
Como criar um visualizador de PDF em Blazor usando o IronPDF
Para mesclar dois arrays de bytes PDF em C#, use o método PdfDocument.Merge() do IronPDF, que carrega arrays de bytes em objetos PdfDocument e os combina enquanto preserva a estrutura, formatação e campos de formulário - sem necessidade de acesso ao sistema de arquivos.
Trabalhar com arquivos PDF na memória é um requisito comum em aplicações .NET modernas. Seja ao receber vários arquivos PDF de APIs da web, recuperá-los de colunas BLOB de um banco de dados ou processar arquivos enviados do seu servidor, muitas vezes você precisa combinar várias matrizes de bytes de PDF em um único documento PDF sem alterar o sistema de arquivos. Neste artigo, exploraremos como o IronPDF torna a fusão de PDFs notavelmente simples com sua API intuitiva para mesclar PDFs programaticamente .
Por que não é possível simplesmente concatenar matrizes de bytes de um arquivo PDF?
Ao contrário dos arquivos de texto, os documentos PDF possuem uma estrutura interna complexa com tabelas de referências cruzadas, definições de objetos e requisitos de formatação específicos. A simples concatenação de dois arquivos PDF como arrays de bytes corromperia a estrutura do documento, resultando em um arquivo PDF ilegível. É por isso que bibliotecas especializadas em PDF, como o IronPDF, são essenciais: elas entendem a especificação do PDF e mesclam arquivos PDF corretamente, mantendo sua integridade. De acordo com discussões no fórum Stack Overflow , tentar concatenar diretamente arrays de bytes é um erro comum que desenvolvedores cometem ao tentar mesclar conteúdo de PDFs.
O que acontece quando você concatena bytes de um PDF diretamente?
Quando bytes de um PDF são concatenados sem a devida análise sintática, o arquivo resultante contém múltiplos cabeçalhos de PDF, tabelas de referência cruzada conflitantes e referências de objetos quebradas. Os leitores de PDF não conseguem interpretar essa estrutura malformada, o que leva a erros de corrupção ou documentos em branco. O formato PDF/A exige, em particular, o cumprimento rigoroso das normas estruturais, tornando a fusão adequada essencial para documentos de arquivo.
Por que as estruturas PDF exigem tratamento especial?
Os arquivos PDF contêm objetos interconectados, definições de fontes e árvores de páginas que devem ser cuidadosamente mesclados. Cada referência interna de um PDF precisa ser atualizada para apontar para os locais corretos no documento combinado, o que requer a compreensão da especificação do PDF. Gerenciar fontes e preservar metadados durante operações de mesclagem exige recursos sofisticados de análise sintática que somente bibliotecas PDF dedicadas oferecem.

Como configurar o IronPDF para mesclar PDFs?
Instale o IronPDF através do Gerenciador de Pacotes NuGet em seu projeto .NET :
Install-Package IronPdf
ou arraste e solte uma imagem aqui.
Adicione as instruções using necessárias para importar a biblioteca:
using IronPdf;
using System.IO; // For MemoryStream
using System.Threading.Tasks;
using System.Collections.Generic; // For List operations
using System.Linq; // For LINQ transformationsusing IronPdf;
using System.IO; // For MemoryStream
using System.Threading.Tasks;
using System.Collections.Generic; // For List operations
using System.Linq; // For LINQ transformationsImports IronPdf
Imports System.IO ' For MemoryStream
Imports System.Threading.Tasks
Imports System.Collections.Generic ' For List operations
Imports System.Linq ' For LINQ transformationsPara ambientes de servidor de produção, utilize sua chave de licença para acessar todos os recursos sem restrições de senha:
IronPdf.License.LicenseKey = "YOUR-LICENSE-KEY";IronPdf.License.LicenseKey = "YOUR-LICENSE-KEY";IronPdf.License.LicenseKey = "YOUR-LICENSE-KEY"O IronPDF é compatível com Windows, Linux, macOS e contêineres Docker, sendo ideal para aplicações ASP.NET Core e nativas da nuvem. A arquitetura de mecanismo nativo versus remoto da biblioteca oferece flexibilidade para vários cenários de implantação, desde servidores Windows até contêineres Linux .
Quais são os requisitos para a implantação de contêineres?
O IronPDF funciona nativamente em contêineres Docker sem dependências externas. A biblioteca inclui todos os componentes necessários, eliminando a necessidade de instalações do Chrome ou configurações complexas de fontes em suas imagens de contêiner. Para obter o melhor desempenho em ambientes conteinerizados, configure a pasta de tempo de execução do IronPDF e implemente um monitoramento de recursos adequado. Ao implantar no AWS Lambda ou no Azure Functions , a biblioteca lida automaticamente com as otimizações específicas da plataforma.
Como o IronPDF lida com a compatibilidade entre plataformas?
A biblioteca utiliza uma arquitetura autocontida que abstrai operações específicas da plataforma, garantindo um comportamento consistente em todo o Windows Server, distribuições Linux e ambientes conteinerizados, sem exigir código específico da plataforma. O mecanismo de renderização do Chrome oferece consistência perfeita em todos os pixels em todas as plataformas, enquanto o contêiner Docker do IronPDFEngine permite o processamento remoto para operações que exigem muitos recursos.

Como Mesclar Dois Arrays de Bytes de PDF em C# com IronPDF?
var PDF = PdfDocument.Merge(
PdfDocument.FromBytes(pdfBytes1),
PdfDocument.FromBytes(pdfBytes2));var PDF = PdfDocument.Merge(
PdfDocument.FromBytes(pdfBytes1),
PdfDocument.FromBytes(pdfBytes2));Dim PDF = PdfDocument.Merge( _
PdfDocument.FromBytes(pdfBytes1), _
PdfDocument.FromBytes(pdfBytes2))Aqui está um exemplo de código principal para mesclar dois arquivos PDF a partir de dados de matriz de bytes:
public byte[] MergePdfByteArrays(byte[] firstPdf, byte[] secondPdf)
{
// Load the first PDF file from byte array
var pdf1 = new PdfDocument(firstPdf);
// Load the second PDF file from byte array
var pdf2 = new PdfDocument(secondPdf);
// Merge PDF documents into one PDF
var mergedPdf = PdfDocument.Merge(pdf1, pdf2);
// Return the combined PDF as byte array
return mergedPdf.BinaryData;
}public byte[] MergePdfByteArrays(byte[] firstPdf, byte[] secondPdf)
{
// Load the first PDF file from byte array
var pdf1 = new PdfDocument(firstPdf);
// Load the second PDF file from byte array
var pdf2 = new PdfDocument(secondPdf);
// Merge PDF documents into one PDF
var mergedPdf = PdfDocument.Merge(pdf1, pdf2);
// Return the combined PDF as byte array
return mergedPdf.BinaryData;
}Public Function MergePdfByteArrays(firstPdf As Byte(), secondPdf As Byte()) As Byte()
' Load the first PDF file from byte array
Dim pdf1 = New PdfDocument(firstPdf)
' Load the second PDF file from byte array
Dim pdf2 = New PdfDocument(secondPdf)
' Merge PDF documents into one PDF
Dim mergedPdf = PdfDocument.Merge(pdf1, pdf2)
' Return the combined PDF as byte array
Return mergedPdf.BinaryData
End FunctionEste método aceita dois arrays de bytes de PDF como parâmetros de entrada. O método PdfDocument.FromBytes() carrega cada array de bytes em objetos PdfDocument. O método Merge() combina os dois documentos PDF em um único novo PDF, preservando todo o conteúdo, formatação e campos de formulário. Para cenários mais complexos, você pode usar opções avançadas de renderização para controlar o comportamento de mesclagem.
Qual é a aparência do resultado final após a fusão?
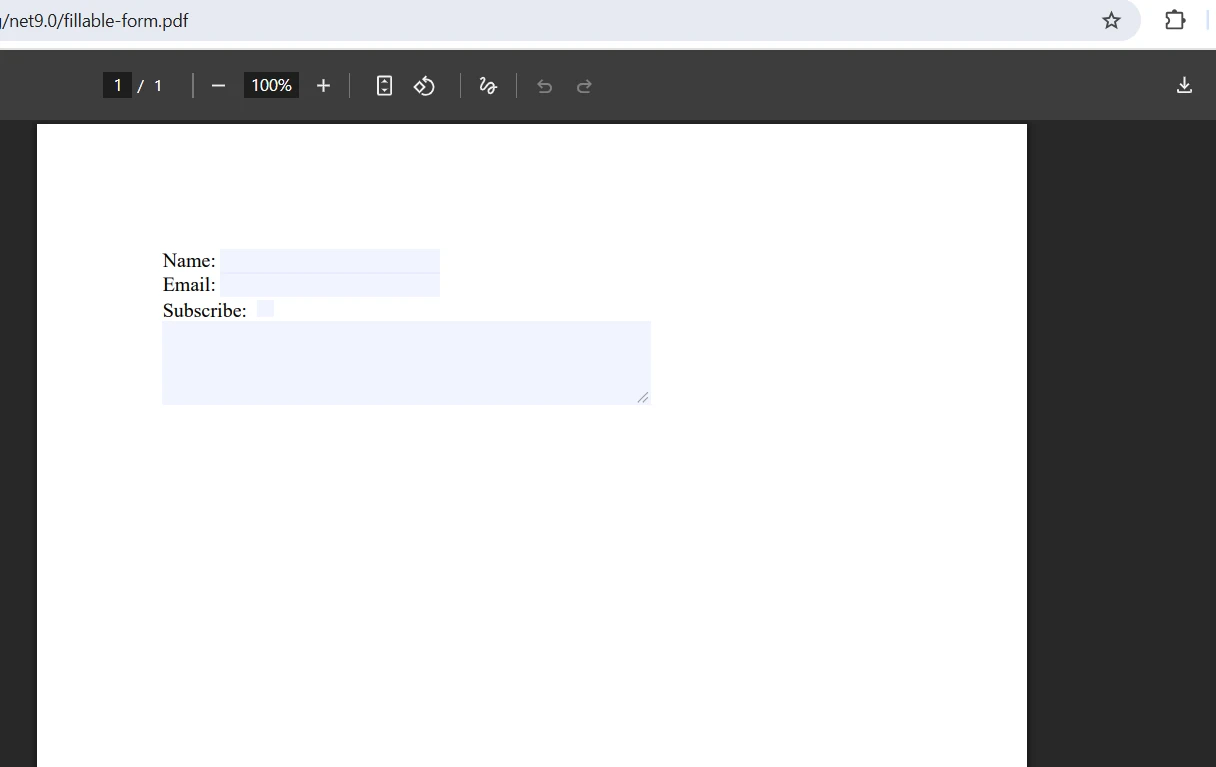
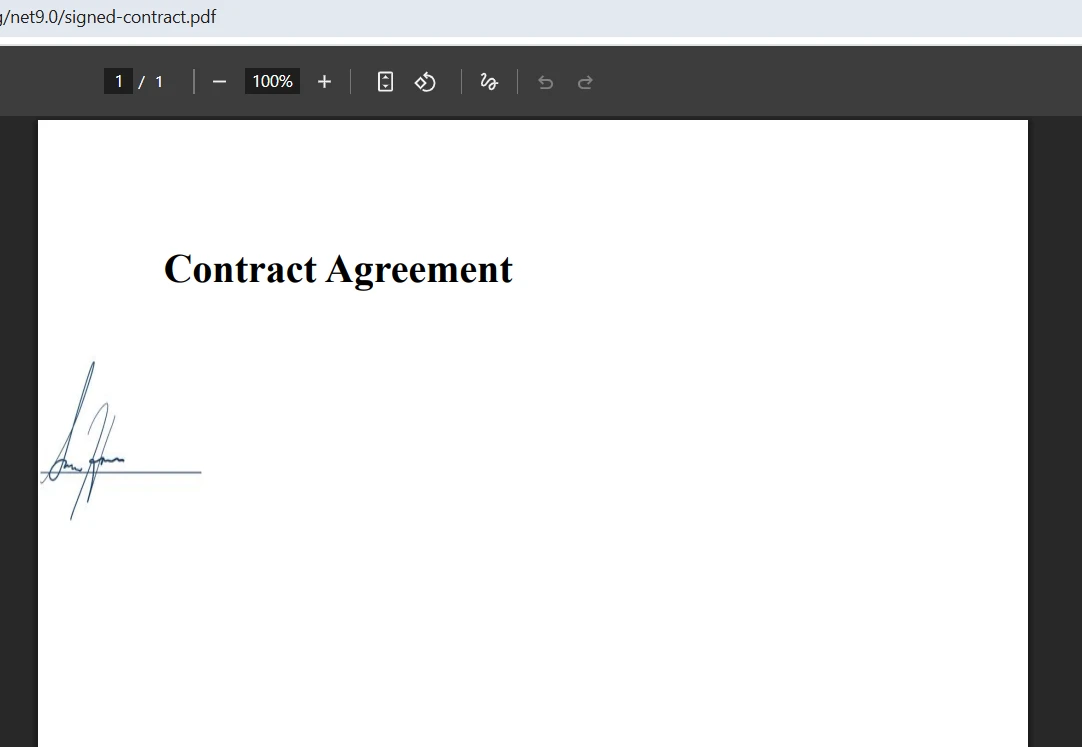
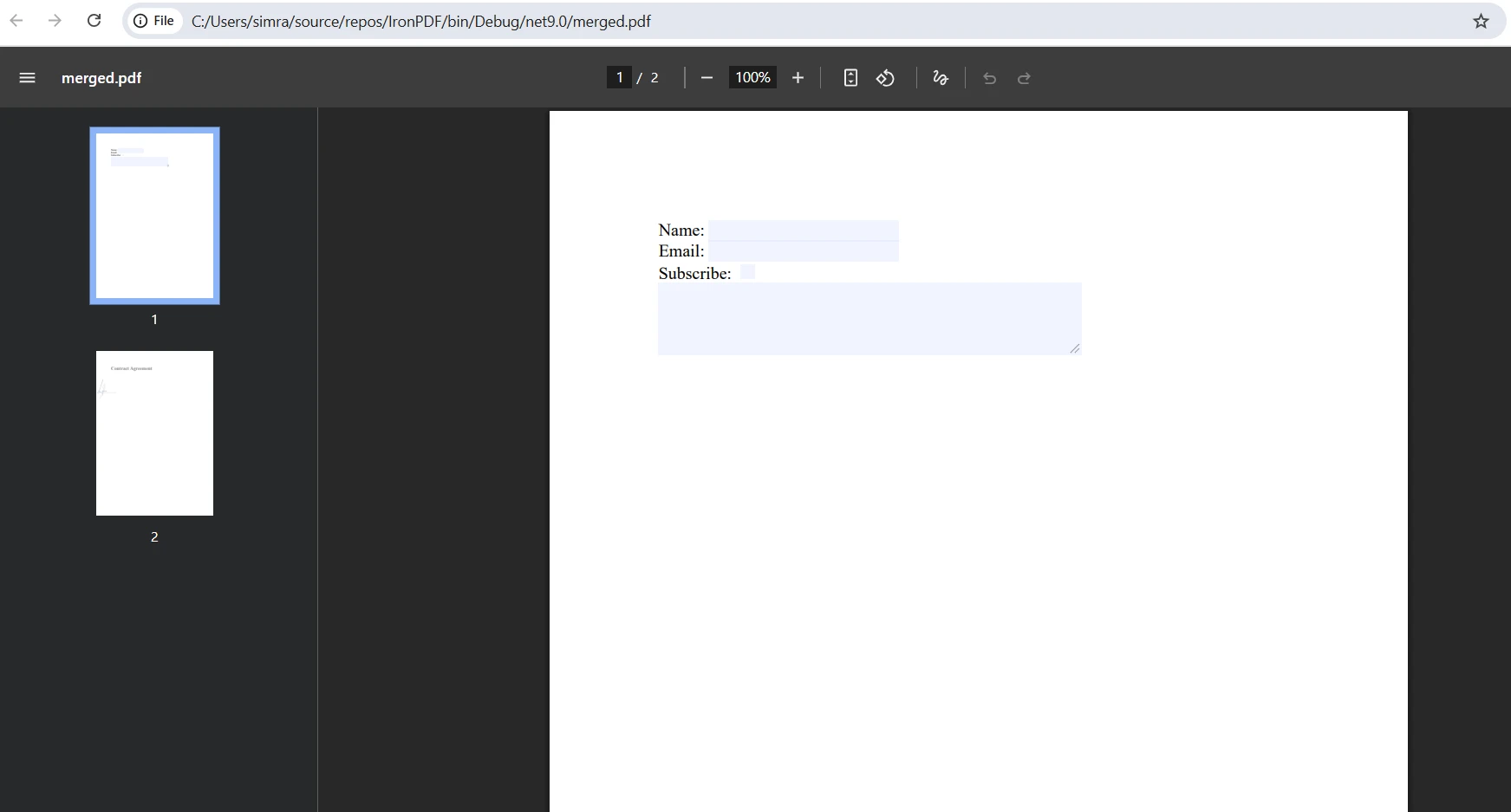
Como lidar com conflitos em campos de formulário durante a mesclagem?
Para mais controle, você também pode trabalhar diretamente com um novo MemoryStream:
public byte[] MergePdfsWithStream(byte[] src1, byte[] src2)
{
using (var stream = new MemoryStream())
{
var pdf1 = new PdfDocument(src1);
var pdf2 = new PdfDocument(src2);
var combined = PdfDocument.Merge(pdf1, pdf2);
// Handle form field name conflicts
if (combined.Form != null && combined.Form.Fields.Count > 0)
{
// Access and modify form fields if needed
foreach (var field in combined.Form.Fields)
{
// Process form fields
Console.WriteLine($"Field: {field.Name}");
}
}
return combined.BinaryData;
}
}public byte[] MergePdfsWithStream(byte[] src1, byte[] src2)
{
using (var stream = new MemoryStream())
{
var pdf1 = new PdfDocument(src1);
var pdf2 = new PdfDocument(src2);
var combined = PdfDocument.Merge(pdf1, pdf2);
// Handle form field name conflicts
if (combined.Form != null && combined.Form.Fields.Count > 0)
{
// Access and modify form fields if needed
foreach (var field in combined.Form.Fields)
{
// Process form fields
Console.WriteLine($"Field: {field.Name}");
}
}
return combined.BinaryData;
}
}Imports System
Imports System.IO
Public Function MergePdfsWithStream(src1 As Byte(), src2 As Byte()) As Byte()
Using stream As New MemoryStream()
Dim pdf1 As New PdfDocument(src1)
Dim pdf2 As New PdfDocument(src2)
Dim combined As PdfDocument = PdfDocument.Merge(pdf1, pdf2)
' Handle form field name conflicts
If combined.Form IsNot Nothing AndAlso combined.Form.Fields.Count > 0 Then
' Access and modify form fields if needed
For Each field In combined.Form.Fields
' Process form fields
Console.WriteLine($"Field: {field.Name}")
Next
End If
Return combined.BinaryData
End Using
End FunctionSe ambos os arquivos PDF contiverem campos de formulário com nomes idênticos, o IronPDF lida automaticamente com conflitos de nomenclatura adicionando sublinhados. Ao trabalhar com formulários PDF preenchíveis , você pode acessar e modificar os campos do formulário programaticamente antes de salvar o documento mesclado. O modelo de objeto DOM do PDF oferece controle total sobre os elementos do formulário. Finalmente, a propriedade BinaryData retorna o PDF combinado como um novo documento em formato de array de bytes. Para passar o resultado para outros métodos, basta retornar esse array de bytes - não é necessário salvar em disco, a menos que seja preciso.
Como implementar a mesclagem assíncrona para obter melhor desempenho?
Para aplicações que lidam com arquivos PDF grandes ou alto volume de requisições no seu servidor, as operações assíncronas evitam o bloqueio de threads. O código a seguir mostra como mesclar documentos PDF de forma assíncrona:
public async Task<byte[]> MergePdfByteArraysAsync(byte[] firstPdf, byte[] secondPdf)
{
return await Task.Run(() =>
{
var pdf1 = new PdfDocument(firstPdf);
var pdf2 = new PdfDocument(secondPdf);
var PDF = PdfDocument.Merge(pdf1, pdf2);
return PDF.BinaryData;
});
}public async Task<byte[]> MergePdfByteArraysAsync(byte[] firstPdf, byte[] secondPdf)
{
return await Task.Run(() =>
{
var pdf1 = new PdfDocument(firstPdf);
var pdf2 = new PdfDocument(secondPdf);
var PDF = PdfDocument.Merge(pdf1, pdf2);
return PDF.BinaryData;
});
}Imports System.Threading.Tasks
Public Class PdfMerger
Public Async Function MergePdfByteArraysAsync(firstPdf As Byte(), secondPdf As Byte()) As Task(Of Byte())
Return Await Task.Run(Function()
Dim pdf1 = New PdfDocument(firstPdf)
Dim pdf2 = New PdfDocument(secondPdf)
Dim PDF = PdfDocument.Merge(pdf1, pdf2)
Return PDF.BinaryData
End Function)
End Function
End ClassEsta implementação assíncrona envolve a operação de mesclagem de PDF em Task.Run(), permitindo que ela seja executada em um thread em segundo plano. Essa abordagem é particularmente valiosa em aplicações web ASP.NET , onde se deseja manter o processamento ágil de requisições ao mesmo tempo em que se processam múltiplos documentos PDF. O método retorna um Task<byte[]>, permitindo que os chamadores aguardem o resultado sem bloquear o thread principal. O código acima garante um gerenciamento de memória eficiente ao lidar com operações em arquivos PDF grandes. Para cenários mais avançados, explore os padrões assíncronos e multithreading no IronPDF.
Quando você deve usar operações assíncronas em PDFs?
Use a mesclagem assíncrona ao processar PDFs maiores que 10 MB, lidar com várias solicitações simultâneas ou integrar-se com APIs web assíncronas. Isso evita a escassez de threads em cenários de alto tráfego. Considere implementar atrasos e tempos limite de renderização para operações que envolvam recursos externos. Em arquiteturas de microsserviços, as operações assíncronas permitem uma melhor utilização dos recursos e evitam falhas em cascata durante picos de carga.
Quais são as implicações para o desempenho?
Operações assíncronas reduzem a pressão sobre a memória em até 40% em cenários de alta concorrência. Elas permitem uma melhor utilização dos recursos em ambientes conteinerizados, onde os limites de CPU e memória são rigorosamente aplicados. Ao combinar essas técnicas com a geração paralela de PDFs , é possível obter melhorias significativas de desempenho. Monitore o desempenho usando registros personalizados para identificar gargalos em seu pipeline de processamento de PDF.
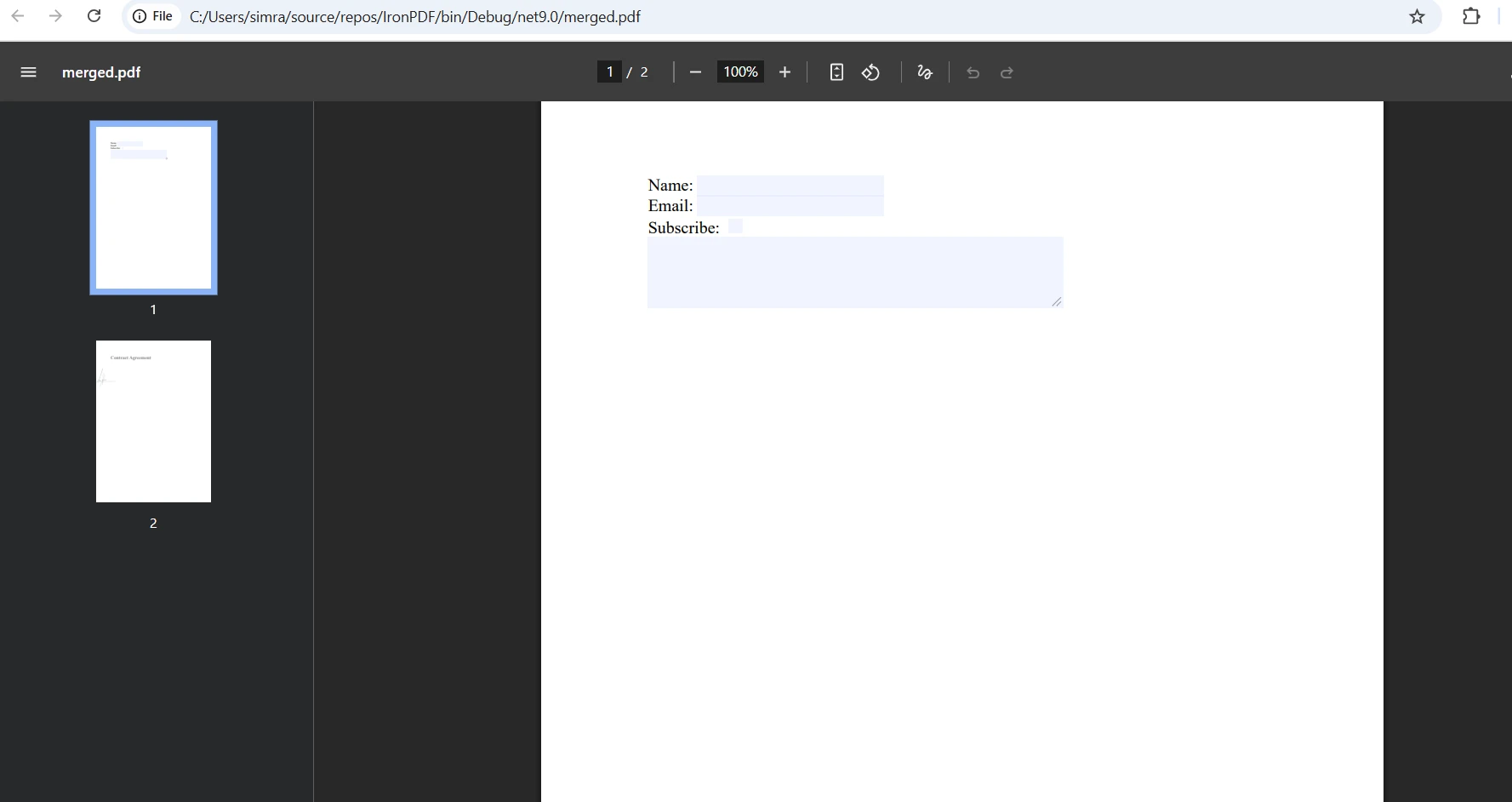
Como mesclar vários arquivos PDF de forma eficiente?
Ao trabalhar com vários arquivos PDF, utilize uma Lista para processamento em lote. Essa abordagem permite combinar qualquer número de documentos PDF em um único arquivo PDF:
public byte[] MergeMultiplePdfByteArrays(List<byte[]> pdfByteArrays)
{
if (pdfByteArrays == null || pdfByteArrays.Count == 0)
return null;
// Convert all byte arrays to PdfDocument objects
var pdfDocuments = pdfByteArrays
.Select(bytes => new PdfDocument(bytes))
.ToList();
// Merge all PDFs in one operation
var PDF = PdfDocument.Merge(pdfDocuments);
// Clean up resources
foreach (var pdfDoc in pdfDocuments)
{
pdfDoc.Dispose();
}
return PDF.BinaryData;
}public byte[] MergeMultiplePdfByteArrays(List<byte[]> pdfByteArrays)
{
if (pdfByteArrays == null || pdfByteArrays.Count == 0)
return null;
// Convert all byte arrays to PdfDocument objects
var pdfDocuments = pdfByteArrays
.Select(bytes => new PdfDocument(bytes))
.ToList();
// Merge all PDFs in one operation
var PDF = PdfDocument.Merge(pdfDocuments);
// Clean up resources
foreach (var pdfDoc in pdfDocuments)
{
pdfDoc.Dispose();
}
return PDF.BinaryData;
}Imports System.Collections.Generic
Imports System.Linq
Public Function MergeMultiplePdfByteArrays(pdfByteArrays As List(Of Byte())) As Byte()
If pdfByteArrays Is Nothing OrElse pdfByteArrays.Count = 0 Then
Return Nothing
End If
' Convert all byte arrays to PdfDocument objects
Dim pdfDocuments = pdfByteArrays _
.Select(Function(bytes) New PdfDocument(bytes)) _
.ToList()
' Merge all PDFs in one operation
Dim PDF = PdfDocument.Merge(pdfDocuments)
' Clean up resources
For Each pdfDoc In pdfDocuments
pdfDoc.Dispose()
Next
Return PDF.BinaryData
End FunctionEste método lida de forma eficiente com qualquer número de matrizes de bytes em PDF. Primeiro, o programa valida a entrada para garantir que a lista contenha dados. Usando o método Select() do LINQ, transforma cada array de bytes em objetos PdfDocument. O método Merge() aceita uma Lista de objetos PDFDocument, combinando-os todos em uma única operação para criar um novo documento. A limpeza de recursos é importante - descartar objetos PdfDocument individuais após a mesclagem de PDF ajuda a gerenciar memoria e recursos de forma eficaz, especialmente ao processar arquivos PDF numerosos ou grandes. O comprimento da matriz de bytes resultante depende do número de páginas em todos os documentos PDF de origem. Você também pode dividir PDFs com várias páginas ou copiar páginas específicas para um controle mais preciso.
Que técnicas de otimização de memória você deve aplicar?
Processe os PDFs em lotes de 10 a 20 documentos para manter um uso de memória previsível. Para operações de maior porte, implemente uma abordagem baseada em filas com limites de concorrência configuráveis. Utilize a compressão de PDF para reduzir o consumo de memória durante o processamento. Ao lidar com arquivos de saída grandes , considere transmitir os resultados diretamente para o Armazenamento de Blobs do Azure em vez de mantê-los na memória.
Como monitorar o uso de recursos durante operações em lote?
Implemente endpoints de verificação de integridade que monitorem operações de mesclagem ativas, consumo de memória e profundidade da fila de processamento. Isso permite que as sondas de prontidão do Kubernetes gerenciem adequadamente o escalonamento de pods. Configure o registro de logs do IronPDF para capturar métricas de desempenho e identificar vazamentos de memória. Utilize a API de fluxo de memória para rastrear padrões exatos de alocação de memória durante operações em lote.
Quais são as melhores práticas para uso na produção?
Sempre envolva as operações com PDFs em blocos try-catch para lidar com possíveis exceções provenientes de arquivos PDF corrompidos ou protegidos por senha. Use declarações using ou descarte explicitamente objetos PdfDocument para evitar vazamentos de memória. Para operações em larga escala, considere implementar abordagens de paginação ou streaming em vez de carregar documentos inteiros na memória simultaneamente.
public byte[] SafeMergePdfByteArrays(byte[] firstPdf, byte[] secondPdf)
{
try
{
// Validate input PDFs
if (firstPdf == null || firstPdf.Length == 0)
throw new ArgumentException("First PDF is empty");
if (secondPdf == null || secondPdf.Length == 0)
throw new ArgumentException("Second PDF is empty");
using (var pdf1 = new PdfDocument(firstPdf))
using (var pdf2 = new PdfDocument(secondPdf))
{
// Check for password protection
if (pdf1.IsPasswordProtected || pdf2.IsPasswordProtected)
throw new InvalidOperationException("Password-protected PDFs require authentication");
var mergedPdf = PdfDocument.Merge(pdf1, pdf2);
// Apply security settings if needed
mergedPdf.SecuritySettings.AllowUserPrinting = true;
mergedPdf.SecuritySettings.AllowUserCopyPasteContent = false;
return mergedPdf.BinaryData;
}
}
catch (Exception ex)
{
// Log error details for debugging
Console.WriteLine($"PDF merge failed: {ex.Message}");
throw;
}
}public byte[] SafeMergePdfByteArrays(byte[] firstPdf, byte[] secondPdf)
{
try
{
// Validate input PDFs
if (firstPdf == null || firstPdf.Length == 0)
throw new ArgumentException("First PDF is empty");
if (secondPdf == null || secondPdf.Length == 0)
throw new ArgumentException("Second PDF is empty");
using (var pdf1 = new PdfDocument(firstPdf))
using (var pdf2 = new PdfDocument(secondPdf))
{
// Check for password protection
if (pdf1.IsPasswordProtected || pdf2.IsPasswordProtected)
throw new InvalidOperationException("Password-protected PDFs require authentication");
var mergedPdf = PdfDocument.Merge(pdf1, pdf2);
// Apply security settings if needed
mergedPdf.SecuritySettings.AllowUserPrinting = true;
mergedPdf.SecuritySettings.AllowUserCopyPasteContent = false;
return mergedPdf.BinaryData;
}
}
catch (Exception ex)
{
// Log error details for debugging
Console.WriteLine($"PDF merge failed: {ex.Message}");
throw;
}
}Imports System
Public Function SafeMergePdfByteArrays(firstPdf As Byte(), secondPdf As Byte()) As Byte()
Try
' Validate input PDFs
If firstPdf Is Nothing OrElse firstPdf.Length = 0 Then
Throw New ArgumentException("First PDF is empty")
End If
If secondPdf Is Nothing OrElse secondPdf.Length = 0 Then
Throw New ArgumentException("Second PDF is empty")
End If
Using pdf1 As New PdfDocument(firstPdf)
Using pdf2 As New PdfDocument(secondPdf)
' Check for password protection
If pdf1.IsPasswordProtected OrElse pdf2.IsPasswordProtected Then
Throw New InvalidOperationException("Password-protected PDFs require authentication")
End If
Dim mergedPdf = PdfDocument.Merge(pdf1, pdf2)
' Apply security settings if needed
mergedPdf.SecuritySettings.AllowUserPrinting = True
mergedPdf.SecuritySettings.AllowUserCopyPasteContent = False
Return mergedPdf.BinaryData
End Using
End Using
Catch ex As Exception
' Log error details for debugging
Console.WriteLine($"PDF merge failed: {ex.Message}")
Throw
End Try
End FunctionAo trabalhar com páginas selecionadas de vários documentos PDF, você também pode extrair instâncias específicas de PdfPage antes de mesclar. O abrangente sistema de tratamento de erros do IronPDF garante implantações robustas em ambientes de produção e de teste. Se você já está familiarizado com outras bibliotecas de PDF, achará a API do IronPDF particularmente intuitiva para importar e usar em seu projeto. Considere implementar a higienização de PDFs para fontes de entrada não confiáveis e assinaturas digitais para autenticação de documentos.
Como implementar um tratamento de erros adequado em ambientes conteinerizados?
Configure o registro estruturado com IDs de correlação para rastrear operações de PDF em sistemas distribuídos. Implemente mecanismos de proteção (circuit breakers) para fontes PDF externas a fim de evitar falhas em cascata. Utilize arquivos de log do Azure ou arquivos de log da AWS para rastreamento centralizado de erros. Ao lidar com exceções nativas , certifique-se de que o contexto de erro adequado seja capturado para depuração.
Quais padrões de implantação funcionam melhor para serviços de processamento de PDF?
Implante o processamento de PDF como microsserviços separados com limites de recursos dedicados. Para obter o melhor desempenho, utilize o dimensionamento automático horizontal de pods com base no uso de memória em vez de CPU. Implemente o processamento baseado em filas para operações em lote com concorrência configurável. Considere usar o pacote IronPdf.Slim para reduzir o tamanho das imagens do contêiner. Configure tamanhos de papel e margens personalizados no nível do serviço para garantir consistência.
Por que escolher o IronPDF para operações de produção em PDF?
IronPDF simplifica a complexa tarefa de mesclar arquivos PDF a partir de arrays de bytes em C#, fornecendo uma API limpa que lida automaticamente com os detalhes intrincados da estrutura do documento PDF. Seja para criar sistemas de gerenciamento de documentos, processar respostas de API, lidar com uploads de arquivos com anexos ou trabalhar com armazenamento de banco de dados, os recursos de mesclagem do IronPDF se integram perfeitamente aos seus aplicativos .NET .
A biblioteca oferece suporte a operações assíncronas e processamento com uso eficiente de memória, tornando-a ideal tanto para aplicações desktop quanto para aplicações de servidor. Você pode editar, converter e salvar arquivos PDF sem gravar arquivos temporários no disco. Para obter suporte e respostas adicionais, visite nosso fórum ou site. A referência da API fornece documentação completa para todos os métodos e propriedades disponíveis.
Pronto para implementar a fusão de PDFs em seu aplicativo? Comece com um teste gratuito ou explore a documentação completa da API para descobrir todos os recursos do IronPDF, incluindo conversão de HTML para PDF , manipulação de formulários PDF e assinaturas digitais. Nosso site fornece documentação de referência completa para todas as operações de fluxo do System.IO, além de tutoriais abrangentes para cenários avançados de manipulação de PDFs.
Perguntas frequentes
Como posso mesclar duas matrizes de bytes de um PDF em C#?
É possível mesclar dois arrays de bytes de PDF em C# usando o IronPDF. Ele permite combinar facilmente vários arquivos PDF armazenados como arrays de bytes em um único documento PDF, sem a necessidade de salvá-los em disco.
Quais são os benefícios de usar o IronPDF para mesclar matrizes de bytes de PDFs?
O IronPDF simplifica o processo de mesclagem de arrays de bytes de PDFs, fornecendo uma API intuitiva. Ele processa PDFs de forma eficiente na memória, o que é ideal para aplicações que recuperam PDFs de bancos de dados ou serviços web.
O IronPDF consegue mesclar arquivos PDF sem salvá-los no disco?
Sim, o IronPDF pode mesclar arquivos PDF sem salvá-los em disco. Ele processa arquivos PDF diretamente de matrizes de bytes, tornando-o adequado para operações baseadas em memória.
É possível mesclar arquivos PDF recebidos de serviços web usando o IronPDF?
Com certeza. O IronPDF consegue mesclar arquivos PDF recebidos como matrizes de bytes de serviços web, permitindo uma integração perfeita com fontes PDF remotas.
Qual é uma aplicação comum da mesclagem de arrays de bytes de PDF em C#?
Uma aplicação comum é combinar vários documentos PDF recuperados de um banco de dados em um único arquivo PDF antes de processá-lo ou exibi-lo em um aplicativo C#.
O IronPDF suporta o processamento de PDFs na memória?
Sim, o IronPDF suporta o processamento de PDFs na memória, o que é essencial para aplicações que exigem manipulação rápida de arquivos PDF sem armazenamento intermediário em disco.
Como o IronPDF lida com a fusão de PDFs provenientes de bancos de dados?
O IronPDF lida com a fusão de PDFs de bancos de dados, permitindo que você trabalhe diretamente com matrizes de bytes de PDF, eliminando a necessidade de armazenamento temporário de arquivos.
O IronPDF consegue combinar vários arquivos PDF em um só?
Sim, o IronPDF pode combinar vários arquivos PDF em um só, mesclando seus arrays de bytes, oferecendo um método simplificado para criar documentos PDF compostos.











