


C#ですべてのPDF DOMオブジェクトにアクセスする方法</#35;
C#でPDFのDOMオブジェクトにアクセスするには、IronPDFのObjectModelプロパティを使用します。このプロパティにより、PDFドキュメント内のテキスト、画像、パスオブジェクトへのプログラムによるアクセスが可能になり、要素の読み取り、変更、翻訳、拡大縮小、削除を直接行うことができます。
クイックスタート: IronPDF を使用した PDF DOM 要素へのアクセスと更新
IronPDFのDOMアクセス機能を使ってPDFドキュメントを操作しましょう。 このガイドでは、PDF DOMにアクセスし、ページを選択し、テキストオブジェクトを変更する方法を示します。 PDFを読み込み、目的のページにアクセスし、数行のコードでコンテンツを更新します。
最小限のワークフロー(5ステップ)
- PDFのDOMオブジェクトにアクセスするためのC#ライブラリをダウンロードする。
- ターゲットとするPDFドキュメントをインポートまたはレンダリングする
- PDFの
Pagesコレクションにアクセスし、必要なページを選択します - ObjectModel プロパティを使用して、DOM オブジェクトを表示し、操作します。
- 修正されたPDFドキュメントを保存またはエクスポートする
PDFのDOMオブジェクトにアクセスするには?
ObjectModel には、PdfPage オブジェクトからアクセスします。 まず、対象のPDFをインポートし、その Pages プロパティにアクセスします。 そこから、任意のページを選択して ObjectModel プロパティにアクセスします。 これは、HTMLのDOM要素を扱うのと同様に、プログラム的にPDFコンテンツと対話することを可能にします。
PDF DOM オブジェクトを扱うとき、PDF 文書の基本構造にアクセスします。 これには、テキスト要素、画像、ベクターグラフィックス(paths)、およびPDFの視覚的表現を構成するその他のコンテンツが含まれます。 IronPDFはC#アプリケーションと統合するPDF操作へのオブジェクト指向のアプローチを提供します。
:path=/static-assets/pdf/content-code-examples/how-to/access-pdf-dom-object.csusing IronPdf;
using System.Linq;
// Instantiate Renderer
ChromePdfRenderer renderer = new ChromePdfRenderer();
// Create a PDF from a URL
PdfDocument pdf = renderer.RenderUrlAsPdf("https://ironpdf.com/");
// Access DOM Objects
var objects = pdf.Pages.First().ObjectModel;Imports IronPdf
Imports System.Linq
' Instantiate Renderer
Private renderer As New ChromePdfRenderer()
' Create a PDF from a URL
Private pdf As PdfDocument = renderer.RenderUrlAsPdf("https://ironpdf.com/")
' Access DOM Objects
Private objects = pdf.Pages.First().ObjectModel
ObjectModel プロパティには、PathObject、および TextObject が含まれています。 各オブジェクトには、そのページインデックス、バウンディングボックス、Translationに関する情報が含まれています。 この情報は変更可能です。 レンダリングオプションでは、これらのオブジェクトの表示方法をカスタマイズできます。 カスタムマージンを使用する場合、オブジェクトの位置を理解することが重要です。
<ImageObject>:
Height: 画像の高さWidth: 画像の幅ExportBytesAsJpg: 画像をJPGバイト配列としてエクスポートする方法
<PathObject>:
FillColor: パスの塗りつぶし色StrokeColor: パスのストローク色Points: パスを定義する点の集合
<TextObject>:
Color: テキストの色Contents: 実際のTextコンテンツ
各オブジェクトタイプは、コンテンツタイプに合わせたメソッドとプロパティを提供します。 テキストや画像を抽出したり、特定のコンテンツを変更する必要がある場合、これらのオブジェクトはきめ細かなコントロールを提供します。 PDF フォームで、プログラム的にフォームフィールドを操作する必要がある場合に役立ちます。
グリフ情報とバウンディングボックスを取得するにはどうすればよいですか?
カスタムフォントで正確なグリフを指定する場合、バウンディングボックスとグリフ情報の取得が不可欠です。 IronPDFは既存のPDFにテキストやビットマップを描画する際、ピクセルパーフェクトな位置決めのためにこの情報を提供します。
ObjectModel オブジェクトから PdfPage にアクセスします。 その後、TextObjects コレクションにアクセスしてください。 GetGlyphInfo メソッドを呼び出して、グリフおよびバウンディングボックスの情報を取得します。
:path=/static-assets/pdf/content-code-examples/how-to/access-pdf-dom-object-retrieve-glyph.csusing IronPdf;
using System.Linq;
PdfDocument pdf = PdfDocument.FromFile("invoice.pdf");
var glyph = pdf.Pages.First().ObjectModel.TextObjects.First().GetGlyphInfo();Imports IronPdf
Imports System.Linq
Dim pdf As PdfDocument = PdfDocument.FromFile("invoice.pdf")
Dim glyph = pdf.Pages.First().ObjectModel.TextObjects.First().GetGlyphInfo()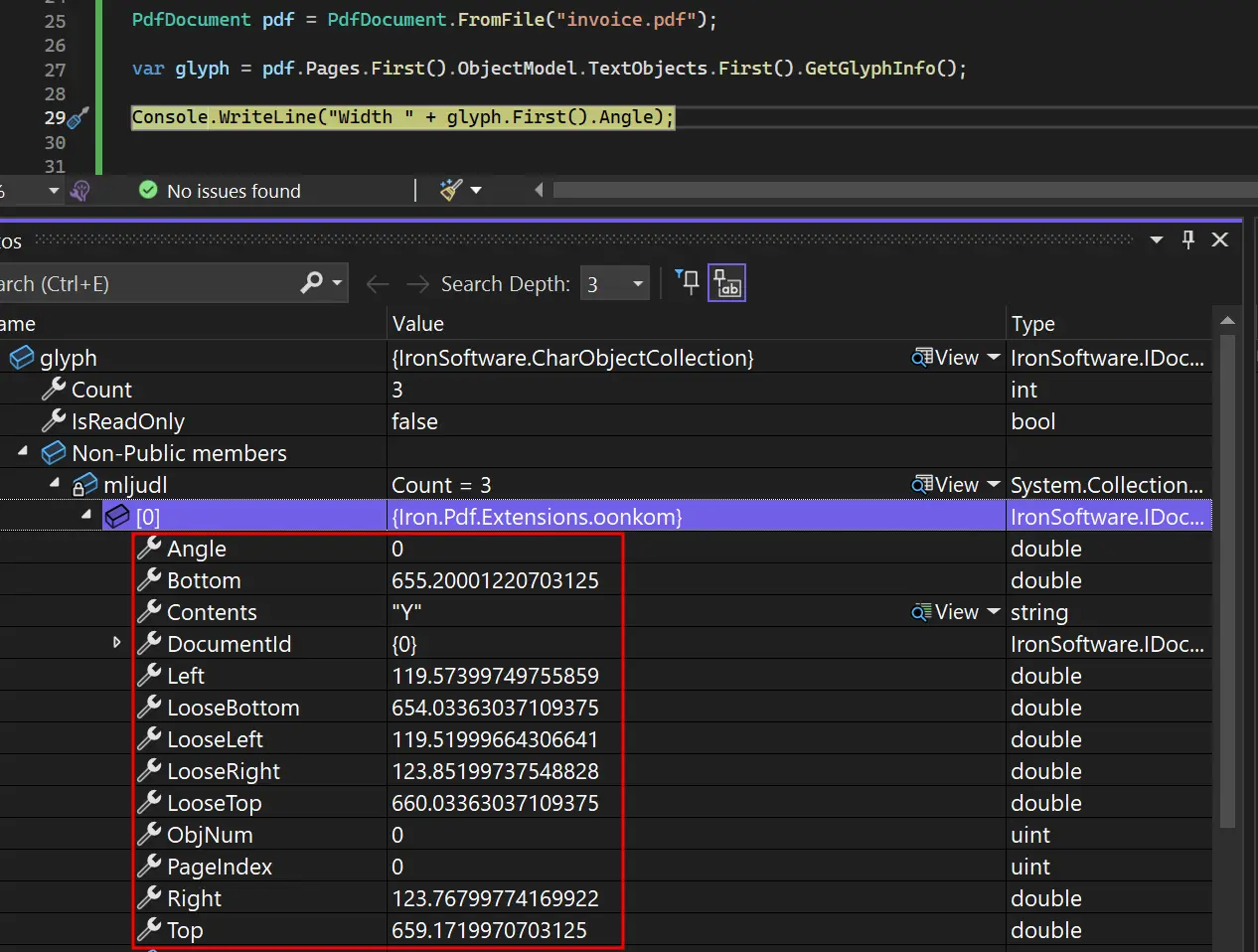
グリフ情報には、位置データ、フォントメトリクス、高度なPDF操作のための文字固有の詳細が含まれます。 これにより、複雑な組版やレイアウト要件を扱うPDF処理アプリケーションの作成が可能になります。 カスタムフォントを使用する場合、このグリフレベルのアクセスにより、システム間で正確なレンダリングが保証されます。
PDFオブジェクトを翻訳するにはどうすればよいですか?
テキストや画像などの要素を再配置することで、PDFのレイアウトを調整します。 オブジェクトを移動するには、その Translate プロパティを変更します。 この機能はIronPDFのPDF変換機能の一部です。
以下の例では、CSS Flexboxを使用してHTMLをレンダリングし、テキストを中央に配置しています。 最初の TextObject にアクセスし、PointF を Translate プロパティに割り当てることで翻訳します。 これにより、テキストは右に200ポイント、上に150ポイント移動します。その他の例については、translate PDF objects example pageをご覧ください。
オブジェクトを翻訳するにはどのコードを使用すればよいですか?
:path=/static-assets/pdf/content-code-examples/how-to/access-pdf-dom-object-translate.csusing IronPdf;
using System.Drawing;
using System.Linq;
// Setup the Renderer
var renderer = new ChromePdfRenderer();
// We use CSS Flexbox to perfectly center the text vertically and horizontally.
var html = @"
<div style='display: flex; justify-content: center; align-items: center; font-size: 48px;'>
Centered
</div>";
// Render the HTML to a PDF
PdfDocument pdf = renderer.RenderHtmlAsPdf(html);
// Save the original PDF to see the "before" state
pdf.SaveAs("BeforeTranslate.pdf");
// Access the first text object on the first page
// In this simple HTML, this will be our "Centered" text block.
var textObject = pdf.Pages.First().ObjectModel.TextObjects.First();
// Apply the translation
// This moves the object 200 points to the right and 150 points up from its original position.
textObject.Translate = new PointF(200, 150);
// Save the modified PDF to see the "after" state
pdf.SaveAs("AfterTranslate.pdf");Imports IronPdf
Imports System.Drawing
Imports System.Linq
' Setup the Renderer
Dim renderer As New ChromePdfRenderer()
' We use CSS Flexbox to perfectly center the text vertically and horizontally.
Dim html As String = "
<div style='display: flex; justify-content: center; align-items: center; font-size: 48px;'>
Centered
</div>"
' Render the HTML to a PDF
Dim pdf As PdfDocument = renderer.RenderHtmlAsPdf(html)
' Save the original PDF to see the "before" state
pdf.SaveAs("BeforeTranslate.pdf")
' Access the first text object on the first page
' In this simple HTML, this will be our "Centered" text block.
Dim textObject = pdf.Pages.First().ObjectModel.TextObjects.First()
' Apply the translation
' This moves the object 200 points to the right and 150 points up from its original position.
textObject.Translate = New PointF(200, 150)
' Save the modified PDF to see the "after" state
pdf.SaveAs("AfterTranslate.pdf")翻訳結果はどのようになりますか?
出力では、"Centered"が元の位置から右に200ポイント、上に150ポイントシフトしています。
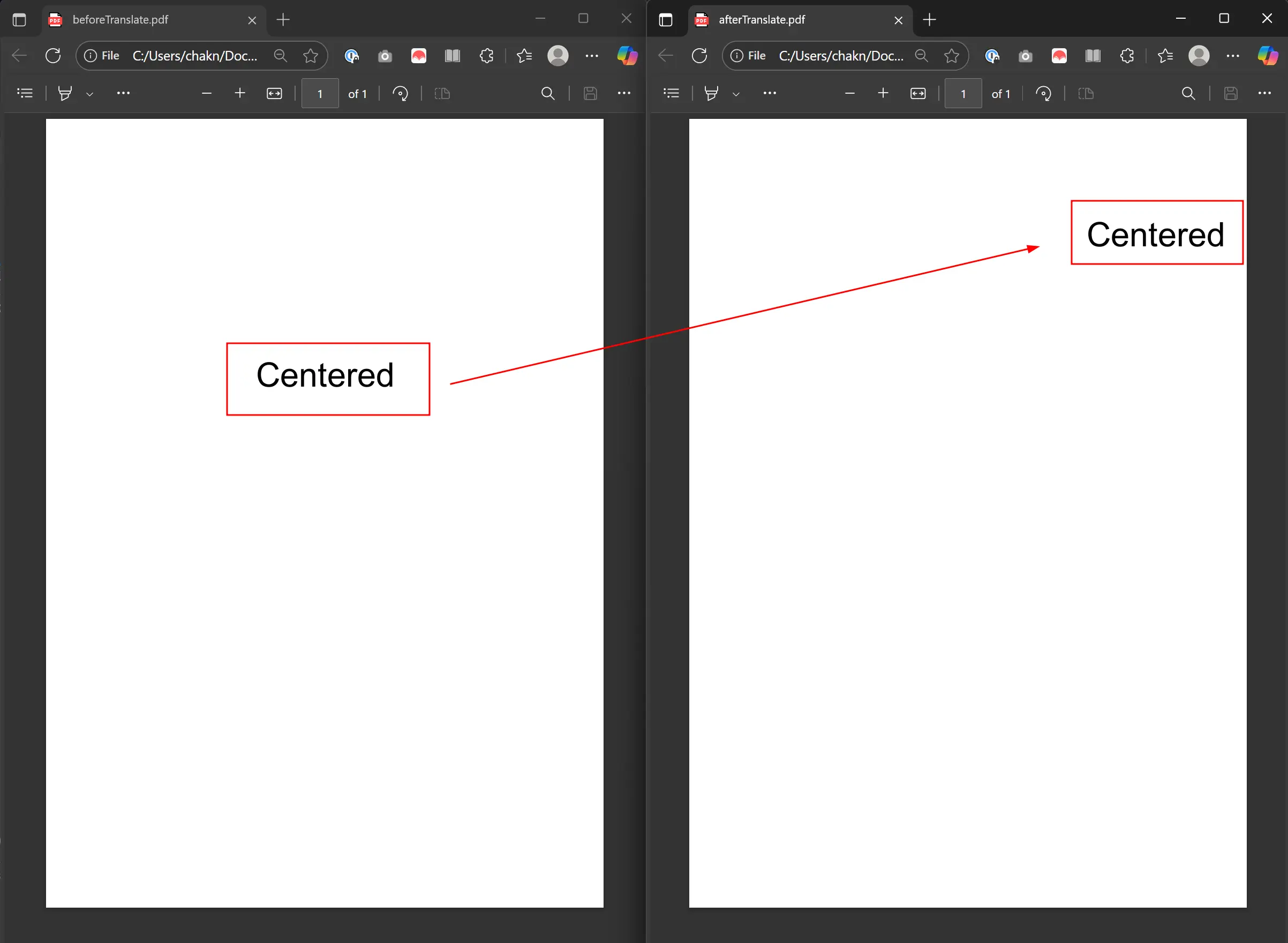
翻訳作業では、フォント、サイズ、色などのオブジェクトの元のプロパティを維持し、位置のみを変更します。 これは、見た目に影響を与えないレイアウト調整に最適です。 この機能は、動的に生成されたコンテンツを再配置するときに、ヘッダーとフッターで動作します。
PDFオブジェクトを拡大縮小するには?
Scale プロパティを使用して、PDF オブジェクトのサイズを変更します。 このプロパティは乗数として機能します。 1より大きい値はサイズが大きくなり、0から1の間の値は小さくなります。 動的なレイアウトや、ページの寸法に合わせてコンテンツを調整するには、スケーリングが不可欠です。 その他の例については、スケールPDFオブジェクトガイドを参照してください。
この例では、画像を含むHTMLをレンダリングしています。 最初の ImageObject にアクセスし、Scale に両軸とも 0.7 の値を持つ新しい PointF を割り当てることで、それを 70% に拡大縮小します。
PDFオブジェクトをスケーリングするコードは何ですか?
:path=/static-assets/pdf/content-code-examples/how-to/access-pdf-dom-object-scale.csusing IronPdf;
using System.Linq;
// Setup the Renderer
var renderer = new ChromePdfRenderer();
// The image is placed in a div to give it some space on the page.
string html = @"<img src='https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcTi8LuOR6_A98euPLs-JRwoLU7Nc31nVP15rw&s'>";
// Render the HTML to a PDF
PdfDocument pdf = renderer.RenderHtmlAsPdf(html);
// Save the PDF before scaling for comparison
pdf.SaveAs("BeforeScale.pdf");
// Access the first image object on the first page
var image = pdf.Pages.First().ObjectModel.ImageObjects.First();
// We scale the image to 70% of its original size on both the X and Y axes.
image.Scale = new System.Drawing.PointF(0.7f, 0.7f);
// Save the modified PDF to see the result
pdf.SaveAs("AfterScale.pdf");Imports IronPdf
Imports System.Linq
Imports System.Drawing
' Setup the Renderer
Dim renderer As New ChromePdfRenderer()
' The image is placed in a div to give it some space on the page.
Dim html As String = "<img src='https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcTi8LuOR6_A98euPLs-JRwoLU7Nc31nVP15rw&s'>"
' Render the HTML to a PDF
Dim pdf As PdfDocument = renderer.RenderHtmlAsPdf(html)
' Save the PDF before scaling for comparison
pdf.SaveAs("BeforeScale.pdf")
' Access the first image object on the first page
Dim image = pdf.Pages.First().ObjectModel.ImageObjects.First()
' We scale the image to 70% of its original size on both the X and Y axes.
image.Scale = New PointF(0.7F, 0.7F)
' Save the modified PDF to see the result
pdf.SaveAs("AfterScale.pdf")X軸とY軸にそれぞれ異なるスケーリング係数を適用して、不均一なスケーリングを行います。 これは、コンテンツを特定の次元に当てはめるのに便利です。 カスタム用紙サイズで作業する場合、拡大縮小することで、コンテンツがページの境界内に収まるようにします。
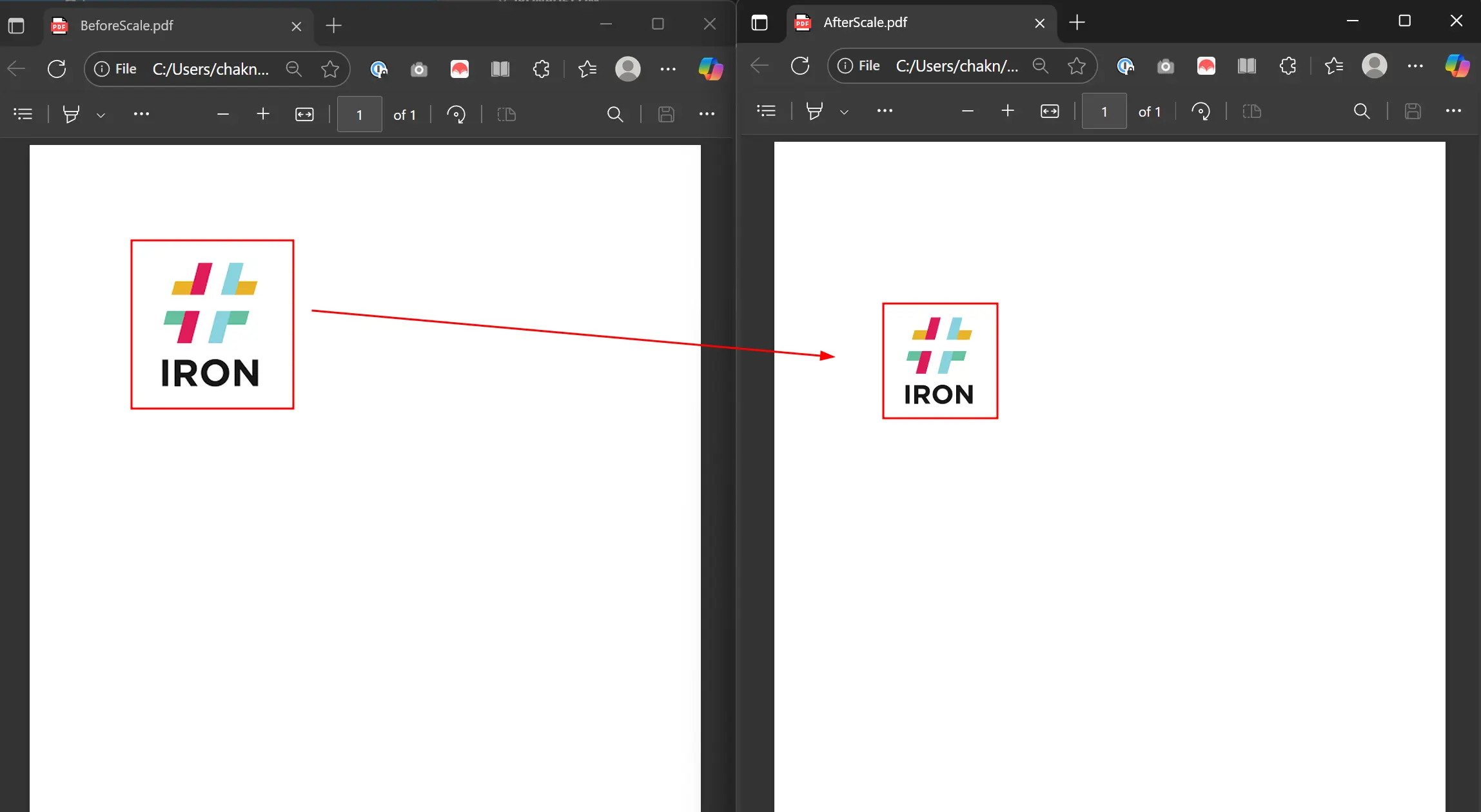
スケーリングは実際にはどのようなものですか?
出力は元のサイズの70%にスケーリングされた画像を示しています。
どのように PDF オブジェクトを削除できますか?
ImageObjects や TextObjects のように、PDF DOM コレクションにアクセスしてオブジェクトを削除します。 コレクションに対して RemoveAt を呼び出し、削除するオブジェクトのインデックスを渡します。 これは、コンテンツの再編集や文書の簡素化に役立ちます。 詳しくはPDFオブジェクトの削除例をご覧ください。
コードはBeforeScale.pdfを読み込み、最初のページから最初の画像を削除します。
オブジェクトを削除するにはどのコードを使用すればよいですか?
:path=/static-assets/pdf/content-code-examples/how-to/access-pdf-dom-object-remove.csusing IronPdf;
using System.Linq;
// Load the PDF file we created in the Scale example
PdfDocument pdf = PdfDocument.FromFile("BeforeScale.pdf");
// Access DOM Objects
var objects = pdf.Pages.First().ObjectModel;
// Remove first image
objects.ImageObjects.RemoveAt(0);
// Save the modified PDF
pdf.SaveAs("removedFirstImage.pdf");Imports IronPdf
Imports System.Linq
' Load the PDF file we created in the Scale example
Dim pdf As PdfDocument = PdfDocument.FromFile("BeforeScale.pdf")
' Access DOM Objects
Dim objects = pdf.Pages.First().ObjectModel
' Remove first image
objects.ImageObjects.RemoveAt(0)
' Save the modified PDF
pdf.SaveAs("removedFirstImage.pdf")複数のオブジェクトを削除するとどうなりますか?
残りのオブジェクトのインデックスは、削除後にシフトします。 複数のオブジェクトを削除する場合は、正しいインデックスを維持するために、逆順に削除してください。 このテクニックは、機密文書からテキストを削除するときに役立ちます。
複数の DOM 操作を組み合わせるにはどうすればよいですか?
IronPDFのDOMアクセスは高度な文書処理ワークフローを可能にします。 複雑な変換のための操作を組み合わせる:
どのような場合に複合語を使うべきですか?
// Example of combining multiple DOM operations
using IronPdf;
using System.Linq;
PdfDocument pdf = PdfDocument.FromFile("complex-document.pdf");
// Iterate through all pages
foreach (var page in pdf.Pages)
{
var objects = page.ObjectModel;
// Process text objects
foreach (var textObj in objects.TextObjects)
{
// Change color of specific text
if (textObj.Contents.Contains("Important"))
{
textObj.Color = System.Drawing.Color.Red;
}
}
// Scale down all images by 50%
foreach (var imgObj in objects.ImageObjects)
{
imgObj.Scale = new System.Drawing.PointF(0.5f, 0.5f);
}
}
pdf.SaveAs("processed-document.pdf");// Example of combining multiple DOM operations
using IronPdf;
using System.Linq;
PdfDocument pdf = PdfDocument.FromFile("complex-document.pdf");
// Iterate through all pages
foreach (var page in pdf.Pages)
{
var objects = page.ObjectModel;
// Process text objects
foreach (var textObj in objects.TextObjects)
{
// Change color of specific text
if (textObj.Contents.Contains("Important"))
{
textObj.Color = System.Drawing.Color.Red;
}
}
// Scale down all images by 50%
foreach (var imgObj in objects.ImageObjects)
{
imgObj.Scale = new System.Drawing.PointF(0.5f, 0.5f);
}
}
pdf.SaveAs("processed-document.pdf");Imports IronPdf
Imports System.Linq
Imports System.Drawing
Dim pdf As PdfDocument = PdfDocument.FromFile("complex-document.pdf")
' Iterate through all pages
For Each page In pdf.Pages
Dim objects = page.ObjectModel
' Process text objects
For Each textObj In objects.TextObjects
' Change color of specific text
If textObj.Contents.Contains("Important") Then
textObj.Color = Color.Red
End If
Next
' Scale down all images by 50%
For Each imgObj In objects.ImageObjects
imgObj.Scale = New PointF(0.5F, 0.5F)
Next
Next
pdf.SaveAs("processed-document.pdf")複合操作の一般的なユースケースは何ですか?
DOM 操作の組み合わせは、次のような場合に有効です:
- バッチ文書処理: 文書のフォーマットを標準化したり、機密内容を削除する
- 動的レポート生成: レイアウトを制御しながら、リアルタイムデータでテンプレートPDFを修正する
- コンテンツ移行: PDFからコンテンツを抽出し、新しいレイアウトに再編成する
- アクセシビリティの向上: テキストサイズ、コントラスト、または間隔を変更して文書を強化する
これらの技術は、複雑な変更を扱う強力なPDF処理アプリケーションを可能にします。 ドキュメントのプロパティの管理については、メタデータ管理ガイドを参照してください。
DOMアクセスは他のPDF操作方法と比較してどうですか?
PDF DOMを使用することで、従来のアプローチにはない利点が得られます:
// Example: Selective content modification based on criteria
using IronPdf;
using System.Linq;
PdfDocument report = PdfDocument.FromFile("quarterly-report.pdf");
foreach (var page in report.Pages)
{
var textObjects = page.ObjectModel.TextObjects;
// Highlight negative values in financial reports
foreach (var text in textObjects)
{
if (text.Contents.StartsWith("-$") || text.Contents.Contains("Loss"))
{
text.Color = System.Drawing.Color.Red;
}
}
}
report.SaveAs("highlighted-report.pdf");// Example: Selective content modification based on criteria
using IronPdf;
using System.Linq;
PdfDocument report = PdfDocument.FromFile("quarterly-report.pdf");
foreach (var page in report.Pages)
{
var textObjects = page.ObjectModel.TextObjects;
// Highlight negative values in financial reports
foreach (var text in textObjects)
{
if (text.Contents.StartsWith("-$") || text.Contents.Contains("Loss"))
{
text.Color = System.Drawing.Color.Red;
}
}
}
report.SaveAs("highlighted-report.pdf");Imports IronPdf
Imports System.Linq
Dim report As PdfDocument = PdfDocument.FromFile("quarterly-report.pdf")
For Each page In report.Pages
Dim textObjects = page.ObjectModel.TextObjects
' Highlight negative values in financial reports
For Each text In textObjects
If text.Contents.StartsWith("-$") OrElse text.Contents.Contains("Loss") Then
text.Color = System.Drawing.Color.Red
End If
Next
Next
report.SaveAs("highlighted-report.pdf")HTMLからPDFへの変換だけでは、このようなきめ細かな制御は不可能であり、高度なPDF処理にはDOMアクセスが不可欠です。
次に何ができるのかを見てみましょうか? チュートリアルのページはこちらをご覧ください:PDFを編集する.
よくある質問
PDF 操作で ObjectModel プロパティは何に使用されますか?
IronPDFのObjectModelプロパティはPDFドキュメント内のテキスト、画像、パスオブジェクトへのプログラムアクセスを提供します。これにより開発者はHTMLのDOM要素を扱うのと同様に、PDF DOMから直接要素を読み込んだり、変更したり、変換したり、拡大縮小したり、削除したりすることができます。
C# で PDF DOM オブジ ェ ク ト にア ク セ スす る 方法は?
IronPDFを使ってPDF DOMオブジェクトにアクセスするには、まず対象のPDFドキュメントをインポートし、そのPagesプロパティにアクセスします。そこから任意のページを選択し、ObjectModelプロパティを使用します。例: var objs = IronPdf.ChromePdfRenderer.RenderUrlAsPdf("https://example.com").Pages.First().ObjectModel;
PDF DOM からアクセスできるオブジェクトの種類は?
IronPDFのObjectModelには3つの主なオブジェクトタイプがあります:ImageObject(Height、Width、ExportBytesAsJpgなどのプロパティを持つ)、PathObject(FillColor、StrokeColor、Pointsを持つ)、TextObject(ColorとContentsプロパティを持つ)です。それぞれ、特定のコンテンツタイプに合わせたメソッドを提供します。
PDF文書内のテキストコンテンツをプログラムで変更できますか?
はい、IronPDFではTextObjectのContentsプロパティを通してテキストの内容を変更することができます。ObjectModelを介してテキストオブジェクトにアクセスし、その内容を更新し、数行のコードで変更したPDFドキュメントを保存することができます。
PDF文書から画像をエクスポートする方法を教えてください。
IronPDFのImageObjectはExportBytesAsJpgメソッドを提供し、画像をJPGバイト配列としてエクスポートすることができます。ObjectModelプロパティを通して画像にアクセスし、このメソッドを使ってプログラムで画像データを取り出してください。
各 DOM オブジェクトの位置について、どのような情報が得られますか?
IronPDFのObjectModelの各オブジェクトはページインデックス、バウンディングボックスの座標、スケール、移動に関する情報を含んでいます。この位置決めデータはPDF内の要素の位置を変えたり、変形させたりするために読み込んだり、変更したりすることができます。


まだスクロールしていますか?
すぐに証拠が欲しいですか? PM > Install-Package IronPdf
サンプルを実行するHTML が PDF に変換されるのを確認します。










