された環境でのリソース利用率が向上します。 並列 PDF 生成技術と組み合わせると、パフォーマンスを大幅に向上させることができます。 カスタム ログを使用してパフォーマンスを監視し、PDF 処理パイプラインのボトルネックを特定します。
複数の PDF ファイルを効率的に結合する方法
複数の PDF ファイルを操作する場合は、リストを使用してバッチ処理を行います。 この方法を使用すると、任意の数の PDF ドキュメントを 1 つの PDF に結合することができます。
public byte[] MergeMultiplePdfByteArrays(List<byte[]> pdfByteArrays)
{
if (pdfByteArrays == null || pdfByteArrays.Count == 0)
return null;
// Convert all byte arrays to PdfDocument objects
var pdfDocuments = pdfByteArrays
.Select(bytes => new PdfDocument(bytes))
.ToList();
// Merge all PDFs in one operation
var PDF = PdfDocument.Merge(pdfDocuments);
// Clean up resources
foreach (var pdfDoc in pdfDocuments)
{
pdfDoc.Dispose();
}
return PDF.BinaryData;
}public byte[] MergeMultiplePdfByteArrays(List<byte[]> pdfByteArrays)
{
if (pdfByteArrays == null || pdfByteArrays.Count == 0)
return null;
// Convert all byte arrays to PdfDocument objects
var pdfDocuments = pdfByteArrays
.Select(bytes => new PdfDocument(bytes))
.ToList();
// Merge all PDFs in one operation
var PDF = PdfDocument.Merge(pdfDocuments);
// Clean up resources
foreach (var pdfDoc in pdfDocuments)
{
pdfDoc.Dispose();
}
return PDF.BinaryData;
}Imports System.Collections.Generic
Imports System.Linq
Public Function MergeMultiplePdfByteArrays(pdfByteArrays As List(Of Byte())) As Byte()
If pdfByteArrays Is Nothing OrElse pdfByteArrays.Count = 0 Then
Return Nothing
End If
' Convert all byte arrays to PdfDocument objects
Dim pdfDocuments = pdfByteArrays _
.Select(Function(bytes) New PdfDocument(bytes)) _
.ToList()
' Merge all PDFs in one operation
Dim PDF = PdfDocument.Merge(pdfDocuments)
' Clean up resources
For Each pdfDoc In pdfDocuments
pdfDoc.Dispose()
Next
Return PDF.BinaryData
End FunctionThis method efficiently handles any number of PDF byte arrays. It first validates the input to ensure the list contains data. LINQのPdfDocumentオブジェクトに変換します。 Merge()メソッドはPDFDocumentオブジェクトのリストを受け取り、1つの操作でそれらすべてを結合し、新しいドキュメントを作成します。 リソースのクリーンアップは重要です - 個々のPdfDocumentオブジェクトをPDFマージ後に廃棄することで、メモリとリソースを効果的に管理できます。特に多数または大規模なPDFファイルを処理する場合に有効です。 ## 生産用途におけるベストプラクティスとは? よりきめ細かな制御を行うために、複数ページの PDF を分割したり、特定のページをコピーしたりすることもできます。
どのようなメモリ最適化手法を適用する必要がありますか?
予測可能なメモリ使用量を維持するために、PDF を 10 ~ 20 ドキュメント単位でバッチ処理します。 より大規模な操作の場合は、同時実行制限を設定できるキューベースのアプローチを実装します。 処理中のメモリフットプリントを削減するには、 PDF 圧縮を使用します。 大きな出力ファイルを扱う場合は、結果をメモリに保持するのではなく、 Azure Blob Storageに直接ストリーミングすることを検討してください。
バッチ操作中にリソースの使用状況を監視するにはどうすればよいでしょうか?
アクティブなマージ操作、メモリ消費量、処理キューの深さを追跡するヘルスチェック エンドポイントを実装します。 これにより、Kubernetes 準備プローブがポッドのスケーリングを適切に管理できるようになります。 パフォーマンス メトリックをキャプチャし、メモリ リークを識別するためにIronPDFログを構成します。 メモリ ストリーム API を使用して、バッチ操作中の正確なメモリ割り当てパターンを追跡します。
PDF操作を常にtry-catchブロックでラップし、破損したまたはパスワード保護されたPDFファイルからの潜在的な例外を処理します。
破損した PDF ファイルやパスワードで保護された PDF ファイルからの潜在的な例外を処理するには、常に PDF 操作を try-catch ブロックで囲みます。 メモリリークを防ぐためにusingステートメントを使用するか、PdfDocumentオブジェクトを明示的に破棄してください。 複数のPDFドキュメントから選択したページを操作するときは、結合前に特定のPdfPageインスタンスを抽出することもできます。
public byte[] SafeMergePdfByteArrays(byte[] firstPdf, byte[] secondPdf)
{
try
{
// Validate input PDFs
if (firstPdf == null || firstPdf.Length == 0)
throw new ArgumentException("First PDF is empty");
if (secondPdf == null || secondPdf.Length == 0)
throw new ArgumentException("Second PDF is empty");
using (var pdf1 = new PdfDocument(firstPdf))
using (var pdf2 = new PdfDocument(secondPdf))
{
// Check for password protection
if (pdf1.IsPasswordProtected || pdf2.IsPasswordProtected)
throw new InvalidOperationException("Password-protected PDFs require authentication");
var mergedPdf = PdfDocument.Merge(pdf1, pdf2);
// Apply security settings if needed
mergedPdf.SecuritySettings.AllowUserPrinting = true;
mergedPdf.SecuritySettings.AllowUserCopyPasteContent = false;
return mergedPdf.BinaryData;
}
}
catch (Exception ex)
{
// Log error details for debugging
Console.WriteLine($"PDF merge failed: {ex.Message}");
throw;
}
}public byte[] SafeMergePdfByteArrays(byte[] firstPdf, byte[] secondPdf)
{
try
{
// Validate input PDFs
if (firstPdf == null || firstPdf.Length == 0)
throw new ArgumentException("First PDF is empty");
if (secondPdf == null || secondPdf.Length == 0)
throw new ArgumentException("Second PDF is empty");
using (var pdf1 = new PdfDocument(firstPdf))
using (var pdf2 = new PdfDocument(secondPdf))
{
// Check for password protection
if (pdf1.IsPasswordProtected || pdf2.IsPasswordProtected)
throw new InvalidOperationException("Password-protected PDFs require authentication");
var mergedPdf = PdfDocument.Merge(pdf1, pdf2);
// Apply security settings if needed
mergedPdf.SecuritySettings.AllowUserPrinting = true;
mergedPdf.SecuritySettings.AllowUserCopyPasteContent = false;
return mergedPdf.BinaryData;
}
}
catch (Exception ex)
{
// Log error details for debugging
Console.WriteLine($"PDF merge failed: {ex.Message}");
throw;
}
}Imports System
Public Function SafeMergePdfByteArrays(firstPdf As Byte(), secondPdf As Byte()) As Byte()
Try
' Validate input PDFs
If firstPdf Is Nothing OrElse firstPdf.Length = 0 Then
Throw New ArgumentException("First PDF is empty")
End If
If secondPdf Is Nothing OrElse secondPdf.Length = 0 Then
Throw New ArgumentException("Second PDF is empty")
End If
Using pdf1 As New PdfDocument(firstPdf)
Using pdf2 As New PdfDocument(secondPdf)
' Check for password protection
If pdf1.IsPasswordProtected OrElse pdf2.IsPasswordProtected Then
Throw New InvalidOperationException("Password-protected PDFs require authentication")
End If
Dim mergedPdf = PdfDocument.Merge(pdf1, pdf2)
' Apply security settings if needed
mergedPdf.SecuritySettings.AllowUserPrinting = True
mergedPdf.SecuritySettings.AllowUserCopyPasteContent = False
Return mergedPdf.BinaryData
End Using
End Using
Catch ex As Exception
' Log error details for debugging
Console.WriteLine($"PDF merge failed: {ex.Message}")
Throw
End Try
End Function複数のPDFドキュメントから選択されたページで作業する場合、マージ前に特定のPdfPageインスタンスを抽出することもできます。 IronPDF の包括的なエラー処理により、テスト環境と本番環境の両方で堅牢な本番環境の展開が保証されます。  信頼できない入力ソースに対してPDF サニタイズを実装し、ドキュメント認証にはデジタル署名を実装することを検討してください。
信頼できない入力ソースに対してPDF サニタイズを実装し、ドキュメント認証にはデジタル署名を実装することを検討してください。
コンテナ化された環境で適切なエラー処理を実装するにはどうすればよいですか?
分散システム全体で PDF 操作を追跡するために、相関 ID を使用して構造化ログを構成します。 カスケード障害を防ぐために、外部 PDF ソース用のサーキットブレーカーを実装します。 一元的なエラー追跡には、 Azure ログ ファイルまたはAWS ログ ファイルを使用します。 ネイティブ例外を処理するときは、デバッグのために適切なエラー コンテキストがキャプチャされていることを確認します。
PDF 処理サービスに最適な展開パターンは何ですか?
専用のリソース制限を持つ個別のマイクロサービスとして PDF 処理を展開します。 最適なパフォーマンスを得るには、CPU ではなくメモリ使用量に基づいて水平ポッド自動スケーリングを使用します。 設定可能な同時実行性を備えたバッチ操作用のキューベースの処理を実装します。 コンテナ イメージのサイズを縮小するには、 IronPdf.Slimパッケージの使用を検討してください。 一貫性を保つために、サービス レベルでカスタム用紙サイズとカスタム余白を構成します。
生産 PDF 操作にIronPDF を選択する理由
ドキュメント管理システムを構築する、APIレスポンスを処理する、添付ファイル付きのファイルアップロードを処理する、またはデータベースストレージを操作する場合でも、IronPDFのPDF結合機能は.NETアプリケーションにスムーズに統合されます。 ドキュメント管理システムの構築、API 応答の処理、添付ファイル付きのファイルアップロードの処理、データベース ストレージの操作など、IronPDF のマージ機能は.NETアプリケーションにシームレスに統合されます。
このライブラリは非同期操作とメモリ効率の高い処理をサポートしているため、デスクトップ アプリケーションとサーバー アプリケーションの両方に最適です。 一時ファイルをディスクに書き込むことなくPDFファイルを編集、変換、保存できます。 追加のサポートや回答については、フォーラムまたはウェブサイトをご覧ください。APIリファレンスには、利用可能なすべてのメソッドとプロパティに関する包括的なドキュメントが掲載されています。
アプリケーションに PDF マージを実装する準備はできていますか? 無料トライアルを開始するか、包括的なAPI ドキュメントを参照して、 HTML から PDF への変換、PDF フォームの処理、デジタル署名など、IronPDF の完全な機能セットをご確認ください。 当サイトでは、すべての System.IO ストリーム操作に関する完全なリファレンス ドキュメントと、高度な PDF 操作シナリオに関する広範なチュートリアルを提供しています。
よくある質問
C#で2つのPDFバイト配列をマージするにはどうすれば良いですか?
IronPDFを使用してC#で2つのPDFバイト配列をマージできます。ディスクに保存する必要なく、複数のPDFファイルをバイト配列として簡単に1つのPDFドキュメントに統合できます。
PDFバイト配列をマージするのにIronPDFを使用するメリットは何ですか?
IronPDFは、直感的なAPIを提供することでPDFバイト配列のマージプロセスを簡素化します。メモリ内でPDFを効率的に処理し、データベースやWebサービスからPDFを取得するアプリケーションに理想的です。
IronPDFはディスクに保存せずにPDFファイルをマージできますか?
はい、IronPDFはディスクに保存せずにPDFファイルをマージできます。バイト配列から直接PDFファイルを処理し、メモリベースの操作に適しています。
IronPDFを使用してWebサービスから受信したPDFファイルをマージすることは可能ですか?
もちろんです。IronPDFは、Webサービスからバイト配列として受け取ったPDFファイルをマージでき、リモートPDFソースとのシームレスな統合を可能にします。
C#でPDFバイト配列をマージする一般的な用途は何ですか?
一般的な用途として、データベースから取得した複数のPDFドキュメントを1つのPDFファイルに結合し、その後C#アプリケーションで処理または表示することがあります。
IronPDFはメモリ内でPDFを処理することをサポートしていますか?
はい、IronPDFはメモリ内でのPDF処理をサポートしており、中間ディスクストレージなしでPDFファイルを迅速に操作する必要があるアプリケーションにとって重要です。
IronPDFはデータベースからのPDFマージをどのように処理しますか?
IronPDFはPDFバイト配列を直接操作できることにより、データベースからのPDFマージを処理します。これにより、一時ファイルの保存が不要となります。
IronPDFは複数のPDFファイルを1つに統合できますか?
はい、IronPDFは複数のPDFファイルをそのバイト配列をマージすることで1つに統合でき、複合PDFドキュメントを作成する簡略化された方法を提供します。











