
IronPDF Kullanarak Blazor'da PDF Görüntüleyici Nasıl Oluşturulur
C#'da iki PDF bayt dizisini birleştirmek için, IronPDF'nin PdfDocument.Merge() yöntemiyle bayt dizilerini PdfDocument nesnelerine yükleyip, yapısını, biçimlendirmeyi ve form alanlarını koruyarak birleştirebilirsiniz - dosya sistemi erişimi gerekmez.
Modern .NET uygulamalarında bellek içindeki PDF dosyalarıyla çalışmak yaygın bir gereksinimdir. İster web API'lerinden birden çok PDF dosyası alıyor olun, ister bunları veritabanı BLOB sütunlarından çekiyor olun, ister sunucunuzdan yüklenen dosyaları işliyor olun, genellikle dosya sistemine dokunmadan birden fazla PDF bayt dizisini tek bir PDF belgesinde birleştirmeniz gerekir. Bu makalede, IronPDF'in, PDF'leri programatik olarak birleştirmek için sunduğu sezgisel API ile PDF birleştirmeyi nasıl son derece kolaylaştırdığını inceleyeceğiz.
Neden PDF Dosya Byte Dizilerini Basitçe Birleştiremezsiniz?
Metin dosyalarının aksine, PDF belgeleri çapraz referans tabloları, nesne tanımları ve belirli biçimlendirme gereksinimleri ile karmaşık bir iç yapıya sahiptir. İki PDF dosyasını bayt dizileri olarak basitçe birleştirmek, belgenin yapısını bozarak okunamaz bir PDF dosyası oluşturur. Bu nedenle IronPDF gibi özel PDF kütüphaneleri hayati öneme sahiptir - PDF spesifikasyonunu anlarlar ve PDF dosyalarını bütünlüklerini koruyarak düzgün bir şekilde birleştirirler. Stack Overflow forum tartışmalarına göre, doğrudan bayt dizisi birleştirme girişimi, geliştiricilerin PDF içeriğini birleştirmeye çalışırken yaptığı yaygın bir hatadır.
PDF baytlarını doğrudan birleştirdiğinizde ne olur?
PDF baytları doğru bir şekilde ayrıştırılmadan birleştirildiğinde, ortaya çıkan dosya birden fazla PDF başlığı, çakışan çapraz referans tabloları ve bozuk nesne referansları içerir. PDF okuyucular, bu hatalı yapıyı yorumlayamaz, bu da bozulma hatalarına veya boş belgelere yol açar. PDF/A formatı, özellikle yapısal standartlara sıkı uyum gerektirir ve bu da arşiv belgeleri için doğru biçimde birleştirmenin hayati olmasını sağlar.
PDF yapıları neden özel bir işlem gerektirir?
PDF'ler, dikkatlice birleştirilmesi gereken birbirine bağlı nesneler, yazı tipi tanımları ve sayfa ağaçları içerir. Her PDF'nin iç referanslarının birleştirilmiş belgedeki doğru konumları işaret edecek şekilde güncellenmesi gerekiyor, bu da PDF spesifikasyonunu anlamayı gerektirir. Yazı tiplerini yönetme ve birleştirme işlemleri sırasında meta verileri koruma, yalnızca özel PDF kütüphanelerinin sunduğu gelişmiş ayrıştırma yetenekleri gerektirir.

PDF'leri Birleştirmek için IronPDF Nasıl Kurulur?
.NET projenizde NuGet Package Manager aracılığıyla IronPDF kurun:
Install-Package IronPdf
veya buraya bir görüntü sürükleyip bırakın
Gerekli using bildirimlerini ekleyerek kütüphaneyi içe aktarın:
using IronPdf;
using System.IO; // For MemoryStream
using System.Threading.Tasks;
using System.Collections.Generic; // For List operations
using System.Linq; // For LINQ transformationsusing IronPdf;
using System.IO; // For MemoryStream
using System.Threading.Tasks;
using System.Collections.Generic; // For List operations
using System.Linq; // For LINQ transformationsImports IronPdf
Imports System.IO ' For MemoryStream
Imports System.Threading.Tasks
Imports System.Collections.Generic ' For List operations
Imports System.Linq ' For LINQ transformationsÜretim sunucusu ortamları için, tam özelliklere şifre kısıtlaması olmadan erişmek amacıyla lisans anahtarınızı uygulayın:
IronPdf.License.LicenseKey = "YOUR-LICENSE-KEY";IronPdf.License.LicenseKey = "YOUR-LICENSE-KEY";IronPdf.License.LicenseKey = "YOUR-LICENSE-KEY"IronPDF, Windows, Linux, macOS ve Docker konteynerlerini destekler; bu da onu ASP.NET Core ve bulut yerel uygulamaları için ideal hale getirir. Kütüphanenin yerel ve uzak motor mimarisi, Windows sunuculardan Linux konteynerlerine kadar çeşitli dağıtım senaryoları için esneklik sağlar.
Konteyner dağıtım gereksinimleri nelerdir?
IronPDF, dış bağımlılıklar olmadan Docker konteynerlerinde doğal olarak çalışır. Kütüphane, Chrome kurulumlarına veya kapsayıcı görüntülerinizde karmaşık yazı tipi yapılandırmalarına gerek bırakmayarak tüm gerekli bileşenleri içerir. Kap kapsayıcı ortamlarda en iyi performansı elde etmek için IronPDF çalışma zamanı klasörünü yapılandırın ve uygun kaynak izleme uygulayın. AWS Lambda veya Azure Functions ortamına dağıtım yaparken, kütüphane platforma özgü optimizasyonları otomatik olarak işler.
IronPDF, platformlar arası uyumluluğu nasıl ele alır?
Kütüphane, platforma özgü işlemleri soyutlayan ve platforma özgü kod gerektirmeden Windows Server, Linux dağıtımları ve konteyner ortamları arasında tutarlı davranış sağlayan bağımsız bir mimari kullanır. Chrome rendering engine, platformlar arasında pikselle mükemmel tutarlılık sağlarken, IronPdfEngine Docker container ise kaynak yoğun işlemler için uzaktan işlem yapılabilmesini mümkün kılıyor.

IronPDF ile C#'da İki PDF Bayt Dizisini Nasıl Birleştirilir?
var PDF = PdfDocument.Merge(
PdfDocument.FromBytes(pdfBytes1),
PdfDocument.FromBytes(pdfBytes2));var PDF = PdfDocument.Merge(
PdfDocument.FromBytes(pdfBytes1),
PdfDocument.FromBytes(pdfBytes2));Dim PDF = PdfDocument.Merge( _
PdfDocument.FromBytes(pdfBytes1), _
PdfDocument.FromBytes(pdfBytes2))İki PDF dosyasını bayt dizisi verilerinden birleştirmek için temel kod örneği aşağıdadır:
public byte[] MergePdfByteArrays(byte[] firstPdf, byte[] secondPdf)
{
// Load the first PDF file from byte array
var pdf1 = new PdfDocument(firstPdf);
// Load the second PDF file from byte array
var pdf2 = new PdfDocument(secondPdf);
// Merge PDF documents into one PDF
var mergedPdf = PdfDocument.Merge(pdf1, pdf2);
// Return the combined PDF as byte array
return mergedPdf.BinaryData;
}public byte[] MergePdfByteArrays(byte[] firstPdf, byte[] secondPdf)
{
// Load the first PDF file from byte array
var pdf1 = new PdfDocument(firstPdf);
// Load the second PDF file from byte array
var pdf2 = new PdfDocument(secondPdf);
// Merge PDF documents into one PDF
var mergedPdf = PdfDocument.Merge(pdf1, pdf2);
// Return the combined PDF as byte array
return mergedPdf.BinaryData;
}Public Function MergePdfByteArrays(firstPdf As Byte(), secondPdf As Byte()) As Byte()
' Load the first PDF file from byte array
Dim pdf1 = New PdfDocument(firstPdf)
' Load the second PDF file from byte array
Dim pdf2 = New PdfDocument(secondPdf)
' Merge PDF documents into one PDF
Dim mergedPdf = PdfDocument.Merge(pdf1, pdf2)
' Return the combined PDF as byte array
Return mergedPdf.BinaryData
End FunctionBu yöntem, giriş parametreleri olarak iki PDF byte dizisi kabul eder. PdfDocument.FromBytes() yöntemi her bayt dizisini PdfDocument nesnelerine yükler. Merge() yöntemi her iki PDF belgesini tek bir yeni PDF içine birleştirir, tüm içeriği, biçimlendirmeyi ve form alanlarını korur. Daha karmaşık senaryolar için, birleştirme davranışını kontrol etmek amacıyla ileri düzey işleme seçeneklerini kullanabilirsiniz.
Birleştirilmiş çıktı nasıl görünüyor?
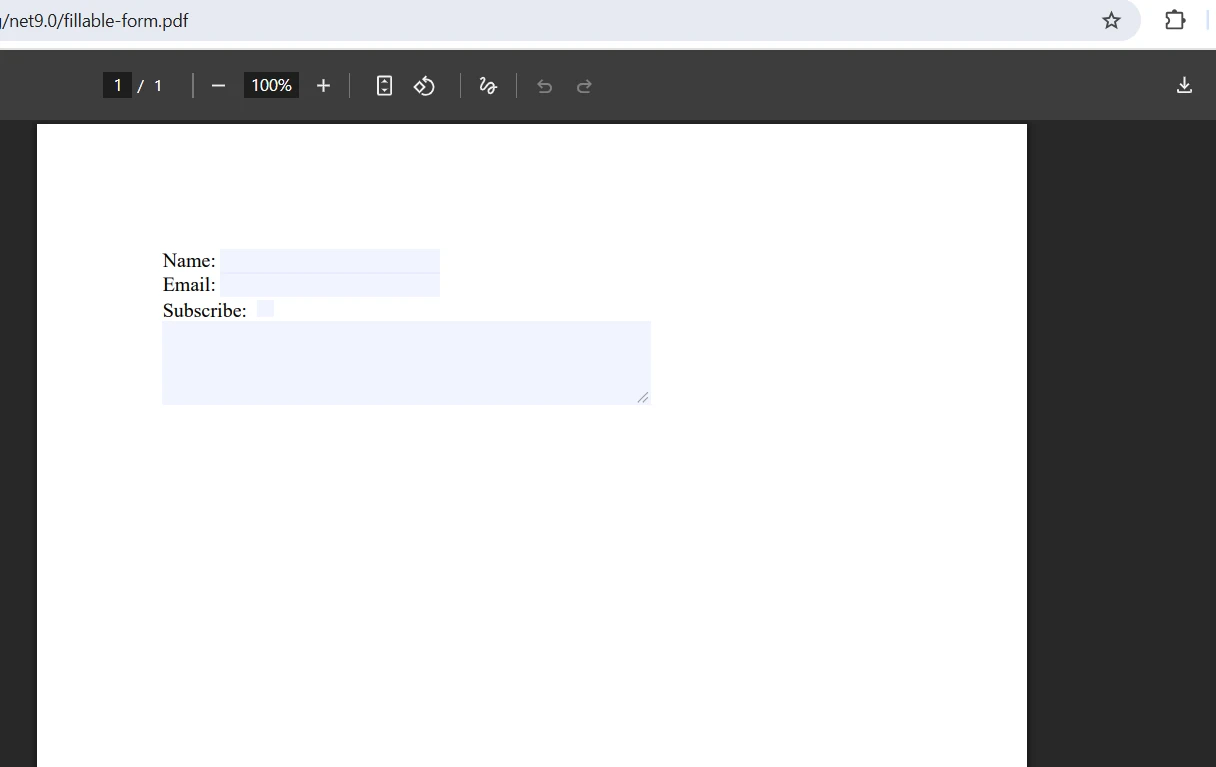
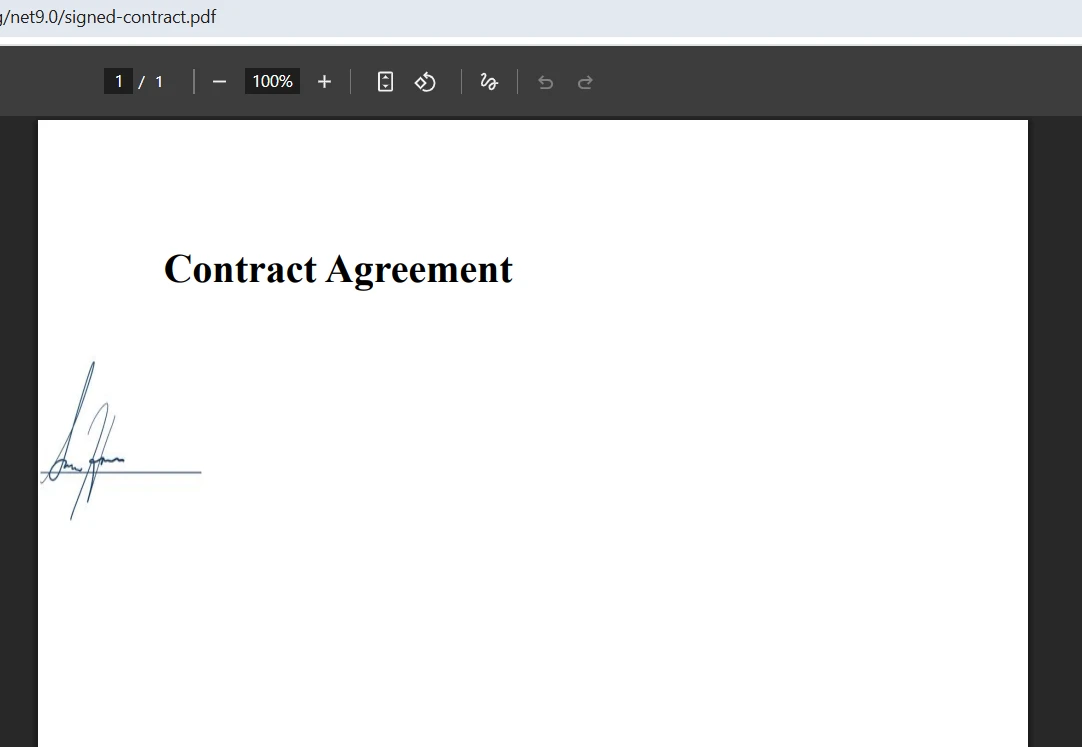
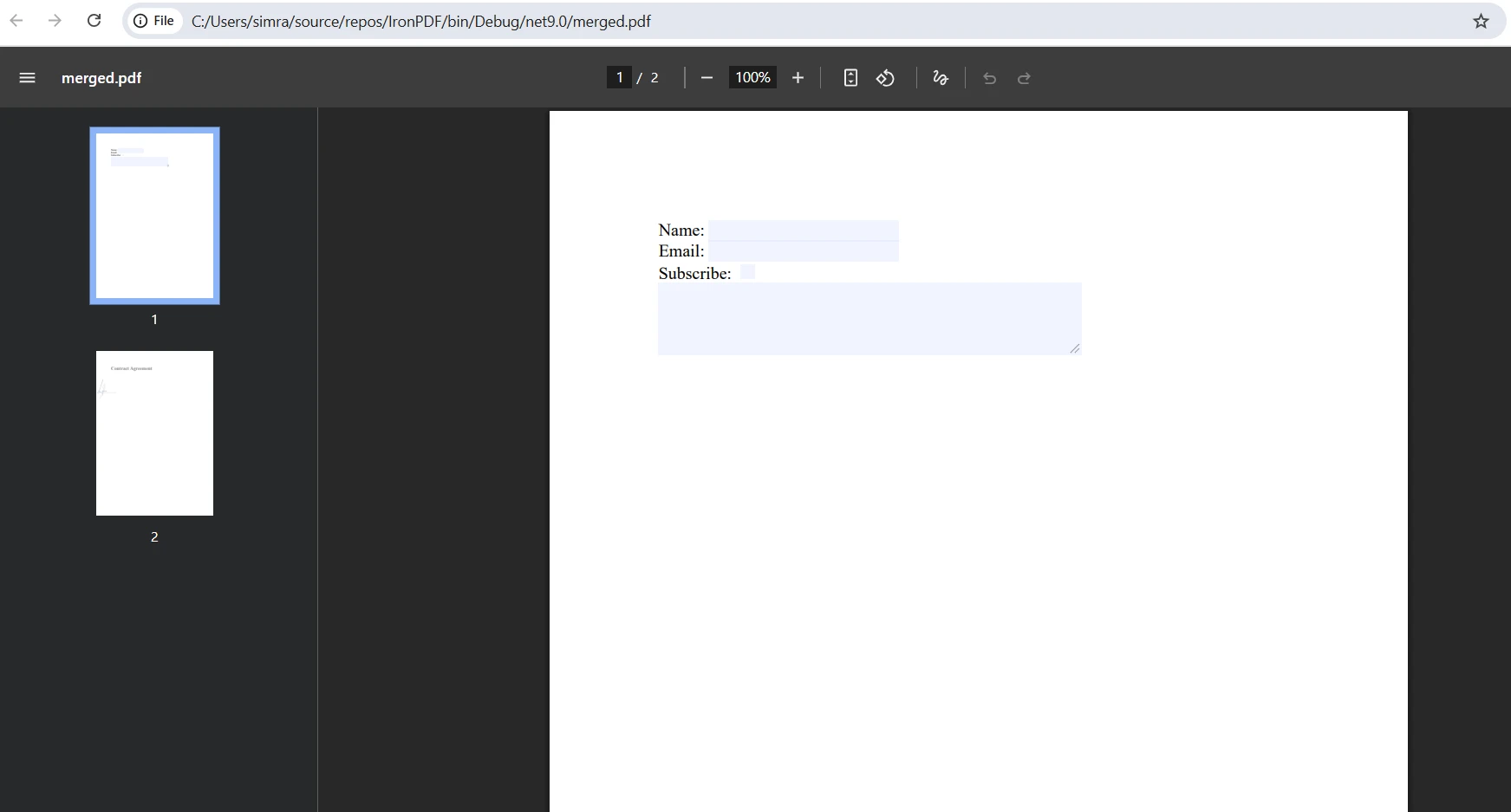
Birleştirme sırasında form alanı çakışmaları nasıl yönetilir?
Daha fazla kontrol için yeni bir MemoryStream ile doğrudan çalışabilirsiniz:
public byte[] MergePdfsWithStream(byte[] src1, byte[] src2)
{
using (var stream = new MemoryStream())
{
var pdf1 = new PdfDocument(src1);
var pdf2 = new PdfDocument(src2);
var combined = PdfDocument.Merge(pdf1, pdf2);
// Handle form field name conflicts
if (combined.Form != null && combined.Form.Fields.Count > 0)
{
// Access and modify form fields if needed
foreach (var field in combined.Form.Fields)
{
// Process form fields
Console.WriteLine($"Field: {field.Name}");
}
}
return combined.BinaryData;
}
}public byte[] MergePdfsWithStream(byte[] src1, byte[] src2)
{
using (var stream = new MemoryStream())
{
var pdf1 = new PdfDocument(src1);
var pdf2 = new PdfDocument(src2);
var combined = PdfDocument.Merge(pdf1, pdf2);
// Handle form field name conflicts
if (combined.Form != null && combined.Form.Fields.Count > 0)
{
// Access and modify form fields if needed
foreach (var field in combined.Form.Fields)
{
// Process form fields
Console.WriteLine($"Field: {field.Name}");
}
}
return combined.BinaryData;
}
}Imports System
Imports System.IO
Public Function MergePdfsWithStream(src1 As Byte(), src2 As Byte()) As Byte()
Using stream As New MemoryStream()
Dim pdf1 As New PdfDocument(src1)
Dim pdf2 As New PdfDocument(src2)
Dim combined As PdfDocument = PdfDocument.Merge(pdf1, pdf2)
' Handle form field name conflicts
If combined.Form IsNot Nothing AndAlso combined.Form.Fields.Count > 0 Then
' Access and modify form fields if needed
For Each field In combined.Form.Fields
' Process form fields
Console.WriteLine($"Field: {field.Name}")
Next
End If
Return combined.BinaryData
End Using
End FunctionHer iki PDF dosyası da aynı ada sahip form alanları içeriyorsa, IronPDF isim çakışmalarını otomatik olarak alt çizgi ekleyerek çözer. Doldurulabilir PDF formları ile çalışırken, birleştirilmiş belgeyi kaydetmeden önce form alanlarına programlı olarak erişebilir ve bunları değiştirebilirsiniz. PDF DOM nesne modeli, form elemanları üzerinde tam kontrol sağlar. Sonunda, BinaryData özelliği birleştirilmiş PDF'yi bayt dizi formatında yeni bir belge olarak döndürür. Sonucu diğer yöntemlere geçirmek için, bu byte dizisini basitçe geri döndürün - diskete kaydetmenize gerek yoktur, aksi belirtilmedikçe.
Daha İyi Performans İçin Async Birleştirmeyi Nasıl Uygularsınız?
Büyük PDF dosyalarını yöneten veya sunucunuzda yüksek istek hacimlerini işleyen uygulamalar için async işlemler, thread bloke olmasını önler. Aşağıdaki kod, PDF belgelerini asenkron olarak birleştirmeyi gösterir:
public async Task<byte[]> MergePdfByteArraysAsync(byte[] firstPdf, byte[] secondPdf)
{
return await Task.Run(() =>
{
var pdf1 = new PdfDocument(firstPdf);
var pdf2 = new PdfDocument(secondPdf);
var PDF = PdfDocument.Merge(pdf1, pdf2);
return PDF.BinaryData;
});
}public async Task<byte[]> MergePdfByteArraysAsync(byte[] firstPdf, byte[] secondPdf)
{
return await Task.Run(() =>
{
var pdf1 = new PdfDocument(firstPdf);
var pdf2 = new PdfDocument(secondPdf);
var PDF = PdfDocument.Merge(pdf1, pdf2);
return PDF.BinaryData;
});
}Imports System.Threading.Tasks
Public Class PdfMerger
Public Async Function MergePdfByteArraysAsync(firstPdf As Byte(), secondPdf As Byte()) As Task(Of Byte())
Return Await Task.Run(Function()
Dim pdf1 = New PdfDocument(firstPdf)
Dim pdf2 = New PdfDocument(secondPdf)
Dim PDF = PdfDocument.Merge(pdf1, pdf2)
Return PDF.BinaryData
End Function)
End Function
End ClassBu async uygulaması PDF birleştirme işlemini Task.Run() içinde sarmalayarak arka planda yürütülmesine izin verir. Bu yaklaşım, birden fazla PDF belgesini işlerken duyarlı istek yönetimini sürdürmek istediğiniz ASP.NET web uygulamalarında özellikle değerlidir. Yöntem, ana ipi tıkamadan sonuç beklemek için çağrı yapıcılara Task<byte[]> döndürür. Yukarıdaki kod, büyük PDF dosya işlemleri ile çalışırken verimli bellek yönetimini sağlar. Daha ileri düzey senaryolar için, IronPDF'de async ve multithreading kalıplarını keşfedin.
Ne zaman asenkron PDF işlemlerini kullanmalısınız?
10MB'den büyük PDF'lerle çalışırken, birden fazla eşzamanlı isteği işlerken veya async web API'ları ile entegre ederken async birleştirme kullanın. Bu, yoğun trafik senaryolarında iş parçacığı havuzunun tükenmesini önler. Harici kaynakları içeren işlemler için işleme gecikmeleri ve zaman aşımı uygulamayı düşünün. Mikro servis mimarilerinde, asenkron işlemler daha iyi kaynak kullanımı sağlar ve tepe yüklemeler sırasında ardışık hataların önüne geçer.
Performans etkileri nelerdir?
Async işlemler, yüksek eşzamanlılık senaryolarında bellek yükünü %40'a kadar azaltır. CPU ve bellek sınırlarının kesin bir şekilde uygulandığı kaplanmış ortamlarda daha iyi kaynak kullanımını sağlarlar. Paralel PDF oluşturma teknikleri ile birleştirildiğinde, önemli performans iyileştirmeleri elde edebilirsiniz. PDF işleme hattınızdaki darboğazları belirlemek için özelleştirilmiş kayıtlarla performansı izleyin.
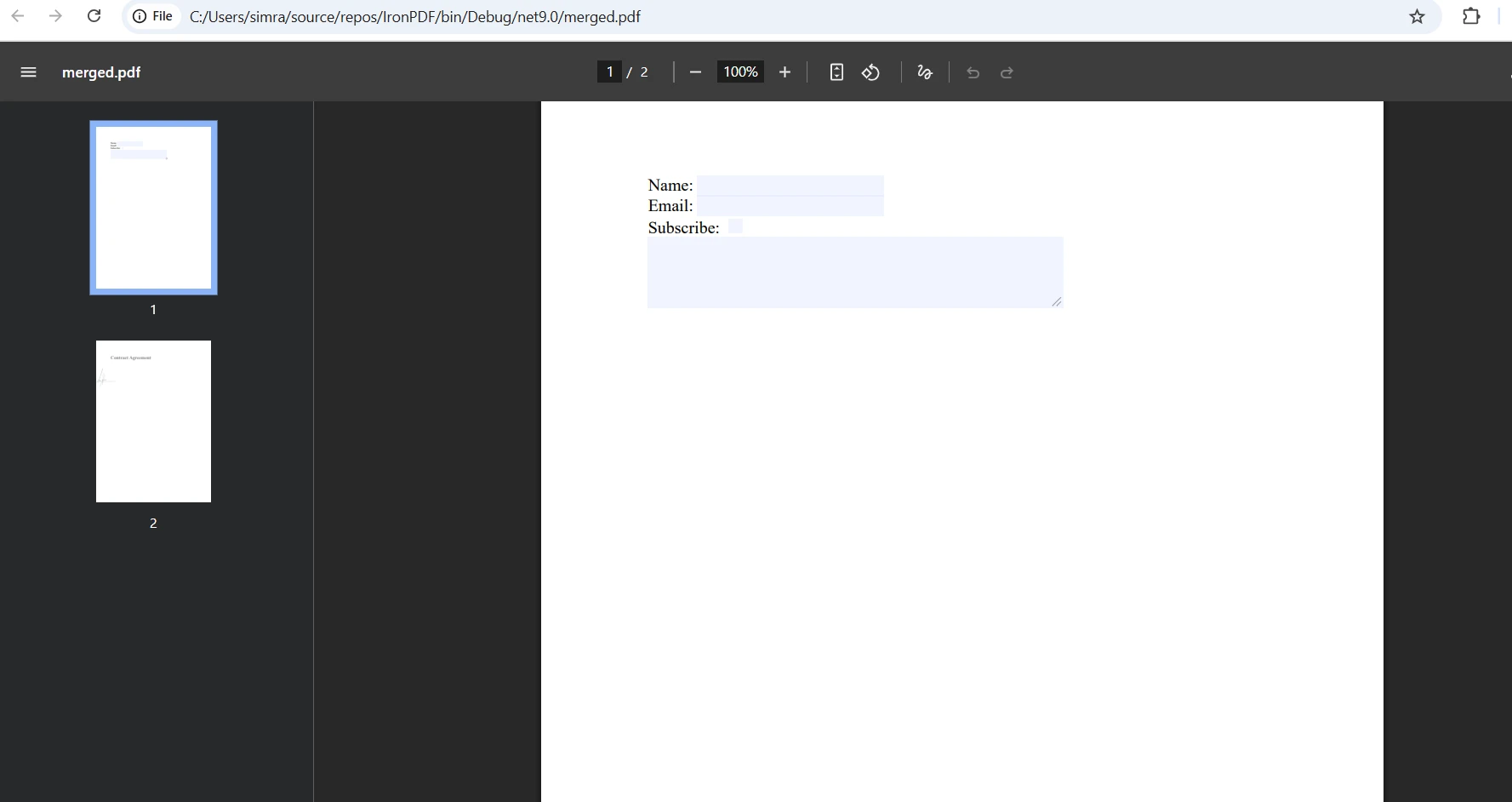
Birden Fazla PDF Dosyasını Etkili Bir Şekilde Nasıl Birleştirilir?
Birden fazla PDF dosyası ile çalışırken, toplu işlem için List kullanın. Bu yaklaşım, herhangi bir sayıda PDF belgesini tek bir PDF olarak birleştirmenizi sağlar:
public byte[] MergeMultiplePdfByteArrays(List<byte[]> pdfByteArrays)
{
if (pdfByteArrays == null || pdfByteArrays.Count == 0)
return null;
// Convert all byte arrays to PdfDocument objects
var pdfDocuments = pdfByteArrays
.Select(bytes => new PdfDocument(bytes))
.ToList();
// Merge all PDFs in one operation
var PDF = PdfDocument.Merge(pdfDocuments);
// Clean up resources
foreach (var pdfDoc in pdfDocuments)
{
pdfDoc.Dispose();
}
return PDF.BinaryData;
}public byte[] MergeMultiplePdfByteArrays(List<byte[]> pdfByteArrays)
{
if (pdfByteArrays == null || pdfByteArrays.Count == 0)
return null;
// Convert all byte arrays to PdfDocument objects
var pdfDocuments = pdfByteArrays
.Select(bytes => new PdfDocument(bytes))
.ToList();
// Merge all PDFs in one operation
var PDF = PdfDocument.Merge(pdfDocuments);
// Clean up resources
foreach (var pdfDoc in pdfDocuments)
{
pdfDoc.Dispose();
}
return PDF.BinaryData;
}Imports System.Collections.Generic
Imports System.Linq
Public Function MergeMultiplePdfByteArrays(pdfByteArrays As List(Of Byte())) As Byte()
If pdfByteArrays Is Nothing OrElse pdfByteArrays.Count = 0 Then
Return Nothing
End If
' Convert all byte arrays to PdfDocument objects
Dim pdfDocuments = pdfByteArrays _
.Select(Function(bytes) New PdfDocument(bytes)) _
.ToList()
' Merge all PDFs in one operation
Dim PDF = PdfDocument.Merge(pdfDocuments)
' Clean up resources
For Each pdfDoc In pdfDocuments
pdfDoc.Dispose()
Next
Return PDF.BinaryData
End FunctionBu yöntem, herhangi bir sayıda PDF bayt dizisini verimli bir şekilde işler. Öncelikle, listenin veri içerdiğinden emin olmak için girişi doğrular. LINQ'in Select() yöntemi kullanılarak, her bayt dizisini PdfDocument nesnelerine dönüştürür. Merge() yöntemi bir PDFDocument nesneleri Listesi alır ve bunların hepsini tek bir işlemde birleştirerek yeni bir belge oluşturur. Kaynak temizliği önemlidir - PDF birleştirme işleminden sonra bireysel PdfDocument nesnelerini ortadan kaldırmak, belleki ve kaynakları etkin bir şekilde yönetmeye yardımcı olur, özellikle çok sayıda veya büyük PDF dosyalarını işlerken. Oluşan bayt dizisinin uzunluğu, tüm kaynak PDF belgelerindeki sayfalara bağlıdır. Belirli sayfaları çok sayfalı PDF'leri ayırabilirsiniz veya kopyalayabilirsiniz ve daha ayrıntılı kontrol sağlayabilirsiniz.
Hangi bellek optimizasyon tekniklerini uygulamalısınız?
Öngörülebilir bellek kullanımını sürdürmek için 10-20 belgeyi toplu olarak işle. Daha büyük işlemler için, yapılandırılabilir eşzamanlılık limitleri ile kuyruk tabanlı bir yaklaşım uygulayın. PDF sıkıştırma kullanarak işlem sırasında bellek kullanımını azaltın. Büyük çıktı dosyaları ile çalışırken, sonuçları bellekte tutmak yerine doğrudan Azure Blob Storage'a akış yapmayı düşünün.
Toplu işlemler sırasında kaynak kullanımını nasıl izleyebilirim?
Aktif birleştirme işlemlerini, bellek tüketimini ve işlem kuyruğu derinliğini izleyen sağlık kontrolü uç noktaları uygulayın. Bu, Kubernetes hazır olma problarının pod ölçeklendirmeyi uygun şekilde yönetmesini sağlar. IronPDF günlük kaydını yapılandırarak performans metriklerini yakalayın ve bellek sızıntılarını belirleyin. Toplu işlemler sırasında bellek tahsis örüntülerini izlemek için bellek akışı API'sini kullanın.
Üretim Kullanımı İçin En İyi Uygulamalar Nelerdir?
Bozuk veya şifre korumalı PDF dosyalarından gelebilecek potansiyel istisnaları ele almak için her zaman PDF işlemlerini try-catch bloklarında sarın. Bellek sızıntılarını önlemek için using deyimlerini kullanın veya açıkça PdfDocument nesnelerini ortadan kaldırın. Büyük ölçekli işlemler için, tüm belgeleri aynı anda belleğe yüklemek yerine sayfalama veya akış yaklaşımlarını uygulamayı düşünün.
public byte[] SafeMergePdfByteArrays(byte[] firstPdf, byte[] secondPdf)
{
try
{
// Validate input PDFs
if (firstPdf == null || firstPdf.Length == 0)
throw new ArgumentException("First PDF is empty");
if (secondPdf == null || secondPdf.Length == 0)
throw new ArgumentException("Second PDF is empty");
using (var pdf1 = new PdfDocument(firstPdf))
using (var pdf2 = new PdfDocument(secondPdf))
{
// Check for password protection
if (pdf1.IsPasswordProtected || pdf2.IsPasswordProtected)
throw new InvalidOperationException("Password-protected PDFs require authentication");
var mergedPdf = PdfDocument.Merge(pdf1, pdf2);
// Apply security settings if needed
mergedPdf.SecuritySettings.AllowUserPrinting = true;
mergedPdf.SecuritySettings.AllowUserCopyPasteContent = false;
return mergedPdf.BinaryData;
}
}
catch (Exception ex)
{
// Log error details for debugging
Console.WriteLine($"PDF merge failed: {ex.Message}");
throw;
}
}public byte[] SafeMergePdfByteArrays(byte[] firstPdf, byte[] secondPdf)
{
try
{
// Validate input PDFs
if (firstPdf == null || firstPdf.Length == 0)
throw new ArgumentException("First PDF is empty");
if (secondPdf == null || secondPdf.Length == 0)
throw new ArgumentException("Second PDF is empty");
using (var pdf1 = new PdfDocument(firstPdf))
using (var pdf2 = new PdfDocument(secondPdf))
{
// Check for password protection
if (pdf1.IsPasswordProtected || pdf2.IsPasswordProtected)
throw new InvalidOperationException("Password-protected PDFs require authentication");
var mergedPdf = PdfDocument.Merge(pdf1, pdf2);
// Apply security settings if needed
mergedPdf.SecuritySettings.AllowUserPrinting = true;
mergedPdf.SecuritySettings.AllowUserCopyPasteContent = false;
return mergedPdf.BinaryData;
}
}
catch (Exception ex)
{
// Log error details for debugging
Console.WriteLine($"PDF merge failed: {ex.Message}");
throw;
}
}Imports System
Public Function SafeMergePdfByteArrays(firstPdf As Byte(), secondPdf As Byte()) As Byte()
Try
' Validate input PDFs
If firstPdf Is Nothing OrElse firstPdf.Length = 0 Then
Throw New ArgumentException("First PDF is empty")
End If
If secondPdf Is Nothing OrElse secondPdf.Length = 0 Then
Throw New ArgumentException("Second PDF is empty")
End If
Using pdf1 As New PdfDocument(firstPdf)
Using pdf2 As New PdfDocument(secondPdf)
' Check for password protection
If pdf1.IsPasswordProtected OrElse pdf2.IsPasswordProtected Then
Throw New InvalidOperationException("Password-protected PDFs require authentication")
End If
Dim mergedPdf = PdfDocument.Merge(pdf1, pdf2)
' Apply security settings if needed
mergedPdf.SecuritySettings.AllowUserPrinting = True
mergedPdf.SecuritySettings.AllowUserCopyPasteContent = False
Return mergedPdf.BinaryData
End Using
End Using
Catch ex As Exception
' Log error details for debugging
Console.WriteLine($"PDF merge failed: {ex.Message}")
Throw
End Try
End FunctionBirden fazla PDF belgesinden seçilen sayfalarla çalışırken, ayrıca birleştirmeden önce belirli PdfPage örneklerini çıkarabilirsiniz. IronPDF'nin kapsamlı hata yönetimi, hem test hem de üretim ortamlarında sağlam üretim uygulamaları sağlar. Diğer PDF kütüphanelerine aşina iseniz, IronPDF'nin API'sini projenize ithal etmek ve kullanmak için özellikle sezgisel bulacaksınız. Güvenilmeyen girdi kaynakları için PDF temizleme ve belge kimlik doğrulaması için dijital imzalar uygulamayı düşünün.
Konteynerleştirilmiş ortamlarda doğru hata yönetimi nasıl uygulanır?
Dağıtılmış sistemler arasında PDF işlemlerini izlemek için korelasyon kimlikleri ile yapılandırılmış günlük kaydı yapılandırın. Çoğaltma hatalarını önlemek için dış PDF kaynakları için devre kesiciler uygulayın. Merkezileştirilmiş hata takibi için Azure günlük dosyalarını veya AWS günlük dosyalarını kullanın. Yerel istisnalarla uğraşırken, hata ayıklama için uygun hata bağlamının kaydedildiğinden emin olun.
PDF işleme hizmetleri için hangi dağıtım kalıpları en iyi sonuç verir?
PDF işleme, ayrılmış kaynak limitlerine sahip ayrı mikro hizmetler olarak dağıtın. En iyi performans için bellek kullanımına dayalı yatay pod otomatik ölçeklendirmeyi kullanın, CPU yerine. Ayarları yapılabilir eşzamanlılık ile toplu işlemler için sıraya dayalı işlemeyi uygulayın. Daha küçük konteyner imaj boyutları için IronPdf.Slim paketini kullanmayı düşünün. Tutarlılık için hizmet seviyesinde özel kağıt boyutları ve özel kenar boşlukları yapılandırın.
Neden Üretim PDF İşlemleri için IronPDF'yi Seçmelisiniz?
IronPDF, C#'ta bayt dizilerinden PDF dosyalarını birleştirme gibi karmaşık bir görevi basitleştirir, PDF belge yapısının ayrıntılarını otomatik olarak ele alan temiz bir API sağlayarak. Belge yönetim sistemleri kuruyor, API yanıtlarını işliyor, eklerle birlikte dosya yüklemelerini yönetiyor veya veritabanı saklama ile çalışıyorsanız, IronPDF'nin birleştirme yetenekleri .NET uygulamalarınıza sorunsuz bir şekilde entegre olur.
Kütüphane, hem masaüstü hem de sunucu uygulamaları için ideal hale getiren asenkron işlemleri ve bellek açısından verimli işlemeyi destekler. Geçici dosyaları diske yazmadan PDF dosyalarını düzenleyebilir, dönüştürebilir ve kaydedebilirsiniz. Ek destek ve cevaplar için forumumuzu veya web sitemizi ziyaret edin. API referansı, kullanılabilir tüm metodlar ve özellikler için kapsamlı bir belge sağlar.
Uygulamanızda PDF birleştirmeyi uygulamaya hazır mısınız? Ücretsiz deneme ile başlayın ya da kapsamlı API belgelerini keşfedin ve IronPDF'nin HTML'den PDF'e dönüşüm, PDF form işlemesi ve dijital imzalar dahil olmak üzere tüm özellik setini keşfedin. Sitemiz, tüm System.IO akış işlemleri için tam referans belgeleri ve gelişmiş PDF işleme senaryoları için kapsamlı eğitim kılavuzları sağlar.
Sıkça Sorulan Sorular
C#'da iki PDF bayt dizisini nasıl birleştirebilirim?
IronPDF kullanarak C#'da iki PDF bayt dizisini birleştirebilirsiniz. Bu, diske kaydetmeye gerek olmadan bayt dizileri olarak depolanan birden fazla PDF dosyasını tek bir PDF belgede birleştirmeyi kolaylaştırır.
PDF bayt dizilerini birleştirirken IronPDF kullanmanın avantajları nelerdir?
IronPDF, PDF bayt dizilerini birleştirmenin kolay bir API sağlayarak süreci basitleştirir. Veritabanlarından veya web hizmetlerinden PDF alan uygulamalar için bellekte verimli bir şekilde PDF'leri işler.
IronPDF, PDF dosyalarını diske kaydetmeden birleştirebilir mi?
Evet, IronPDF, PDF dosyalarını diske kaydetmeden birleştirebilir. PDF dosyalarını doğrudan bayt dizilerinden işler, bu da onu bellek tabanlı işlemler için uygun hale getirir.
IronPDF, web hizmetlerinden alınan PDF dosyalarını birleştirebilir mi?
Kesinlikle. IronPDF, web hizmetlerinden gelen bayt dizileri olarak alınan PDF dosyalarını birleştirebilir, bu da uzaktaki PDF kaynaklarıyla sorunsuz bir entegrasyon sağlar.
C#'da PDF bayt dizilerini birleştirmenin yaygın bir uygulaması nedir?
Yaygın bir uygulama, bir C# uygulamasında işlemden önce veya görüntülemeden önce bir veritabanından alınan birden fazla PDF belgesini tek bir PDF dosyası haline getirmektir.
IronPDF, PDF'leri bellekte işlemeyi destekler mi?
Evet, IronPDF, bellekte PDF işlemeyi destekler, bu da ara disk depolaması gerektirmeyen hızlı PDF dosyası manipülasyonunu gerektiren uygulamalar için gereklidir.
IronPDF, veri tabanlarından PDF birleştirmeyi nasıl ele alır?
IronPDF, veri tabanlarından PDF birleştirmeyi, PDF bayt dizileri üzerinde doğrudan çalışmanıza olanak tanıyarak geçici dosya depolama gereksinimini ortadan kaldırarak ele alır.
IronPDF, birden fazla PDF dosyasını tek bir dosya halinde birleştirebilir mi?
Evet, IronPDF, bayt dizilerini birleştirerek birden fazla PDF dosyasını tek bir dosya haline getirebilir, birleşik PDF belgeleri oluşturmak için sık kullanılan bir yöntem sunar.











