
如何使用IronPDF建立Blazor PDF查看器
在C#中合併兩個PDF位元組陣列時,使用IronPDF的PdfDocument物件並結合它們,同時保留結構、格式和表單欄位 - 無需存取檔案系統。
在現代.NET應用程式中,記憶體中的PDF檔案處理是一個常見的需求。 無論您是從Web API接收多個PDF檔案,從資料庫BLOB列檢索,或處理從伺服器上載的檔案,您通常需要將多個PDF位元組陣列合併成一個PDF文件而不觸碰檔案系統。 在本文中,我們將探討IronPDF如何通過其直觀的API來程式化合併PDF使合併PDF變得非常簡單。
為什麼您不能簡單連接PDF文件的位元組陣列?
與文字檔案不同,PDF文件具有複雜的內部結構,包括交叉引用表、物件定義和特定的格式要求。 簡單將兩個PDF檔案作為位元組陣列連接起來將破壞文件結構,導致無法閱讀的PDF檔案。這就是為什麼像IronPDF這樣的專業PDF庫是必需的 - 它們理解PDF規範並正確合併PDF文件,同時保持其完整性。 根據Stack Overflow論壇討論,嘗試直接位元組陣列連接是開發人員在合併PDF內容時常犯的錯誤。
當您直接連接PDF位元組會發生什麼?
當不進行正確解析就將PDF位元組連接時,生成的文件包含多個PDF標頭、衝突的交叉引用表和損壞的物件引用。 PDF閱讀器無法解釋這種格式錯誤的結構,導致損壞錯誤或空白文件。 PDF/A格式特別要求嚴格遵守結構標準,這使得正確合併對於存檔文件尤為重要。
為什麼PDF結構需要特殊處理?
PDF包含相互連結的物件、字體定義和必須小心合併的頁面樹。 每個PDF的內部引用需要更新以指向合併文件中的正確位置,這需要了解PDF規範。 管理字體和合併操作期間保留元資料需要專業的解析功能,這只有專用的PDF庫能夠提供。

如何設置IronPDF以合併PDF?
通過NuGet Package Manager在您的.NET專案中安裝IronPDF:
Install-Package IronPdf
或將影像拖放在此處
新增必要的using語句以導入程式庫:
using IronPdf;
using System.IO; // For MemoryStream
using System.Threading.Tasks;
using System.Collections.Generic; // For List operations
using System.Linq; // For LINQ transformationsusing IronPdf;
using System.IO; // For MemoryStream
using System.Threading.Tasks;
using System.Collections.Generic; // For List operations
using System.Linq; // For LINQ transformationsImports IronPdf
Imports System.IO ' For MemoryStream
Imports System.Threading.Tasks
Imports System.Collections.Generic ' For List operations
Imports System.Linq ' For LINQ transformations對於生產伺服器環境,應用您的授權金鑰以存取完整功能,無需密碼限制:
IronPdf.License.LicenseKey = "YOUR-LICENSE-KEY";IronPdf.License.LicenseKey = "YOUR-LICENSE-KEY";IronPdf.License.LicenseKey = "YOUR-LICENSE-KEY"IronPDF支援Windows、Linux、macOS和Docker容器,使其成為ASP.NET Core和雲原生應用程式的理想選擇。 該程式庫的本地與遠端引擎架構為各種部署方案提供靈活性,從Windows伺服器到Linux容器。
容器部署的要求是什麼?
IronPDF無外部依賴性地在Docker容器中本地運行。 該程式庫包括所有必要組件,消除了在容器映像中進行Chrome安裝或複雜字體配置的需求。 為了在容器化環境中獲得最佳效能,配置IronPDF執行時目錄並實施適當的資源監控。 在部署到AWS Lambda或Azure Functions時,程式庫會自動處理平台特定的優化。
IronPDF如何處理跨平台相容性?
該程式庫採用自包含架構,抽象平台特定操作,確保在Windows伺服器、Linux發行版和容器化環境中行為一致,無需平台特定程式碼。 Chrome渲染引擎提供跨平台的像素級一致性,而IronPdfEngine Docker容器使資源密集型操作的遠端處理成為可能。

如何在C#中使用IronPDF合併兩個PDF位元組陣列?
var PDF = PdfDocument.Merge(
PdfDocument.FromBytes(pdfBytes1),
PdfDocument.FromBytes(pdfBytes2));var PDF = PdfDocument.Merge(
PdfDocument.FromBytes(pdfBytes1),
PdfDocument.FromBytes(pdfBytes2));Dim PDF = PdfDocument.Merge( _
PdfDocument.FromBytes(pdfBytes1), _
PdfDocument.FromBytes(pdfBytes2))以下是從位元組資料合併兩個PDF檔案的核心程式碼範例:
public byte[] MergePdfByteArrays(byte[] firstPdf, byte[] secondPdf)
{
// Load the first PDF file from byte array
var pdf1 = new PdfDocument(firstPdf);
// Load the second PDF file from byte array
var pdf2 = new PdfDocument(secondPdf);
// Merge PDF documents into one PDF
var mergedPdf = PdfDocument.Merge(pdf1, pdf2);
// Return the combined PDF as byte array
return mergedPdf.BinaryData;
}public byte[] MergePdfByteArrays(byte[] firstPdf, byte[] secondPdf)
{
// Load the first PDF file from byte array
var pdf1 = new PdfDocument(firstPdf);
// Load the second PDF file from byte array
var pdf2 = new PdfDocument(secondPdf);
// Merge PDF documents into one PDF
var mergedPdf = PdfDocument.Merge(pdf1, pdf2);
// Return the combined PDF as byte array
return mergedPdf.BinaryData;
}Public Function MergePdfByteArrays(firstPdf As Byte(), secondPdf As Byte()) As Byte()
' Load the first PDF file from byte array
Dim pdf1 = New PdfDocument(firstPdf)
' Load the second PDF file from byte array
Dim pdf2 = New PdfDocument(secondPdf)
' Merge PDF documents into one PDF
Dim mergedPdf = PdfDocument.Merge(pdf1, pdf2)
' Return the combined PDF as byte array
Return mergedPdf.BinaryData
End Function此方法接受兩個PDF位元組陣列作為輸入參數。 PdfDocument物件。 Merge()方法將兩個PDF文件組合成一個新的PDF,同時保留所有內容、格式和表單欄位。 對於更複雜的情況,您可以使用高級渲染選項來控制合併行為。
合併輸出是什麼樣的?
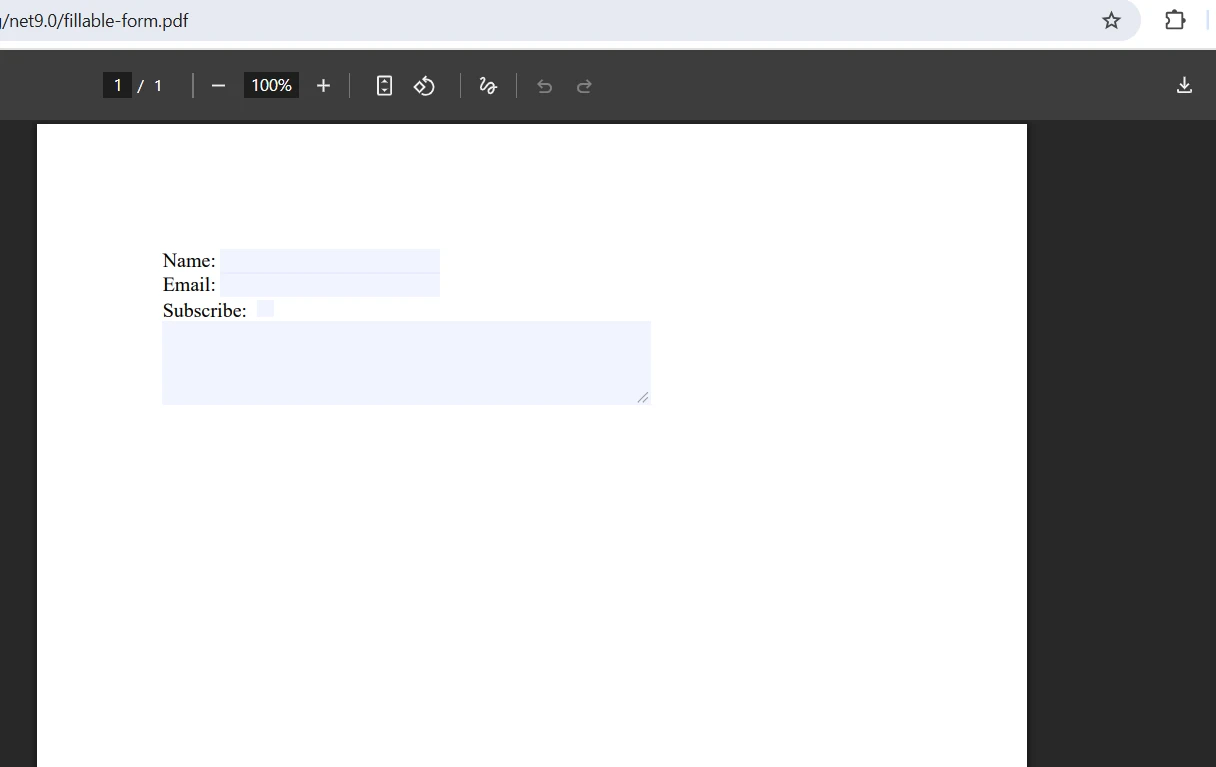
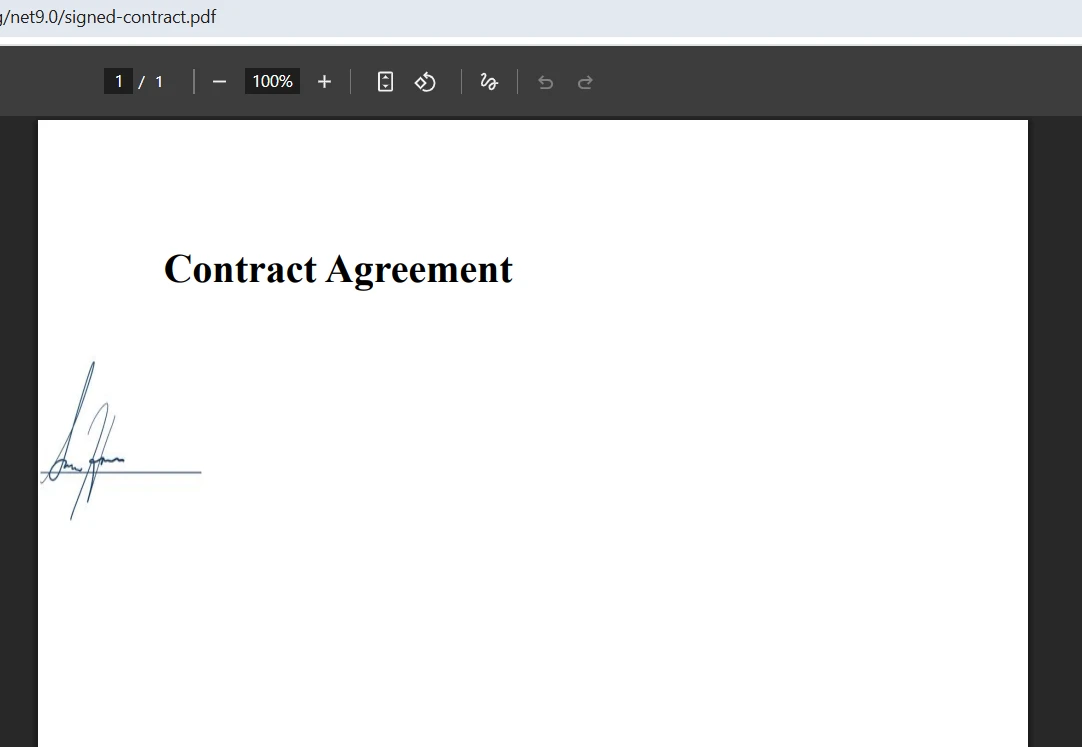
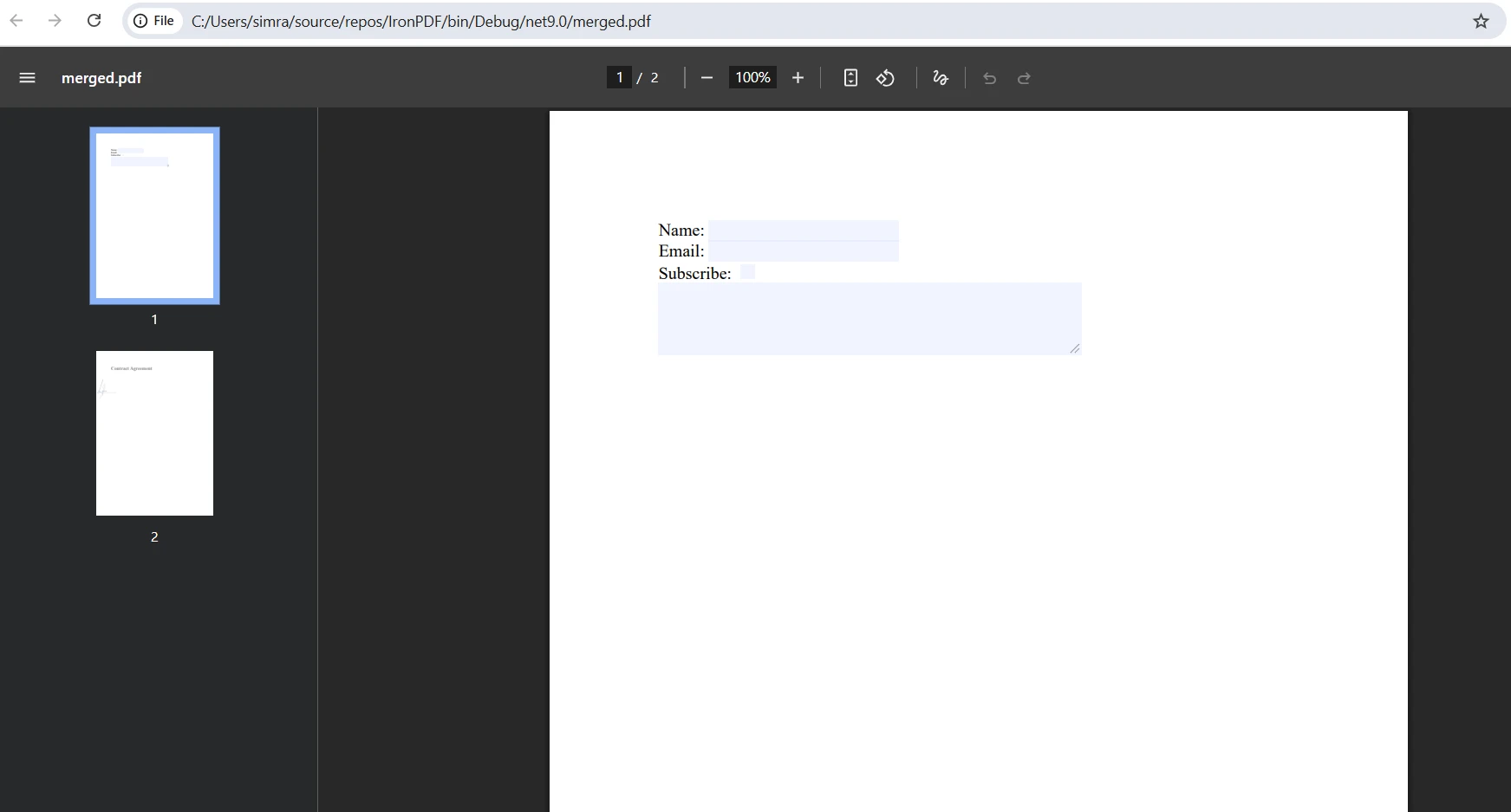
如何在合併過程中處理表單欄位衝突?
為了更多控制,您也可以直接使用新的MemoryStream:
public byte[] MergePdfsWithStream(byte[] src1, byte[] src2)
{
using (var stream = new MemoryStream())
{
var pdf1 = new PdfDocument(src1);
var pdf2 = new PdfDocument(src2);
var combined = PdfDocument.Merge(pdf1, pdf2);
// Handle form field name conflicts
if (combined.Form != null && combined.Form.Fields.Count > 0)
{
// Access and modify form fields if needed
foreach (var field in combined.Form.Fields)
{
// Process form fields
Console.WriteLine($"Field: {field.Name}");
}
}
return combined.BinaryData;
}
}public byte[] MergePdfsWithStream(byte[] src1, byte[] src2)
{
using (var stream = new MemoryStream())
{
var pdf1 = new PdfDocument(src1);
var pdf2 = new PdfDocument(src2);
var combined = PdfDocument.Merge(pdf1, pdf2);
// Handle form field name conflicts
if (combined.Form != null && combined.Form.Fields.Count > 0)
{
// Access and modify form fields if needed
foreach (var field in combined.Form.Fields)
{
// Process form fields
Console.WriteLine($"Field: {field.Name}");
}
}
return combined.BinaryData;
}
}Imports System
Imports System.IO
Public Function MergePdfsWithStream(src1 As Byte(), src2 As Byte()) As Byte()
Using stream As New MemoryStream()
Dim pdf1 As New PdfDocument(src1)
Dim pdf2 As New PdfDocument(src2)
Dim combined As PdfDocument = PdfDocument.Merge(pdf1, pdf2)
' Handle form field name conflicts
If combined.Form IsNot Nothing AndAlso combined.Form.Fields.Count > 0 Then
' Access and modify form fields if needed
For Each field In combined.Form.Fields
' Process form fields
Console.WriteLine($"Field: {field.Name}")
Next
End If
Return combined.BinaryData
End Using
End Function如果兩個PDF文件包含具有相同名稱的表單欄位,IronPDF會自動處理命名衝突,通過追加下劃線。 當處理可填寫的PDF表單時,您可以在儲存合併文件之前程式化地存取和修改表單欄位。 PDF DOM物件模型提供對表單元素的完整控制。 最後,BinaryData屬性以位元組陣列格式返回合併的PDF作為一個新文件。 為了將結果傳遞給其他方法,只需返回此位元組陣列 - 除非需要,無需儲存到磁碟。
如何實現異步合併以提高效能?
對於處理大PDF檔案或伺服器上高請求量的應用程式,異步操作可防止執行緒阻塞。 以下程式碼顯示如何異步合併PDF文件:
public async Task<byte[]> MergePdfByteArraysAsync(byte[] firstPdf, byte[] secondPdf)
{
return await Task.Run(() =>
{
var pdf1 = new PdfDocument(firstPdf);
var pdf2 = new PdfDocument(secondPdf);
var PDF = PdfDocument.Merge(pdf1, pdf2);
return PDF.BinaryData;
});
}public async Task<byte[]> MergePdfByteArraysAsync(byte[] firstPdf, byte[] secondPdf)
{
return await Task.Run(() =>
{
var pdf1 = new PdfDocument(firstPdf);
var pdf2 = new PdfDocument(secondPdf);
var PDF = PdfDocument.Merge(pdf1, pdf2);
return PDF.BinaryData;
});
}Imports System.Threading.Tasks
Public Class PdfMerger
Public Async Function MergePdfByteArraysAsync(firstPdf As Byte(), secondPdf As Byte()) As Task(Of Byte())
Return Await Task.Run(Function()
Dim pdf1 = New PdfDocument(firstPdf)
Dim pdf2 = New PdfDocument(secondPdf)
Dim PDF = PdfDocument.Merge(pdf1, pdf2)
Return PDF.BinaryData
End Function)
End Function
End Class此異步實現將PDF合併操作包裝在Task.Run()中,允許其在背景執行緒上執行。 此方法在ASP.NET Web應用程式中特別有價值,因為您希望在處理多個PDF檔案時保持響應的請求處理。 該方法返回Task<byte[]>,允許呼叫者等待結果而不阻塞主執行緒。 上面的程式碼確保在處理大PDF檔案操作時的有效記憶體管理。 對於更高級的場景,請探索IronPDF中的異步和多執行緒模式。
您應該何時使用異步PDF操作?
當處理大於10MB的PDF、處理多個同時請求或與異步Web API整合時,使用異步合併。這可防止在高流量環境中執行緒池枯竭。 考慮對涉及外部資源的操作實現渲染延遲和超時。 在微服務架構中,異步操作可提高資源利用效率,並在尖峰負載期間防止連鎖故障。
效能影響是什麼?
在高並發場景中,異步操作可減少高達40%的記憶體壓力。 它們使得在嚴格執行CPU和記憶體限制的容器化環境中更好地利用資源。 與parallel PDF generation技術結合使用時,您可以獲得顯著的效能改進。 使用自定義日誌記錄監控效能,以識別您的PDF處理管道中的瓶頸。
如何高效地合併多個PDF文件?
在處理多個PDF檔案時,使用List進行批次處理。 此方法允許您將任意數量的PDF文件組合為一個PDF:
public byte[] MergeMultiplePdfByteArrays(List<byte[]> pdfByteArrays)
{
if (pdfByteArrays == null || pdfByteArrays.Count == 0)
return null;
// Convert all byte arrays to PdfDocument objects
var pdfDocuments = pdfByteArrays
.Select(bytes => new PdfDocument(bytes))
.ToList();
// Merge all PDFs in one operation
var PDF = PdfDocument.Merge(pdfDocuments);
// Clean up resources
foreach (var pdfDoc in pdfDocuments)
{
pdfDoc.Dispose();
}
return PDF.BinaryData;
}public byte[] MergeMultiplePdfByteArrays(List<byte[]> pdfByteArrays)
{
if (pdfByteArrays == null || pdfByteArrays.Count == 0)
return null;
// Convert all byte arrays to PdfDocument objects
var pdfDocuments = pdfByteArrays
.Select(bytes => new PdfDocument(bytes))
.ToList();
// Merge all PDFs in one operation
var PDF = PdfDocument.Merge(pdfDocuments);
// Clean up resources
foreach (var pdfDoc in pdfDocuments)
{
pdfDoc.Dispose();
}
return PDF.BinaryData;
}Imports System.Collections.Generic
Imports System.Linq
Public Function MergeMultiplePdfByteArrays(pdfByteArrays As List(Of Byte())) As Byte()
If pdfByteArrays Is Nothing OrElse pdfByteArrays.Count = 0 Then
Return Nothing
End If
' Convert all byte arrays to PdfDocument objects
Dim pdfDocuments = pdfByteArrays _
.Select(Function(bytes) New PdfDocument(bytes)) _
.ToList()
' Merge all PDFs in one operation
Dim PDF = PdfDocument.Merge(pdfDocuments)
' Clean up resources
For Each pdfDoc In pdfDocuments
pdfDoc.Dispose()
Next
Return PDF.BinaryData
End Function此方法高效處理任意數量的PDF位元組陣列。 它首先驗證輸入以確保列表包含資料。 使用LINQ的PdfDocument物件。 Merge()方法接受PDFDocument物件的清單,將它們全部在單一操作中合併以建立一個新文件。 資源清理很重要 - 在合併PDF後處置個別的PdfDocument物件,有助於有效管理記憶體和資源,特別是當處理眾多或大型PDF檔案時。 生成位元組陣列的長度取決於所有來源PDF文件中的頁面數。 您還可以分割多頁PDF或複製特定頁面以獲得更精細的控制。
應該應用哪些記憶體優化技術?
以10-20個文件為一批處理PDF,以保持預測的記憶體使用量。 對於大型操作,實施具有可配置並發限制的基於佇列的方案。 使用PDF壓縮以在處理期間減少記憶體佔用量。 在處理大輸出文件時,考慮將結果直接流傳輸到Azure Blob儲存而不是將它們保存在記憶體中。
如何在批次操作期間監控資源使用?
實施健康檢查端點以跟蹤活動合併操作、記憶體消耗和處理佇列深度。 這使得Kubernetes就緒探測可以正確管理Pod縮放。 配置IronPDF日誌以捕獲效能指標並識別記憶體洩漏。 使用記憶體流API來在批次操作期間跟蹤確切的記憶體分配模式。
生產使用的最佳實踐是什麼?
始終將PDF操作包裝在try-catch塊中,以處理來自損壞或受密碼保護的PDF文件的潛在例外情況。 使用using語句或顯式釋放PdfDocument物件以防止記憶體洩漏。 對於大規模操作,考慮實施分頁或流傳輸方案,而不是一次將整個文件載入到記憶體中。
public byte[] SafeMergePdfByteArrays(byte[] firstPdf, byte[] secondPdf)
{
try
{
// Validate input PDFs
if (firstPdf == null || firstPdf.Length == 0)
throw new ArgumentException("First PDF is empty");
if (secondPdf == null || secondPdf.Length == 0)
throw new ArgumentException("Second PDF is empty");
using (var pdf1 = new PdfDocument(firstPdf))
using (var pdf2 = new PdfDocument(secondPdf))
{
// Check for password protection
if (pdf1.IsPasswordProtected || pdf2.IsPasswordProtected)
throw new InvalidOperationException("Password-protected PDFs require authentication");
var mergedPdf = PdfDocument.Merge(pdf1, pdf2);
// Apply security settings if needed
mergedPdf.SecuritySettings.AllowUserPrinting = true;
mergedPdf.SecuritySettings.AllowUserCopyPasteContent = false;
return mergedPdf.BinaryData;
}
}
catch (Exception ex)
{
// Log error details for debugging
Console.WriteLine($"PDF merge failed: {ex.Message}");
throw;
}
}public byte[] SafeMergePdfByteArrays(byte[] firstPdf, byte[] secondPdf)
{
try
{
// Validate input PDFs
if (firstPdf == null || firstPdf.Length == 0)
throw new ArgumentException("First PDF is empty");
if (secondPdf == null || secondPdf.Length == 0)
throw new ArgumentException("Second PDF is empty");
using (var pdf1 = new PdfDocument(firstPdf))
using (var pdf2 = new PdfDocument(secondPdf))
{
// Check for password protection
if (pdf1.IsPasswordProtected || pdf2.IsPasswordProtected)
throw new InvalidOperationException("Password-protected PDFs require authentication");
var mergedPdf = PdfDocument.Merge(pdf1, pdf2);
// Apply security settings if needed
mergedPdf.SecuritySettings.AllowUserPrinting = true;
mergedPdf.SecuritySettings.AllowUserCopyPasteContent = false;
return mergedPdf.BinaryData;
}
}
catch (Exception ex)
{
// Log error details for debugging
Console.WriteLine($"PDF merge failed: {ex.Message}");
throw;
}
}Imports System
Public Function SafeMergePdfByteArrays(firstPdf As Byte(), secondPdf As Byte()) As Byte()
Try
' Validate input PDFs
If firstPdf Is Nothing OrElse firstPdf.Length = 0 Then
Throw New ArgumentException("First PDF is empty")
End If
If secondPdf Is Nothing OrElse secondPdf.Length = 0 Then
Throw New ArgumentException("Second PDF is empty")
End If
Using pdf1 As New PdfDocument(firstPdf)
Using pdf2 As New PdfDocument(secondPdf)
' Check for password protection
If pdf1.IsPasswordProtected OrElse pdf2.IsPasswordProtected Then
Throw New InvalidOperationException("Password-protected PDFs require authentication")
End If
Dim mergedPdf = PdfDocument.Merge(pdf1, pdf2)
' Apply security settings if needed
mergedPdf.SecuritySettings.AllowUserPrinting = True
mergedPdf.SecuritySettings.AllowUserCopyPasteContent = False
Return mergedPdf.BinaryData
End Using
End Using
Catch ex As Exception
' Log error details for debugging
Console.WriteLine($"PDF merge failed: {ex.Message}")
Throw
End Try
End Function當使用多個PDF文件中的選定頁面時,您還可以在合併之前提取特定的PdfPage實例。 IronPDF的全面錯誤處理確保在測試和生產環境中進行穩健的生產部署。 如果您熟悉其他PDF庫,您會發現IronPDF的API特別直觀地導入和使用在項目中。 考慮爲不受信任的輸入源實施PDF消毒及用於文件認證的數位簽章。
如何在容器化环境中實施適當的錯誤處理?
配置具有關聯ID的結構化日誌記錄以跟蹤分佈式系統中的PDF操作。 爲外部PDF源實現斷路器以防止級聯故障。 使用Azure日誌文件或AWS日誌文件進行集中錯誤跟蹤。 處理本地異常時,確保捕獲正確的錯誤上下文以進行除錯。
哪些部署模式最適用於PDF處理服務?
將PDF處理部署爲具有專用資源限制的獨立微服務。 使用基於記憶體使用而非CPU的水平Pod自動縮放以實現最佳性能。 爲批量操作實施具有可配置併發的基於隊列的處理。 考慮使用IronPdf.Slim套件以減少容器映像大小。 在服務層級配置自定義紙張尺寸和自定義邊距以確保一致性。
為什麼選擇IronPDF進行生產PDF操作?
IronPDF簡單化了從C#中的位元組陣列合並PDF文件的複雜任務,提供了處理PDF文件結構細節的乾淨API。 無論您是在構建文件管理系統、處理API回應、處理帶有附件的文件上傳,還是使用資料庫儲存,IronPDF的合併功能都能無縫整合到您的.NET應用程式中。
該程式庫支援異步操作和記憶體高效處理,適用於桌面和伺服器應用程式。 您可以編輯、轉換和儲存PDF文件,而無需將暫存文件寫入磁盤。 如需額外的支援和答案,請存取我們的論壇或網站。API參考提供了所有可用方法和屬性的詳細文件。
準備在您的應用程式中實現PDF合併嗎? 利用免費試用開始或瀏覽詳細的API文件發掘IronPDF的完整功能集,包括HTML到PDF轉換、PDF表單處理和電子簽名。 我們的網站提供了完整的System.IO流操作參考文件,以及用於高級PDF操作場景的廣泛教程。
常見問題
如何在C#中合併兩個PDF位元組陣列?
您可以使用IronPDF在C#中合併兩個PDF位元組陣列。它允許您輕鬆地將作為位元組陣列儲存的多個PDF檔案合併為一個PDF文件,而無需將它們儲存到磁碟上。
使用IronPDF合併PDF位元組陣列的好處是什麼?
IronPDF通過提供直觀的API簡化了合併PDF位元組陣列的過程。它在記憶體中高效地處理PDF,非常適合從資料庫或Web服務中檢索PDF的應用程式。
IronPDF能否在不將PDF檔儲存到磁碟的情況下合併它們?
是的,IronPDF可以在不將PDF檔儲存到磁碟的情況下合併它們。它直接從位元組陣列處理PDF檔案,非常適合記憶體為基礎的操作。
使用IronPDF合併來自Web服務的PDF檔案是否可行?
當然可以。IronPDF可以合併作為位元組陣列從Web服務接收的PDF檔案,實現與遠程PDF來源的無縫整合。
合併PDF位元組陣列在C#中的常見應用是什麼?
一個常見的應用是將從資料庫檢索的多個PDF文件結合為一個PDF檔案,然後在C#應用程式中處理或顯示。
IronPDF是否支持在記憶體中處理PDF?
是的,IronPDF支持在記憶體中處理PDF,這對於需要快速操作PDF文件且無需中介磁碟儲存的應用程式至關重要。
IronPDF如何處理從資料庫中合併PDF?
IronPDF通過允許直接操作PDF位元組陣列來自資料庫中處理PDF合併,消除了對臨時文件儲存的需求。
IronPDF能否將多個PDF檔案合併為一個?
是的,IronPDF可以通過合併它們的位元組陣列將多個PDF檔案合併為一個,提供建立複合PDF文件的精簡方法。











