
IronPDF를 사용하여 Blazor PDF 뷰어 생성하기
C#에서 두 개의 PDF 바이트 배열을 병합하려면 IronPDF의 PdfDocument.Merge() 메서드를 사용하세요. 이 메서드는 바이트 배열을 PdfDocument 객체에 로드하고 구조, 서식 및 양식 필드를 유지하면서 결합합니다. 파일 시스템 접근이 필요 없습니다.
메모리에서 PDF 파일을 다루는 것은 현대 .NET 응용 프로그램에서 일반적인 요구 사항입니다. 웹 API로부터 여러 PDF 파일을 수신하거나 데이터베이스 BLOB 열에서 이를 검색하거나 서버에서 업로드된 파일을 처리하는 경우 파일 시스템을 건드리지 않고 여러 PDF 바이트 배열을 단일 PDF 문서로 병합해야 할 때가 종종 있습니다. 이 기사에서는 IronPDF가 PDF를 프로그래밍 방식으로 병합하는 직관적인 API를 통해 PDF 병합을 놀랍도록 간단하게 만드는 방법을 탐구할 것입니다.
왜 단순히 PDF 파일 바이트 배열을 연결할 수 없습니까?
텍스트 파일과 달리 PDF 문서는 교차 참조 테이블, 객체 정의 및 특정 형식 요구 사항을 포함하는 복잡한 내부 구조를 가지고 있습니다. 바이트 배열로 두 개의 PDF 파일을 단순히 연결하면 문서 구조가 손상되어 읽을 수 없는 PDF 파일이 됩니다. 이는 IronPDF와 같은 전문 PDF 라이브러리가 필수적인 이유입니다 - PDF 사양을 이해하고 PDF 파일을 병합하여 무결성을 유지합니다. Stack Overflow 포럼 토론에 따르면, 개발자가 PDF 콘텐츠를 병합하려고 할 때 직접 바이트 배열 연결을 시도하는 것은 흔한 실수입니다.
PDF 바이트를 직접 연결하면 어떻게 됩니까?
적절한 구문 분석 없이 PDF 바이트를 연결하면 결과 파일에는 여러 PDF 헤더, 상충하는 교차 참조 테이블 및 손상된 객체 참조가 포함됩니다. PDF 리더가 이 잘못된 구조를 해석할 수 없어 손상 오류 또는 빈 문서가 발생합니다. PDF/A 형식은 특히 구조적 표준을 엄격하게 준수해야 하므로, 아카이브 문서의 올바른 병합이 필수적입니다.
왜 PDF 구조는 특별한 처리가 필요한가요?
PDF는 상호 연결된 개체, 폰트 정의 및 페이지 트리를 포함하며, 이는 신중하게 병합해야 합니다. 각 PDF의 내부 참조는 결합된 문서에서 올바른 위치를 가리키도록 업데이트해야 하며, 이는 PDF 사양을 이해해야 합니다. 폰트를 관리하고 병합 작업 중 메타데이터를 유지하는 것은 헌신적인 PDF 라이브러리만 제공하는 복잡한 구문 분석 기능이 필요합니다.

IronPDF를 사용하여 PDF를 병합하는 방법은?
NuGet 패키지 관리자를 통해 .NET 프로젝트에 IronPDF를 설치하세요:
Install-Package IronPdf
또는 여기로 이미지를 끌어다 놓으세요
라이브러리를 가져오기 위해 필요한 using 문을 추가하세요:
using IronPdf;
using System.IO; // For MemoryStream
using System.Threading.Tasks;
using System.Collections.Generic; // For List operations
using System.Linq; // For LINQ transformationsusing IronPdf;
using System.IO; // For MemoryStream
using System.Threading.Tasks;
using System.Collections.Generic; // For List operations
using System.Linq; // For LINQ transformationsImports IronPdf
Imports System.IO ' For MemoryStream
Imports System.Threading.Tasks
Imports System.Collections.Generic ' For List operations
Imports System.Linq ' For LINQ transformations프로덕션 서버 환경에서는 라이선스 키를 적용하여 비밀번호 제한 없이 모든 기능을 액세스하세요:
IronPdf.License.LicenseKey = "YOUR-LICENSE-KEY";IronPdf.License.LicenseKey = "YOUR-LICENSE-KEY";IronPdf.License.LicenseKey = "YOUR-LICENSE-KEY"IronPDF는 Windows, Linux, macOS 및 Docker 컨테이너를 지원하여 ASP.NET Core 및 클라우드 네이티브 애플리케이션에 이상적입니다. 라이브러리의 네이티브 대 원격 엔진 아키텍처는 Windows 서버에서 Linux 컨테이너까지 다양한 배포 시나리오에 유연성을 제공합니다.
컨테이너 배포 요구 사항은 무엇인가요?
IronPDF는 외부 종속성 없이 Docker 컨테이너에서 네이티브로 실행됩니다. 라이브러리는 컨테이너 이미지에서 Chrome 설치나 복잡한 폰트 구성이 필요 없는 모든 구성 요소를 포함합니다. 컨테이너화된 환경에서 최적의 성능을 위해 IronPDF 런타임 폴더를 구성하고 적절한 리소스 모니터링을 구현하세요. AWS Lambda 또는 Azure Functions에 배포할 때, 라이브러리는 플랫폼별 최적화를 자동으로 처리합니다.
IronPDF는 플랫폼 간 호환성을 어떻게 처리하나요?
라이브러리는 플랫폼별 작업을 추상화하는 자체 포함 아키텍처를 사용하여 Windows Server, Linux 배포판 및 컨테이너화된 환경 간에 일관된 동작을 보장합니다. Chrome 렌더링 엔진은 플랫폼 간 픽셀 완벽한 일관성을 제공하며, IronPdfEngine Docker 컨테이너는 리소스 집약적인 작업을 위한 원격 프로세싱을 가능하게 합니다.

C#에서 IronPDF로 두 PDF 바이트 배열을 병합하는 방법
var PDF = PdfDocument.Merge(
PdfDocument.FromBytes(pdfBytes1),
PdfDocument.FromBytes(pdfBytes2));var PDF = PdfDocument.Merge(
PdfDocument.FromBytes(pdfBytes1),
PdfDocument.FromBytes(pdfBytes2));Dim PDF = PdfDocument.Merge( _
PdfDocument.FromBytes(pdfBytes1), _
PdfDocument.FromBytes(pdfBytes2))바이트 배열 데이터에서 두 PDF 파일을 병합하는 핵심 코드 예제입니다:
public byte[] MergePdfByteArrays(byte[] firstPdf, byte[] secondPdf)
{
// Load the first PDF file from byte array
var pdf1 = new PdfDocument(firstPdf);
// Load the second PDF file from byte array
var pdf2 = new PdfDocument(secondPdf);
// Merge PDF documents into one PDF
var mergedPdf = PdfDocument.Merge(pdf1, pdf2);
// Return the combined PDF as byte array
return mergedPdf.BinaryData;
}public byte[] MergePdfByteArrays(byte[] firstPdf, byte[] secondPdf)
{
// Load the first PDF file from byte array
var pdf1 = new PdfDocument(firstPdf);
// Load the second PDF file from byte array
var pdf2 = new PdfDocument(secondPdf);
// Merge PDF documents into one PDF
var mergedPdf = PdfDocument.Merge(pdf1, pdf2);
// Return the combined PDF as byte array
return mergedPdf.BinaryData;
}Public Function MergePdfByteArrays(firstPdf As Byte(), secondPdf As Byte()) As Byte()
' Load the first PDF file from byte array
Dim pdf1 = New PdfDocument(firstPdf)
' Load the second PDF file from byte array
Dim pdf2 = New PdfDocument(secondPdf)
' Merge PDF documents into one PDF
Dim mergedPdf = PdfDocument.Merge(pdf1, pdf2)
' Return the combined PDF as byte array
Return mergedPdf.BinaryData
End Function이 메서드는 두 개의 PDF 바이트 배열을 입력 파라미터로 받습니다. PdfDocument.FromBytes() 메서드는 각각의 바이트 배열을 PdfDocument 객체에 로드합니다. Merge() 메서드는 모든 컨텐츠, 서식 및 양식 필드를 보존하면서 두 개의 PDF 문서를 하나의 새 PDF로 결합합니다. 더 복잡한 시나리오에 대해 고급 렌더링 옵션을 사용하여 병합 동작을 제어할 수 있습니다.
병합된 출력은 어떻게 보이나요?
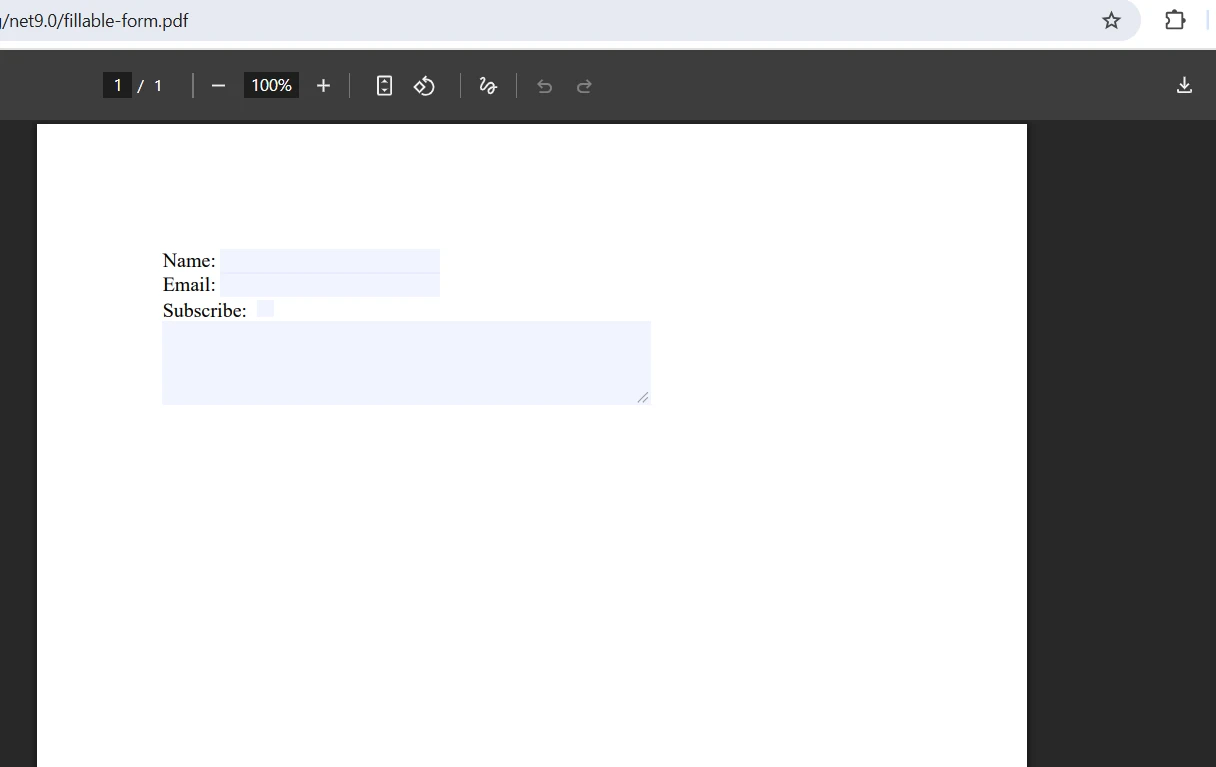
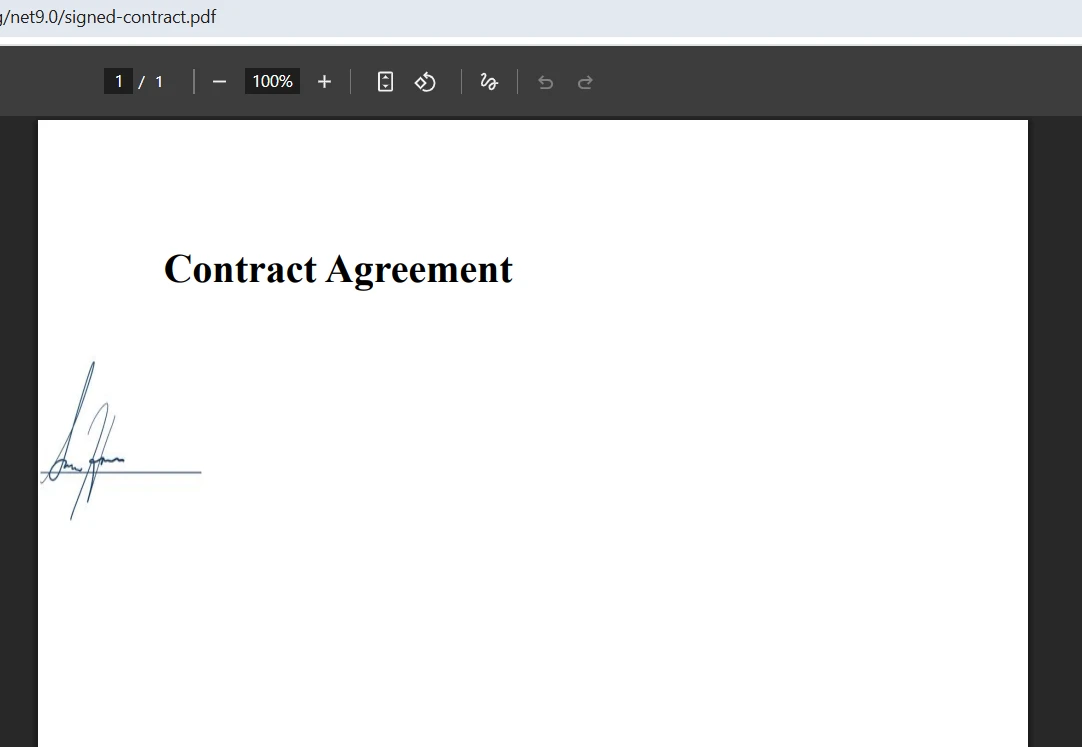
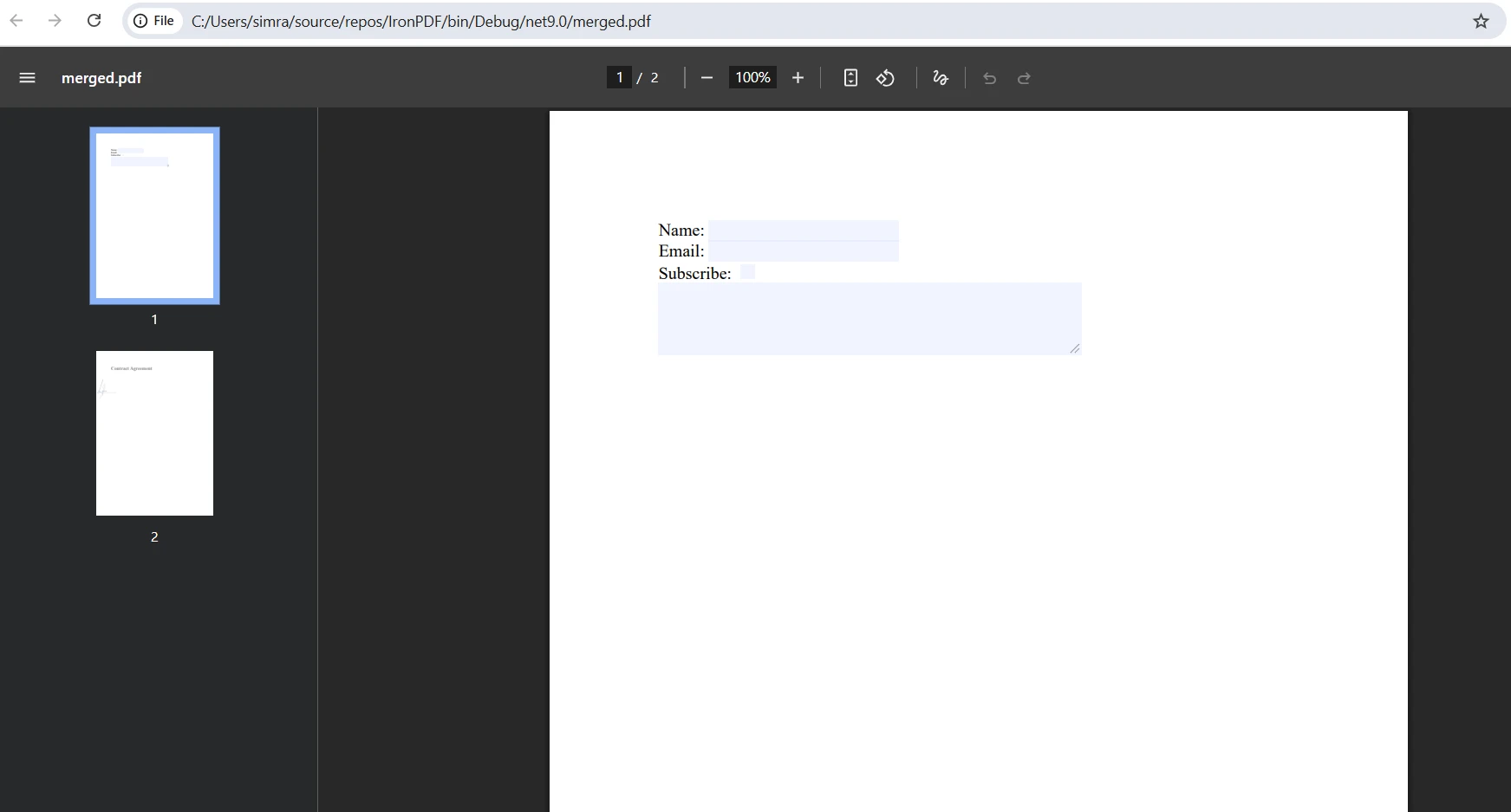
병합 중 양식 필드 충돌을 어떻게 처리하나요?
더 많은 제어를 위해 새로운 MemoryStream와 직접 작업할 수도 있습니다:
public byte[] MergePdfsWithStream(byte[] src1, byte[] src2)
{
using (var stream = new MemoryStream())
{
var pdf1 = new PdfDocument(src1);
var pdf2 = new PdfDocument(src2);
var combined = PdfDocument.Merge(pdf1, pdf2);
// Handle form field name conflicts
if (combined.Form != null && combined.Form.Fields.Count > 0)
{
// Access and modify form fields if needed
foreach (var field in combined.Form.Fields)
{
// Process form fields
Console.WriteLine($"Field: {field.Name}");
}
}
return combined.BinaryData;
}
}public byte[] MergePdfsWithStream(byte[] src1, byte[] src2)
{
using (var stream = new MemoryStream())
{
var pdf1 = new PdfDocument(src1);
var pdf2 = new PdfDocument(src2);
var combined = PdfDocument.Merge(pdf1, pdf2);
// Handle form field name conflicts
if (combined.Form != null && combined.Form.Fields.Count > 0)
{
// Access and modify form fields if needed
foreach (var field in combined.Form.Fields)
{
// Process form fields
Console.WriteLine($"Field: {field.Name}");
}
}
return combined.BinaryData;
}
}Imports System
Imports System.IO
Public Function MergePdfsWithStream(src1 As Byte(), src2 As Byte()) As Byte()
Using stream As New MemoryStream()
Dim pdf1 As New PdfDocument(src1)
Dim pdf2 As New PdfDocument(src2)
Dim combined As PdfDocument = PdfDocument.Merge(pdf1, pdf2)
' Handle form field name conflicts
If combined.Form IsNot Nothing AndAlso combined.Form.Fields.Count > 0 Then
' Access and modify form fields if needed
For Each field In combined.Form.Fields
' Process form fields
Console.WriteLine($"Field: {field.Name}")
Next
End If
Return combined.BinaryData
End Using
End Function두 PDF 파일 모두 동일한 이름의 양식 필드를 포함하는 경우 IronPDF는 자동으로 이름 충돌을 밑줄로 처리합니다. 작성 가능한 PDF 양식을 작업할 때 프로그램적으로 양식 필드를 액세스 및 수정할 수 있으며 병합된 문서를 저장하기 전에 가능합니다. PDF DOM 객체 모델은 양식 요소에 대한 완전한 제어를 제공합니다. 마지막으로, BinaryData 속성은 병합된 PDF를 바이트 배열 형식의 새로운 문서로 반환합니다. 결과를 다른 메서드에 전달하려면 단순히 이 바이트 배열을 반환하면 되며, 필요한 경우를 제외하고 디스크에 저장할 필요는 없습니다.
성능 향상을 위한 비동기 병합 구현 방법?
서버에서 대용량 PDF 파일을 처리하거나 높은 요청량을 처리하는 애플리케이션의 경우 비동기 작업은 스레드 블로킹을 방지합니다. 다음 코드에서는 PDF 문서를 비동기적으로 병합하는 방법을 보여줍니다:
public async Task<byte[]> MergePdfByteArraysAsync(byte[] firstPdf, byte[] secondPdf)
{
return await Task.Run(() =>
{
var pdf1 = new PdfDocument(firstPdf);
var pdf2 = new PdfDocument(secondPdf);
var PDF = PdfDocument.Merge(pdf1, pdf2);
return PDF.BinaryData;
});
}public async Task<byte[]> MergePdfByteArraysAsync(byte[] firstPdf, byte[] secondPdf)
{
return await Task.Run(() =>
{
var pdf1 = new PdfDocument(firstPdf);
var pdf2 = new PdfDocument(secondPdf);
var PDF = PdfDocument.Merge(pdf1, pdf2);
return PDF.BinaryData;
});
}Imports System.Threading.Tasks
Public Class PdfMerger
Public Async Function MergePdfByteArraysAsync(firstPdf As Byte(), secondPdf As Byte()) As Task(Of Byte())
Return Await Task.Run(Function()
Dim pdf1 = New PdfDocument(firstPdf)
Dim pdf2 = New PdfDocument(secondPdf)
Dim PDF = PdfDocument.Merge(pdf1, pdf2)
Return PDF.BinaryData
End Function)
End Function
End Class이 비동기 구현은 PDF 병합 작업을 Task.Run()로 래핑하여 백그라운드 스레드에서 실행될 수 있도록 합니다. 이 접근 방식은 여러 PDF 문서를 처리하면서 반응형 요청 처리를 유지하려는 ASP.NET 웹 애플리케이션에서 특히 유용합니다. 메서드는 Task<byte[]>를 반환하여 호출자가 메인 스레드를 차단하지 않고 결과를 기다릴 수 있게 합니다. 위 코드는 대용량 PDF 파일 작업 시 효율적인 메모리 관리를 보장합니다. 더 고급 시나리오에 대해 IronPDF에서 비동기 및 멀티 스레딩 패턴을 탐색하세요.
언제 비동기 PDF 작업을 사용해야 하나요?
10MB를 초과하는 PDF를 처리하거나, 여러 동시 요청을 처리하거나, 비동기 웹 API와 통합할 때 비동기 병합을 사용하세요. 이는 고트래픽 시나리오에서 스레드 풀 소모를 방지합니다. 외부 자원을 포함한 작업에 대한 렌더링 지연 및 타임아웃 구현을 고려하세요. 마이크로서비스 아키텍처에서는 비동기 작업이 리소스 활용을 개선하고 최대 부하 시 계단식 실패를 방지합니다.
성능에 미치는 영향은 무엇인가요?
비동기 작업은 높은 동시성 시나리오에서 최대 40%의 메모리 부담을 줄입니다. CPU 및 메모리 제한이 엄격히 적용되는 컨테이너 환경에서 리소스 활용을 개선합니다. 병렬 PDF 생성 기술과 결합하면 성능을 크게 향상할 수 있습니다. PDF 처리 파이프라인에서 병목 현상을 식별하기 위해 맞춤 로깅을 사용하여 성능을 모니터링하세요.
여러 PDF 파일을 효율적으로 병합하는 방법?
여러 PDF 파일을 다룰 때, 배치 처리에 List를 사용하세요. 이 접근 방식은 PDF 문서를 원하는 개수만큼 하나의 PDF로 결합할 수 있게 합니다:
public byte[] MergeMultiplePdfByteArrays(List<byte[]> pdfByteArrays)
{
if (pdfByteArrays == null || pdfByteArrays.Count == 0)
return null;
// Convert all byte arrays to PdfDocument objects
var pdfDocuments = pdfByteArrays
.Select(bytes => new PdfDocument(bytes))
.ToList();
// Merge all PDFs in one operation
var PDF = PdfDocument.Merge(pdfDocuments);
// Clean up resources
foreach (var pdfDoc in pdfDocuments)
{
pdfDoc.Dispose();
}
return PDF.BinaryData;
}public byte[] MergeMultiplePdfByteArrays(List<byte[]> pdfByteArrays)
{
if (pdfByteArrays == null || pdfByteArrays.Count == 0)
return null;
// Convert all byte arrays to PdfDocument objects
var pdfDocuments = pdfByteArrays
.Select(bytes => new PdfDocument(bytes))
.ToList();
// Merge all PDFs in one operation
var PDF = PdfDocument.Merge(pdfDocuments);
// Clean up resources
foreach (var pdfDoc in pdfDocuments)
{
pdfDoc.Dispose();
}
return PDF.BinaryData;
}Imports System.Collections.Generic
Imports System.Linq
Public Function MergeMultiplePdfByteArrays(pdfByteArrays As List(Of Byte())) As Byte()
If pdfByteArrays Is Nothing OrElse pdfByteArrays.Count = 0 Then
Return Nothing
End If
' Convert all byte arrays to PdfDocument objects
Dim pdfDocuments = pdfByteArrays _
.Select(Function(bytes) New PdfDocument(bytes)) _
.ToList()
' Merge all PDFs in one operation
Dim PDF = PdfDocument.Merge(pdfDocuments)
' Clean up resources
For Each pdfDoc In pdfDocuments
pdfDoc.Dispose()
Next
Return PDF.BinaryData
End Function이 방법은 PDF 바이트 배열을 효율적으로 처리합니다. 입력을 먼저 검증하여 목록에 데이터가 포함되어 있는지 확인합니다. LINQ의 Select() 메서드를 사용하여 각 바이트 배열을 PdfDocument 객체로 변환합니다. Merge() 메서드는 PDFDocument 객체 목록을 받아들이고, 이들을 하나의 작업으로 모두 결합하여 새 문서를 생성합니다. 자원 정리가 중요합니다 - PDF 병합 후 개별 PdfDocument 객체를 삭제하면 많은 또는 큰 PDF 파일을 처리할 때 메모리와 자원을 효과적으로 관리할 수 있습니다. 결과 바이트 배열의 길이는 모든 소스 PDF 문서의 페이지에 따라 다릅니다. 또한 다중 페이지 PDF를 분할하거나 특정 페이지를 복사하여 더 세부적인 제어가 가능합니다.
어떤 메모리 최적화 기술을 적용해야 할까요?
예측 가능한 메모리 사용량을 유지하기 위해 10-20개의 문서 배치로 PDF를 처리하세요. 대규모 작업의 경우, 설정 가능한 동시성 제한이 있는 큐 기반 접근 방식을 구현하세요. 처리 중 메모리 점유를 줄이기 위해 PDF 압축을 사용하세요. 큰 출력 파일을 다룰 때는 메모리에 파일을 유지하기보단 결과를 Azure Blob Storage로 직접 스트리밍하는 것을 고려하세요.
배치 작업 중 리소스 사용량을 어떻게 모니터링할까요?
활성 병합 작업, 메모리 소비 및 처리 큐 깊이를 추적하는 상태 검사 엔드포인트를 구현하세요. Kubernetes 준비 프로브가 적절하게 pod 스케일링을 관리할 수 있게 합니다. IronPDF 로깅을 구성하여 성능 지표를 수집하고 메모리 누수를 식별하세요. 배치 작업 중 정확한 메모리 할당 패턴을 추적하기 위해 메모리 스트림 API를 사용하세요.
프로덕션 사용을 위한 모범 사례는 무엇인가요?
손상되었거나 암호로 보호된 PDF 파일에서 발생할 수 있는 예외 처리를 위해 PDF 작업을 항상 try-catch 블록에 감싸세요. 메모리 누수를 방지하기 위해 using 구문을 사용하거나 PdfDocument 객체를 명시적으로 삭제하세요. 대규모 작업의 경우, 전체 문서를 메모리에 동시에 로드하기보다는 페이지네이션이나 스트리밍 접근 방식 구현을 고려하세요.
public byte[] SafeMergePdfByteArrays(byte[] firstPdf, byte[] secondPdf)
{
try
{
// Validate input PDFs
if (firstPdf == null || firstPdf.Length == 0)
throw new ArgumentException("First PDF is empty");
if (secondPdf == null || secondPdf.Length == 0)
throw new ArgumentException("Second PDF is empty");
using (var pdf1 = new PdfDocument(firstPdf))
using (var pdf2 = new PdfDocument(secondPdf))
{
// Check for password protection
if (pdf1.IsPasswordProtected || pdf2.IsPasswordProtected)
throw new InvalidOperationException("Password-protected PDFs require authentication");
var mergedPdf = PdfDocument.Merge(pdf1, pdf2);
// Apply security settings if needed
mergedPdf.SecuritySettings.AllowUserPrinting = true;
mergedPdf.SecuritySettings.AllowUserCopyPasteContent = false;
return mergedPdf.BinaryData;
}
}
catch (Exception ex)
{
// Log error details for debugging
Console.WriteLine($"PDF merge failed: {ex.Message}");
throw;
}
}public byte[] SafeMergePdfByteArrays(byte[] firstPdf, byte[] secondPdf)
{
try
{
// Validate input PDFs
if (firstPdf == null || firstPdf.Length == 0)
throw new ArgumentException("First PDF is empty");
if (secondPdf == null || secondPdf.Length == 0)
throw new ArgumentException("Second PDF is empty");
using (var pdf1 = new PdfDocument(firstPdf))
using (var pdf2 = new PdfDocument(secondPdf))
{
// Check for password protection
if (pdf1.IsPasswordProtected || pdf2.IsPasswordProtected)
throw new InvalidOperationException("Password-protected PDFs require authentication");
var mergedPdf = PdfDocument.Merge(pdf1, pdf2);
// Apply security settings if needed
mergedPdf.SecuritySettings.AllowUserPrinting = true;
mergedPdf.SecuritySettings.AllowUserCopyPasteContent = false;
return mergedPdf.BinaryData;
}
}
catch (Exception ex)
{
// Log error details for debugging
Console.WriteLine($"PDF merge failed: {ex.Message}");
throw;
}
}Imports System
Public Function SafeMergePdfByteArrays(firstPdf As Byte(), secondPdf As Byte()) As Byte()
Try
' Validate input PDFs
If firstPdf Is Nothing OrElse firstPdf.Length = 0 Then
Throw New ArgumentException("First PDF is empty")
End If
If secondPdf Is Nothing OrElse secondPdf.Length = 0 Then
Throw New ArgumentException("Second PDF is empty")
End If
Using pdf1 As New PdfDocument(firstPdf)
Using pdf2 As New PdfDocument(secondPdf)
' Check for password protection
If pdf1.IsPasswordProtected OrElse pdf2.IsPasswordProtected Then
Throw New InvalidOperationException("Password-protected PDFs require authentication")
End If
Dim mergedPdf = PdfDocument.Merge(pdf1, pdf2)
' Apply security settings if needed
mergedPdf.SecuritySettings.AllowUserPrinting = True
mergedPdf.SecuritySettings.AllowUserCopyPasteContent = False
Return mergedPdf.BinaryData
End Using
End Using
Catch ex As Exception
' Log error details for debugging
Console.WriteLine($"PDF merge failed: {ex.Message}")
Throw
End Try
End Function여러 PDF 문서의 선택된 페이지에서 작업할 때 결합하기 전에 특정 PdfPage 인스턴스를 추출할 수도 있습니다. IronPDF의 포괄적인 오류 처리는 테스트 및 프로덕션 환경 모두에서 강력한 프로덕션 배포를 보장합니다. 다른 PDF 라이브러리에 익숙하다면 IronPDF의 API가 프로젝트에서 가져와 사용하기에 특히 직관적임을 알게 될 것입니다. 신뢰할 수 없는 입력 소스에 대해 PDF 정리 및 문서 인증을 위한 디지털 서명 구현을 고려하세요.
컨테이너 환경에서 적절한 오류 처리를 구현하는 방법?
분산 시스템 전체에서 PDF 작업을 추적하기 위한 상관 ID를 사용하여 구조적 로깅을 구성하세요. 외부 PDF 소스에 대한 회로 차단기를 구현하여 연속적인 실패를 방지하세요. Azure 로그 파일이나 AWS 로그 파일을 사용하여 중앙 집중식 오류 추적을 하세요. 네이티브 예외를 다룰 때는 디버깅을 위해 적절한 오류 컨텍스트가 캡처되었는지 확인하세요.
PDF 처리 서비스에 가장 적합한 배포 패턴은 무엇입니까?
별도의 마이크로서비스로 PDF 처리를 배포하고 전용 리소스 제한을 설정하세요. 최적 성능을 위해 메모리 사용량을 기준으로 한 수평적 pod 오토스케일링을 사용하세요. 설정 가능한 동시성을 가진 배치 작업의 큐 기반 처리를 구현하세요. 컨테이너 이미지 크기를 줄이기 위해 IronPdf.Slim 패키지를 사용하는 것을 고려하세요. 서비스 레벨에서 일관성을 위해 맞춤 종이 크기와 맞춤 여백을 구성하세요.
왜 프로덕션 PDF 작업에 IronPDF를 선택해야 할까요?
IronPDF는 C#에서 바이트 배열로부터 PDF 파일을 병합하는 복잡한 작업을 간단히 처리하고, PDF 문서 구조의 세부 사항을 자동으로 다루는 깔끔한 API를 제공합니다. 문서 관리 시스템을 구축하든, API 응답을 처리하든, 첨부 파일을 포함한 파일 업로드를 처리하든, 데이터베이스 스토리지를 작업하든 간에 IronPDF의 병합 기능은 .NET 애플리케이션에 매끄럽게 통합됩니다.
라이브러리는 비동기 작업과 메모리 효율적인 처리를 지원하여 데스크톱 및 서버 애플리케이션 모두에 이상적입니다. 임시 파일을 디스크에 저장하지 않고 PDF 파일을 편집, 변환, 저장할 수 있습니다. 추가 지원 및 답변을 위해 저희 포럼이나 웹사이트를 방문하세요. API 참조는 사용 가능한 모든 메서드와 속성에 대한 포괄적인 문서를 제공합니다.
애플리케이션에서 PDF 병합을 구현할 준비가 되셨나요? 무료 체험판으로 시작하세요 또는 IronPDF의 모든 기능 세트를 탐색하세요. 여기에는 HTML을 PDF로 변환, PDF 양식 처리, 디지털 서명이 포함됩니다. 저희 사이트는 모든 System.IO 스트림 작업에 대한 완전한 참조 문서와 고급 PDF 조작 시나리오에 대한 광범위한 튜토리얼을 제공합니다.
자주 묻는 질문
C#에서 두 PDF 바이트 배열을 어떻게 병합할 수 있습니까?
C#에서 IronPDF를 사용하여 두 PDF 바이트 배열을 병합할 수 있습니다. 이를 통해 바이트 배열로 저장된 여러 PDF 파일을 디스크에 저장할 필요 없이 쉽게 하나의 PDF 문서로 결합할 수 있습니다.
PDF 바이트 배열을 병합할 때 IronPDF를 사용하는 이점은 무엇입니까?
IronPDF는 직관적인 API를 제공하여 PDF 바이트 배열을 병합하는 과정을 단순화합니다. 메모리 내에서 PDF를 효율적으로 처리하므로, 데이터베이스 또는 웹 서비스에서 PDF를 검색하는 애플리케이션에 이상적입니다.
IronPDF는 PDF 파일을 디스크에 저장하지 않고 병합할 수 있습니까?
네, IronPDF는 PDF 파일을 디스크에 저장하지 않고 병합할 수 있습니다. 이 기능은 바이트 배열에서 직접 PDF 파일을 처리하여 메모리 기반 작업에 적합합니다.
IronPDF를 사용하여 웹 서비스에서 받은 PDF 파일을 병합할 수 있습니까?
물론입니다. IronPDF는 웹 서비스에서 바이트 배열로 받은 PDF 파일을 병합할 수 있으며, 원격 PDF 소스와 매끄럽게 통합할 수 있습니다.
C#에서 PDF 바이트 배열을 병합하는 일반적인 응용 프로그램은 무엇입니까?
일반적인 응용 프로그램은 데이터베이스에서 검색한 여러 PDF 문서를 하나의 PDF 파일로 결합하여 C# 애플리케이션에서 처리하거나 표시하는 것입니다.
IronPDF는 메모리에서 PDF 처리를 지원합니까?
네, IronPDF는 메모리에서 PDF 처리를 지원합니다. 이는 중간 디스크 저장 없이 PDF 파일을 빠르게 조작해야 하는 애플리케이션에 필수적입니다.
IronPDF가 데이터베이스에서 PDF 병합을 어떻게 처리합니까?
IronPDF는 임시 파일 저장 없이 PDF 바이트 배열로 직접 작업할 수 있도록 하여 데이터베이스에서 PDF 병합을 처리합니다.
IronPDF는 여러 PDF 파일을 하나로 결합할 수 있습니까?
네, IronPDF는 바이트 배열을 병합하여 여러 PDF 파일을 하나로 결합할 수 있으며, 이는 복합적인 PDF 문서를 생성하는 간소화된 방법을 제공합니다.











